Panoramica dell'AI generativa
Questo documento descrive le funzionalità di intelligenza artificiale (IA) generativa supportate da BigQuery ML. Queste funzionalità ti consentono di eseguire attività di IA in BigQuery ML utilizzando modelli Vertex AI pre-addestrati. Le attività supportate includono:
Per accedere a un modello Vertex AI ed eseguire una di queste funzioni, crea un modello remoto in BigQuery ML che rappresenti l'endpoint del modello Vertex AI. Dopo aver creato un modello remoto sul modello Vertex AI che vuoi utilizzare, accedi alle sue funzionalità eseguendo una funzione BigQuery ML sul modello remoto.
Questo approccio ti consente di utilizzare le funzionalità di questi modelli Vertex AI nelle query SQL per analizzare i dati di BigQuery.
Flusso di lavoro
Puoi utilizzare modelli remoti rispetto ai modelli Vertex AI e modelli remoti rispetto ai servizi Cloud AI insieme alle funzioni BigQuery ML per eseguire analisi dei dati complesse e attività di IA generativa.
Il seguente diagramma mostra alcuni flussi di lavoro tipici in cui potresti utilizzare queste funzionalità insieme:
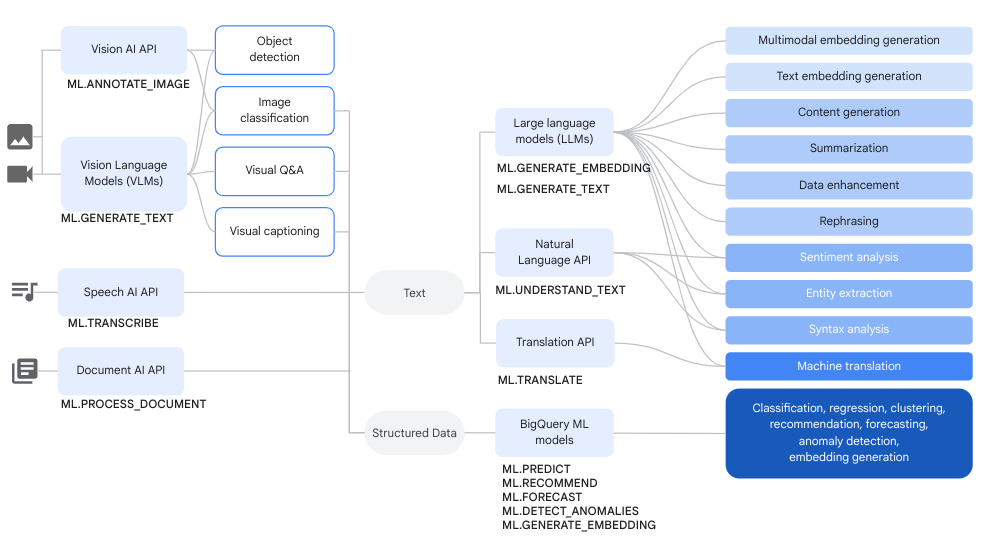
Generazione di testo
La generazione di testo è una forma di IA generativa in cui il testo viene generato in base a un prompt o all'analisi dei dati. Puoi eseguire la generazione di testo utilizzando sia i dati di testo che quelli multimodali.
Ecco alcuni casi d'uso comuni per la generazione di testo:
- Generazione di contenuti creativi.
- Generazione del codice.
- Generazione di risposte via chat o email.
- Brainstorming, ad esempio suggerendo strade per prodotti o servizi futuri.
- Personalizzazione dei contenuti, ad esempio suggerimenti di prodotti.
- Classificazione dei dati mediante l'applicazione di una o più etichette ai contenuti per ordinarli in categorie.
- Identificazione dei principali sentimenti espressi nei contenuti.
- Riepilogare le idee o le impressioni chiave trasmesse dai contenuti.
- Identificazione di una o più entità in evidenza nei dati di testo o visivi.
- Traduzione dei contenuti di dati di testo o audio in un'altra lingua.
- Generazione di testo corrispondente ai contenuti verbali nei dati audio.
- Sottotitolazione codificata o domande e risposte sui dati visivi.
L'arricchimento dei dati è un passaggio comune successivo alla generazione di testo, in cui puoi arricchire le informazioni dell'analisi iniziale combinandole con dati aggiuntivi. Ad esempio, potresti analizzare le immagini di arredi per la casa per generare il testo per una colonna design_type, in modo che lo SKU degli arredi abbia una descrizione associata, ad esempio mid-century modern o farmhouse.
Modelli supportati
Per eseguire attività di IA generativa, puoi utilizzare i modelli remoti in BigQuery ML per fare riferimento ai modelli di cui è stato eseguito il deployment o che sono ospitati in Vertex AI. Puoi creare i seguenti tipi di modelli remoti:
Modelli remoti su uno dei seguenti modelli Vertex AI preaddestrati:
Per fornire feedback o richiedere assistenza per i modelli in anteprima, invia un'email all'indirizzo bqml-feedback@google.com.
Utilizzo di modelli di generazione di testo
Dopo aver creato un modello remoto, puoi utilizzare la
funzione ML.GENERATE_TEXT
per interagire con il modello:
- Per i modelli remoti basati sui modelli Gemini 1.5 o 2.0,
puoi utilizzare la funzione
ML.GENERATE_TEXTper analizzare testo, immagini, audio, video o contenuti PDF da una tabella di oggetti con un prompt fornito come argomento della funzione oppure puoi generare testo da un prompt fornito in una query o da una colonna di una tabella standard. - Per i modelli remoti basati sul modello
gemini-1.0-pro-vision, puoi utilizzare la funzioneML.GENERATE_TEXTper analizzare i contenuti di immagini o video da una tabella di oggetti con un prompt fornito come argomento della funzione. - Per tutti gli altri tipi di modelli remoti, puoi utilizzare la funzione
ML.GENERATE_TEXTcon un prompt fornito in una query o da una colonna di una tabella standard.
Puoi utilizzare
grounding
e
attributi di sicurezza
quando utilizzi i modelli Gemini con la funzione ML.GENERATE_TEXT,
a condizione che tu stia utilizzando una tabella standard per l'input. La funzionalità di grounding consente al
modello Gemini di utilizzare informazioni aggiuntive di internet per
generare risposte più specifiche e oggettive. Gli attributi di sicurezza consentono al
modello Gemini di filtrare le risposte restituite in base agli
attributi specificati.
Quando crei un modello remoto che fa riferimento a uno dei seguenti modelli, se vuoi puoi scegliere di configurare contemporaneamente la ottimizzazione supervisionata:
gemini-1.5-pro-002gemini-1.5-flash-002gemini-1.0-pro-002(Anteprima)
Tutta l'inferenza avviene in Vertex AI. I risultati vengono archiviati in BigQuery.
Utilizza i seguenti argomenti per provare la generazione di testo in BigQuery ML:
- Genera testo utilizzando un modello Gemini e la funzione
ML.GENERATE_TEXT. - Analizzare le immagini con un modello di visione di Gemini.
- Genera del testo utilizzando la funzione
ML.GENERATE_TEXTcon i tuoi dati. - Ottimizzare un modello utilizzando i tuoi dati.
- Genera testo utilizzando un modello
text-bisone la funzioneML.GENERATE_TEXT. generation
Incorporamento
Un embedding è un vettore numerico ad alta dimensione che rappresenta una determinata entità, ad esempio un testo o un file audio. La generazione di embedding ti consente di acquisire la semantica dei dati in modo da ragionare e confrontare più facilmente i dati.
Di seguito sono riportati alcuni casi d'uso comuni per la generazione di embed:
- Utilizzo della Retrieval Augmented Generation (RAG) per migliorare le risposte del modello alle query degli utenti facendo riferimento a dati aggiuntivi di una fonte attendibile. La RAG offre una maggiore accuratezza fattuale e coerenza delle risposte, nonché l'accesso a dati più recenti rispetto a quelli di addestramento del modello.
- Eseguire una ricerca multimodale. Ad esempio, l'utilizzo dell'input di testo per cercare nelle immagini.
- Eseguire una ricerca semantica per trovare elementi simili per consigli, sostituzione e deduplica dei record.
- Creazione di rappresentazioni distribuite da utilizzare con un modello K-means per il clustering.
Modelli supportati
Sono supportati i seguenti modelli:
- Per creare embedding di testo, puoi utilizzare i modelli
text-embeddingetext-multilingual-embeddingdi Vertex AI. - Per creare embedding multimodali, che possono incorporare testo, immagini e video nello stesso spazio semantico, puoi utilizzare il modello
multimodalembeddingdi Vertex AI. - Per creare embedding per i dati strutturati di variabili casuali indipendenti e con distribuzione identica (IID), puoi utilizzare un modello di analisi delle componenti principali (PCA) di BigQuery ML o un modello di autoencoder.
- Per creare embedding per i dati utente o articolo, puoi utilizzare un modello di fattorizzazione matriciale di BigQuery ML.
Per un embedding di testo più piccolo e leggero, prova a utilizzare un modello di TensorFlow preaddestrato, come NNLM, SWIVEL o BERT.
Utilizzo di modelli di generazione di embedding
Dopo aver creato il modello, puoi utilizzare la
funzione ML.GENERATE_EMBEDDING
per interagire con esso. Per tutti i tipi di modelli supportati, ML.GENERATE_EMBEDDING
funziona con i dati nelle
tabelle standard. Per i modelli di embedding multimodali, ML.GENERATE_EMBEDDING funziona anche con i contenuti visivi nelle tabelle di oggetti.
Per i modelli remoti, tutta l'inferenza avviene in Vertex AI. Per gli altri tipi di modelli, tutta l'inferenza avviene in BigQuery. I risultati vengono memorizzati in BigQuery.
Utilizza i seguenti argomenti per provare la generazione di testo in BigQuery ML:
- Genera rappresentazioni distribuite di testo utilizzando la funzione
ML.GENERATE_EMBEDDING - Genera rappresentazioni distribuite di immagini utilizzando la funzione
ML.GENERATE_EMBEDDING - Generare incorporamenti di video utilizzando la funzione
ML.GENERATE_EMBEDDING - Generare ed eseguire ricerche di embedding multimodali
- Eseguire la ricerca semantica e la generazione basata sul recupero
Prezzi
Ti vengono addebitate le risorse di calcolo utilizzate per eseguire query sui modelli. I modelli remoti effettuano chiamate ai modelli Vertex AI, pertanto le query relative ai modelli remoti comportano anche addebiti da Vertex AI.
Per ulteriori informazioni, consulta Prezzi di BigQuery ML.
Passaggi successivi
- Per saperne di più sull'esecuzione dell'inferenza sui modelli di machine learning, consulta la Panoramica dell'inferenza del modello.