Ringkasan AI Generatif
Dokumen ini menjelaskan fitur kecerdasan buatan (AI) generatif yang didukung BigQuery ML. Fitur ini memungkinkan Anda melakukan tugas AI di BigQuery ML menggunakan model Vertex AI yang telah dilatih sebelumnya. Tugas yang didukung meliputi:
Anda mengakses model Vertex AI untuk menjalankan salah satu fungsi ini dengan membuat model jarak jauh di BigQuery ML yang mewakili endpoint model Vertex AI. Setelah membuat model jarak jauh melalui model Vertex AI yang ingin digunakan, Anda dapat mengakses kemampuan model tersebut dengan menjalankan fungsi BigQuery ML terhadap model jarak jauh.
Pendekatan ini memungkinkan Anda menggunakan kemampuan model Vertex AI ini dalam kueri SQL untuk menganalisis data BigQuery.
Alur kerja
Anda dapat menggunakan model jarak jauh melalui model Vertex AI dan model jarak jauh melalui layanan Cloud AI bersama dengan fungsi BigQuery ML untuk menyelesaikan analisis data yang kompleks dan tugas AI generatif.
Diagram berikut menunjukkan beberapa alur kerja umum tempat Anda dapat menggunakan kemampuan ini bersama-sama:
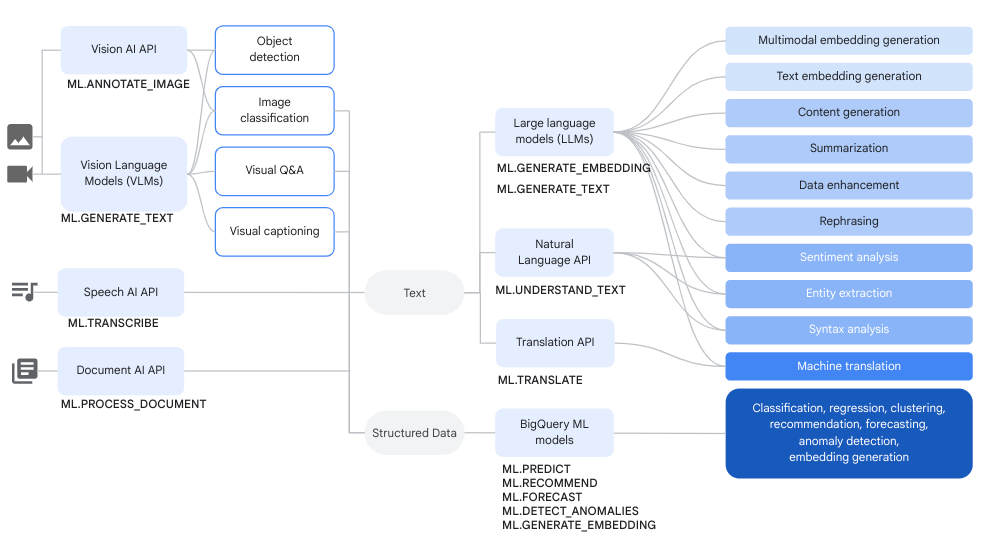
Pembuatan teks
Pembuatan teks adalah bentuk AI generatif yang menghasilkan teks berdasarkan perintah atau analisis data. Anda dapat melakukan pembuatan teks menggunakan data teks dan multimodal.
Beberapa kasus penggunaan umum untuk pembuatan teks adalah sebagai berikut:
- Membuat konten materi iklan.
- Membuat kode.
- Membuat respons chat atau email.
- Bertukar pikiran, seperti menyarankan cara untuk produk atau layanan mendatang.
- Personalisasi konten, seperti saran produk.
- Mengelompokkan data dengan menerapkan satu atau beberapa label ke konten untuk mengurutkannya ke dalam kategori.
- Mengidentifikasi sentimen utama yang diungkapkan dalam konten.
- Merangkum ide atau kesan utama yang disampaikan oleh konten.
- Mengidentifikasi satu atau beberapa entity yang penting dalam data teks atau visual.
- Menerjemahkan konten teks atau data audio ke bahasa lain.
- Membuat teks yang cocok dengan konten verbal dalam data audio.
- Memberi teks atau melakukan Tanya Jawab tentang data visual.
Pengayaan data adalah langkah berikutnya yang umum setelah pembuatan teks, yaitu Anda memperkaya insight dari analisis awal dengan menggabungkannya dengan data tambahan. Misalnya, Anda dapat menganalisis gambar perlengkapan rumah untuk membuat teks untuk
kolom design_type, sehingga SKU perlengkapan memiliki
deskripsi terkait, seperti mid-century modern atau farmhouse.
Model yang didukung
Untuk melakukan tugas AI generatif, Anda dapat menggunakan model jarak jauh di BigQuery ML untuk mereferensikan ke model yang di-deploy ke atau dihosting di Vertex AI. Anda dapat membuat jenis model jarak jauh berikut:
Model jarak jauh di atas salah satu model Vertex AI terlatih sebelumnya berikut:
Model jarak jauh melalui model Claude Anthropic (Pratinjau).
Untuk memberikan masukan atau meminta dukungan terkait model dalam pratinjau, kirim email ke bqml-feedback@google.com.
Menggunakan model pembuatan teks
Setelah membuat model jarak jauh, Anda dapat menggunakan
fungsi ML.GENERATE_TEXT
untuk berinteraksi dengan model tersebut:
- Untuk model jarak jauh berdasarkan model Gemini 1.5 atau 2.0,
Anda dapat menggunakan fungsi
ML.GENERATE_TEXTuntuk menganalisis konten teks, gambar, audio, video, atau PDF dari tabel objek dengan perintah yang Anda berikan sebagai argumen fungsi, atau Anda dapat membuat teks dari perintah yang Anda berikan dalam kueri atau dari kolom dalam tabel standar. - Untuk model jarak jauh berdasarkan model
gemini-1.0-pro-vision, Anda dapat menggunakan fungsiML.GENERATE_TEXTuntuk menganalisis konten gambar atau video dari tabel objek dengan perintah yang Anda berikan sebagai argumen fungsi. - Untuk semua jenis model jarak jauh lainnya, Anda dapat menggunakan fungsi
ML.GENERATE_TEXTdengan perintah yang Anda berikan dalam kueri atau dari kolom dalam tabel standar.
Anda dapat menggunakan
grounding
dan
atribut keamanan
saat menggunakan model Gemini dengan fungsi ML.GENERATE_TEXT,
asalkan Anda menggunakan tabel standar untuk input. Dengan mereferensikan,
model Gemini dapat menggunakan informasi tambahan dari internet untuk
menghasilkan respons yang lebih spesifik dan faktual. Atribut keamanan memungkinkan
model Gemini memfilter respons yang ditampilkannya berdasarkan
atribut yang Anda tentukan.
Saat membuat model jarak jauh yang mereferensikan salah satu model berikut, Anda dapat memilih untuk mengonfigurasi penyesuaian terpantau secara bersamaan:
gemini-1.5-pro-002gemini-1.5-flash-002gemini-1.0-pro-002(Pratinjau)
Semua inferensi terjadi di Vertex AI. Hasilnya disimpan di BigQuery.
Gunakan topik berikut untuk mencoba pembuatan teks di BigQuery ML:
- Buat teks menggunakan model Gemini dan fungsi
ML.GENERATE_TEXT. - Menganalisis gambar dengan model visi Gemini.
- Buat teks menggunakan fungsi
ML.GENERATE_TEXTdengan data Anda. - Menyesuaikan model menggunakan data Anda.
- Buat teks menggunakan model
text-bisondan fungsiML.GENERATE_TEXT. generation
Embedding
Embedding adalah vektor numerik berdimensi tinggi yang mewakili entity tertentu, seperti teks atau file audio. Membuat penyematan memungkinkan Anda menangkap semantik data dengan cara yang memudahkan untuk memahami dan membandingkan data.
Beberapa kasus penggunaan umum untuk pembuatan penyematan adalah sebagai berikut:
- Menggunakan retrieval-augmented generation (RAG) untuk meningkatkan respons model terhadap kueri pengguna dengan mereferensikan data tambahan dari sumber tepercaya. RAG memberikan akurasi faktual dan konsistensi respons yang lebih baik, serta memberikan akses ke data yang lebih baru daripada data pelatihan model.
- Melakukan penelusuran multimodal. Misalnya, menggunakan input teks untuk menelusuri gambar.
- Melakukan penelusuran semantik untuk menemukan item serupa untuk rekomendasi, penggantian, dan penghapusan duplikat data.
- Membuat penyematan untuk digunakan dengan model k-means untuk pengelompokan.
Model yang didukung
Model berikut didukung:
- Untuk membuat embedding teks, Anda dapat menggunakan model
text-embeddingdantext-multilingual-embeddingVertex AI. - Untuk membuat embedding multimodal, yang dapat menyematkan teks, gambar, dan video ke dalam
ruang semantik yang sama, Anda dapat menggunakan model
multimodalembeddingVertex AI. - Untuk membuat penyematan data variabel acak independen dan terdistribusi identik (IID) terstruktur, Anda dapat menggunakan model Analisis komponen utama (PCA) BigQuery ML atau model Autoencoder.
- Untuk membuat penyematan data pengguna atau item, Anda dapat menggunakan model Faktorisasi matriks BigQuery ML.
Untuk penyematan teks yang lebih kecil dan ringan, coba gunakan model TensorFlow yang telah dilatih sebelumnya, seperti NNLM, SWIVEL, atau BERT.
Menggunakan model pembuatan penyematan
Setelah membuat model, Anda dapat menggunakan
fungsi ML.GENERATE_EMBEDDING
untuk berinteraksi dengannya. Untuk semua jenis model yang didukung, ML.GENERATE_EMBEDDING
berfungsi dengan data dalam
tabel standar. Untuk model
penyematan multimodal, ML.GENERATE_EMBEDDING juga berfungsi dengan konten
visual di tabel objek.
Untuk model jarak jauh, semua inferensi terjadi di Vertex AI. Untuk jenis model lainnya, semua inferensi terjadi di BigQuery. Hasilnya disimpan di BigQuery.
Gunakan topik berikut untuk mencoba pembuatan teks di BigQuery ML:
- Membuat penyematan teks menggunakan fungsi
ML.GENERATE_EMBEDDING - Membuat penyematan gambar menggunakan fungsi
ML.GENERATE_EMBEDDING - Membuat penyematan video menggunakan fungsi
ML.GENERATE_EMBEDDING - Membuat dan menelusuri embedding multimodal
- Melakukan penelusuran semantik dan retrieval-augmented generation
Harga
Anda akan ditagih untuk resource komputasi yang digunakan untuk menjalankan kueri terhadap model. Model jarak jauh melakukan panggilan ke model Vertex AI, sehingga kueri terhadap model jarak jauh juga dikenai biaya dari Vertex AI.
Untuk informasi selengkapnya, lihat Harga BigQuery ML.
Langkah berikutnya
- Untuk informasi selengkapnya tentang cara melakukan inferensi pada model machine learning, lihat Ringkasan inferensi model.