Tabellenaktualisierungen mit Change Data Capture streamen
BigQuery Change Data Capture (CDC) aktualisiert Ihre BigQuery-Tabellen durch Verarbeitung und Anwendung von gestreamten Änderungen auf vorhandene Daten. Diese Synchronisierung wird durch Upsert- und Löschzeilenvorgänge erreicht, die in Echtzeit von der BigQuery Storage Write API gestreamt werden, mit der Sie vertraut sein sollten, bevor Sie fortfahren.
Hinweis
Erteilen Sie IAM-Rollen (Identity and Access Management), die Nutzern die erforderlichen Berechtigungen zum Ausführen der einzelnen Aufgaben in diesem Dokument geben und dafür sorgen, dass Ihr Workflow alle Voraussetzungen erfüllt.
Erforderliche Berechtigungen
Bitten Sie Ihren Administrator, Ihnen die IAM-Rolle BigQuery Data Editor (roles/bigquery.dataEditor) zu gewähren, um die Berechtigung zu erhalten, die Sie zur Verwendung der Storage Write API benötigen.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff verwalten.
Diese vordefinierte Rolle enthält die Berechtigung bigquery.tables.updateData, die für die Verwendung der Storage Write API erforderlich ist.
Sie können diese Berechtigung auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Einführung in IAM.
Vorbereitung
Zur Verwendung von BigQuery CDC muss Ihr Workflow die folgenden Bedingungen erfüllen:
- Sie müssen die Storage Write API im Standardstream verwenden.
- Sie müssen Primärschlüssel für die Zieltabelle in BigQuery deklarieren. Zusammengesetzte Primärschlüssel mit bis zu 16 Spalten werden unterstützt.
- Ausreichende BigQuery-Rechenressourcen müssen für die CDC-Zeilenvorgänge verfügbar sein. Wenn Operationen zur CDC-Zeilenänderung fehlschlagen, können Sie unbeabsichtigt Daten behalten, die Sie löschen möchten. Weitere Informationen finden Sie unter Überlegungen zu gelöschten Daten.
Änderungen an vorhandenen Einträgen angeben
In BigQuery CDC gibt die Pseudospalte _CHANGE_TYPE die Art der Änderung an, die für jede Zeile verarbeitet werden soll. Wenn Sie CDC verwenden möchten, legen Sie _CHANGE_TYPE fest, wenn Sie Zeilenänderungen mit der Storage Write API streamen. Die Pseudospalte _CHANGE_TYPE akzeptiert nur die Werte UPSERT und DELETE.
Eine Tabelle gilt als CDC-aktiviert, während die Storage Write API Zeilenänderungen an der Tabelle auf diese Weise streamt.
Beispiel mit den Werten UPSERT und DELETE
Sehen Sie sich die folgende Tabelle in BigQuery an:
| ID | Name | Gehalt |
|---|---|---|
| 100 | Rechnung | 2000 |
| 101 | Lucy | 3.000 |
| 102 | Ethan | 5.000 |
Die folgenden Zeilenänderungen werden von der Storage Write API gestreamt:
| ID | Name | Gehalt | _CHANGE_TYPE |
|---|---|---|---|
| 100 | LÖSCHEN | ||
| 101 | Lucy | 8.000 | UPSERT |
| 105 | Max. | 6000 | UPSERT |
Die aktualisierte Tabelle sieht jetzt so aus:
| ID | Name | Gehalt |
|---|---|---|
| 101 | Lucy | 8.000 |
| 102 | Ethan | 5.000 |
| 105 | Max. | 6000 |
Tabellenveralterung verwalten
Standardmäßig gibt BigQuery bei jeder Abfrage die aktuellsten Ergebnisse zurück. Um beim Abfragen einer CDC-fähigen Tabelle die aktuellsten Ergebnisse bereitzustellen, muss BigQuery jede gestreamte Zeilenänderung bis zur Startzeit der Abfrage anwenden, damit die aktuellste Version der Tabelle abgefragt wird. Wenn Sie diese Zeilenänderungen zum Zeitpunkt der Abfrage anwenden, erhöhen sich die Abfragelatenz und die Kosten. Wenn Sie jedoch keine vollständigen aktuellen Abfrageergebnisse benötigen, können Sie die Kosten und die Latenz Ihrer Abfragen reduzieren. Legen Sie dazu die Option max_staleness für Ihre Tabelle fest. Wenn diese Option festgelegt ist, wendet BigQuery Zeilenänderungen mindestens einmal innerhalb des durch den Wert max_staleness definierten Intervalls an, sodass Sie Abfragen ausführen können, ohne auf die Anwendung von Aktualisierungen warten zu müssen, was aber zu einigen veralteten Daten führen kann.
Dieses Verhalten ist besonders nützlich bei Dashboards und Berichten, bei denen die Datenaktualität nicht wichtig ist. Dies ist auch bei der Kostenverwaltung hilfreich, da Sie besser steuern können, wie häufig BigQuery Zeilenänderungen anwendet.
Tabellen mit der Option max_staleness abfragen
Wenn Sie eine Tabelle mit festgelegter Option max_staleness abfragen, gibt BigQuery das Ergebnis basierend auf dem Wert von max_staleness und der Zeit zurück, zu der der letzte Anwendungsjob aufgetreten ist, was durch den Zeitstempel upsert_stream_apply_watermark der Tabelle dargestellt wird.
Betrachten Sie das folgende Beispiel, bei dem für eine Tabelle die Option max_staleness auf 10 Minuten festgelegt ist und der letzte Anwendungsjob um T20 ausgeführt wurde:
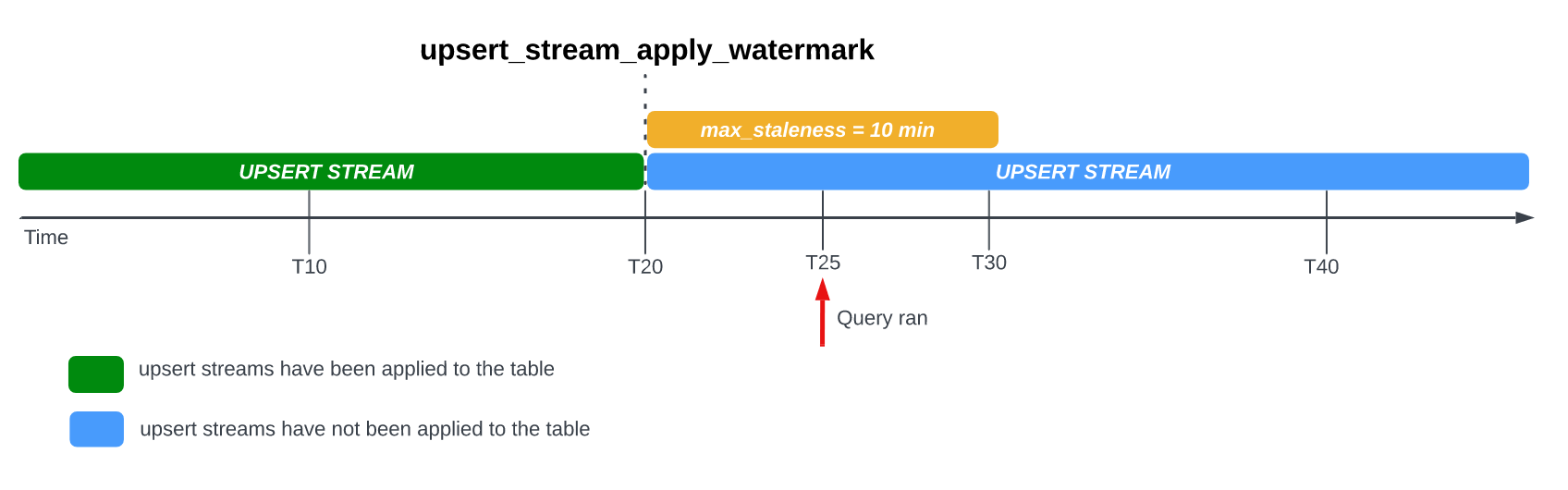
Wenn Sie die Tabelle bei T25 abfragen, ist die aktuelle Version der Tabelle 5 Minuten veraltet. Dies ist kleiner als das Intervall max_staleness von 10 Minuten. In diesem Fall gibt BigQuery die Version der Tabelle bei T20 zurück, was bedeutet, dass die zurückgegebenen Daten auch 5 Minuten veraltet sind.
Wenn Sie die Option max_staleness für Ihre Tabelle festlegen, wendet BigQuery ausstehende Zeilenänderungen mindestens einmal innerhalb des Intervalls max_staleness an. In einigen Fällen kann BigQuery den Vorgang der Anwendung dieser ausstehenden Zeilenänderungen jedoch innerhalb des Intervalls nicht abschließen.
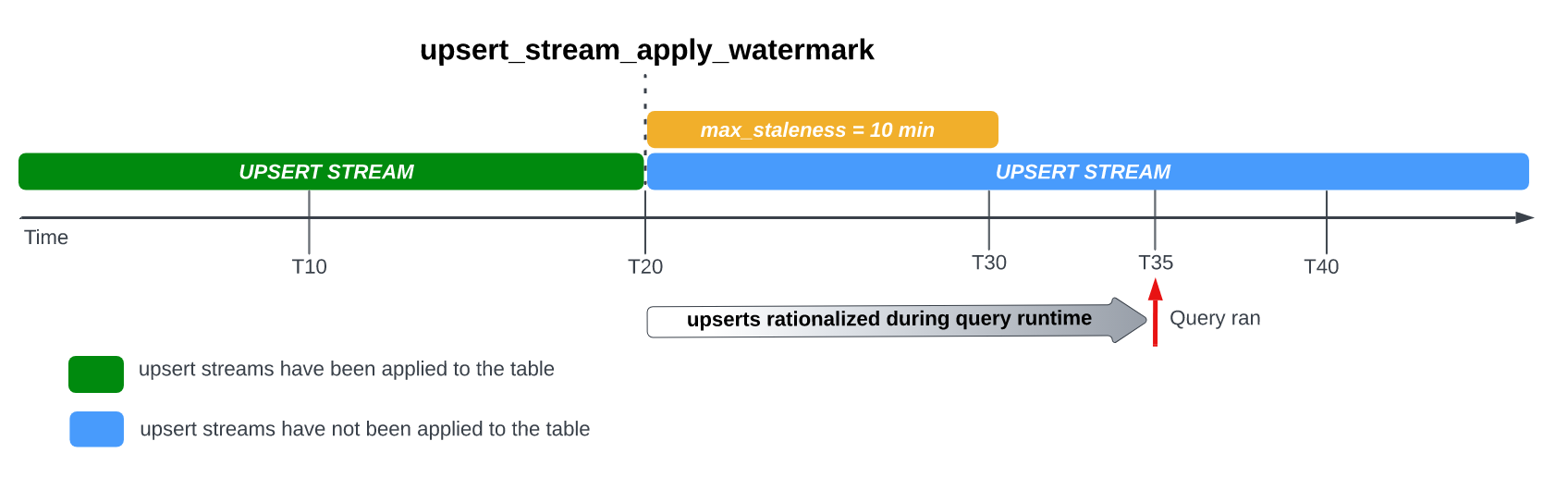
Wenn Sie die Tabelle beispielsweise bei T35 abfragen und der Vorgang zum Anwenden ausstehender Zeilenänderungen noch nicht abgeschlossen ist, ist die aktuelle Version der Tabelle 15 Minuten veraltet, was länger ist als das Intervall max_staleness von 10 Minuten.
In diesem Fall wendet BigQuery zum Zeitpunkt der Abfrage alle Zeilenänderungen zwischen T20 und T35 für die aktuelle Abfrage an, was bedeutet, dass die abgefragten Daten auf Kosten einer zusätzlichen Abfragelatenz auf dem neuesten Stand sind.
Dies wird als Laufzeitzusammenführungsjob betrachtet.
Empfohlener max_staleness-Tabellenwert
Der Wert max_staleness einer Tabelle sollte im Allgemeinen der höhere der folgenden beiden Werte sein:
- Die maximal zulässige Veralterung des Workflows.
- Verdoppeln Sie die maximale Zeit, die für das Anwenden von per Upsert aktualisierten Änderungen auf Ihre Tabelle benötigt wird, und fügen Sie einen zusätzlichen Puffer hinzu.
Um die Zeit zu berechnen, die Sie zum Anwenden von Upsert-Aktualisierungen auf eine vorhandene Tabelle benötigen, verwenden Sie die folgende SQL-Abfrage, um die Dauer des 95. Perzentils der Hintergrundanwendungsjobs zu bestimmen, und fügen Sie einen siebenminütigen Puffer hinzu, um die Konvertierung des schreiboptimierten BigQuery-Speichers (Streaming-Zwischenspeicher) zu ermöglichen.
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-us`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
Ersetzen Sie dabei PROJECT_ID durch die ID des Projekts, das die BigQuery-Tabellen enthält, die von BigQuery CDC geändert werden.
Die Dauer von Hintergrundjobs kann von mehreren Faktoren beeinflusst werden, einschließlich der Anzahl und Komplexität der CDC-Vorgänge, die innerhalb des Veralterungsintervalls ausgegeben werden, der Tabellengröße und der Verfügbarkeit von BigQuery-Ressourcen. Weitere Informationen zur Ressourcenverfügbarkeit finden Sie unter Größe von BACKGROUND-Reservierungen festlegen und überwachen.
Erstellen Sie eine Tabelle mit der Option max_staleness
Zum Erstellen einer Tabelle mit der Option max_staleness verwenden Sie die Anweisung CREATE TABLE.
Im folgenden Beispiel wird die Tabelle employees mit einem max_staleness-Limit von 10 Minuten erstellt:
CREATE TABLE employees (
id INT64 PRIMARY KEY NOT ENFORCED,
name STRING)
CLUSTER BY
id
OPTIONS (
max_staleness = INTERVAL 10 MINUTE);
Option max_staleness für eine vorhandene Tabelle ändern
Mit der Anweisung ALTER TABLE können Sie ein max_staleness-Limit in einer vorhandenen Tabelle hinzufügen oder ändern.
Das folgende Beispiel ändert das max_staleness-Limit der Tabelle employees auf 15 Minuten:
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
Aktuellen max_staleness-Wert einer Tabelle ermitteln
Fragen Sie die Ansicht INFORMATION_SCHEMA.TABLE_OPTIONS ab, um den aktuellen max_staleness-Wert einer Tabelle zu ermitteln.
Im folgenden Beispiel wird der aktuelle max_staleness-Wert der Tabelle mytable geprüft:
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
Ersetzen Sie Folgendes:
DATASET_NAME: der Name des Datasets, in dem sich die CDC-fähige Tabelle befindet.TABLE_NAME: der Name der CDC-fähigen Tabelle.
Aus den Ergebnissen geht hervor, dass der max_staleness-Wert 10 Minuten beträgt:
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
Fortschritt des Tabellen-Upsert-Vorgangs überwachen
Wenn Sie den Status einer Tabelle überwachen und prüfen möchten, wann Zeilenänderungen zuletzt angewendet wurden, fragen Sie die Ansicht INFORMATION_SCHEMA.TABLES ab, um den Zeitstempel upsert_stream_apply_watermark zu erhalten.
Im folgenden Beispiel wird der upsert_stream_apply_watermark-Wert der Tabelle mytable geprüft:
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
Ersetzen Sie Folgendes:
DATASET_NAME: der Name des Datasets, in dem sich die CDC-fähige Tabelle befindet.TABLE_NAME: der Name der CDC-fähigen Tabelle.
Das Ergebnis sieht etwa so aus:
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
Upsert-Vorgänge werden vom Dienstkonto bigquery-adminbot@system.gserviceaccount.com ausgeführt und im Jobverlauf des Projekts angezeigt, das die CDC-fähige Tabelle enthält.
Benutzerdefinierte Sortierung verwalten
Beim Streaming von Upserts in BigQuery wird das Standardverhalten der Sortierung von Datensätzen mit identischen Primärschlüsseln durch die BigQuery-Systemzeit bestimmt, zu der der Datensatz in BigQuery aufgenommen wurde. Anders ausgedrückt: Der Datensatz, der zuletzt mit dem neuesten Zeitstempel aufgenommen wurde, hat Vorrang vor dem Datensatz, der zuvor mit einem älteren Zeitstempel aufgenommen wurde. Für bestimmte Anwendungsfälle, z. B. wenn sehr häufige Upserts für denselben Primärschlüssel innerhalb eines sehr kurzen Zeitfensters erfolgen können oder bei denen die Upsert-Reihenfolge nicht garantiert ist, reicht dies möglicherweise nicht aus. In diesen Szenarien ist möglicherweise ein vom Nutzer bereitgestellter Reihenfolgeschlüssel erforderlich.
Zum Konfigurieren von Sortierschlüsseln, die vom Nutzer bereitgestellt werden, wird mit der Pseudospalte _CHANGE_SEQUENCE_NUMBER die Reihenfolge angegeben, in der BigQuery Datensätze anwenden soll. Diese basieren auf dem größeren _CHANGE_SEQUENCE_NUMBER zwischen zwei übereinstimmenden Datensätzen mit demselben Primärschlüssel. Die Pseudospalte _CHANGE_SEQUENCE_NUMBER ist eine optionale Spalte und akzeptiert nur Werte im festen Format STRING.
Format: _CHANGE_SEQUENCE_NUMBER
Die Pseudospalte _CHANGE_SEQUENCE_NUMBER akzeptiert nur STRING-Werte, die in einem festen Format geschrieben sind. Dieses feste Format verwendet STRING-Werte, die in Hexadezimalform geschrieben sind und durch einen Schrägstrich / in Abschnitte getrennt sind. Jeder Abschnitt kann mit höchstens 16 Hexadezimalzeichen ausgedrückt werden. Pro _CHANGE_SEQUENCE_NUMBER sind bis zu vier Abschnitte zulässig. Der zulässige Bereich von _CHANGE_SEQUENCE_NUMBER unterstützt Werte zwischen 0/0/0/0 und FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF.
_CHANGE_SEQUENCE_NUMBER-Werte unterstützen sowohl Groß- als auch Kleinbuchstaben.
Die Darstellung grundlegender Sortierschlüssel kann über einen einzelnen Abschnitt erfolgen. Wenn Sie beispielsweise Schlüssel ausschließlich basierend auf dem Verarbeitungszeitstempel eines Anwendungsservers sortieren möchten, können Sie einen Abschnitt verwenden: '2024-04-30 11:19:44 UTC', hexadezimal angegeben als durch Konvertierung des Zeitstempels in die Millisekunden der Epoche. '18F2EBB6480' in diesem Fall. Die Logik zum Konvertieren von Daten in Hexadezimalzahlen liegt in der Verantwortung des Clients, der den Schreibvorgang in BigQuery mithilfe der Storage Write API ausführt.
Durch die Unterstützung mehrerer Abschnitte können Sie mehrere Verarbeitungslogik-Werte für komplexere Anwendungsfälle in einem Schlüssel kombinieren. Wenn Sie beispielsweise Schlüssel basierend auf dem Verarbeitungszeitstempel eines Eintrags von einem Anwendungsserver, einer Logsequenznummer und dem Status des Eintrags sortieren möchten, können Sie drei Abschnitte verwenden: '2024-04-30 11:19:44 UTC' / '123' / 'complete', jeweils hexadezimal angegeben.
Die Reihenfolge der Abschnitte ist ein wichtiger Aspekt für das Ranking der Verarbeitungslogik. BigQuery vergleicht _CHANGE_SEQUENCE_NUMBER-Werte. Dazu wird der erste Abschnitt verglichen und dann der nächste Abschnitt nur dann verglichen, wenn die vorherigen Abschnitte gleich waren.
BigQuery verwendet _CHANGE_SEQUENCE_NUMBER, um durch den Vergleich von zwei oder mehr _CHANGE_SEQUENCE_NUMBER-Feldern als vorzeichenlose numerische Werte eine Sortierung durchzuführen. Sehen Sie sich die folgenden _CHANGE_SEQUENCE_NUMBER-Vergleichsbeispiele und ihre Prioritätsergebnisse an:
Beispiel 1:
- Datensatz Nr. 1:
_CHANGE_SEQUENCE_NUMBER= '77' - Datensatz Nr. 2:
_CHANGE_SEQUENCE_NUMBER= '7B'
Ergebnis: Datensatz Nr. 2 wird als neuester Datensatz betrachtet, da „7B“ > „77“ (d. h. „123“ > „119“)
- Datensatz Nr. 1:
Beispiel 2:
- Datensatz Nr. 1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/B' - Datensatz Nr. 2:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC'
Ergebnis: Datensatz Nr. 2 wird als der neueste Datensatz betrachtet, da „FFF/ABC“ > „FFF/B“ (d. h. „4095/2748“ > „4095/11“)
- Datensatz Nr. 1:
3. Beispiel:
- Datensatz Nr. 1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - Datensatz Nr. 2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
Ergebnis: Datensatz Nr. 2 wird als der neueste Datensatz betrachtet, da „ABC“ > „BA/FFFFFFFF“ (d. h. „2748“ > „186/4294967295“)
- Datensatz Nr. 1:
4. Beispiel:
- Datensatz Nr. 1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC' - Datensatz Nr. 2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
Ergebnis: Datensatz Nr. 1 wird als der neueste Datensatz betrachtet, da „FFF/ABC“ > „ABC“ (d. h. „4095/2748“ > „2748“)
- Datensatz Nr. 1:
Wenn zwei _CHANGE_SEQUENCE_NUMBER-Werte identisch sind, hat der Eintrag mit der neuesten BigQuery-Systemaufnahmezeit Vorrang vor zuvor aufgenommenen Einträgen.
BigQuery-Reservierung für die Verwendung mit CDC konfigurieren
Sie können BigQuery-Reservierungen verwenden, um dedizierte BigQuery-Rechenressourcen für CDC-Zeilenänderungsvorgänge zuzuweisen. Mit Reservierungen können Sie die Kosten für die Ausführung dieser Vorgänge begrenzen. Dieser Ansatz ist besonders für Workflows mit häufigen CDC-Vorgängen für große Tabellen nützlich, die aufgrund der großen Anzahl von verarbeiteten Byte bei jedem Vorgang andernfalls hohe On-Demand-Kosten verursachen würden.
BigQuery-CDC-Jobs, die ausstehende Zeilenänderungen innerhalb des max_staleness-Intervalls anwenden, werden als Hintergrundjobs betrachtet und nutzen den Zuweisungstyp BACKGROUND anstelle des Zuweisungstyps QUERY.
Im Gegensatz dazu nutzen Abfragen außerhalb des Intervalls max_staleness, bei denen Zeilenänderungen zum Zeitpunkt der Abfrageausführung angewendet werden müssen, den Zuweisungstyp QUERY.
BigQuery CDC-Hintergrundjobs, die ohne BACKGROUND-Zuweisung ausgeführt werden, nutzen On-Demand-Preise.
Diese Überlegungen sind wichtig, wenn Sie Ihre Strategie zur Arbeitslastverwaltung für BigQuery CDC entwerfen.
Zum Konfigurieren einer BigQuery-Reservierung für die Verwendung mit CDC beginnen Sie mit dem Kaufen einer Kapazitätszusicherung und konfigurieren eine Reservierung in der Region, in der sich Ihre BigQuery-Tabellen befinden. Eine Anleitung zum Umfang der Reservierung finden Sie unter Größe von BACKGROUND-Reservierungen festlegen und überwachen.
Nachdem Sie eine Reservierung erstellt haben, weisen Sie das BigQuery-Projekt der Reservierung zu und setzen Sie die Option job_type auf BACKGROUND. Führen Sie dazu die folgende CREATE ASSIGNMENT-Anweisung aus:
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
Dabei gilt:
ADMIN_PROJECT_ID: Die ID des Administrationsprojekts, dem die Reservierung gehört.LOCATION: Der Standort der Reservierung.RESERVATION_NAME: Der Name der Reservierung.ASSIGNMENT_ID: Die ID der Zuweisung. Die ID muss für das Projekt und den Standort eindeutig sein, mit einem Kleinbuchstaben oder einer Zahl beginnen und enden und darf nur Kleinbuchstaben, Zahlen und Bindestriche enthalten.PROJECT_ID: Die ID des Projekts, das die BigQuery-Tabellen enthält, die von BigQuery CDC geändert werden. Dieses Projekt wird der Reservierung zugewiesen.
Größe von BACKGROUND-Reservierungen festlegen und überwachen
Reservierungen bestimmen die Menge der Rechenressourcen, die zum Ausführen von BigQuery-Computing-Vorgängen verfügbar sind. Eine zuklein ausgelegte Reservierung kann die Verarbeitungszeit von CDC-Zeilenänderungsvorgängen erhöhen. Wenn Sie die Größe einer Reservierung genau steuern möchten, überwachen Sie den bisherigen Slot-Verbrauch für das Projekt, in dem die CDC-Vorgänge ausgeführt werden. Fragen Sie dazu die Ansicht INFORMATION_SCHEMA.JOBS_TIMELINE ab:
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
Ersetzen Sie REGION durch den Regionsnamen, in dem sich Ihr Projekt befindet. Beispiel: region-us.
Überlegungen zu gelöschten Daten
- BigQuery CDC-Vorgänge nutzen BigQuery-Rechenressourcen. Wenn die CDC-Vorgänge für die Verwendung der On-Demand-Abrechnung konfiguriert sind, werden CDC-Vorgänge regelmäßig mit internen BigQuery-Ressourcen ausgeführt. Wenn die CDC-Vorgänge mit einer
BACKGROUND-Reservierung konfiguriert sind, unterliegen CDC-Vorgänge stattdessen der Ressourcenverfügbarkeit der konfigurierten Reservierung. Wenn in der konfigurierten Reservierung nicht genügend Ressourcen verfügbar sind, kann die Verarbeitung von CDC-Vorgängen, einschließlich des Löschens, länger als erwartet dauern. - Ein CDC-Vorgang
DELETEgilt nur dann, wenn der Zeitstempelupsert_stream_apply_watermarkden Zeitstempel übergeben hat, zu dem die Storage Write API den Vorgang gestreamt hat. Weitere Informationen zum Zeitstempelupsert_stream_apply_watermarkfinden Sie unter Fortschritt beim Tabellenaktualisierungsvorgang überwachen. - Für die Anwendung von CDC-
DELETE-Vorgängen, die in der falschen Reihenfolge eingehen, hat BigQuery ein Aufbewahrungsfenster von zwei Tagen. Tabellen-DELETE-Vorgänge werden für diesen Zeitraum gespeichert, bevor der standardmäßige Löschvorgang der Google Cloud-Daten beginnt. FürDELETE-Vorgänge innerhalb des Zeitfensters für die Aufbewahrung werden die Standardpreise für BigQuery-Speicher verwendet.
Beschränkungen
- Da BigQuery CDC keine Schlüsselerzwingung durchführt, müssen Ihre Primärschlüssel eindeutig sein.
- Primärschlüssel dürfen 16 Spalten nicht überschreiten.
- Für CDC aktivierte Tabellen dürfen nicht mehr als 2.000 Spalten der obersten Ebene haben,die durch das Schema der Tabelle definiert sind.
- CDC-fähige Tabellen unterstützen Folgendes nicht:
- Mutieren von DML-Anweisungen (Datenbearbeitungssprache)-wie
DELETE,UPDATEundMERGE - Platzhaltertabellen abfragen
- Suchindexe
- Mutieren von DML-Anweisungen (Datenbearbeitungssprache)-wie
- CDC-fähige Tabellen, die Laufzeitzusammenführungsjobs ausführen, da der
max_staleness-Wert der Tabelle zu niedrig ist, können Folgendes nicht unterstützen: - BigQuery-Exportvorgänge für CDC-fähige Tabellen exportieren keine kürzlich gestreamten Zeilenänderungen, die noch von einem Hintergrundjob angewendet werden müssen. Verwenden Sie zum Exportieren der vollständigen Tabelle eine
EXPORT DATA-Anweisung. - Wenn Ihre Abfrage eine Laufzeitzusammenführung für eine partitionierte Tabelle auslöst, wird die gesamte Tabelle gescannt, unabhängig davon, ob die Abfrage auf eine Teilmenge der Partitionen beschränkt ist.
- Wenn Sie die Standard Edition nutzen, stehen
BACKGROUND-Reservierungen nicht zur Verfügung. Das Anwenden von ausstehenden Zeilenänderungen verwendet daher das On-Demand-Preismodell. Sie können jedoch CDC-fähige Tabellen unabhängig von Ihrer Version abfragen. - Die Pseudospalten
_CHANGE_TYPEund_CHANGE_SEQUENCE_NUMBERsind beim Lesen einer Tabelle keine abfragbaren Spalten.
BigQuery CDC – Preise
BigQuery CDC verwendet die Storage Write API für die Datenaufnahme, den BigQuery-Speicher für die Datenspeicherung und den BigQuery-Computer für Zeilenänderungsvorgänge. Dies alles verursacht Kosten. Preisinformationen finden Sie unter BigQuery-Preise.
Kosten für BigQuery CDC schätzen
Zusätzlich zu den Best Practices für die allgemeine Kostenschätzung von BigQuery kann die Schätzung der Kosten von BigQuery CDC für Workflows wichtig sein, die große Datenmengen, eine niedrige max_staleness-Konfiguration oder häufig wechselnde Daten enthalten.
Die Preise für die BigQuery-Datenaufnahme und die BigQuery-Speicherpreise werden direkt anhand der Datenmenge berechnet, die Sie aufnehmen und speichern, einschließlich Pseudospalten. Die BigQuery-Computing-Preise sind jedoch möglicherweise schwieriger zu schätzen, da sie sich auf den Verbrauch von Rechenressourcen beziehen, die zum Ausführen von BigQuery CDC-Jobs verwendet werden.
BigQuery CDC-Jobs sind in drei Kategorien unterteilt:
- Hintergrundanwendungsjobs: Jobs, die in regelmäßigen Intervallen im Hintergrund ausgeführt werden und den
max_staleness-Wert der Tabelle definieren. Diese Jobs wenden kürzlich gestreamte Zeilenänderungen auf die Tabelle an, in der CDC aktiviert ist. - Abfragejobs: GoogleSQL-Abfragen, die im Fenster
max_stalenessausgeführt werden und nur aus der CDC-Baseline-Tabelle lesen. - Runtime-Merge-Jobs: Jobs, die von Ad-hoc-GoogleSQL-Abfragen ausgelöst werden, die außerhalb des Fensters
max_stalenessausgeführt werden. Diese Jobs müssen die CDC-Baseline-Tabelle und die kürzlich gestreamten Zeilenänderungen bei der Abfragelaufzeit direkt zusammenführen.
Alle drei Arten von BigQuery-CDC-Jobs nutzen das BigQuery-Clustering, aber nur Abfragejobs nutzen die BigQuery-Partitionierung. Hintergrundanwendungsjobs und Laufzeitzusammenführungsjobs können keine Partitionierung verwenden, da bei Anwendung von kürzlich gestreamten Zeilenänderungen nicht garantiert wird, auf welche Tabellenpartition die kürzlich gestreamten Upserts angewendet werden. Mit anderen Worten: Die vollständige Referenztabelle wird während der Anwendung von Jobs im Hintergrund und während der Laufzeit gelesen. Das Verständnis der Menge an Daten, die zum Ausführen von CDC-Vorgängen gelesen werden, ist hilfreich, um die Gesamtkosten zu schätzen.
Wenn die aus der Tabellenreferenz gelesene Datenmenge hoch ist, sollten Sie das BigQuery-Kapazitätspreismodell verwenden, das nicht auf der Menge der verarbeiteten Daten basiert.
Best Practices für BigQuery CDC
Zusätzlich zu den Best Practices für BigQuery-Kosten können Sie die Kosten für BigQuery-CDC-Vorgänge mit den folgenden Methoden optimieren:
- Vermeiden Sie es gegebenenfalls, die Option
max_stalenesseiner Tabelle mit einem sehr niedrigen Wert zu konfigurieren. Der Wertmax_stalenesskann das Vorkommen von Hintergrundjob- und Laufzeitzusammenführungsjobs erhöhen. Diese sind teurer und langsamer als Abfragejobs. Eine ausführliche Anleitung finden Sie unter Empfohlener Wert für die Tabellemax_staleness. - Sie können eine BigQuery-Reservierung zur Verwendung mit CDC-Tabellen konfigurieren.
Andernfalls werden für Jobs im Hintergrund und für Laufzeitausführungen On-Demand-Preise verwendet, die aufgrund von mehr Datenverarbeitung kostspieliger sein können. Weitere Informationen finden Sie unter BigQuery-Reservierungen und Anleitung zum Dimensionieren und Überwachen einer
BACKGROUND-Reservierung zur Verwendung mit BigQuery CDC.
Nächste Schritte
- Storage Write API-Standardstream implementieren
- Best Practices für die Storage Write API
- Mit BigQuery CDC Transaktionsdatenbanken mit Datastream in BigQuery replizieren.