Carregue dados do Blob Storage para o BigQuery
Pode carregar dados do Blob Storage para o BigQuery através do conetor do Serviço de transferência de dados do BigQuery para o Blob Storage. Com o Serviço de transferência de dados do BigQuery, pode agendar tarefas de transferência recorrentes que adicionam os seus dados mais recentes do Blob Storage ao BigQuery.
Antes de começar
Antes de criar uma transferência de dados do Blob Storage, faça o seguinte:
- Verifique se concluiu todas as ações necessárias para ativar o Serviço de transferência de dados do BigQuery.
- Escolha um conjunto de dados do BigQuery existente ou crie um novo conjunto de dados para armazenar os seus dados.
- Escolha uma tabela do BigQuery existente ou crie uma nova tabela de destino para a transferência de dados e especifique a definição do esquema. A tabela de destino tem de seguir as regras de nomenclatura de tabelas. Os nomes das tabelas de destino também suportam parâmetros.
- Obtenha o nome da conta de armazenamento do Blob Storage, o nome do contentor, o caminho dos dados (opcional) e o token SAS. Para ver informações sobre como conceder acesso ao Blob Storage através de uma assinatura de acesso partilhado (SAS), consulte o artigo Assinatura de acesso partilhado (SAS).
- Se restringir o acesso aos seus recursos do Azure através de uma firewall do Azure Storage, adicione trabalhadores do Serviço de transferência de dados do BigQuery à sua lista de IPs permitidos.
- Se planeia especificar uma chave de encriptação gerida pelo cliente (CMEK), certifique-se de que a sua conta de serviço tem autorizações para encriptar e desencriptar e que tem o ID de recurso da chave do Cloud KMS necessário para usar a CMEK. Para obter informações sobre como a CMEK funciona com o Serviço de transferência de dados do BigQuery, consulte o artigo Especifique a chave de encriptação com transferências.
Autorizações necessárias
Certifique-se de que concedeu as seguintes autorizações.
Funções do BigQuery necessárias
Para receber as autorizações de que precisa para criar uma transferência de dados do Serviço de transferência de dados do BigQuery,
peça ao seu administrador para lhe conceder a função do IAM de
administrador do BigQuery (roles/bigquery.admin) no seu projeto.
Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.
Esta função predefinida contém as autorizações necessárias para criar uma transferência de dados do Serviço de transferência de dados do BigQuery. Para ver as autorizações exatas que são necessárias, expanda a secção Autorizações necessárias:
Autorizações necessárias
São necessárias as seguintes autorizações para criar uma transferência de dados do Serviço de transferência de dados do BigQuery:
-
Autorizações do Serviço de transferência de dados do BigQuery:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
Autorizações do BigQuery:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
Também pode conseguir estas autorizações com funções personalizadas ou outras funções predefinidas.
Para mais informações, consulte o artigo Conceda acesso ao bigquery.admin.
Funções de armazenamento de blobs necessárias
Para obter informações sobre as autorizações necessárias no armazenamento de blobs para ativar a transferência de dados, consulte o artigo Assinatura de acesso partilhado (SAS).
Limitações
As transferências de dados do Armazenamento de blobs estão sujeitas às seguintes limitações:
- O intervalo de tempo mínimo entre transferências de dados recorrentes é de 1 hora. O intervalo predefinido é de 24 horas.
- Consoante o formato dos dados de origem do armazenamento de blobs, podem existir limitações adicionais:
- As transferências de dados para localizações do BigQuery Omni não são suportadas.
Configure uma transferência de dados do Blob Storage
Selecione uma das seguintes opções:
Consola
Aceda à página Transferências de dados na Google Cloud consola.
Clique em Criar transferência.
Na página Criar transferência, faça o seguinte:
Na secção Tipo de origem, para Origem, selecione Azure Blob Storage e ADLS:
Na secção Nome da configuração de transferência, em Nome a apresentar, introduza um nome para a transferência de dados.
Na secção Opções de programação:
- Selecione uma Frequência de repetição. Se selecionar Horas, Dias, Semanas ou Meses, também tem de especificar uma frequência. Também pode selecionar Personalizado para especificar uma frequência de repetição personalizada. Se selecionar A pedido, esta transferência de dados é executada quando aciona manualmente a transferência.
- Se aplicável, selecione Começar agora ou Começar à hora definida e indique uma data de início e um tempo de execução.
Na secção Definições de destino, em Conjunto de dados, escolha o conjunto de dados que criou para armazenar os seus dados.
Na secção Detalhes da origem de dados, faça o seguinte:
- Em Tabela de destino, introduza o nome da tabela que criou para armazenar os dados no BigQuery. Os nomes das tabelas de destino suportam parâmetros.
- Para o Nome da conta de armazenamento do Azure, introduza o nome da conta de armazenamento de blobs.
- Em Nome do contentor, introduza o nome do contentor do armazenamento de blobs.
- Para Caminho dos dados, introduza o caminho para filtrar os ficheiros a transferir. Veja exemplos.
- Para o token SAS, introduza o token SAS do Azure.
- Em Formato de ficheiro, escolha o formato dos dados de origem.
- Para Disposição de escrita, selecione
WRITE_APPENDpara anexar incrementalmente novos dados à tabela de destino ouWRITE_TRUNCATEpara substituir os dados na tabela de destino durante cada execução de transferência.WRITE_APPENDé o valor predefinido para Write disposition.
Para mais informações sobre como o Serviço de transferência de dados do BigQuery carrega dados usando
WRITE_APPENDouWRITE_TRUNCATE, consulte o artigo Carregamento de dados para transferências de blobs do Azure. Para mais informações acerca do campowriteDisposition, consulteJobConfigurationLoad.
Na secção Opções de transferência, faça o seguinte:
- Para Número de erros permitidos, introduza um valor inteiro para o número máximo de registos inválidos que podem ser ignorados. O valor predefinido é 0.
- (Opcional) Para tipos de destino decimal, introduza uma lista separada por vírgulas dos tipos de dados SQL possíveis para os quais os valores decimais nos dados de origem são convertidos. O tipo de dados SQL selecionado para a conversão depende das seguintes condições:
- Pela ordem de
NUMERIC,BIGNUMERICeSTRING, é selecionado um tipo se estiver na lista especificada e se suportar a precisão e a escala. - Se nenhum dos tipos de dados indicados suportar a precisão e a escala, é selecionado o tipo de dados que suporta o intervalo mais amplo na lista especificada. Se um valor exceder o intervalo suportado ao ler os dados de origem, é gerado um erro.
- O tipo de dados
STRINGsuporta todos os valores de precisão e escala. - Se este campo for deixado em branco, o tipo de dados é predefinido como
NUMERIC,STRINGpara ORC eNUMERICpara outros formatos de ficheiros. - Este campo não pode conter tipos de dados duplicados.
- A ordem dos tipos de dados que indica é ignorada.
- Pela ordem de
Se escolheu CSV ou JSON como formato de ficheiro, na secção JSON, CSV, selecione Ignorar valores desconhecidos para aceitar linhas que contenham valores que não correspondem ao esquema.
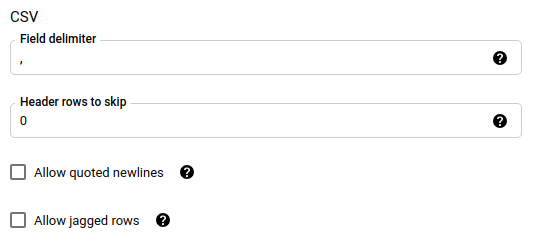
Se escolheu CSV como formato de ficheiro, na secção CSV, introduza quaisquer opções de CSV adicionais para carregar dados.
Na secção Opções de notificação, pode optar por ativar as notificações por email e as notificações do Pub/Sub.
- Quando ativa as notificações por email, o administrador da transferência recebe uma notificação por email quando uma execução de transferência falha.
- Quando ativa as notificações do Pub/Sub, escolha um nome de tópico para publicar ou clique em Criar um tópico para criar um.
Se usar CMEKs, na secção Opções avançadas, selecione Chave gerida pelo cliente. É apresentada uma lista das CMEKs disponíveis para que possa escolher. Para obter informações sobre como as CMEKs funcionam com o Serviço de transferência de dados do BigQuery, consulte o artigo Especifique a chave de encriptação com transferências.
Clique em Guardar.
bq
Use o comando
bq mk --transfer_config
para criar uma transferência do Blob Storage:
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=DISPLAY_NAME \ --target_dataset=DATASET \ --destination_kms_key=DESTINATION_KEY \ --params=PARAMETERS
Substitua o seguinte:
PROJECT_ID: (opcional) o ID do projeto que contém o conjunto de dados de destino. Se não for especificado, é usado o projeto predefinido.DATA_SOURCE:azure_blob_storage.DISPLAY_NAME: o nome a apresentar da configuração de transferência de dados. O nome da transferência pode ser qualquer valor que lhe permita identificar a transferência se precisar de a modificar mais tarde.DATASET: o conjunto de dados de destino para a configuração de transferência de dados.DESTINATION_KEY: (Opcional) o ID do recurso da chave do Cloud KMS, por exemplo,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name.PARAMETERS: os parâmetros para a configuração de transferência de dados, apresentados no formato JSON. Por exemplo,--params={"param1":"value1", "param2":"value2"}. Seguem-se os parâmetros para uma transferência de dados do armazenamento de blobs:destination_table_name_template: obrigatório. O nome da tabela de destino.storage_account: obrigatório. O nome da conta do armazenamento de blobs.container: obrigatório. O nome do contentor do armazenamento de blobs.data_path: opcional. O caminho para filtrar os ficheiros a transferir. Veja exemplos.sas_token: obrigatório. O token SAS do Azure.file_format: opcional. O tipo de ficheiros que quer transferir:CSV,JSON,AVRO,PARQUETouORC. O valor predefinido éCSV.write_disposition: opcional. SelecioneWRITE_APPENDpara anexar dados à tabela de destino ouWRITE_TRUNCATEpara substituir dados na tabela de destino. O valor predefinido éWRITE_APPEND.max_bad_records: opcional. O número de registos inválidos permitidos. O valor predefinido é 0.decimal_target_types: opcional. Uma lista separada por vírgulas de possíveis tipos de dados SQL para os quais os valores decimais nos dados de origem são convertidos. Se este campo não for fornecido, o tipo de dados é predefinido comoNUMERIC,STRINGpara ORC eNUMERICpara os outros formatos de ficheiros.ignore_unknown_values: opcional e ignorado sefile_formatnão forJSONouCSV. Defina comotruepara aceitar linhas que contenham valores que não correspondam ao esquema.field_delimiter: opcional e aplica-se apenas quandofile_formatéCSV. O caráter que separa os campos. O valor predefinido é,.skip_leading_rows: opcional e aplica-se apenas quandofile_formatéCSV. Indica o número de linhas de cabeçalho que não quer importar. O valor predefinido é 0.allow_quoted_newlines: opcional e aplica-se apenas quandofile_formatéCSV. Indica se devem ser permitidas novas linhas em campos entre aspas.allow_jagged_rows: opcional e aplica-se apenas quandofile_formatéCSV. Indica se devem ser aceites linhas com colunas opcionais finais em falta. Os valores em falta são preenchidos comNULL.
Por exemplo, o seguinte cria uma transferência de dados do Armazenamento de blobs
denominada mytransfer:
bq mk \ --transfer_config \ --data_source=azure_blob_storage \ --display_name=mytransfer \ --target_dataset=mydataset \ --destination_kms_key=projects/myproject/locations/us/keyRings/mykeyring/cryptoKeys/key1 --params={"destination_table_name_template":"mytable", "storage_account":"myaccount", "container":"mycontainer", "data_path":"myfolder/*.csv", "sas_token":"my_sas_token_value", "file_format":"CSV", "max_bad_records":"1", "ignore_unknown_values":"true", "field_delimiter":"|", "skip_leading_rows":"1", "allow_quoted_newlines":"true", "allow_jagged_rows":"false"}
API
Use o método projects.locations.transferConfigs.create e forneça uma instância do recurso TransferConfig.
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do BigQuery com bibliotecas cliente. Para mais informações, consulte a API Java BigQuery documentação de referência.
Para se autenticar no BigQuery, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para bibliotecas de cliente.
Especifique a chave de encriptação com transferências
Pode especificar chaves de encriptação geridas pelo cliente (CMEKs) para encriptar dados para uma execução de transferência. Pode usar uma CMEK para suportar transferências do Azure Blob Storage.Quando especifica uma CMEK com uma transferência, o Serviço de transferência de dados do BigQuery aplica a CMEK a qualquer cache intermédia no disco dos dados carregados, para que todo o fluxo de trabalho de transferência de dados esteja em conformidade com a CMEK.
Não é possível atualizar uma transferência existente para adicionar uma CMEK se a transferência não tiver sido criada originalmente com uma CMEK. Por exemplo, não pode alterar uma tabela de destino que foi originalmente encriptada por predefinição para ser encriptada com CMEK. Por outro lado, também não pode alterar uma tabela de destino encriptada com CMEK para ter um tipo de encriptação diferente.
Pode atualizar uma CMEK para uma transferência se a configuração de transferência tiver sido criada originalmente com uma encriptação CMEK. Quando atualiza uma CMEK para uma configuração de transferência, o Serviço de transferência de dados do BigQuery propaga a CMEK para as tabelas de destino na execução seguinte da transferência, em que o Serviço de transferência de dados do BigQuery substitui todas as CMEKs desatualizadas pela nova CMEK durante a execução da transferência. Para mais informações, consulte o artigo Atualize uma transferência.
Também pode usar as chaves predefinidas do projeto. Quando especifica uma chave predefinida do projeto com uma transferência, o Serviço de transferência de dados do BigQuery usa a chave predefinida do projeto como a chave predefinida para quaisquer novas configurações de transferência.
Resolva problemas de configuração da transferência
Se estiver a ter problemas com a configuração da transferência de dados, consulte o artigo Problemas de transferência do armazenamento de blobs.
O que se segue?
- Saiba mais acerca dos parâmetros de tempo de execução nas transferências.
- Saiba mais acerca do Serviço de transferência de dados do BigQuery.
- Saiba como carregar dados com operações em várias nuvens.