Blob 스토리지 전송 소개
Azure Blob Storage용 BigQuery Data Transfer Service를 사용하면 Azure Blob Storage 및 Azure Data Lake Storage Gen2에서 BigQuery로 반복되는 로드 작업을 자동으로 예약하고 관리할 수 있습니다.
지원되는 파일 형식
BigQuery Data Transfer Service는 현재 Blob Storage에서 다음 형식의 데이터를 로드할 수 있습니다.
- 쉼표로 구분된 값(CSV)
- JSON(줄바꿈으로 구분)
- Avro
- Parquet
- ORC
지원되는 압축 유형
Blob Storage용 BigQuery Data Transfer Service는 압축 데이터 로드를 지원합니다. BigQuery Data Transfer Service에서 지원되는 압축 유형은 BigQuery 로드 작업에서 지원되는 압축 유형과 동일합니다. 자세한 내용은 압축 데이터 및 압축되지 않은 데이터 로드를 참조하세요.
전송 기본 요건
Blob Storage 데이터 소스에서 데이터를 로드하려면 먼저 다음을 수집하세요.
- 소스 데이터의 Blob Storage 계정 이름, 컨테이너 이름, 데이터 경로(선택사항). 데이터 경로 필드는 선택사항입니다. 일반적인 객체 접두사와 파일 확장자를 일치시키는 데 사용됩니다. 데이터 경로를 생략하면 컨테이너의 모든 파일이 전송됩니다.
- 데이터 소스에 대한 읽기 액세스 권한을 부여하는 Azure 공유 액세스 서명 (SAS) 토큰. SAS 토큰 만들기에 대한 자세한 내용은 공유 액세스 서명(SAS)을 참조하세요.
전송 런타임 파라미터화
Blob Storage 데이터 경로와 대상 테이블을 모두 매개변수화할 수 있으므로 날짜별로 구성된 컨테이너에서 데이터를 로드할 수 있습니다. Blob Storage 전송에 사용되는 매개변수는 Cloud Storage 전송에 사용되는 매개변수와 동일합니다. 자세한 내용은 전송의 런타임 매개변수을 참조하세요.
Azure Blob 전송을 위한 데이터 수집
Azure Blob 전송을 설정할 때 전송 구성에서 쓰기 환경설정을 선택하여 데이터가 BigQuery에 로드되는 방법을 지정할 수 있습니다.
사용 가능한 쓰기 환경설정에는 증분 전송 및 잘린 전송 두 가지 유형이 있습니다.증분 전송
증분 전송이라고도 하는 APPEND 또는 WRITE_APPEND 쓰기 환경설정이 있는 전송 구성에서는 이전의 BigQuery 대상 테이블로의 성공적인 전송 이후의 새 데이터를 점진적으로 추가합니다. 전송 구성이 APPEND 쓰기 환경설정으로 실행되면 BigQuery Data Transfer Service는 이전에 성공한 전송 실행 이후 수정된 파일을 필터링합니다. 파일이 수정되는 시간을 확인하기 위해 BigQuery Data Transfer Service는 파일 메타데이터에서 "마지막 수정 시간" 속성을 찾습니다. 예를 들어 BigQuery Data Transfer Service는 Cloud Storage 파일에서 updated 타임스탬프 속성을 찾습니다. BigQuery Data Transfer Service가 마지막으로 성공한 전송 타임스탬프 이후에 발생한 '마지막 수정 시간'이 있는 파일을 찾으면 BigQuery Data Transfer Service는 증분 전송으로 해당 파일을 전송합니다.
증분 전송 작동 방식을 이해하려면 다음 Cloud Storage 전송 예시를 참조하세요. 사용자가 2023-07-01T00:00Z에 file_1이라는 파일을 Cloud Storage 버킷에 만듭니다. file_1의 updated 타임스탬프는 파일이 생성된 시간입니다. 그런 다음 사용자는 Cloud Storage 버킷에서 2023-07-01T03:00Z부터 시작하여 03:00Z에 매일 한 번 실행되도록 예약된 증분 전송을 만듭니다.
- 2023-07-01T03:00Z에 첫 번째 전송 실행이 시작됩니다. 이 구성에 대한 전송 실행이 이번이 처음이기 때문에 BigQuery Data Transfer Service가 소스 URI와 일치하는 모든 파일을 대상 BigQuery 테이블에 로드하려고 시도합니다. 전송 실행이 성공하고 BigQuery Data Transfer Service가 대상 BigQuery 테이블에
file_1을 성공적으로 로드합니다. - 다음 전송 실행인 2023-07-02T03:00Z에는
updated타임스탬프 속성이 마지막으로 성공한 전송 실행(2023-07-01T03:00Z)보다 큰 파일을 감지하지 않습니다. 전송 실행은 추가 데이터를 대상 BigQuery 테이블에 로드하지 않고도 성공합니다.
위 예시에서는 BigQuery Data Transfer Service가 소스 파일의 updated 타임스탬프 속성을 확인하여 소스 파일에 변경사항이 있는지 확인하고 감지한 변경사항이 있으면 이를 전송하는 방법을 보여줍니다.
동일한 예시를 따라 사용자가 2023-07-03T00:00Z 시간에 Cloud Storage 버킷에 file_2라는 다른 파일을 만든다고 가정해 보겠습니다. file_2의 updated 타임스탬프는 파일이 생성된 시간입니다.
- 다음 전송 실행인 2023-07-03T03:00Z에는
file_2가 마지막으로 성공한 전송 실행(2023-07-01T03:00Z)보다 큰updated타임스탬프를 감지합니다. 전송 실행이 시작될 때 일시적인 오류로 인해 실패한다고 가정해 보세요. 이 시나리오에서는file_2가 대상 BigQuery 테이블에 로드되지 않습니다. 마지막으로 성공한 전송 실행 타임스탬프는 2023-07-01T03:00Z로 유지됩니다. - 다음 전송 실행인 2023-07-04T03:00Z에는
file_2가 마지막으로 성공한 전송 실행(2023-07-01T03:00Z)보다 큰updated타임스탬프를 감지합니다. 이번에는 전송 실행이 문제 없이 완료되므로file_2가 대상 BigQuery 테이블에 성공적으로 로드됩니다. - 다음 전송 실행인 2023-07-05T03:00Z에는
updated타임스탬프가 마지막으로 성공한 전송 실행(2023-07-04T03:00Z)보다 큰 파일을 감지하지 않습니다. 전송 실행은 추가 데이터를 대상 BigQuery 테이블에 로드하지 않고도 성공합니다.
앞의 예시는 전송이 실패할 때 BigQuery 대상 테이블에 파일이 전송되지 않는 것을 보여줍니다. 모든 파일 변경사항은 다음에 전송 실행이 성공할 때 전송됩니다. 전송이 실패한 후 다음 전송이 성공해도 중복 데이터가 발생하지는 않습니다. 전송이 실패한 경우 정기적으로 예약된 시간 이외의 전송을 수동으로 트리거하도록 선택할 수도 있습니다.
잘린 전송
잘린 전송이라고도 하는 MIRROR 또는 WRITE_TRUNCATE 쓰기 환경설정이 있는 전송 구성은 각 전송 중에 BigQuery 대상 테이블의 데이터를 소스 URI와 일치하는 모든 파일의 데이터로 덮어씁니다. MIRROR는 대상 테이블의 새 데이터 복사본을 덮어씁니다. 대상 테이블에 파티션 데코레이터가 사용될 경우 전송 실행 시 지정된 파티션의 데이터만 덮어씁니다. 파티션 데코레이터가 있는 대상 테이블은 my_table${run_date} 형식입니다(예: my_table$20230809).
하루에 동일한 증분 또는 잘린 전송을 반복해도 중복 데이터가 발생하지 않습니다. 그러나 동일한 BigQuery 대상 테이블에 영향을 미치는 여러 전송 구성을 실행하는 경우 BigQuery Data Transfer Service에서 중복 데이터가 발생할 수 있습니다.
Blob Storage 데이터 경로에 대한 와일드 카드 지원
데이터 경로에 별표(*) 와일드 카드 문자를 하나 이상 지정하여 여러 파일로 구분된 소스 데이터를 선택할 수 있습니다.
데이터 경로에 두 개 이상의 와일드 카드를 사용할 수 있지만, 와일드 카드를 하나만 사용하면 어느 정도 최적화가 가능합니다.
- 전송 실행당 최대 파일 수에는 상한이 있습니다.
- 와일드 카드는 디렉터리 경계를 포괄합니다. 예를 들어 데이터 경로
my-folder/*.csv는 파일my-folder/my-subfolder/my-file.csv와 일치합니다.
Blob Storage 데이터 경로 예시
다음은 Blob Storage 전송에 대한 유효한 데이터 경로의 예시입니다. 참고로, 데이터 경로는 /로 시작하지 않습니다.
예시: 단일 파일
Blob Storage에서 BigQuery로 단일 파일을 로드하려면 Blob Storage 파일 이름을 지정하세요.
my-folder/my-file.csv
예시: 모든 파일
Blob Storage 컨테이너의 모든 파일을 BigQuery로 로드하려면 데이터 경로를 단일 와일드 카드로 설정합니다.
*
예시: 공통 프리픽스가 있는 파일
공통 프리픽스를 공유하는 Blob Storage에서 모든 파일을 로드하려면 와일드 카드를 사용하거나 사용하지 않고 공통 프리픽스를 지정합니다.
my-folder/
또는
my-folder/*
예시: 경로가 비슷한 파일
비슷한 경로를 사용하여 Blob Storage에서 모든 파일을 로드하려면 공통 프리픽스 및 서픽스를 지정합니다.
my-folder/*.csv
와일드 카드를 하나만 사용하면 디렉터리를 포괄합니다. 이 예시에서는 my-folder의 모든 CSV 파일과 my-folder의 모든 하위 폴더에 있는 모든 CSV 파일이 선택됩니다.
예시: 경로 끝의 와일드 카드
다음 데이터 경로를 살펴보세요.
logs/*
다음 파일이 모두 선택됩니다.
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
예시: 경로 시작 부분의 와일드 카드
다음 데이터 경로를 살펴보세요.
*logs.csv
다음 파일이 모두 선택됩니다.
logs.csv
system/logs.csv
some-application/logs.csv
다음 파일은 선택되지 않습니다.
metadata.csv
system/users.csv
some-application/output.csv
예시: 여러 와일드 카드
여러 개의 와일드 카드를 사용하면 하한값을 포기하는 대신 파일 선택을 더 세밀하게 제어할 수 있습니다. 여러 개의 와일드 카드를 사용하는 경우 각 개별 와일드 카드는 단일 하위 디렉터리에만 걸쳐 있습니다.
다음 데이터 경로를 살펴보세요.
*/*.csv
다음 두 파일이 모두 선택됩니다.
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
다음 파일 중 어느 것도 선택되지 않습니다.
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
공유 액세스 서명(SAS)
Azure SAS 토큰은 사용자 대신 Blob Storage 데이터에 액세스하는 데 사용됩니다. 다음 단계에 따라 전송용 SAS 토큰을 만드세요.
- 기존 Blob Storage 사용자를 만들거나 사용하여 Blob Storage 컨테이너의 스토리지 계정에 액세스합니다.
스토리지 계정 수준에서 SAS 토큰을 만듭니다. Azure Portal을 사용하여 SAS 토큰을 만들려면 다음 안내를 따르세요.
- 허용된 서비스에 Blob을 선택합니다.
- 허용된 리소스 유형에서 컨테이너 및 객체를 모두 선택합니다.
- 허용된 권한에 읽기 및 나열을 선택합니다.
- SAS 토큰의 기본 만료 시간은 8시간입니다. 전송 일정에 맞는 만료 시간을 설정합니다.
- 허용된 IP 주소 필드에 IP 주소를 지정하지 마세요.
- 허용되는 프로토콜에 HTTPS만을 선택합니다.
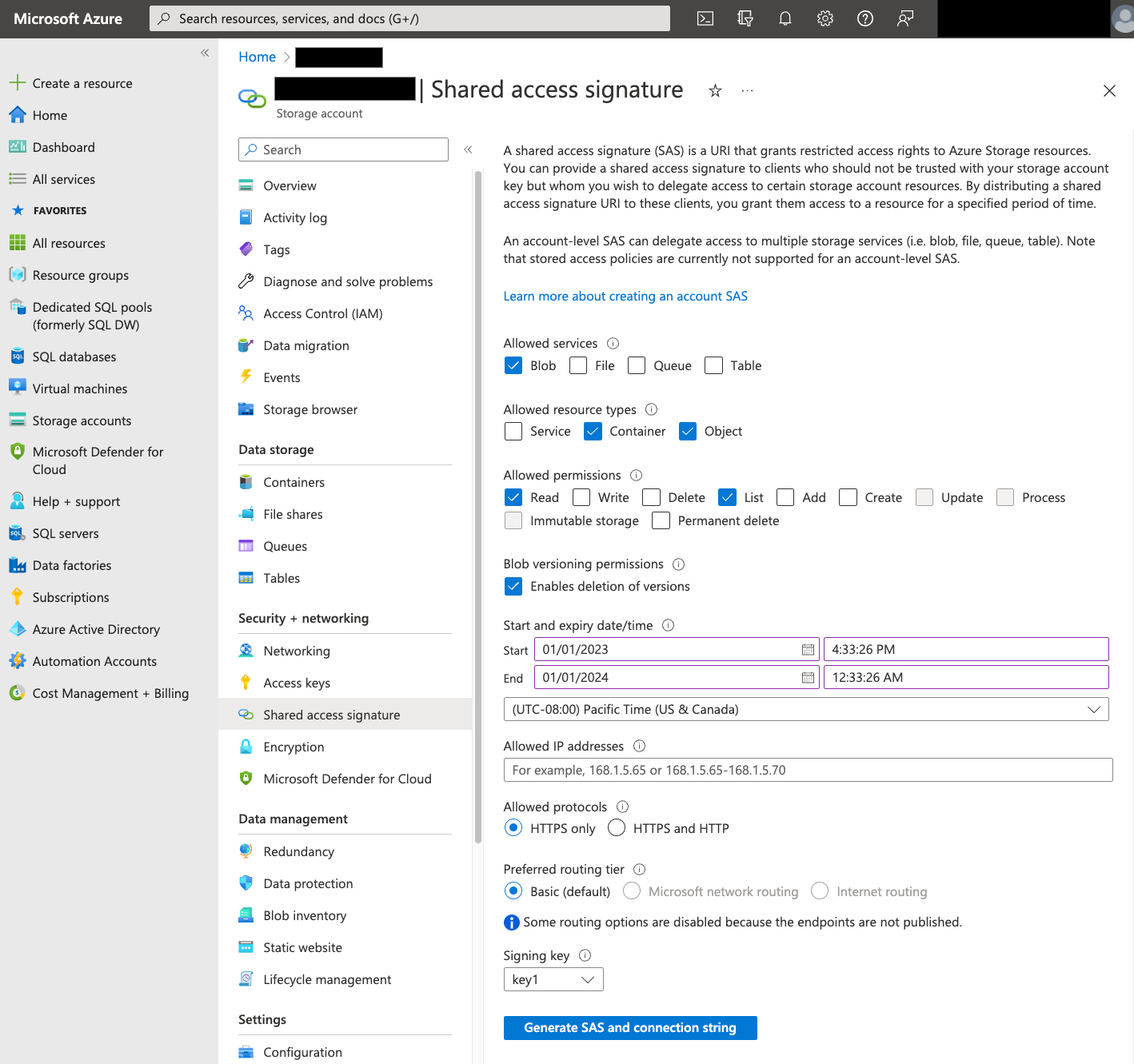
SAS 토큰이 생성되면 반환된 SAS 토큰 값을 기록합니다. 전송을 구성할 때 이 값이 필요합니다.
IP 제한사항
Azure Storage 방화벽을 사용하여 Azure 리소스에 대한 액세스를 제한하는 경우, BigQuery Data Transfer Service 작업자가 사용하는 IP 범위를 허용된 IP 목록에 추가해야 합니다.
IP 범위를 Azure Storage 방화벽에 허용되는 IP로 추가하려면 IP 제한사항을 참조하세요.
일관성 관련 고려사항
Blob Storage 컨테이너에 파일을 추가한 후 BigQuery Data Transfer Service에서 사용할 수 있게 될 때까지 약 5분이 소요됩니다.
이그레스 비용 제어를 위한 권장사항
대상 테이블이 제대로 구성되지 않으면 Blob Storage에서 전송이 실패할 수 있습니다. 부적절한 구성의 가능한 원인은 다음과 같습니다.
- 대상 테이블이 존재하지 않음
- 테이블 스키마가 정의되지 않음
- 테이블 스키마가 전송되는 데이터와 호환되지 않음
추가 Blob Storage 이그레스 비용을 방지하려면 먼저 파일의 작지만 대표적인 하위 집합을 사용하여 전송을 테스트하세요. 이 테스트의 데이터 크기와 파일 수가 작은지 확인합니다.
또한 Blob Storage에서 파일이 전송되기 전에 데이터 경로에 대해 프리픽스 일치가 수행되지만 와일드 카드 일치가 Google Cloud내에서 발생한다는 점에 주의해야 합니다. 이러한 구분으로 인해Google Cloud 로 전송되었지만 BigQuery에 로드되지 않은 파일의 Blob Storage 이그레스 비용이 증가할 수 있습니다.
다음 데이터 경로를 예시로 들어보겠습니다.
folder/*/subfolder/*.csv
두 파일 모두 프리픽스 folder/가 있으므로 Google Cloud로 전송됩니다.
folder/any/subfolder/file1.csv
folder/file2.csv
하지만 folder/any/subfolder/file1.csv 파일만 전체 데이터 경로와 일치하므로 BigQuery에 로드됩니다.
가격 책정
자세한 내용은 BigQuery Data Transfer Service 가격 책정을 참조하세요.
이 서비스를 사용하면 Google 외부에서 비용이 발생할 수도 있습니다. 자세한 내용은 Blob Storage 가격 책정을 참조하세요.
할당량 및 한도
BigQuery Data Transfer Service는 로드 작업을 사용하여 Blob Storage 데이터를 BigQuery로 로드합니다. 로드 작업에 대한 모든 BigQuery 할당량 및 한도는 다음과 같은 추가 고려사항과 함께 반복되는 Blob Storage 전송에 적용됩니다.
| 한도 | 기본값 |
|---|---|
| 로드 작업 전송 실행당 최대 크기 | 15TB |
| Blob Storage 데이터 경로에 0 또는 1개의 와일드 카드가 포함된 경우 전송 실행당 최대 파일 수 | 10,000,000개 파일 |
| Blob Storage 데이터 경로에 2개 이상의 와일드 카드가 포함된 경우 전송 실행당 최대 파일 수 | 10,000개 파일 |
다음 단계
- Blob Storage 전송 설정 자세히 알아보기
- 전송의 런타임 파라미터 자세히 알아보기
- BigQuery Data Transfer Service 자세히 알아보기