Este tutorial tem a finalidade de apresentar aos analistas de dados o modelo de fatoração de matrizes do BigQuery ML. Com o BigQuery ML, usuários podem criar e executar modelos de machine learning no BigQuery usando consultas SQL. O objetivo é democratizar o uso do machine learning ao permitir que os usuários de SQL criem modelos com as ferramentas que já utilizam, além de acelerar o desenvolvimento ao eliminar a necessidade de movimentar dados.
Neste tutorial, você aprenderá como criar um modelo a partir de feedback explícito, usando o conjunto de dados movielens1m (em inglês), para fazer recomendações com base em IDs de filme e usuário.
O conjunto de dados MovieLens contém classificações em uma escala de 1 a 5 atribuídas a filmes pelos usuários, além dos metadados do filme, como o gênero.
Objetivos
Neste tutorial, você usará:
- o BigQuery ML para criar um modelo de recomendações explícitas usando a
instrução
CREATE MODEL; - a função
ML.EVALUATEpara avaliar os modelos de ML; - a função
ML.WEIGHTSpara inspecionar os pesos de fatores latentes gerados durante o treinamento; - a função
ML.RECOMMENDpara produzir recomendações para um usuário.
Custos
Neste tutorial, há componentes faturáveis do Google Cloud, entre eles:
- BigQuery
- BigQuery ML
Para mais informações sobre os custos do BigQuery, consulte a página de preços do BigQuery.
Para mais informações sobre os custos do BigQuery ML, consulte os preços do BigQuery ML.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- O BigQuery é ativado automaticamente em novos projetos.
Para ativar o BigQuery em um projeto preexistente, acesse
Enable the BigQuery API.
Etapa 1: criar conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o modelo de ML:
No console do Google Cloud, acesse a página do BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.
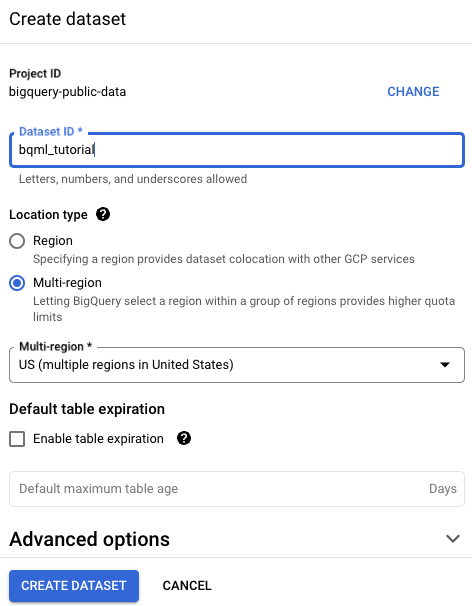
Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
bqml_tutorial.Em Tipo de local, selecione Multirregião e EUA (várias regiões nos Estados Unidos).
Os conjuntos de dados públicos são armazenados na multirregião
US. Para simplificar, armazene seus conjuntos de dados no mesmo local.Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.
Etapa 2: carregar o conjunto de dados do MovieLens no BigQuery
Veja a seguir as etapas para carregar o conjunto de dados MovieLens 1M no BigQuery usando as ferramentas de linha de comando.
Um conjunto de dados chamado movielens será criado e as tabelas relevantes do conjunto original serão armazenadas nele.
curl -O 'http://files.grouplens.org/datasets/movielens/ml-1m.zip'
unzip ml-1m.zip
bq mk --dataset movielens
sed 's/::/,/g' ml-1m/ratings.dat > ratings.csv
bq load --source_format=CSV movielens.movielens_1m ratings.csv \
user_id:INT64,item_id:INT64,rating:FLOAT64,timestamp:TIMESTAMP
Como os títulos dos filmes podem conter dois pontos, vírgulas e barras verticais, precisaremos usar um delimitador diferente. Para carregar os títulos dos filmes, use uma variante um pouco diferente dos dois últimos comandos.
sed 's/::/@/g' ml-1m/movies.dat > movie_titles.csv
bq load --source_format=CSV --field_delimiter=@ \
movielens.movie_titles movie_titles.csv \
movie_id:INT64,movie_title:STRING,genre:STRING
Etapa 3: criar um modelo de recomendações explícitas
Em seguida, crie um modelo de recomendações explícitas usando a tabela de amostra MovieLens que foi carregada na etapa anterior. A consulta GoogleSQL padrão a seguir é usada para criar o modelo que será usado na previsão de uma classificação para cada par de usuário e item.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
Ao executar o comando CREATE MODEL, o modelo será criado e treinado.
Detalhes da consulta
A cláusula CREATE MODEL é usada para criar e treinar o modelo chamado bqml_tutorial.my_explicit_mf_model.
A cláusula OPTIONS(model_type='matrix_factorization', user_col='user_id', ...) indica que você está criando um modelo de fatoração de matrizes (em inglês). Por padrão, isso criará um modelo de fatoração de matrizes explícita, a menos que o comando feedback_type='IMPLICIT' seja especificado. Consulte Como usar o BigQuery ML para fazer recomendações para feedback implícito para ver um exemplo explicado sobre a criação de um modelo de fatoração de matrizes implícita.
A instrução SELECT dessa consulta usa as colunas a seguir para gerar recomendações.
user_id: o ID do usuário (INT64).item_id: o ID do filme (INT64).rating: a classificação explícita de 1 a 5 que ouser_iddeu aoitem_id(FLOAT64).
A cláusula FROM (movielens.movielens_1m) indica que a consulta é feita na tabela movielens_1m do conjunto de dados movielens.
Esse conjunto de dados estará no seu projeto do BigQuery se você seguir as instruções na etapa 2.
Executar a consulta CREATE MODEL
Para executar a consulta CREATE MODEL para criar e treinar seu modelo:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.my_explicit_mf_model` OPTIONS (model_type='matrix_factorization', user_col='user_id', item_col='item_id', l2_reg=9.83, num_factors=34) AS SELECT user_id, item_id, rating FROM `movielens.movielens_1m`
Clique em Executar.
A consulta leva cerca de 10 minutos para ser concluída. Depois disso, o modelo (
my_explicit_mf_model) aparecerá no painel de navegação do console do Google Cloud. Como a consulta usa uma instruçãoCREATE MODELpara criar um modelo, você não verá os resultados dela.
Etapa 4 (opcional): receber estatísticas de treinamento
Para conferir os resultados do treinamento de modelo, use a função
ML.TRAINING_INFO
ou visualize as estatísticas no console do Google Cloud. Neste
tutorial, você usa o console do Google Cloud.
Para criar um modelo, o algoritmo de machine learning examina vários exemplos e tenta encontrar um modelo que minimize a perda (em inglês). Esse processo é chamado de minimização do risco empírico.
Para ver as estatísticas de treinamento do modelo que foram geradas quando você executou a consulta CREATE MODEL:
Na seção Recursos do painel de navegação do console do Google Cloud, expanda [PROJECT_ID] > bqml_tutorial e clique em my_explicit_mf_model.
Clique na guia Treinamento e depois em Tabela. Os resultados terão o seguinte formato:
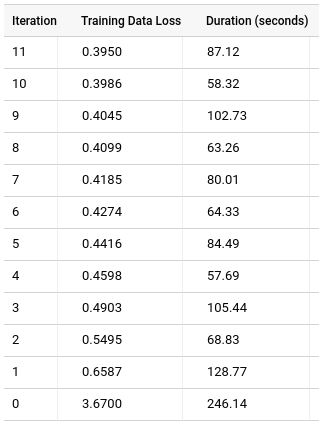
A coluna Perda de dados de treinamento representa métrica da perda, calculada depois de o modelo ser treinado no conjunto de dados de treinamento. Como você realizou a fatoração de matrizes, essa coluna é o erro quadrático médio. Por padrão, os modelos de fatoração de matrizes não dividem os dados. Portanto, a coluna Perda de dados de avaliação não estará presente, a menos que um conjunto de dados de teste (holdout) seja especificado porque a divisão desses dados pode ter como consequência a perda de todas as classificações de um usuário ou um item. Como resultado, o modelo não terá informações de fatores latentes sobre usuários ou itens ausentes.
Para mais detalhes sobre a função
ML.TRAINING_INFO, consulte a referência da sintaxe do BigQuery ML.
Etapa 5: avaliar o modelo
Depois de criar o modelo, será necessário avaliar o desempenho do recomendador usando a função ML.EVALUATE. A função ML.EVALUATE avalia as classificações previstas em relação às classificações reais.
A consulta usada para avaliar o modelo é esta:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id, item_id, rating FROM `movielens.movielens_1m`))
Detalhes da consulta
A principal instrução SELECT recupera as colunas do modelo.
A cláusula FROM usa a função ML.EVALUATE no modelo: bqml_tutorial.my_explicit_mf_model.
A instrução SELECT aninhada dessa consulta e a cláusula FROM são as mesmas da consulta CREATE MODEL.
Também é possível chamar ML.EVALUATE
sem fornecer os dados de entrada. Ela usará as métricas de avaliação calculadas durante o treinamento:
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`)
Executar a consulta ML.EVALUATE
Para executar a consulta ML.EVALUATE que avalia o modelo:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id, item_id, rating FROM `movielens.movielens_1m`))
(Opcional) Para definir o local de processamento, clique em Mais > Configurações de consulta. Para Local de processamento, escolha
US. Esta etapa é opcional, porque o local de processamento é detectado automaticamente com base no local do conjunto de dados.
Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão o seguinte formato:

Como você realizou a fatoração de matrizes explícita, os resultados incluem as colunas a seguir:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Uma métrica importante nos resultados da avaliação é a pontuação R2. A pontuação R2 é uma medida estatística que determina se as previsões de regressão linear se aproximam dos dados reais. 0 indica que o modelo não explica a variabilidade dos dados de resposta em torno da média. O valor 1 indica que o modelo explica toda a variabilidade dos dados de resposta em torno da média.
Etapa 6: usar o modelo para prever classificações e fazer recomendações
Encontrar todas as classificações de itens para um conjunto de usuários
ML.RECOMMEND não precisa aceitar qualquer argumento além do modelo, mas pode aceitar uma tabela opcional. Se a tabela de entrada tiver apenas uma coluna que corresponda ao nome das colunas de entrada user ou item, todas as classificações de itens previstas para cada user serão exibidas na saída e vice-versa. Se todos
users ou items estiverem na tabela de entrada,
a saída terá os mesmos resultados de não transmitir qualquer argumento opcional para ML.RECOMMEND.
Veja a seguir um exemplo de consulta para buscar todas as classificações de filme previstas para cinco usuários:
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`, ( SELECT user_id FROM `movielens.movielens_1m` LIMIT 5))
Detalhes da consulta
A principal instrução SELECT recupera as colunas user, item e predicted_rating.
Essa última coluna é gerada pela função ML.RECOMMEND. Ao usar a função ML.RECOMMEND, o nome da coluna de saída para o modelo é predicted_<rating_column_name>. Em modelos de fatoração de matrizes explícita, predicted_rating é o valor estimado de rating.
A função ML.RECOMMEND é empregada na previsão de classificações usando seu modelo: bqml_tutorial.my_explicit_mf_model.
A instrução SELECT aninhada dessa consulta seleciona apenas a coluna user_id da tabela original usada para treinamento.
A cláusula LIMIT (LIMIT 5) filtrará de maneira aleatória cinco user_ids para enviar a ML.RECOMMEND.
Encontrar as classificações de todos os pares de usuário e item
Agora que você avaliou seu modelo, a próxima etapa é usá-lo para prever uma classificação. Use o modelo para prever as classificações de cada combinação de usuário e item na consulta abaixo:
#standardSQL SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Detalhes da consulta
A principal instrução SELECT recupera as colunas user, item e predicted_rating.
Essa última coluna é gerada pela função ML.RECOMMEND. Ao usar a função ML.RECOMMEND, o nome da coluna de saída para o modelo é predicted_<rating_column_name>. Em modelos de fatoração de matrizes explícita, predicted_rating é o valor estimado de rating.
A função ML.RECOMMEND é empregada na previsão de classificações usando seu modelo: bqml_tutorial.my_explicit_mf_model.
Uma maneira de salvar o resultado na tabela é:
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Se ocorrer um erro Query Exceeded Resource Limits para ML.RECOMMEND, tente novamente com um nível de faturamento mais alto. Na ferramenta de linha de comando do BigQuery, é possível definir isso usando a sinalização --maximum_billing_tier.
Gerar recomendações
Usando a consulta de recomendações anterior, podemos ordenar por classificação prevista e gerar os principais itens previstos para cada usuário. A consulta a seguir une os item_ids aos movie_ids encontrados na tabela movielens.movie_titles, que foi enviada anteriormente, e gera os cinco principais filmes recomendados por usuário.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
Detalhes da consulta
A instrução SELECT interna executa uma mesclagem interna em item_id da tabela de resultados de recomendação e em movie_id da tabela movielens.movie_titles. Além de mapear movie_id para o nome de um filme, movielens.movie_titles também inclui o gênero, conforme listado pelo IMDB.
A instrução SELECT de alto nível agrupa os resultados da instrução SELECT aninhada ao usar GROUPS BY user_id para agregar movie_title,
genre, e predicted_rating em ordem decrescente, mantendo apenas os cinco principais filmes.
Executar a consulta ML.RECOMMEND
Para executar a consulta ML.RECOMMEND que gera os cinco principais filmes recomendados por usuário, faça o seguinte:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL CREATE OR REPLACE TABLE `bqml_tutorial.recommend_1m` OPTIONS() AS SELECT * FROM ML.RECOMMEND(MODEL `bqml_tutorial.my_explicit_mf_model`)
Clique em Executar.
Quando a consulta termina de ser executada, (
bqml_tutorial.recommend_1m) , aparece no painel de navegação. Como a consulta usa uma instruçãoCREATE TABLEpara criar uma tabela, você não verá os resultados dela.Escreva uma nova consulta. Insira a consulta do GoogleSQL a seguir na área de texto do Editor de consultas quando a consulta anterior terminar.
#standardSQL SELECT user_id, ARRAY_AGG(STRUCT(movie_title, genre, predicted_rating) ORDER BY predicted_rating DESC LIMIT 5) FROM ( SELECT user_id, item_id, predicted_rating, movie_title, genre FROM `bqml_tutorial.recommend_1m` JOIN `movielens.movie_titles` ON item_id = movie_id) GROUP BY user_id
(Opcional) Para definir o local de processamento, clique em Mais > Configurações de consulta. Para Local de processamento, escolha
US. Esta etapa é opcional, porque o local de processamento é detectado automaticamente com base no local do conjunto de dados. Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão o seguinte formato:
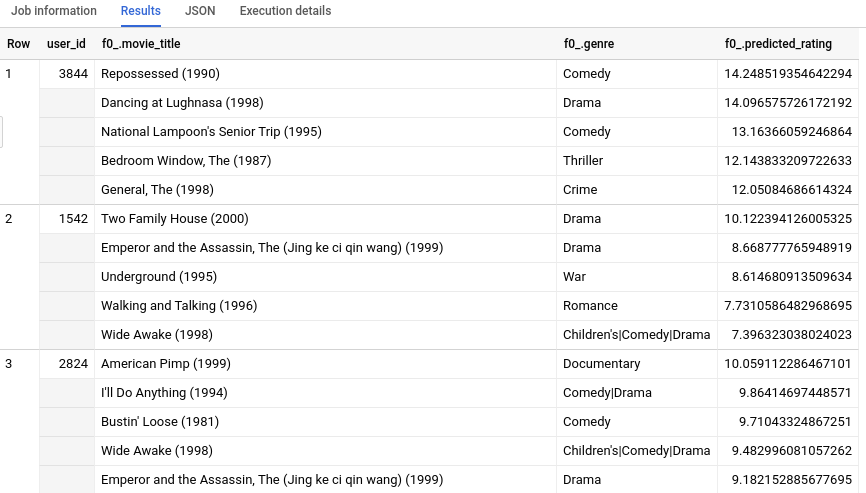
Como tínhamos informações de metadados extras sobre cada movie_id, além de um INT64, podemos ver algumas informações, como o gênero, dos cinco principais filmes recomendados para cada usuário. Se você não tiver uma tabela movietitles equivalente para seus dados de treinamento, os resultados talvez não sejam facilmente interpretáveis por humanos porque terão apenas IDs de número ou hashes.
Principais gêneros por fator
Se quiser saber a que gênero cada fator latente pode estar correlacionado, execute a consulta a seguir:
#standardSQL SELECT factor, ARRAY_AGG(STRUCT(feature, genre, weight) ORDER BY weight DESC LIMIT 10) AS weights FROM ( SELECT * EXCEPT(factor_weights) FROM ( SELECT * FROM ( SELECT factor_weights, CAST(feature AS INT64) as feature FROM ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`) WHERE processed_input= 'item_id') JOIN `movielens.movie_titles` ON feature = movie_id) weights CROSS JOIN UNNEST(weights.factor_weights) ORDER BY feature, weight DESC) GROUP BY factor
Detalhes da consulta
A instrução SELECT interior extrai o item_id ou a matriz de pesos do fator do filme e os mescla com a tabela movielens.movie_titles para receber o gênero de cada ID de item.
Em seguida, cada resultado passa por uma operação de CROSS JOIN com cada matriz factor_weights, resultando em ORDER BY feature, weight DESC.
Por fim, a instrução SELECT de alto nível agrupa os resultados da instrução interna por factor e cria uma matriz para cada fator ordenado pelo peso de cada gênero.
Executar a consulta
Para executar a consulta acima, que gera os 10 principais gêneros de filme por fator, faça o seguinte:
No console do Google Cloud, clique no botão Escrever nova consulta.
Insira a seguinte consulta do GoogleSQL na área de texto do Editor de consultas.
#standardSQL SELECT factor, ARRAY_AGG(STRUCT(feature, genre, weight) ORDER BY weight DESC LIMIT 10) AS weights FROM ( SELECT * EXCEPT(factor_weights) FROM ( SELECT * FROM ( SELECT factor_weights, CAST(feature AS INT64) as feature FROM ML.WEIGHTS(model `bqml_tutorial.my_explicit_mf_model`) WHERE processed_input= 'item_id') JOIN `movielens.movie_titles` ON feature = movie_id) weights CROSS JOIN UNNEST(weights.factor_weights) ORDER BY feature, weight DESC) GROUP BY factor
(Opcional) Para definir o local de processamento, clique em Mais > Configurações de consulta. Para Local de processamento, escolha
US. Esta etapa é opcional, porque o local de processamento é detectado automaticamente com base no local do conjunto de dados. Clique em Executar.
Após concluir a consulta, clique na guia Resultados abaixo da área de texto da consulta. Os resultados terão o seguinte formato:
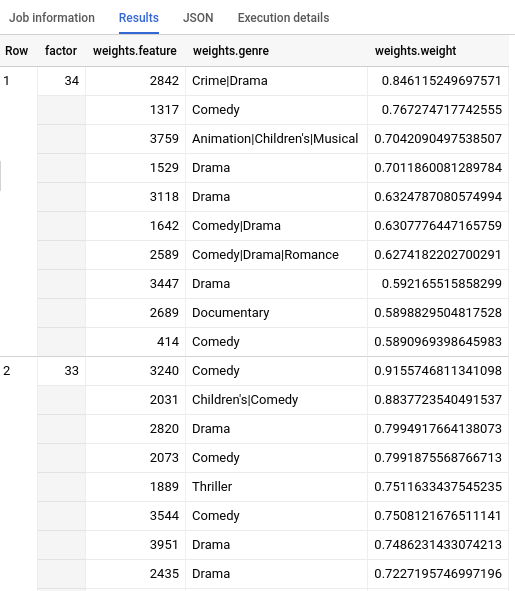
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
- exclua o projeto que você criou; ou
- Mantenha o projeto e exclua o conjunto de dados.
Excluir o conjunto de dados
A exclusão do seu projeto removerá todos os conjuntos de dados e tabelas no projeto. Caso prefira reutilizá-lo, exclua o conjunto de dados criado neste tutorial:
Se necessário, abra a página do BigQuery no console do Google Cloud.
Na navegação, clique no conjunto de dados bqml_tutorial criado.
Clique em Excluir conjunto de dados no lado direito da janela. Essa ação exclui o conjunto, a tabela e todos os dados.
Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão digitando o nome do seu conjunto de dados (
bqml_tutorial) e clique em Excluir.
Excluir o projeto
Para excluir o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Para saber mais sobre machine learning, consulte o Curso intensivo de machine learning.
- Para uma visão geral do BigQuery ML, consulte Introdução ao BigQuery ML.
- Para saber mais, consulte Como usar o console do Google Cloud.