空間分析最佳做法
本文說明在 BigQuery 中,如何運用最佳做法提升地理空間查詢效能。您可以運用這些最佳做法提升效能,並降低成本和延遲時間。
資料集可包含大量多邊形、多邊形形狀和線串,用來表示複雜的特徵,例如道路、地塊和洪氾區。每個形狀最多可包含數千個點。在 BigQuery 中,大部分的空間作業 (例如交集和距離計算) 的基礎演算法通常會造訪每個形狀中的大多數點,以產生結果。對於某些作業,演算法會造訪所有點。如果是複雜形狀,造訪每個點可能會增加空間作業的成本和時間。您可以運用本指南中介紹的策略和方法,針對這些常見的空間作業進行最佳化,進而提升效能並降低成本。
本文假設您的 BigQuery 地理空間資料表已根據地理資料欄叢集化。
簡化形狀
最佳做法:使用簡化和格線對齊功能,將原始資料集的簡化版本儲存為具體化檢視區塊。
許多複雜形狀 (具有大量點) 都可以簡化,而不會大幅降低精確度。請分別或一併使用 BigQuery ST_SIMPLIFY 和 ST_SNAPTOGRID 函式,減少複雜形狀中的點數。將這些函式與 BigQuery 具體化檢視區塊結合,即可將原始資料集的簡化版本儲存為具體化檢視區塊,並根據基本資料表自動保持最新狀態。
在下列應用實例中,簡化形狀最能提升資料集的成本效益和效能:
- 你必須盡量維持與真實形狀的高度相似性。
- 您必須執行高精確度作業。
- 您想加快視覺化速度,但又不想明顯損失形狀細節。
以下程式碼範例說明如何在具有名為 geom 的 GEOGRAPHY 資料欄的基本表格上使用 ST_SIMPLIFY 函式。這段程式碼會簡化形狀並移除點,但不會干擾形狀的任何邊緣,且干擾程度不會超過 1.0 公尺的容許值。
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SIMPLIFY(geom, 1.0) AS geom
FROM base_table
)
下列程式碼範例說明如何使用 ST_SNAPTOGRID 函式,將點對齊解析度為 0.00001 度的格線:
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SNAPTOGRID(geom, -5) AS geom
FROM base_table
)
這個函式中的 grid_size 引數會做為指數,也就是說 10e-5 = 0.00001。在最差的情況下 (發生於赤道),這個解析度相當於約 1 公尺。
建立這些檢視區塊後,請使用與查詢基本資料表相同的查詢語意,查詢 base_mv 檢視區塊。您可以使用這項技術快速找出需要深入分析的形狀集合,然後對基礎表格執行第二次深入分析。測試查詢,找出最適合資料的門檻值。
如果是評估用途,請判斷用途所需的準確度。使用 ST_SIMPLIFY 函式時,請將 threshold_meters 參數設為所需的準確度層級。如要測量城市或更大範圍的距離,請將門檻設為 10 公尺。如果規模較小 (例如測量建築物與最近水體之間的距離),請考慮使用 1 公尺以下的較小門檻。使用較小的門檻值,可減少從指定形狀移除的點。
從網路服務提供地圖圖層時,您可以使用 bigquery-geotools 專案,預先計算不同縮放等級的具體化檢視區塊。這個專案是 Geoserver 的驅動程式,可讓您從 BigQuery 提供空間圖層。這個驅動程式會使用不同的 ST_SIMPLIFY 門檻參數建立多個具體化檢視區塊,以便在較高的縮放層級提供較少的詳細資料。
使用點和矩形
最佳做法:將形狀縮小為點或矩形,代表其位置。
您可以將形狀縮減為單一點或矩形,藉此提升查詢效能。本節的方法無法準確呈現形狀的詳細資料和比例,而是著重於呈現形狀的位置。
您可以使用形狀的地理中心點 (即質心) 代表整個形狀的位置。使用包含形狀的矩形建立形狀的範圍,可用於表示形狀的位置,並維護其相對大小的相關資訊。
如果您需要測量兩點之間的距離 (例如兩座城市之間的距離),使用點和矩形最能有效提升資料集的費用和效能。
舉例來說,您可以將美國土地地塊的資料庫載入 BigQuery 資料表,然後判斷最近的水體。在這種情況下,使用 ST_CENTROID 函式預先計算地塊質心,並搭配本文件「簡化形狀」一節所述方法,即可減少使用 ST_DISTANCE 或 ST_DWITHIN 函式時執行的比較次數。使用 ST_CENTROID 函式時,計算中必須納入地塊質心。以這種方式預先計算地塊質心,也能減少效能變異性,因為不同地塊形狀可能包含不同數量的點。
這個方法的變體是使用 ST_BOUNDINGBOX 函式 (而非 ST_CENTROID 函式),計算輸入形狀周圍的矩形封套。雖然效率不如使用單一點,但可以減少特定極端情況的發生。這個變體仍可提供良好且一致的效能,因為 ST_BOUNDINGBOX 函式的輸出內容一律只包含四個需要考量的點。邊界框結果的類型為 STRUCT,這表示您需要手動計算距離,或使用本文稍後說明的向量索引方法。
使用船體
最佳做法:使用船體來盡量呈現形狀的位置。
如果想像將形狀包在收縮膜中,並計算收縮膜的邊界,該邊界就稱為「凸包」。在凸包中,所得形狀的所有角度都是凸角。凸包與形狀範圍類似,會保留基礎形狀的相對大小和比例等資訊。不過,使用船體會導致後續分析需要儲存及考量更多點,因此會產生額外成本。
您可以使用 ST_CONVEXHULL 函式,針對代表形狀位置的
項目進行最佳化。使用這項函式可提高準確度,但效能會隨之降低。ST_CONVEXHULL 函式與 ST_EXTENT 函式類似,但輸出形狀包含更多點,且點數會根據輸入形狀的複雜度而有所不同。如果資料集很小,形狀也不複雜,使用 ST_CONVEXHULL 函式可能不會帶來明顯的效能提升。但如果資料集很大,形狀也很複雜,ST_CONVEXHULL 函式就能在成本、效能和準確度之間取得良好平衡。
使用格線系統
最佳做法:使用地理空間格線系統比較不同區域。
如果您的用途是匯總特定區域內的資料,並比較這些區域的統計匯總資料,則可利用標準化格線系統比較不同區域。
舉例來說,零售商可能會想分析商店所在區域或考慮新建商店區域的客層變化。或者,保險公司可能會想分析特定區域的常見天然災害風險,進一步瞭解房地產風險。
使用 S2 和 H3 等標準格線系統,可加快這類統計資料匯總和空間分析作業。使用這些格線系統也能簡化 Analytics 開發作業,並提升開發效率。
舉例來說,在美國使用人口普查區進行比較時,會因大小不一致而受到影響,因此必須套用修正因子,才能在人口普查區之間進行類似的比較。此外,人口普查區和其他行政邊界會隨時間變更,需要花費心力修正這些變更。使用格線系統進行空間分析,即可解決這類難題。
使用向量搜尋和向量索引
最佳做法:使用向量搜尋和向量索引,進行最鄰近的地理空間查詢。
BigQuery 導入向量搜尋功能,可支援語意搜尋、相似度偵測和檢索增強生成等機器學習用途。啟用這些用途的關鍵在於一種稱為「近似最鄰近搜尋」的索引方法。您可以透過比較代表空間中點的向量,使用向量搜尋加快及簡化最鄰近的地理空間查詢。
您可以使用向量搜尋功能,依半徑搜尋特徵。首先,請設定搜尋半徑。您可以在最鄰近搜尋的結果集中,找出最佳半徑。建立半徑後,請使用 ST_DWITHIN 函式識別附近的特徵。
舉例來說,假設您已知道特定錨定建築物的位置,可以找出距離該建築物最近的十棟建築物。您可以將每個建築物的質心儲存為新資料表中的向量、為資料表建立索引,並使用向量搜尋功能進行搜尋。
在本範例中,您也可以使用 BigQuery 中的 Overture Maps 資料,建立與感興趣區域對應的建築物形狀資料表,以及名為 geom_vector 的向量。在本範例中,感興趣的區域是美國維吉尼亞州諾福克市,以 FIPS 程式碼 51710 表示,如下列程式碼範例所示:
CREATE TABLE vector_search.norfolk_buildings
AS (
SELECT
*,
[
ST_X(ST_CENTROID(building.geometry)),
ST_Y(ST_CENTROID(building.geometry))] AS geom_vector
FROM `bigquery-public-data.overture_maps.building` AS building
INNER JOIN `bigquery-public-data.geo_us_boundaries.counties` AS county
ON (st_intersects(county.county_geom, building.geometry))
WHERE county.county_fips_code = '51710'
)
以下程式碼範例顯示如何在資料表上建立向量索引:
CREATE
vector index building_vector_index
ON
vector_search.norfolk_buildings(geom_vector)
OPTIONS (index_type = 'IVF')
這項查詢會找出特定錨定建築物附近 10 棟建築物:
SELECT base.*
FROM
VECTOR_SEARCH(
TABLE vector_search.norfolk_buildings,
'geom_vector',
(
SELECT
geom_vector
FROM
vector_search.norfolk_buildings
WHERE id = '56873794-9873-4fe1-871a-5987bb3a0efb'
),
top_k => 10,
distance_type => 'EUCLIDEAN',
options => '{"fraction_lists_to_search":0.1}')
在「查詢結果」窗格中,按一下「圖表」分頁標籤。地圖會顯示最靠近錨定建築物的建築物形狀叢集:
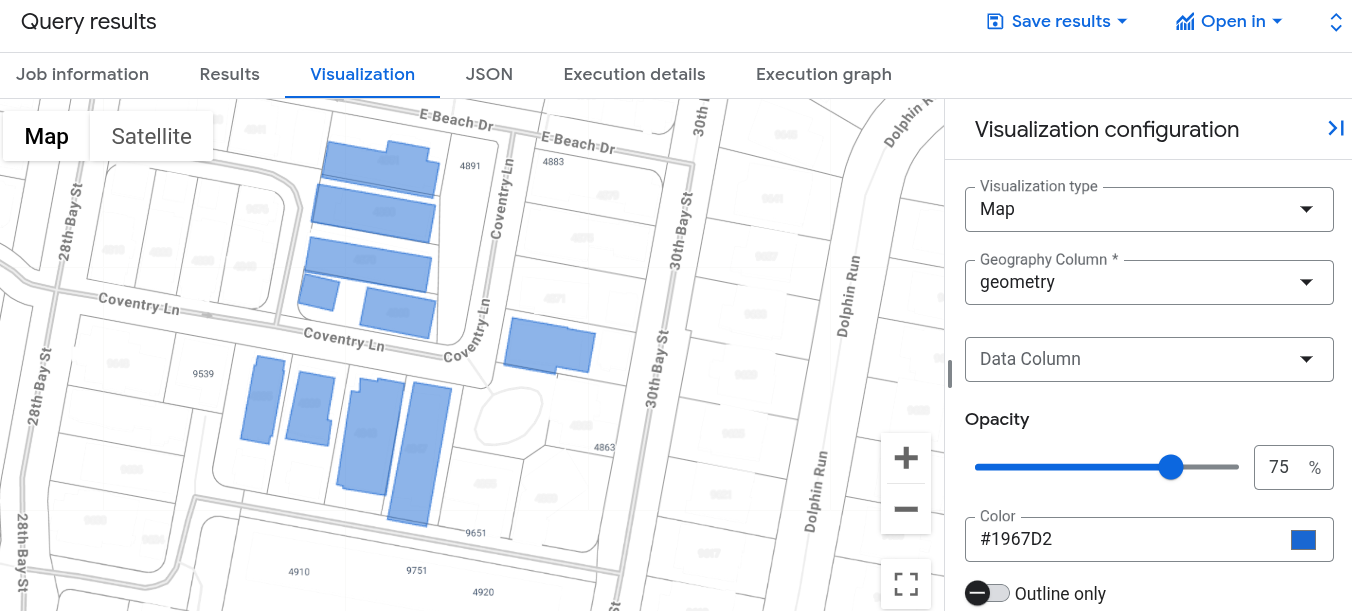
在 Google Cloud 控制台中執行這項查詢時,請按一下「工作資訊」,並確認「向量索引使用模式」設為 FULLY_USED。這表示查詢正在運用您稍早建立的 building_vector_index 向量索引。
分割大型形狀
最佳做法:使用 ST_SUBDIVIDE 函式分割大型形狀。
使用 ST_SUBDIVIDE 函式將大型形狀或長線字串分割成較小的形狀。
後續步驟
- 瞭解如何使用格線系統進行空間分析。
- 進一步瞭解 BigQuery 地理函式。
- 瞭解如何管理向量索引。
- 進一步瞭解 BigQuery 空間索引和叢集功能的最佳做法。
- 如要進一步瞭解如何在 BigQuery 中分析及視覺化呈現地理空間資料,請參閱「開始使用地理空間分析」。