En este instructivo, usarás un modelo de regresión logística binario en BigQuery ML para predecir el rango de ingresos de las personas según sus datos demográficos. Un modelo de regresión logística binaria predice si un valor pertenece a una de dos categorías, en este caso, si el ingreso anual de una persona es superior o inferior a USD 50,000.
En este instructivo, se usa el conjunto de datos bigquery-public-data.ml_datasets.census_adult_income. Este conjunto de datos contiene la información demográfica y de ingresos de los residentes de EE.UU. de los años 2000 y 2010.
Objetivos
En este instructivo, realizarás las siguientes tareas:- Crearás un modelo de regresión logística.
- Evalúa el modelo.
- Haz predicciones mediante el modelo.
- Explica los resultados que generó el modelo.
Costos
En este instructivo, se usan los siguientes componentes facturables de Google Cloud:
- BigQuery
- BigQuery ML
Para obtener más información sobre los costos de BigQuery, consulta la página Precios de BigQuery.
Para obtener más información sobre los costos de BigQuery ML, consulta los precios de BigQuery ML.
Antes de comenzar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Permisos necesarios
Para crear el modelo con BigQuery ML, necesitas los siguientes permisos de IAM:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Para ejecutar inferencias, necesitas los siguientes permisos:
bigquery.models.getDataen el modelobigquery.jobs.create
Introducción
Una tarea común con el aprendizaje automático es clasificar los datos en uno de dos tipos, conocidos como etiquetas. Por ejemplo, es posible que un minorista quiera predecir si un cliente determinado comprará un producto nuevo en función de otra información sobre ese cliente. En ese caso, las dos etiquetas podrían ser will buy y won't buy. El minorista puede construir un conjunto de datos de modo que una columna represente ambas etiquetas y también contenga información del cliente, como su ubicación, sus compras anteriores y sus preferencias informadas. Luego, el comercio puede usar un modelo de regresión logística binaria que utilice esta información del cliente para predecir qué etiqueta representa mejor a cada cliente.
En este instructivo, crearás un modelo de regresión logística binaria que prediga si el ingreso de un encuestado del censo de EE.UU. se encuentra en uno de los dos rangos según los atributos demográficos del encuestado.
Crea un conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
census.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU. (varias regiones en Estados Unidos).
Los conjuntos de datos públicos se almacenan en la multirregión
US. Para que sea más simple, almacena tu conjunto de datos en la misma ubicación.Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.
Examina los datos
Examina el conjunto de datos y, luego, identifica qué columnas usar como datos de entrenamiento para el modelo de regresión logística. Selecciona 100 filas de la tabla census_adult_income:
SQL
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, ejecuta la siguiente consulta de GoogleSQL:
SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, functional_weight FROM `bigquery-public-data.ml_datasets.census_adult_income` LIMIT 100;
Los resultados son similares a los siguientes:

BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Los resultados de la consulta muestran que la columna income_bracket de la tabla census_adult_income tiene solo uno de dos valores: <=50K o >50K.
Prepara los datos de muestra
En este instructivo, predecirás el ingreso del encuestado del censo en función de los valores de las siguientes columnas de la tabla census_adult_income:
age: Es la edad del encuestado.workclass: Clase de trabajo realizado. Por ejemplo, gobierno local, privado o trabajador independiente.marital_statuseducation_num: Es el nivel más alto de educación del encuestado.occupationhours_per_week: Horas trabajadas por semana.
Excluyes las columnas que duplican datos. Por ejemplo, la columna education, ya que los valores de las columnas education y education_num expresan los mismos datos en diferentes formatos.
La columna functional_weight muestra la cantidad de personas que la organización del censo cree que representa una fila en particular. Dado que el valor de esta columna no se relaciona con el valor de income_bracket para ninguna fila determinada, usas el valor de esta columna para separar los datos en conjuntos de entrenamiento, evaluación y predicción creando una nueva columna dataframe que se deriva de la columna functional_weight. Etiqueta el 80% de los datos para entrenar el modelo, el 10% de los datos para la evaluación y el 10% de los datos para la predicción.
SQL
Crea una vista con los datos de muestra.
Esta vista se usa en la declaración CREATE MODEL más adelante en este instructivo.
Ejecuta la consulta que prepara los datos de muestra:
En la consola de Google Cloud , ve a la página BigQuery.
En el Editor de consultas, ejecute la siguiente consulta:
CREATE OR REPLACE VIEW `census.input_data` AS SELECT age, workclass, marital_status, education_num, occupation, hours_per_week, income_bracket, CASE WHEN MOD(functional_weight, 10) < 8 THEN 'training' WHEN MOD(functional_weight, 10) = 8 THEN 'evaluation' WHEN MOD(functional_weight, 10) = 9 THEN 'prediction' END AS dataframe FROM `bigquery-public-data.ml_datasets.census_adult_income`;
Sigue estos pasos para ver los datos de muestra:
SELECT * FROM `census.input_data`;
Permite trabajar con BigQuery DataFrames.
Crea un DataFrame llamado input_data. Usarás input_data más adelante en este instructivo para entrenar el modelo, evaluarlo y hacer predicciones.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Crea un modelo de regresión logística
Crea un modelo de regresión logística con los datos de entrenamiento que etiquetaste en la sección anterior.
SQL
Usa la sentencia CREATE MODEL y especifica LOGISTIC_REG para el tipo de modelo.
La siguiente información es útil para saber sobre la declaración CREATE MODEL:
La opción
input_label_colsespecifica qué columna de la instrucciónSELECTse usará como columna de la etiqueta. Aquí, la columna de la etiqueta esincome_bracket, por lo que el modelo aprende cuál de los dos valores deincome_bracketes más probable para una fila determinada en función de los demás valores presentes en esa fila.No es necesario especificar si un modelo de regresión logística es binario o de varias clases. BigQuery ML determina qué tipo de modelo entrenar según la cantidad de valores únicos en la columna de la etiqueta.
La opción
auto_class_weightsse establece enTRUEpara equilibrar las etiquetas de clase en los datos de entrenamiento. De forma predeterminada, los datos de entrenamiento no están ponderados. Si las etiquetas en los datos de entrenamiento no tienen un equilibrio, el modelo puede aprender a predecir la clase de etiquetas más popular, lo que podría no ser conveniente. En este caso, la mayoría de los encuestados en el conjunto de datos están en el segmento de ingresos más bajos. Esto puede ocasionar que un modelo prediga el rango de ingresos más bajos con demasiada frecuencia. Los pesos de clase equilibran las etiquetas de clase calculando los pesos de cada clase en proporción inversa a la frecuencia de esa clase.La opción
enable_global_explainse establece enTRUEpara permitirte usar la funciónML.GLOBAL_EXPLAINen el modelo más adelante en el instructivo.La sentencia
SELECTconsulta la vistainput_dataque contiene los datos de muestra. La cláusulaWHEREfiltra las filas para que solo se usen aquellas etiquetadas como datos de entrenamiento para entrenar el modelo.
Ejecuta la consulta que crea tu modelo de regresión logística:
En la consola de Google Cloud , ve a la página BigQuery.
En el Editor de consultas, ejecute la siguiente consulta:
CREATE OR REPLACE MODEL `census.census_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, enable_global_explain=TRUE, data_split_method='NO_SPLIT', input_label_cols=['income_bracket'], max_iterations=15) AS SELECT * EXCEPT(dataframe) FROM `census.input_data` WHERE dataframe = 'training'
En el panel Explorador, haz clic en Conjuntos de datos.
En el panel Conjuntos de datos, haz clic en
census.Haz clic en el panel Modelos.
Haz clic en
census_model.En la pestaña Detalles, se enumeran los atributos que BigQuery ML usó para realizar la regresión logística.
Permite trabajar con BigQuery DataFrames.
Usa el método fit para entrenar el modelo y el método to_gbq para guardarlo en tu conjunto de datos.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Evalúa el rendimiento del modelo
Después de crear el modelo, evalúa su rendimiento en comparación con los datos de evaluación.
SQL
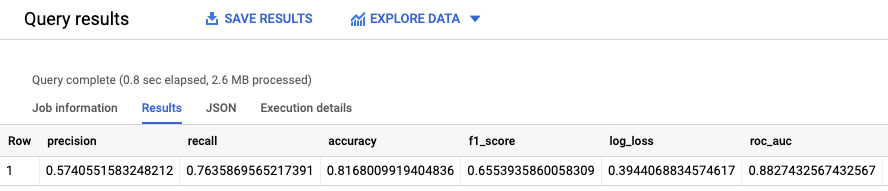
La función ML.EVALUATE evalúa los valores predichos que generó el modelo con los datos de evaluación.
Como entrada, la función ML.EVALUATE toma el modelo entrenado y las filas de la vista input_data que tienen evaluation como valor de la columna dataframe. La función muestra una sola fila de estadísticas del modelo.
Ejecuta la consulta ML.EVALUATE:
En la consola de Google Cloud , ve a la página BigQuery.
En el Editor de consultas, ejecute la siguiente consulta:
SELECT * FROM ML.EVALUATE (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation' ) );
Los resultados son similares a los siguientes:
BigQuery DataFrames
Usa el método score para evaluar el modelo en comparación con los datos reales.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
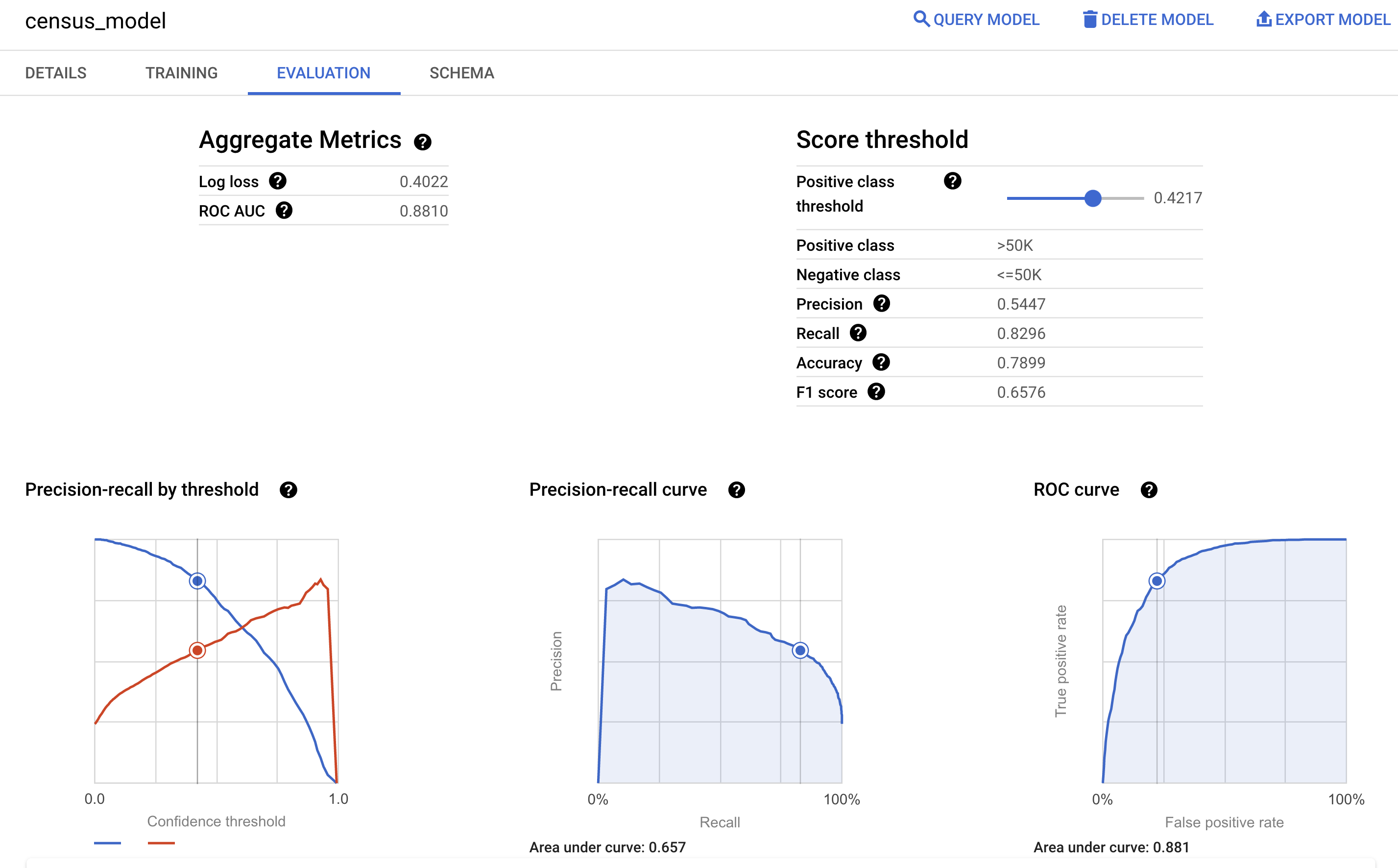
También puedes ver el panel Evaluación del modelo en la consola Google Cloud para ver las métricas de evaluación calculadas durante el entrenamiento:
Predecir el rango de ingresos
Usa el modelo para predecir el rango de ingresos más probable para cada encuestado.
SQL
Usa la función ML.PREDICT para hacer predicciones sobre el rango de ingresos probable. Como entrada, la función ML.PREDICT toma el modelo entrenado y las filas de la vista input_data que tienen prediction como el valor de la columna dataframe.
Ejecuta la consulta ML.PREDICT:
En la consola de Google Cloud , ve a la página BigQuery.
En el Editor de consultas, ejecute la siguiente consulta:
SELECT * FROM ML.PREDICT (MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'prediction' ) );
Los resultados son similares a los siguientes:
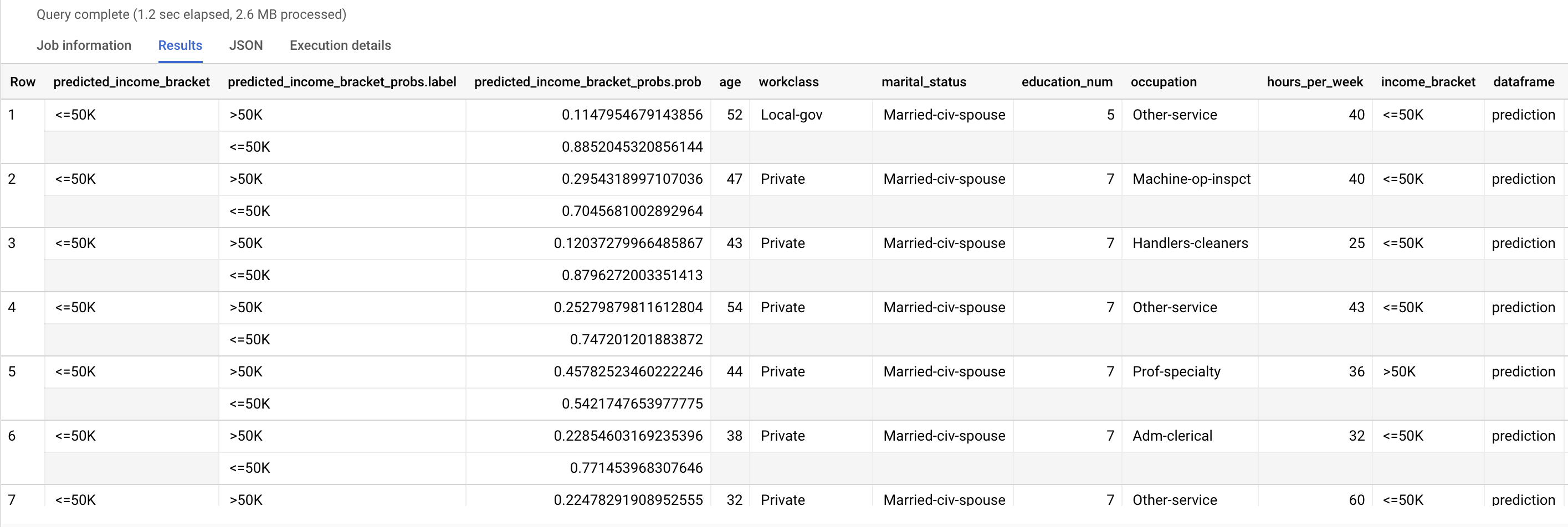
La columna predicted_income_bracket contiene el rango de ingresos previsto para el encuestado.
Permite trabajar con BigQuery DataFrames.
Usa el método predict para hacer predicciones sobre el rango de ingresos probable.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Explica los resultados de la predicción
Para comprender por qué el modelo genera estos resultados de predicción, puedes usar la función ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT es una versión extendida de la función ML.PREDICT.
ML.EXPLAIN_PREDICT no solo genera resultados de predicción, sino también columnas adicionales para explicar los resultados de la predicción. Para obtener más información sobre la interpretabilidad, consulta la descripción general de Explainable AI para BigQuery ML.
Ejecuta la consulta ML.EXPLAIN_PREDICT:
En la consola de Google Cloud , ve a la página BigQuery.
En el Editor de consultas, ejecute la siguiente consulta:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `census.census_model`, ( SELECT * FROM `census.input_data` WHERE dataframe = 'evaluation'), STRUCT(3 as top_k_features));
Los resultados son similares a los siguientes:
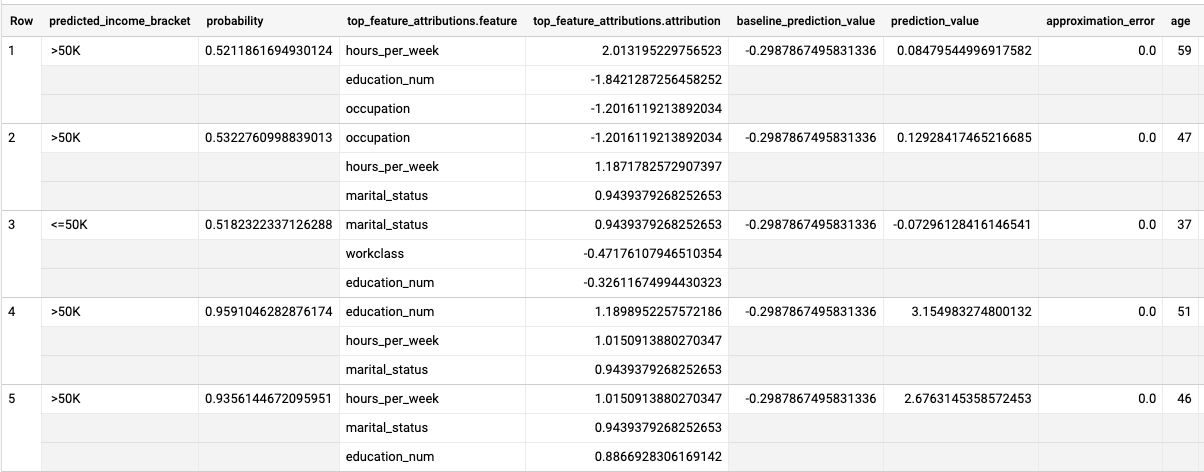
En el caso de los modelos de regresión logística, se usan los valores de Shapley para determinar la atribución relativa de cada atributo del modelo. Dado que la opción top_k_features se estableció en 3 en la consulta, ML.EXPLAIN_PREDICT genera las tres atribuciones de atributos principales para cada fila de la vista input_data. Estas atribuciones se muestran en orden descendente según el valor absoluto de la atribución.
Explica el modelo de forma global
Para saber qué características son las más importantes a fin de determinar el rango de ingresos, usa la función ML.GLOBAL_EXPLAIN.
Obtén explicaciones globales para el modelo:
En la consola de Google Cloud , ve a la página BigQuery.
En el Editor de consultas, ejecuta la siguiente consulta para obtener explicaciones globales:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `census.census_model`)
Los resultados son similares a los siguientes:
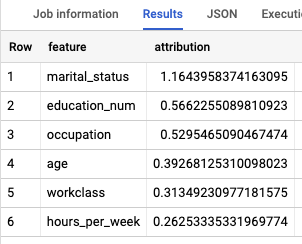
Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra tu conjunto de datos
Borrar tu proyecto quita todos sus conjuntos de datos y tablas. Si prefieres volver a usar el proyecto, puedes borrar el conjunto de datos que creaste en este instructivo:
Si es necesario, abre la página de BigQuery en la consola deGoogle Cloud .
En la navegación, haz clic en el conjunto de datos census que creaste.
Haz clic en Borrar conjunto de datos en el lado derecho de la ventana. Esta acción borra el conjunto de datos y el modelo.
En el cuadro de diálogo Borrar conjunto de datos, escribe el nombre del conjunto de datos (
census) para confirmar el comando de borrado y, luego, haz clic en Borrar.
Borra tu proyecto
Para borrar el proyecto, haz lo siguiente:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
¿Qué sigue?
- Para obtener una descripción general de BigQuery ML, consulta Introducción a BigQuery ML.
- Para obtener información sobre cómo crear modelos, consulta la página de sintaxis de
CREATE MODEL.