What is BI Engine?
BigQuery BI Engine is a fast, in-memory analysis service that accelerates many SQL queries in BigQuery by intelligently caching the data you use most frequently. BI Engine can accelerate SQL queries from any source, including those written by data visualization tools, and can manage cached tables for on-going optimization. This lets you improve query performance without manual tuning or data tiering. You can use clustering and partitioning to further optimize the performance of large tables with BI Engine.
For example, if your dashboard only displays the last quarter's data, then consider partitioning your tables by time so only the latest partitions are loaded into memory. You can also combine the benefits of materialized views and BI Engine. This works particularly well when the materialized views are used to join and flatten data to optimize their structure for BI Engine.
BI Engine provides the following advantages:
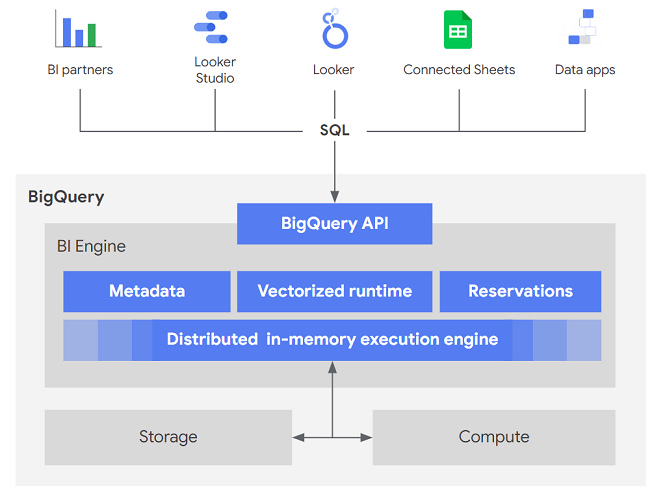
- BigQuery API: BI Engine directly integrates with the BigQuery API. Any BI solution or custom application that works with the BigQuery API through standard mechanisms such as REST or JDBC and ODBC drivers can use BI Engine without modification.
- Vectorized runtime: With the BI Engine SQL interface, BI Engine introduces a more modern technique called vectorized processing. Using vectorized processing in an execution engine makes more efficient use of modern CPU architecture, by operating on batches of data at a time. BI Engine also uses advanced data encodings, specifically, dictionary run-length encoding, to further compress the data that's stored in the in-memory layer.
- Seamless integration: BI Engine works with BigQuery features and metadata, including authorized views, column level security, and data masking.
- Reservations: BI Engine reservations manage memory allocation at the project location level. BI Engine caches specific columns or partitions that are queried, prioritizing those in tables marked as preferred.
About the BI Engine SQL interface
The BI Engine SQL interface expands BI Engine to integrate with other business intelligence (BI) tools such as Looker, Tableau, Power BI, and custom applications to accelerate data exploration and analysis. This page provides an overview of the BI Engine SQL interface, and the expanded capabilities that it brings to BI Engine.
BI Engine use cases
BI Engine can significantly accelerate many SQL queries, including those used for BI dashboards. Acceleration is most effective if you identify the tables that essential to your queries and then mark them as preferred tables. To use BI Engine, create a reservation that defines the storage capacity dedicated to BI Engine. You can let BigQuery determine which tables to cache based on the project's usage patterns or you can mark specific tables to prevent other traffic from interfering with acceleration.
BI Engine is useful in the following use cases:
- You use BI tools to analyze your data: The BI Engine SQL interface can accelerate BigQuery queries regardless of whether they run in the BigQuery console, client library, or through an API or an ODBC or JDBC connector. This can significantly improve the performance of dashboards connected to BigQuery through a built-in connection (API) or connectors.
- You have certain tables that are queried most frequently: BI Engine lets you designate specific preferred tables to accelerate. This is helpful if you have a subset of tables that are queried more frequently or are used for high-visibility dashboards.
BI Engine might not fit your needs in the following cases:
You use wildcards in your queries: Queries referencing wildcard tables are not supported by BI Engine and don't benefit from acceleration.
You rely heavily on BigQuery features which BI Engine doesn't support: While BI Engine supports most SQL functions and operators when connecting business intelligence (BI) tools to BigQuery, there are unsupported features, including external tables and non-SQL user-defined functions.
Considerations for BI Engine
Consider the following when deciding how to configure BI Engine:
Ensure acceleration for specific queries
You can ensure a particular set of queries always gets accelerated by creating a separate project with a BI Engine reservation. To do so, you should ensure that the BI Engine reservation in that project is large enough to match the size of all tables used in those queries and designate those tables as preferred tables for BI Engine. Only those queries that need to be accelerated should be run in that project.
Minimize your joins
BI Engine works best with pre-joined or pre-aggregated, and with data in a small number of joins. This is particularly true when one side of the join is large and the others are much smaller such as when you query a large fact table joined with a small dimension table. You can combine BI Engine with materialized views that which perform joins to produce a single large, flat table. In this way, the same joins don't have to be performed on every query.
Understand the impact of BI Engine
To understand your utilization of BI Engine, see
Monitor BI Engine with Cloud Monitoring,
or query the
INFORMATION_SCHEMA.BI_CAPACITIES
and
INFORMATION_SCHEMA.BI_CAPACITY_CHANGES
views. Be sure to disable the Use cached results
option in BigQuery to get the most accurate comparison. For more
information, see Use cached query results.
Quotas and limitations
See BigQuery quotas and limits for quotas and limits that apply to BI Engine.
Pricing
For information on BI Engine pricing, see the BigQuery Pricing page.
What's next
- To learn how to create your BI Engine reservation, see Reserve BI Engine capacity.
- For information designating preferred tables, see BI Engine preferred tables.
- To understand your utilization of BI Engine, see Monitor BI Engine with Cloud Monitoring.
- Learn about BI Engine optimized functions
- Learn how to use BI Engine with the following: