Este documento es la segunda parte de una serie en la que se trata la recuperación ante desastres (DR) en Google Cloud. En esta parte, se analizan los servicios y los productos que puedes usar como componentes básicos del plan de DR, incluidos los productos de Google Cloud y los que funcionan en distintas plataformas.
La serie consta de estas partes:
- Guía de planificación para la recuperación ante desastres
- Componentes básicos de la recuperación ante desastres (este artículo)
- Situaciones de recuperación ante desastres para datos
- Situaciones de recuperación ante desastres para aplicaciones
- Arquitectura de recuperación ante desastres para cargas de trabajo con restricciones de localidad
- Casos de uso de recuperación ante desastres: aplicaciones de análisis de datos con restricciones de localidad
- Arquitectura de recuperación ante desastres para interrupciones de infraestructura de nube
Introducción
Google Cloud tiene una amplia gama de productos que puedes usar como parte de la arquitectura de recuperación ante desastres (DR). En esta sección, analizamos las funciones relacionadas con la DR de los productos que se usan con mayor frecuencia como componentes básicos de la DR de Google Cloud.
Muchos de estos servicios tienen funciones de alta disponibilidad (HA). La HA no se solapa completamente con la recuperación ante desastres, pero muchos de los objetivos de la HA también se aplican al diseño de un plan de recuperación ante desastres. Por ejemplo, si aprovechas las funciones de HA, puedes diseñar arquitecturas que optimicen el tiempo de actividad y que mitiguen los efectos de fallas de pequeña escala, como la falla de una sola máquina virtual (VM). Para obtener más información sobre la relación entre la DR y la HA, consulta la Guía de planificación de recuperación ante desastres.
En las siguientes secciones, se describen estos componentes básicos de la DR de Google Cloud y cómo te ayudan a implementar los objetivos de DR.
Compute y almacenamiento
|
|
|
|
|
Compute Engine
Compute Engine proporciona instancias de máquina virtual (VM); es un producto imprescindible de Google Cloud. Además de configurar, iniciar y supervisar instancias de Compute Engine, por lo general, usas una variedad de funciones relacionadas para implementar un plan de DR.
Para las situaciones de DR, puedes evitar la eliminación accidental de VM si configuras la marca de protección contra eliminaciones. Esto es útil sobre todo cuando alojas servicios con estado, como bases de datos. A fin de que sea más fácil lograr valores bajos de RTO y RPO, sigue las prácticas recomendadas para diseñar sistemas sólidos.
Puedes configurar una instancia con tu aplicación preinstalada; luego, guarda esa configuración como una imagen personalizada. Tu imagen personalizada puede reflejar el RTO que deseas lograr.
Plantillas de instancia
Puedes usar las plantillas de instancias de Compute Engine para guardar los detalles de configuración de la VM y, luego, crear instancias a partir de las plantillas de instancias existentes. Puedes usar la plantilla para iniciar la cantidad de instancias que necesites; además, podrás configurar esa plantilla de la manera que desees cuando sea necesario poner en funcionamiento el entorno de destino de DR. Las plantillas de instancias se replican de manera global, por lo que puedes recrear la instancia con la misma configuración en cualquier lugar de Google Cloud.
Puedes crear plantillas de instancias mediante una imagen personalizada o a partir de instancias de VM existentes.
Proporcionaremos más detalles sobre el uso de las imágenes de Compute Engine en la sección de equilibrio de configuración de imagen y velocidad de implementación más adelante en este documento.
Grupos de instancias administrados
Los grupos de instancias administrados funcionan con Cloud Load Balancing (que se explica más adelante en este documento) para distribuir el tráfico en grupos de instancias configuradas de forma idéntica, las cuales se copian en todas las zonas. Los grupos de instancias administrados permiten funciones como el ajuste de escala automático y la recuperación automática, en las que el grupo de instancias administrado puede borrar y recrear instancias automáticamente.
Reservas
Compute Engine permite la reserva de instancias de VM en una zona específica, mediante tipos de máquinas personalizados o predefinidos, con o sin SSD locales o GPU adicionales. A fin de garantizar la capacidad de tus cargas de trabajo esenciales para el DR, debes crear reservas en tus zonas de destino de DR. Sin reservas, existe la posibilidad de que no obtengas la capacidad a pedido que necesitas para cumplir con tu objetivo de tiempo de recuperación. Las reservas pueden ser útiles en situaciones de DR frías, tibias o calientes. Te permiten mantener los recursos de recuperación disponibles para la conmutación por error a fin de satisfacer las necesidades de RTO más bajas, sin tener que configurarlos ni implementarlos completamente por adelantado.
Instantáneas y discos persistentes
Los discos persistentes son dispositivos de almacenamiento de red duraderos a los que pueden acceder las instancias. Son independientes de las instancias, por lo que puedes separar y mover discos persistentes para mantener tus datos incluso después de borrar las instancias.
Puedes realizar copias de seguridad o instantáneas incrementales de las VM de Compute Engine en diferentes regiones y utilizarlas para recrear discos persistentes en caso de un desastre. Además, puedes crear instantáneas de discos persistentes para obtener protección contra la pérdida de datos debido a un error del usuario. Las instantáneas son incrementales y crearlas solo te llevará unos minutos, incluso si tus discos de instantáneas se encuentran adjuntos a instancias en ejecución.
Los discos persistentes tienen redundancia incorporada a fin de proteger los datos contra fallas del equipo, así como para garantizar la disponibilidad de los datos a través de eventos de mantenimiento del centro de datos. Los discos persistentes pueden ser zonales o regionales. Los discos persistentes regionales replican escrituras en dos zonas de una región. En el caso de una interrupción zonal, una instancia de VM de copia de seguridad puede forzar la conexión de un disco persistente regional en la zona secundaria. Para obtener más información, consulta Opciones de alta disponibilidad con discos persistentes regionales.
Migración en vivo
La migración en vivo mantiene las instancias de VM en ejecución aun cuando ocurre un evento del sistema de host, como la actualización de hardware o software. Compute Engine realiza migraciones en vivo de las instancias en ejecución a otro host en la misma zona, y no requiere que tus VM se reinicien. Esto le permite a Google realizar un mantenimiento integral para que la infraestructura esté protegida y siga siendo confiable, sin interrumpir ninguna de tus VM.
Herramienta de importación de discos virtuales
La herramienta de importación de discos virtuales te permite importar formatos de archivo, incluidos VMDK, VHD y RAW, para crear máquinas virtuales nuevas de Compute Engine. Con esta herramienta, puedes crear máquinas virtuales de Compute Engine que tengan la misma configuración que tus máquinas virtuales locales. Este es un método adecuado que puedes aplicar cuando no puedas configurar las imágenes de Compute Engine a partir de los objetos binarios de origen del software que ya está instalado en las imágenes.
Cloud Storage
Cloud Storage es un depósito de objetos ideal para almacenar los archivos de copia de seguridad. Proporciona diferentes clases de almacenamiento que son adecuadas para casos prácticos específicos, como se describe en el siguiente diagrama.

En situaciones de DR, Nearline, Coldline y Archive Storage son de especial interés. Estas clases de almacenamiento reducen el costo de almacenamiento en comparación con la clase Standard Storage. Sin embargo, existen costos adicionales relacionados con la recuperación de datos o metadatos almacenados en esas clases, así como los períodos de duración mínima del almacenamiento por los que se te cobra. Nearline está diseñado para situaciones de copias de seguridad en las que el acceso ocurre, como máximo, una vez al mes. Esto resulta ideal para que puedas realizar pruebas de esfuerzo de DR regulares y mantener los costos bajos.
Nearline, Coldline y Archive están optimizadas para el acceso poco frecuente, y esto se tuvo en cuenta para diseñar el modelo de precios. Por lo tanto, se te cobra por la duración mínima de almacenamiento, y hay costos adicionales por la recuperación de datos o metadatos en estas clases antes de la duración mínima de almacenamiento correspondiente a la clase.
Para proteger tus datos en un bucket de Cloud Storage contra la eliminación accidental o maliciosa, puedes usar la función de eliminación no definitiva para conservar los objetos borrados y reemplazados durante un período específico.
El Servicio de transferencia de almacenamiento te permite importar datos de Amazon S3 o de fuentes basadas en HTTP a Cloud Storage. En las situaciones de DR, puedes usar el Servicio de transferencia de almacenamiento para llevar a cabo las siguientes tareas:
- Realizar una copia de seguridad de los datos de otros proveedores de almacenamiento en un bucket de Cloud Storage
- Transferir los datos de un bucket en una región doble o múltiple a un bucket en una región para reducir los costos de almacenamiento de las copias de seguridad.
Filestore
Las instancias de Filestore son servidores de archivos NFS completamente administrados que se usan con aplicaciones que se ejecutan en instancias de Compute Engine o clústeres de GKE.
Las instancias de Filestore son zonales y no admiten la replicación
entre zonas. Una instancia de Filestore no está disponible si la zona en la que reside está inactiva. Te recomendamos realizar una copia de seguridad de tus datos de forma periódica mediante la sincronización del volumen de Filestore con una instancia de Filestore en otra región con el comando gsutil rsync. Esto requiere que se programe un trabajo para que se ejecute en instancias de Compute Engine o en clústeres de GKE.
En las situaciones de DR, las aplicaciones pueden reanudar el acceso a los volúmenes de Filestore con rapidez si se cambian a Filestore en regiones de conmutación por error sin tener que esperar a que finalice un proceso de restablecimiento. El valor de RTO de esta solución de DR depende en gran medida de la frecuencia del trabajo programado.
GKE
GKE es un entorno administrado y listo para la producción que permite implementar aplicaciones en contenedores. GKE te permite organizar sistemas de alta disponibilidad; además, incluye las siguientes funciones:
- Reparación automática del nodo. Si un nodo falla en varias verificaciones de estado consecutivas durante un período prolongado (aproximadamente 10 minutos), GKE iniciará un proceso de reparación para ese nodo.
- Sondeo de capacidad de respuesta. Puedes especificar un sondeo de capacidad de respuesta, el cual, periódicamente, le dice a GKE que el pod se está ejecutando. Si el pod falla durante el sondeo, se puede reiniciar.
- Volúmenes persistentes. Las bases de datos deben tener la capacidad de persistir más allá de la vida útil de un contenedor. Si usas la abstracción de volúmenes persistentes, que se asigna a un disco persistente de Compute Engine, podrás conservar la disponibilidad del almacenamiento independientemente de los contenedores individuales.
- Clústeres multizona y regionales. Puedes distribuir los recursos de Kubernetes en varias zonas dentro de una región.
- La puerta de enlace de varios clústeres te permite configurar recursos de balanceo de cargas compartidos en varios clústeres de GKE en diferentes regiones.
- La Copia de seguridad para GKE te permite crear copias de seguridad de las cargas de trabajo y restablecerlas en clústeres de GKE.
Herramientas de redes y transferencia de datos
|
|
|
|
|
|
|
Cloud Load Balancing
Cloud Load Balancing proporciona alta disponibilidad para Compute Engine mediante la distribución de solicitudes de usuarios entre un conjunto de instancias. Puedes configurar Cloud Load Balancing con verificaciones de estado, que determinan si las instancias están disponibles para realizar tareas, de modo que el tráfico no se enrute hacia las instancias con errores.
Cloud Load Balancing proporciona una única dirección IP accesible a nivel global para enfrentar las instancias de Compute Engine. Tu aplicación puede tener instancias que se ejecutan en diferentes regiones (por ejemplo, en Europa y en los EE.UU.), y tus usuarios finales se dirigen al conjunto de instancias más cercano. Además de proporcionar un balanceo de cargas destinado a los servicios que están expuestos a Internet, puedes configurar un balanceo de cargas interno para los servicios detrás de una dirección IP privada de balanceo de cargas. Solo las instancias de VM que son internas de la nube privada virtual (VPC) pueden acceder a esta dirección IP.
Traffic Director
Con Traffic Director, puedes implementar un plano de control de tráfico completamente administrado para la malla de servicios. Traffic Director administra la configuración de los proxies de servicio que se ejecutan en Compute Engine y GKE. Implementa un servicio en varias regiones para que tenga HA. Traffic Director descargará las verificaciones de estado del servicio e iniciará una configuración de conmutación por error de los proxies de servicio, lo que redireccionará el tráfico a instancias en buen estado.
Traffic Director también es compatible con los conceptos avanzados de control de tráfico, las interrupciones del circuito y la inserción de errores. Mediante la interrupción del circuito, puedes aplicar límites en las solicitudes a un servicio en particular. Una vez alcanzado el límite, las solicitudes no pueden llegar al servicio, lo que evita que este se degrade aún más. Con la inserción de errores, Traffic Director puede ingresar demoras o anular una fracción de solicitudes a un servicio, lo que te permite probar la capacidad del servicio de sobrevivir a las demoras de las solicitudes o a las solicitudes anuladas.
Cloud DNS
Cloud DNS proporciona una manera programática de administrar tus entradas de DNS como parte de un proceso de recuperación automatizado. Cloud DNS usa la red mundial de servidores de nombres Anycast de Google para entregar datos en las zonas de DNS desde ubicaciones redundantes en todo el mundo, lo que proporciona alta disponibilidad y baja latencia a los usuarios.
Si eliges administrar las entradas de DNS de forma local, puedes habilitar las VM en Google Cloud para resolver estas direcciones por medio del reenvío de Cloud DNS.
Cloud Interconnect
Cloud Interconnect proporciona formas de transferir información de otras fuentes a Google Cloud. Analizaremos este producto más adelante en la sección Transfiere datos hacia y desde Google Cloud.
Administración y supervisión
| Panel de estado de Cloud |
|
|
Panel de estado de Cloud
En el Panel de estado de Cloud, se muestra la disponibilidad actual de los servicios de Google Cloud. Puedes ver el estado en la página y suscribirte a un feed RSS que se actualiza cada vez que hay noticias sobre un servicio.
Cloud Monitoring
Cloud Monitoring recopila métricas, eventos y metadatos de Google Cloud, AWS, sondeos de tiempo de actividad alojados, instrumentación de aplicaciones y una variedad de otros componentes de la aplicación. Puedes configurar alertas para enviar notificaciones a herramientas de terceros, como Slack o Pagerduty, con el fin de proporcionar actualizaciones oportunas a los administradores. Otra forma de usar Cloud Monitoring para la DR es configurar un receptor de Pub/Sub y usar Cloud Functions a fin de activar un proceso automatizado en respuesta a una alerta de Cloud Monitoring.
Componentes básicos de la recuperación ante desastres multiplataforma
Cuando ejecutas cargas de trabajo en más de una plataforma, una manera de reducir la sobrecarga operativa es seleccionar herramientas que funcionen con todas las plataformas que utilices. En esta sección, analizaremos algunas herramientas y servicios que son independientes de la plataforma y, por lo tanto, son compatibles con las situaciones de DR multiplataforma.
Herramientas de plantillas declarativas
Las herramientas de plantillas declarativas te permiten automatizar la implementación de infraestructura en todas las plataformas. Terraform es una herramienta popular de plantillas declarativas.
Herramientas de administración de configuración
Para una infraestructura de recuperación ante desastres grande o compleja, recomendamos herramientas de administración de software independientes de la plataforma, como Chef y Ansible. Estas herramientas aseguran que se puedan aplicar configuraciones reproducibles sin importar dónde se encuentre la carga de trabajo de Compute.
Almacenamiento de objetos
Un patrón de DR común consiste en tener copias de objetos en almacenes de objetos en diferentes proveedores de servicios en la nube. Una herramienta multiplataforma útil para esto es boto, que consiste en una biblioteca de código abierto de Python que te permite interactuar con Amazon S3 y Cloud Storage.
Herramientas de organizador
Los contenedores también pueden considerarse componentes básicos para la recuperación ante desastres. Los contenedores son una forma de empaquetar servicios y lograr que haya coherencia en todas las plataformas.
Si trabajas con contenedores, generalmente usas un organizador. Kubernetes no solo funciona para administrar contenedores dentro de Google Cloud (mediante GKE), sino que también proporciona una forma de organizar las cargas de trabajo basadas en contenedores en varias plataformas. Google Cloud, AWS y Microsoft Azure proporcionan versiones administradas de Kubernetes.
Para distribuir el tráfico a los clústeres de Kubernetes que se ejecutan en diferentes plataformas de Cloud, puedes usar un servicio DNS que admita registros ponderados y que incorpore la verificación de estado.
También debes asegurarte de que puedes incorporar la imagen en el entorno de destino. Esto significa que debes tener acceso al registro de imágenes en caso de que ocurra un desastre. Una opción adecuada, que también es independiente de la plataforma, es Artifact Registry.
Transferencia de datos
La transferencia de datos es un componente crítico de las situaciones de recuperación ante desastres multiplataforma. Asegúrate de diseñar, implementar y evaluar las situaciones de recuperación ante desastres multiplataforma mediante simulaciones realistas de lo que requiere la situación de transferencia de datos de recuperación ante desastres. Analizaremos las situaciones de transferencia de datos en la sección siguiente.
Patrones de recuperación ante desastres
En esta sección, se analizan algunos de los patrones más comunes de las arquitecturas de DR, que se basan en los componentes básicos que se analizaron antes.
Transferencia de datos hacia y desde Google Cloud
Un aspecto importante del plan de DR es la rapidez con la que se pueden transferir los datos desde y hacia Google Cloud. Esto es fundamental si tu plan de DR se basa en la transferencia de datos desde las instalaciones locales hacia Google Cloud o desde otro proveedor de servicios en la nube hacia Google Cloud. En esta sección, analizamos las herramientas de redes y los servicios de Google Cloud que pueden garantizar una buena capacidad de procesamiento.
Cuando uses Google Cloud como el sitio de recuperación para cargas de trabajo que sean locales o se encuentren en otro entorno de nube, ten en cuenta los siguientes elementos clave:
- ¿Cómo te conectas a Google Cloud?
- ¿Cuánto ancho de banda hay entre el lugar donde te encuentras tú y el proveedor de interconexión?
- ¿Cuál es el ancho de banda proporcionado por el proveedor directamente a Google Cloud?
- ¿Qué otros datos se transferirán mediante ese vínculo?
Cuando utilizas una conexión a Internet pública para transferir datos, la capacidad de procesamiento de la red es impredecible porque está limitada por la capacidad y el enrutamiento del proveedor de servicios de Internet (ISP). El ISP puede ofrecer un Acuerdo de Nivel de Servicio (ANS) limitado o, simplemente, nada. Por otro lado, estas conexiones tienen costos relativamente bajos.
Cloud Interconnect proporciona varias opciones para conectarse a Google y a Google Cloud:
- Cloud VPN permite la creación de túneles VPN con IPsec entre una red de VPC de Google Cloud y una red de destino. Una puerta de enlace de VPN encripta el tráfico que se traslada entre las dos redes; luego, la otra puerta de enlace de VPN lo desencripta. La VPN con alta disponibilidad te permite crear conexiones de VPN con alta disponibilidad y con un ANS del 99.99%, además de una configuración simplificada en comparación con la creación de VPN redundantes.
- El intercambio de tráfico directo proporciona saltos de red mínimos a las direcciones IP públicas de Google. Puedes usar el intercambio de tráfico directo para intercambiar tráfico de Internet entre tu red y los puntos de presencia perimetrales (PoP) de Google.
- La interconexión dedicada proporciona una conexión física directa entre la red local y la de Google. Brinda un ANS junto con una capacidad de procesamiento más coherente para las transferencias de datos grandes. Los circuitos son de 10 Gbps o 100 Gbps y finalizan en una de las instalaciones de colocación de Google.
Si tienes un ancho de banda mayor, puedes reducir el tiempo que lleva transferir datos desde un entorno local hacia Google Cloud. En la siguiente tabla, se ilustra el aumento de velocidad que se genera cuando se pasa de 10 Gbps a 100 Gbps.
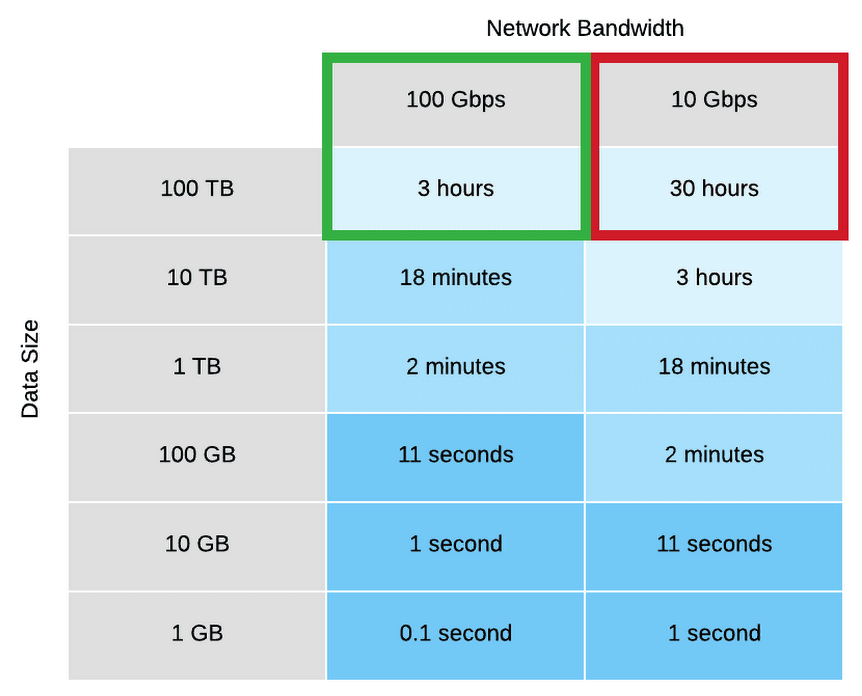
- La interconexión de socio proporciona funciones similares a las de la interconexión dedicada, pero a velocidades de circuito inferiores a 10 Gbps. Consulta Proveedores de servicios admitidos.
En el siguiente diagrama, se proporciona orientación sobre qué método de transferencia usar, según la cantidad de datos que necesites transferir a Google Cloud.

Puedes usar la calculadora de tiempo de transferencia para entender cuánto tiempo puede tomar una transferencia, en función del tamaño del conjunto de datos que transfieres y del ancho de banda disponible para la transferencia. Para obtener más información sobre la transferencia de datos como parte de la planificación de DR, consulta Transfiere conjuntos de datos grandes.
Equilibra la configuración de imágenes y la velocidad de implementación
Cuando configures una imagen de máquina para implementar instancias nuevas, considera el efecto que tendrá la configuración en la velocidad de implementación. Existe una compensación entre la cantidad de configuración previa de la imagen, los costos de mantenimiento de la imagen y la velocidad de implementación. Por ejemplo, si la imagen de una máquina está configurada mínimamente, las instancias que la utilizan requerirán más tiempo para iniciarse, ya que necesitan instalar y descargar dependencias. Por otro lado, si la imagen de tu máquina tiene una configuración alta, las instancias que la usan se inician más rápidamente, pero debes actualizar la imagen con más frecuencia. El tiempo necesario para iniciar una instancia totalmente operativa tendrá una correlación directa con el RTO.
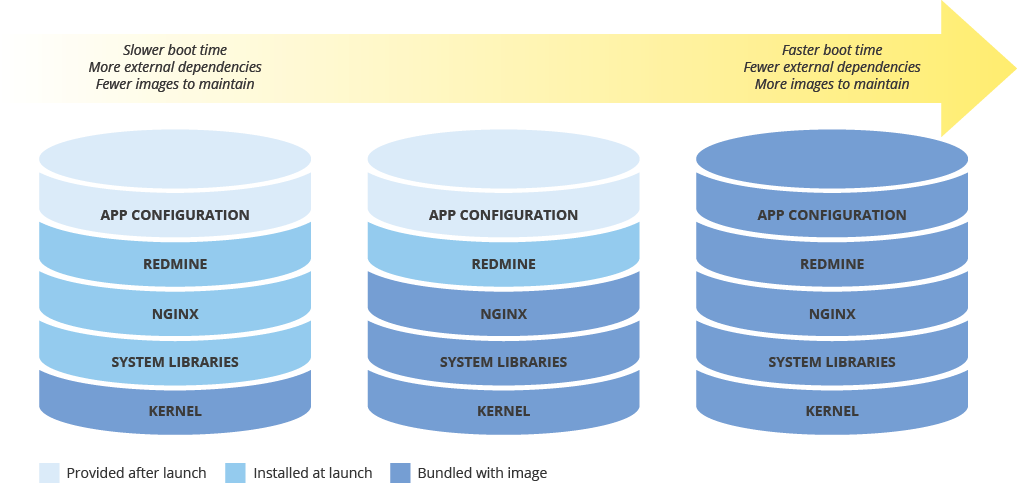
Mantén la coherencia de las imágenes de máquina en entornos híbridos
Si implementas una solución híbrida (del sitio local a la nube o de nube a nube), debes buscar una manera de mantener la coherencia de la VM en los entornos de producción.
Si se requiere una imagen totalmente configurada, considera una opción como Packer, que es capaz de crear imágenes de máquina idénticas para varias plataformas. Puedes usar las mismas secuencias de comandos con archivos de configuración específicos de la plataforma. En el caso de Packer, puedes colocar el archivo de configuración en el control de versiones para realizar un seguimiento de la versión implementada en la producción.
Como otra opción, puedes usar herramientas de administración de configuración, como Chef, Puppet, Ansible o Saltstack, para configurar instancias con mayor nivel de detalle, a fin de crear imágenes base, imágenes configuradas mínimamente o imágenes totalmente configuradas según sea necesario. Para ver un análisis de cómo usar estas herramientas de manera eficaz, consulta Implementa desde cero con Chef en Google Cloud.
También puedes convertir e importar imágenes existentes de forma manual, como las AMI de Amazon, las imágenes de Virtualbox y las imágenes de disco RAW, a Compute Engine.
Implementa el almacenamiento en niveles
El patrón de almacenamiento en niveles suele usarse para las copias de seguridad en las que la copia más reciente está en un almacenamiento más rápido, y las copias de seguridad más antiguas migran lentamente a un almacenamiento más económico, pero de menor velocidad. Existen dos formas de implementar el patrón mediante Cloud Storage, según la ubicación en la que se originen los datos: en Google Cloud o a nivel local. En ambos casos, se migran objetos entre buckets de diferentes clases de almacenamiento, en general, de la clase Standard a Nearline, que es más económica.
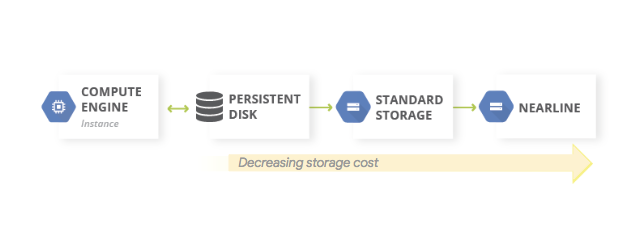
Si los datos de origen se generan a nivel local, la implementación es similar al siguiente diagrama:

De manera alternativa, puedes cambiar la clase de almacenamiento de los objetos en un depósito mediante las reglas de ciclo de vida de los objetos a fin de generar el cambio automáticamente en la clase de objeto.
Conserva la misma dirección IP para las instancias privadas
Un patrón común es mantener una sola instancia de entrega de una VM. Si se debe reemplazar la VM, el reemplazo debe aparecer como si fuera la VM original. Por lo tanto, la dirección IP que los clientes utilizan para conectarse con la nueva instancia debe permanecer igual.
La configuración más sencilla es establecer un grupo de instancias administrado que mantenga una sola instancia. Este grupo de instancias administrado está integrado en un balanceador de cargas interno (privado) que garantiza que se use la misma dirección IP para la instancia, sin importar si es la imagen original o un reemplazo.
Socios de tecnología
Google tiene un ecosistema de socios sólido que admite los casos prácticos de copia de seguridad y DR con Google Cloud. En particular, observamos que los clientes usan las soluciones de los socios para las siguientes acciones:
- Crear una copia de seguridad de los datos locales en Google Cloud. En estos casos, Cloud Storage está integrado como un destino de almacenamiento para la mayoría de las plataformas de copia de seguridad locales. Puedes usar este método para reemplazar la cinta y otros dispositivos de almacenamiento
- Implementar un plan de DR que abarque las instalaciones locales y Google Cloud. Nuestros socios pueden ayudar a eliminar los centros de datos secundarios y usar Google Cloud como el sitio de DR
- Implementar la DR y una copia de seguridad para cargas de trabajo basadas en la nube
Si deseas obtener más información sobre las soluciones de los socios, consulta la Página de socios en el sitio web de Google Cloud.
¿Qué sigue?
- Consulta Geografía y regiones de Google Cloud.
Lee otros artículos de esta serie de recuperación ante desastres:
- Guía de planificación para la recuperación ante desastres
- Situaciones de recuperación ante desastres para datos
- Situaciones de recuperación ante desastres para aplicaciones
- Arquitectura de recuperación ante desastres para cargas de trabajo con restricciones de localidad
- Casos de uso de recuperación ante desastres: aplicaciones de análisis de datos con restricciones de localidad
- Arquitectura de recuperación ante desastres para interrupciones de infraestructura de nube
Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.