En este documento, se describe cómo implementar la arquitectura en Usa una canalización de CI/CD para flujos de trabajo de procesamiento de datos.
Esta implementación está dirigida a científicos y analistas de datos que compilan trabajos de procesamiento de datos en ejecución recurrentes para ayudar a estructurar la investigación y el desarrollo (I+D) a fin de mantener las cargas de trabajo de procesamiento de datos de forma sistemática y automática.
Los científicos y los analistas de datos pueden adaptar las metodologías de las prácticas de CI/CD para garantizar la alta calidad, el mantenimiento y la adaptabilidad de los procesos de datos y los flujos de trabajo. A continuación, se incluyen los métodos que puede aplicar:
- Control de versión del código fuente
- Compilación, prueba e implementación automática de apps
- Aislamiento del entorno y separación de la producción
- Procedimientos replicables para la configuración del entorno
Arquitectura
En el siguiente diagrama, se muestra una vista detallada de los pasos de la canalización de CI/CD para la canalización de prueba y la de producción.

En el diagrama anterior, la canalización de prueba comienza cuando un desarrollador confirma cambios de código en Cloud Source Repositories y finaliza cuando se pasa la prueba de integración del flujo de trabajo de procesamiento de datos. En ese punto, la canalización publica un mensaje en Pub/Sub que contiene una referencia al último archivo de Java (JAR) de ejecución automática (obtenido de las variables de Airflow) en el campo de datos del mensaje.
En el diagrama anterior, la canalización de producción comienza cuando se publica un mensaje en un tema de Pub/Sub y finaliza cuando se implementa el archivo DAG del flujo de trabajo de producción en Cloud Composer.
En esta guía de implementación, usarás los siguientes productos de Google Cloud:
- Usará Cloud Build a fin de crear una canalización de CI/CD para compilar, implementar y probar un flujo de trabajo de procesamiento de datos y el procesamiento de datos en sí. Cloud Build es un servicio administrado que ejecuta la compilación en Google Cloud. Una compilación es una serie de pasos de compilación en la que cada paso se ejecuta en un contenedor de Docker.
- Usarás Cloud Composer para definir y ejecutar los pasos del flujo de trabajo, como el inicio del procesamiento de datos, la prueba y la verificación de los resultados. Cloud Composer es un servicio administrado de Apache Airflow que ofrece un entorno en el que puedes crear, programar, supervisar y administrar flujos de trabajo complejos, como el flujo de trabajo de procesamiento de datos de esta implementación.
- Usarás Dataflow para ejecutar el ejemplo WordCount de Apache Beam como un proceso de datos de muestra.
Objetivos
- Configura el entorno de Cloud Composer.
- Crea depósitos de Cloud Storage para los datos.
- Crea las canalizaciones de compilación, prueba y producción.
- Configura el activador de compilación.
Optimización de costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Antes de comenzar
En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
Asegúrate de que la facturación esté habilitada para tu proyecto de Google Cloud. Obtén información sobre cómo verificar si la facturación está habilitada en un proyecto.
Código de muestra
El código de muestra para esta implementación está en dos carpetas:
- La carpeta
env-setupcontiene secuencias de comandos de shell para la configuración inicial del entorno de Google Cloud. La carpeta
source-codecontiene código que se desarrolla a lo largo del tiempo, debe controlarse mediante el código fuente y activa procesos automáticos de compilación y prueba. Esta carpeta contiene las siguientes subcarpetas:- La carpeta
data-processing-codecontiene el código fuente del proceso de Apache Beam. - La carpeta
workflow-dagcontiene las definiciones de DAG del compositor destinadas a los flujos de trabajo de procesamiento de datos con los pasos para diseñar, implementar y probar el proceso de Dataflow. - La carpeta
build-pipelinecontiene dos opciones de configuración de Cloud Build: una destinada a la canalización de prueba y otra para la canalización de producción. Esta carpeta también contiene una secuencia de comandos de compatibilidad para las canalizaciones.
- La carpeta
En esta implementación, los archivos de código fuente para el procesamiento de datos y el flujo de trabajo de DAG se encuentran en diferentes carpetas en el mismo repositorio de código fuente. En un entorno de producción, los archivos de código fuente suelen estar en sus propios repositorios de código fuente y los administran equipos diferentes.
Pruebas de integración y unidades
Además de la prueba de integración que verifica el flujo de trabajo de procesamiento de datos de extremo a extremo, hay dos pruebas de unidades en esta implementación. Las pruebas de unidades son pruebas automáticas en el código de procesamiento de datos y el código del flujo de trabajo de procesamiento de datos. La prueba en el código de procesamiento de datos se escribe en Java y se ejecuta de forma automática durante el proceso de compilación de Maven. La prueba en el código del flujo de trabajo de procesamiento de datos se escribe en Python y se ejecuta como un paso de compilación independiente.
Configure su entorno
En esta implementación, ejecutarás todos los comandos en Cloud Shell. Cloud Shell aparece como una ventana en la parte inferior de la consola de Google Cloud.
En la consola de Google Cloud, abre Cloud Shell.
Clona el repositorio de código de muestra:
git clone https://github.com/GoogleCloudPlatform/ci-cd-for-data-processing-workflow.gitEjecuta una secuencia de comandos para establecer variables de entorno:
cd ~/ci-cd-for-data-processing-workflow/env-setup source set_env.shLa secuencia de comandos establece las siguientes variables de entorno:
- El ID del proyecto de Google Cloud
- La región y la zona
- El nombre de los buckets de Cloud Storage que usan la canalización de compilación y el flujo de trabajo de procesamiento de datos
Debido a que las variables de entorno no se conservan entre sesiones, si la sesión de Cloud Shell se cierra o se desconecta mientras se trabaja en esta implementación, deberás restablecer las variables de entorno.
Crea el entorno de Cloud Composer
En esta implementación, configurarás un entorno de Cloud Composer.
En Cloud Shell, agrega el rol Extensión del agente de servicio de la versión 2 de la API de Cloud Composer (
roles/composer.ServiceAgentV2Ext) a la cuenta del agente de servicio de Cloud Composer:gcloud projects add-iam-policy-binding $GCP_PROJECT_ID \ --member serviceAccount:service-$PROJECT_NUMBER@cloudcomposer-accounts.iam.gserviceaccount.com \ --role roles/composer.ServiceAgentV2ExtEn Cloud Shell, crea el entorno de Cloud Composer:
gcloud composer environments create $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --image-version composer-2.0.14-airflow-2.2.5Ejecute una secuencia de comandos para configurar las variables en el entorno de Cloud Composer. Las variables se necesitan en los DAG de procesamiento de datos.
cd ~/ci-cd-for-data-processing-workflow/env-setup chmod +x set_composer_variables.sh ./set_composer_variables.shLa secuencia de comandos establece las siguientes variables de entorno:
- El ID del proyecto de Google Cloud
- La región y la zona
- El nombre de los buckets de Cloud Storage que usan la canalización de compilación y el flujo de trabajo de procesamiento de datos
Extrae las propiedades del entorno de Cloud Composer
Cloud Composer usa un bucket de Cloud Storage para almacenar los DAG. Si mueves un archivo de definición de DAG al bucket, se activará Cloud Composer para leer los archivos de forma automática. Creaste el bucket de Cloud Storage para Cloud Composer cuando creaste el entorno de Cloud Composer. En el procedimiento siguiente, debes extraer la URL de los buckets y, luego, configurar la canalización de CI/CD para implementar definiciones de DAG en el bucket de Cloud Storage de forma automática.
En Cloud Shell, exporta la URL del bucket como una variable de entorno:
export COMPOSER_DAG_BUCKET=$(gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.dagGcsPrefix)")Exporte el nombre de la cuenta de servicio que usa Cloud Composer para tener acceso a los buckets de Cloud Storage:
export COMPOSER_SERVICE_ACCOUNT=$(gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.nodeConfig.serviceAccount)")
Crea los buckets de Cloud Storage
En esta sección, crearás un conjunto de depósitos de Cloud Storage para almacenar los siguientes elementos:
- Los artefactos de los pasos intermedios del proceso de compilación
- Los archivos de entrada y salida para el flujo de trabajo de procesamiento de datos
- La ubicación de etapa de pruebas para que los trabajos de Dataflow almacenen los archivos binarios
Para crear los depósitos de Cloud Storage, completa el siguiente paso:
En Cloud Shell, cree buckets de Cloud Storage y otorgue permiso a la cuenta de servicio de Cloud Composer para ejecutar los flujos de trabajo de procesamiento de datos:
cd ~/ci-cd-for-data-processing-workflow/env-setup chmod +x create_buckets.sh ./create_buckets.sh
Cree el tema de Pub/Sub
En esta sección, crearás un tema de Pub/Sub para recibir los mensajes enviados desde la prueba de integración del flujo de trabajo de procesamiento de datos a fin de activar automáticamente la canalización de compilación de producción.
En la consola de Google Cloud, ve a la página Temas de Pub/Sub.
Haz clic en Crear tema.
Para configurar el tema, completa los siguientes pasos:
- En ID del tema, ingresa
integration-test-complete-topic. - Confirma que la opción Agregar una suscripción predeterminada esté marcada.
- Deja desmarcadas las opciones restantes.
- En Encriptación, selecciona Clave de encriptación administrada por Google.
- Haga clic en Create Topic.
- En ID del tema, ingresa
Envía el código fuente a Cloud Source Repositories
En esta implementación, tienes una base de código fuente que debes poner en el control de versiones. En el siguiente paso, se muestra cómo se desarrolla y se cambia una base de código con el tiempo. Cada vez que se envían cambios al repositorio, se activa la canalización para compilar, implementar y probar.
En Cloud Shell, envía la carpeta
source-codea Cloud Source Repositories:gcloud source repos create $SOURCE_CODE_REPO cp -r ~/ci-cd-for-data-processing-workflow/source-code ~/$SOURCE_CODE_REPO cd ~/$SOURCE_CODE_REPO git init git remote add google \ https://source.developers.google.com/p/$GCP_PROJECT_ID/r/$SOURCE_CODE_REPO git add . git commit -m 'initial commit' git push google masterEstos son comandos estándar para inicializar Git en un directorio nuevo y enviar el contenido a un repositorio remoto.
Crea canalizaciones de Cloud Build
En esta sección, creará las canalizaciones de compilación con las que se compila, implementa y prueba el flujo de trabajo de procesamiento de datos.
Otorga acceso a la cuenta de servicio de Cloud Build
Cloud Build implementa los DAG de Cloud Composer y activa flujos de trabajo, que se habilitan cuando agregas acceso adicional a la cuenta de servicio de Cloud Build. Para obtener más información sobre las diferentes funciones disponibles cuando se trabaja con Cloud Composer, consulta la documentación de control de acceso.
En Cloud Shell, agrega la función
composer.admina la cuenta de servicio de Cloud Build para que el trabajo de Cloud Build pueda configurar variables de Airflow en Cloud Composer:gcloud projects add-iam-policy-binding $GCP_PROJECT_ID \ --member=serviceAccount:$PROJECT_NUMBER@cloudbuild.gserviceaccount.com \ --role=roles/composer.adminAgrega la función
composer.workera la cuenta de servicio de Cloud Build para que el trabajo de Cloud Build pueda activar el flujo de trabajo de datos en Cloud Composer:gcloud projects add-iam-policy-binding $GCP_PROJECT_ID \ --member=serviceAccount:$PROJECT_NUMBER@cloudbuild.gserviceaccount.com \ --role=roles/composer.worker
Crea la canalización de compilación y prueba
Los pasos de canalización de compilación y prueba se configuran en el archivo de configuración YAML.
En esta implementación, usarás imágenes de compiladores ya compiladas para git, maven, gsutil y gcloud a fin de ejecutar las tareas en cada paso de compilación.
Use las sustituciones de la variable de configuración para definir la configuración del entorno en el momento de la compilación. La ubicación del repositorio de código fuente se define mediante sustituciones de variables y las ubicaciones de los buckets de Cloud Storage. La compilación necesita esta información para implementar el archivo JAR, los archivos de prueba y la definición de DAG.
En Cloud Shell, envía el archivo de configuración de canalización de compilación para crear la canalización en Cloud Build:
cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline gcloud builds submit --config=build_deploy_test.yaml --substitutions=\ REPO_NAME=$SOURCE_CODE_REPO,\ _DATAFLOW_JAR_BUCKET=$DATAFLOW_JAR_BUCKET_TEST,\ _COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_TEST,\ _COMPOSER_REF_BUCKET=$REF_BUCKET_TEST,\ _COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\ _COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\ _COMPOSER_REGION=$COMPOSER_REGION,\ _COMPOSER_DAG_NAME_TEST=$COMPOSER_DAG_NAME_TESTEste comando le indica a Cloud Build que ejecute una compilación con los siguientes pasos:
Compilación e implementación del archivo JAR de ejecución automática de WordCount
- Consultar el código fuente
- Compilar el código fuente de WordCount Beam en un archivo JAR de ejecución automática
- Almacenar el archivo JAR en Cloud Storage, donde Cloud Composer lo puede captar para ejecutar el trabajo de procesamiento de WordCount
Implementación y configuración del flujo de trabajo de procesamiento de datos en Cloud Composer
- Ejecutar la prueba de unidades en el código de operador personalizado que usa el DAG del flujo de trabajo
- Implementar el archivo de entrada de prueba y el archivo de referencia de prueba en Cloud Storage. El archivo de entrada de prueba es la entrada para el trabajo de procesamiento de WordCount. El archivo de referencia de prueba se usa como referencia para verificar el resultado del trabajo de procesamiento de WordCount
- Configurar las variables de Cloud Composer para que apunten al archivo JAR recién compilado
- Implementar la definición de DAG del flujo de trabajo en el entorno de Cloud Composer
Para activar el flujo de trabajo de procesamiento de pruebas, ejecuta el flujo de trabajo de procesamiento de datos en el entorno de pruebas.
Verifica la compilación y la canalización de prueba
Después de enviar el archivo de compilación, verifica los pasos de compilación.
En la consola de Google Cloud, ve a la página Historial de compilaciones para ver una lista de todas las compilaciones anteriores y en ejecución.
Haz clic en la compilación que está en ejecución.
En la página Detalles de compilación (Build Steps), verifica que los pasos de compilación coincidan con los pasos descritos antes.
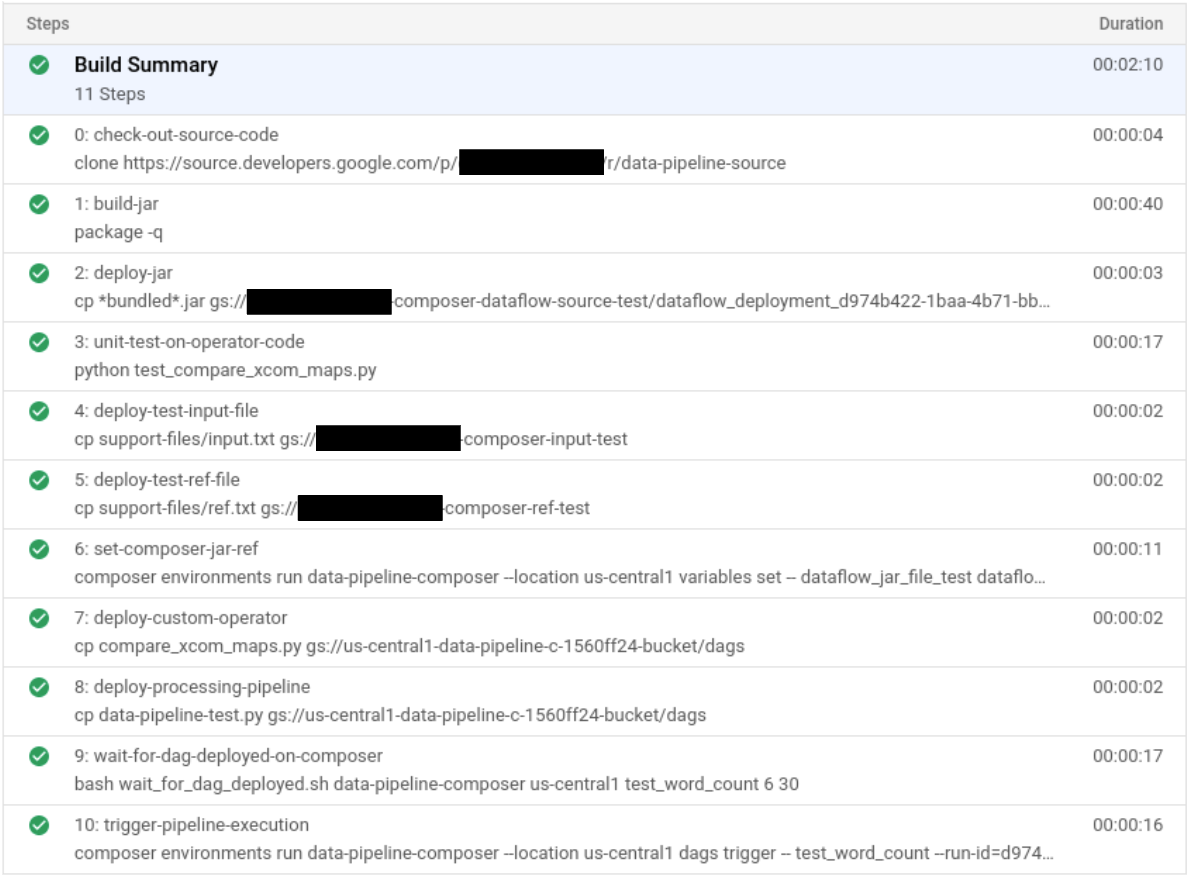
En la página Detalles de compilación, el campo Estado de la compilación indica
Build successfulcuando esta finaliza.En Cloud Shell, verifica que el archivo JAR de muestra de WordCount se haya copiado en el bucket correcto:
gsutil ls gs://$DATAFLOW_JAR_BUCKET_TEST/dataflow_deployment*.jarEl resultado es similar a este:
gs://…-composer-dataflow-source-test/dataflow_deployment_e88be61e-50a6-4aa0-beac-38d75871757e.jar
Obtén la URL de tu interfaz web de Cloud Composer. Toma nota de la URL, porque la usarás en el siguiente paso.
gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.airflowUri)"Use la URL del paso anterior para ir a la IU de Cloud Composer a fin de verificar la ejecución exitosa del DAG. Si la columna Ejecuciones no muestra información, espera unos minutos y vuelve a cargar la página.
Para verificar que el
test_word_countdel DAG del flujo de trabajo de procesamiento de datos se implemente y esté en modo de ejecución, mantén el cursor sobre el círculo verde claro en Ejecuciones y verifica que indique En ejecución.Para ver el flujo de trabajo de procesamiento de datos en ejecución como un gráfico, haz clic en el círculo verde claro y, luego, en la página Ejecuciones de DAG, haz clic en ID de DAG:
test_word_count.Vuelva a cargar la página Vista de gráfico para actualizar el estado de la ejecución de DAG actual. Por lo general, el flujo de trabajo toma entre 3 y 5 minutos en completarse. Para verificar que la ejecución de DAG finalice de manera correcta, mantenga el cursor sobre cada tarea a fin de verificar que la información sobre la herramienta indique Estado: finalizado. La segunda y última tarea, llamada
do_comparison, es la prueba de integración que verifica el resultado del proceso mediante su comparación con el archivo de referencia.
Una vez que se completa la prueba de integración, la última tarea, llamada
publish_test_complete, publica un mensaje en el temaintegration-test-complete-topicde Pub/Sub que se usará para activar la canalización de compilación de producción.Para verificar que el mensaje publicado contenga la referencia correcta al último archivo JAR, podemos extraer el mensaje de la suscripción predeterminada de Pub/Sub
integration-test-complete-topic-sub.En la consola de Google Cloud, ve a la página Suscripciones.
Haz clic en integration-test-complete-topic-sub, selecciona la pestaña Mensaje y haz clic en Extraer
El resultado debería ser similar al siguiente ejemplo:

Crea la canalización de producción
Cuando el flujo de trabajo de procesamiento de pruebas se ejecute de forma correcta, podrás cambiar la versión actual del flujo de trabajo a producción. Existen varias formas de implementar el flujo de trabajo en producción:
- De forma manual
- De forma automática cuando todas las pruebas se aprueban en los entornos de prueba o de etapa de pruebas
- De forma automática mediante un trabajo programado
En esta implementación, activarás automáticamente la compilación de producción cuando todas las pruebas se aprueben en el entorno de prueba. Para obtener más información sobre los enfoques automatizados, consulta Ingeniería de lanzamientos.
Antes de implementar el enfoque automatizado, verifica la compilación de implementación de producción mediante una implementación manual en producción. La compilación de la implementación de producción sigue estos pasos:
- Se copia el archivo JAR de WordCount del bucket de prueba en el bucket de producción.
- Se configuran las variables de Cloud Composer para que el flujo de trabajo de producción apunte al archivo JAR recién cambiado.
- Se implementa la definición de DAG del flujo de trabajo de producción en el entorno de Cloud Composer y se ejecuta el flujo de trabajo.
Con las sustituciones de variables, se define el nombre del último archivo JAR que se implementa en producción con los buckets de Cloud Storage que usa el flujo de trabajo de procesamiento de producción. Para crear la canalización de Cloud Build que implementa el flujo de trabajo de producción de Airflow, completa los siguientes pasos:
En Cloud Shell, imprime la variable de Cloud Composer para el nombre de archivo JAR a fin de poder leer el nombre del archivo JAR más reciente:
export DATAFLOW_JAR_FILE_LATEST=$(gcloud composer environments run $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION variables get -- \ dataflow_jar_file_test 2>&1 | grep -i '.jar')Usa el archivo de configuración de canalización de compilación
deploy_prod.yaml,para crear la canalización en Cloud Build:cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline gcloud builds submit --config=deploy_prod.yaml --substitutions=\ REPO_NAME=$SOURCE_CODE_REPO,\ _DATAFLOW_JAR_BUCKET_TEST=$DATAFLOW_JAR_BUCKET_TEST,\ _DATAFLOW_JAR_FILE_LATEST=$DATAFLOW_JAR_FILE_LATEST,\ _DATAFLOW_JAR_BUCKET_PROD=$DATAFLOW_JAR_BUCKET_PROD,\ _COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_PROD,\ _COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\ _COMPOSER_REGION=$COMPOSER_REGION,\ _COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\ _COMPOSER_DAG_NAME_PROD=$COMPOSER_DAG_NAME_PROD
Verifica el flujo de trabajo de procesamiento de datos que creó la canalización de producción
Obtén la URL de la IU de Cloud Composer:
gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.airflowUri)"Para verificar que el DAG del flujo de trabajo de procesamiento de datos de producción esté implementado, ve a la URL que recuperaste en el paso anterior y verifica que el DAG
prod_word_countesté en la lista de DAG.- En la página DAGs, en la fila
prod_word_count, haz clic en Activar DAG.
- En la página DAGs, en la fila
Para actualizar el estado de ejecución del DAG, haz clic en el logotipo de Airflow o vuelve a cargar la página. Un círculo verde claro en la columna Ejecuciones indica que el DAG se encuentra en ejecución.
Después de que la ejecución se realice con éxito, mantén el cursor sobre el círculo verde oscuro cerca de la columna Ejecuciones de DAG y verifica que indique Finalizado.
En Cloud Shell, enumere los archivos de resultados en el bucket de Cloud Storage:
gsutil ls gs://$RESULT_BUCKET_PRODEl resultado es similar a este:
gs://…-composer-result-prod/output-00000-of-00003 gs://…-composer-result-prod/output-00001-of-00003 gs://…-composer-result-prod/output-00002-of-00003
Crea activadores de Cloud Build
En esta sección, crearás los activadores de Cloud Build que vinculan los cambios del código fuente al proceso de compilación de prueba, y entre la canalización de prueba y la de compilación de producción.
Configura el activador de canalización de compilación de prueba
Configure un activador de Cloud Build que active una compilación nueva cuando los cambios se envíen a la rama principal del repositorio de código fuente.
En la consola de Google Cloud, ve a la página Activadores de compilación.
Haga clic en Crear activador.
Para establecer la configuración del activador, siga estos pasos:
- En el campo Nombre, ingresa
trigger-build-in-test-environment. - En el menú desplegable Región, selecciona global (no regional).
- En Evento, haz clic en Enviar a una rama.
- En Fuente, selecciona
data-pipeline-source. - En el campo Nombre de la rama, ingresa
master. - En Configuración de compilación, haz clic en Archivo de configuración de Cloud Build (YAML o JSON).
- En Ubicación, haz clic en Repositorio.
- En el campo Ubicación del archivo de configuración de Cloud Build, ingresa
build-pipeline/build_deploy_test.yaml.
- En el campo Nombre, ingresa
En Cloud Shell, ejecuta el siguiente comando a fin de obtener todas las variables de sustitución necesarias para la compilación. Tome nota de estos valores, porque los necesitará en un paso posterior.
echo "_COMPOSER_DAG_BUCKET : ${COMPOSER_DAG_BUCKET} _COMPOSER_DAG_NAME_TEST : ${COMPOSER_DAG_NAME_TEST} _COMPOSER_ENV_NAME : ${COMPOSER_ENV_NAME} _COMPOSER_INPUT_BUCKET : ${INPUT_BUCKET_TEST} _COMPOSER_REF_BUCKET : ${REF_BUCKET_TEST} _COMPOSER_REGION : ${COMPOSER_REGION} _DATAFLOW_JAR_BUCKET : ${DATAFLOW_JAR_BUCKET_TEST}"En la página Configuración del activador, en Variables de sustitución avanzadas, reemplaza las variables por los valores del entorno que obtuviste en el paso anterior. Agrega lo siguiente uno por vez y haz clic en + Agregar elemento (+ Add item) para cada par nombre-valor.
_COMPOSER_DAG_BUCKET_COMPOSER_DAG_NAME_TEST_COMPOSER_ENV_NAME_COMPOSER_INPUT_BUCKET_COMPOSER_REF_BUCKET_COMPOSER_REGION_DATAFLOW_JAR_BUCKET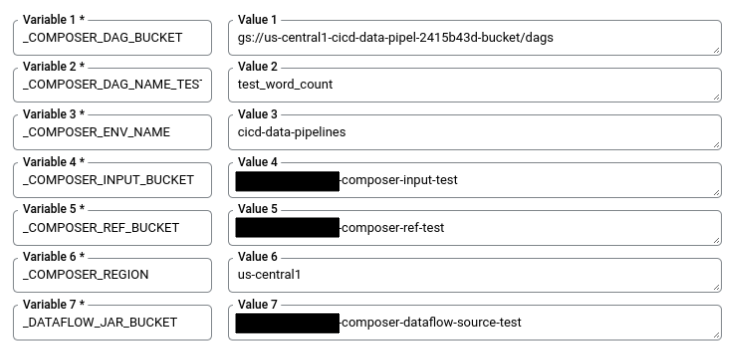
Haz clic en Crear.
Configura el activador de canalización de compilación de producción
Configura un activador de Cloud Build que active una compilación de producción cuando las pruebas se aprueben en el entorno de prueba y se publique un mensaje en el tema tests-complete de Pub/Sub. Este activador incluye un paso de aprobación en el que la compilación debe aprobarse de forma manual antes de que se ejecute la canalización de producción.
En la consola de Google Cloud, ve a la página Activadores de compilación.
Haga clic en Crear activador.
Para establecer la configuración del activador, siga estos pasos:
- En el campo Nombre, ingresa
trigger-build-in-prod-environment. - En el menú desplegable Región, selecciona global (no regional).
- En Evento, haz clic en Mensaje de Pub/Sub.
- En Suscripción, selecciona integration-test-complete-topic.
- En Fuente, selecciona
data-pipeline-source. - En Revisión, selecciona Rama.
- En el campo Nombre de la rama, ingresa
master. - En Configuración de compilación, haz clic en Archivo de configuración de Cloud Build (YAML o JSON).
- En Ubicación, haz clic en Repositorio.
- En el campo Ubicación del archivo de configuración de Cloud Build, ingresa
build-pipeline/deploy_prod.yaml.
- En el campo Nombre, ingresa
En Cloud Shell, ejecuta el siguiente comando a fin de obtener todas las variables de sustitución necesarias para la compilación. Tome nota de estos valores, porque los necesitará en un paso posterior.
echo "_COMPOSER_DAG_BUCKET : ${COMPOSER_DAG_BUCKET} _COMPOSER_DAG_NAME_PROD : ${COMPOSER_DAG_NAME_PROD} _COMPOSER_ENV_NAME : ${COMPOSER_ENV_NAME} _COMPOSER_INPUT_BUCKET : ${INPUT_BUCKET_PROD} _COMPOSER_REGION : ${COMPOSER_REGION} _DATAFLOW_JAR_BUCKET_PROD : ${DATAFLOW_JAR_BUCKET_PROD} _DATAFLOW_JAR_BUCKET_TEST : ${DATAFLOW_JAR_BUCKET_TEST}"En la página Configuración del activador, en Variables de sustitución avanzadas, reemplaza las variables por los valores del entorno que obtuviste en el paso anterior. Agrega lo siguiente uno por vez y haz clic en + Agregar elemento (+ Add item) para cada par nombre-valor.
_COMPOSER_DAG_BUCKET_COMPOSER_DAG_NAME_PROD_COMPOSER_ENV_NAME_COMPOSER_INPUT_BUCKET_COMPOSER_REGION_DATAFLOW_JAR_BUCKET_PROD_DATAFLOW_JAR_BUCKET_TEST_DATAFLOW_JAR_FILE_LATEST = $(body.message.data)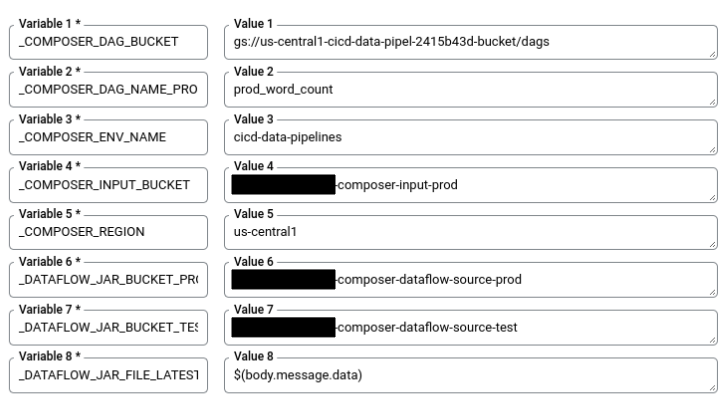
En Aprobación, selecciona Solicitar aprobación antes de que se ejecute la compilación.
Haz clic en Crear.
Prueba los activadores
Para probar el activador, agrega una palabra nueva al archivo de entrada de prueba y realiza el ajuste correspondiente en el archivo de referencia de prueba. Verifica que la canalización de compilación se active mediante un envío de confirmación a Cloud Source Repositories y que el flujo de trabajo de procesamiento de datos se ejecute de forma correcta con los archivos de prueba actualizados.
En Cloud Shell, agrega una palabra de prueba al final del archivo de prueba:
echo "testword" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/input.txtActualiza el archivo de referencia de resultados de prueba,
ref.txt, para que coincida con los cambios realizados en el archivo de entrada de prueba:echo "testword: 1" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/ref.txtConfirme y envíe cambios a Cloud Source Repositories:
cd ~/$SOURCE_CODE_REPO git add . git commit -m 'change in test files' git push google masterEn la consola de Google Cloud, ve a la página Historial.
Para verificar que una compilación de prueba nueva se active mediante el envío anterior a la rama principal, en la compilación que se está ejecutando actualmente, la columna Ref dice principal.
En Cloud Shell, obtenga la URL de la interfaz web de Cloud Composer:
gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION --format="get(config.airflowUri)"Una vez finalizada la compilación, ve a la URL del comando anterior para verificar que el DAG de
test_word_countse esté ejecutando.Espere hasta que finalice la ejecución del DAG, que se indica cuando el círculo verde claro en la columna Ejecuciones de DAG desaparece. Por lo general, el proceso demora entre 3 y 5 minutos.
En Cloud Shell, descargue los archivos de resultados de la prueba:
mkdir ~/result-download cd ~/result-download gsutil cp gs://$RESULT_BUCKET_TEST/output* .Verifica que la palabra agregada hace poco esté en uno de los archivos de resultados:
grep testword output*El resultado es similar a este:
output-00000-of-00003:testword: 1
En la consola de Google Cloud, ve a la página Historial.
Verifica que se haya activado una nueva compilación de producción cuando se complete la prueba de integración y que la compilación esté en espera de aprobación.
Para ejecutar la canalización de compilación de producción, selecciona la casilla de verificación junto a la compilación, haz clic en Aprobar y, luego, en Aprobar en el cuadro de confirmación.
Una vez finalizada la compilación, ve a la URL del comando anterior y activa el DAG
prod_word_countde forma manual para ejecutar la canalización de producción.
Limpia
En las siguientes secciones, se explica cómo puedes evitar cargos futuros para el proyecto de Google Cloud y los recursos de Apache Hive y Dataproc que usaste en esta implementación.
Borra el proyecto de Google Cloud
Puedes borrar el proyecto de Google Cloud para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en esta implementación.
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
Borra los recursos individuales
Si deseas mantener el proyecto que usaste en esta implementación, ejecuta los siguientes pasos a fin de borrar los recursos que creaste.
Para borrar el activador de Cloud Build, completa los siguientes pasos:
En la consola de Google Cloud, ve a la página Activadores.
Junto a los activadores que creaste, haz clic en Másmore_vert y, luego, en Borrar.
En Cloud Shell, borra el entorno de Cloud Composer:
gcloud -q composer environments delete $COMPOSER_ENV_NAME \ --location $COMPOSER_REGIONBorra los buckets de Cloud Storage y los archivos:
gsutil -m rm -r gs://$DATAFLOW_JAR_BUCKET_TEST \ gs://$INPUT_BUCKET_TEST \ gs://$REF_BUCKET_TEST \ gs://$RESULT_BUCKET_TEST \ gs://$DATAFLOW_STAGING_BUCKET_TEST \ gs://$DATAFLOW_JAR_BUCKET_PROD \ gs://$INPUT_BUCKET_PROD \ gs://$RESULT_BUCKET_PROD \ gs://$DATAFLOW_STAGING_BUCKET_PRODPara borrar el tema y la suscripción predeterminada de Pub/Sub, ejecuta los siguientes comandos en Cloud Shell:
gcloud pubsub topics delete integration-test-complete-topic gcloud pubsub subscriptions delete integration-test-complete-topic-subBorra el repositorio:
gcloud -q source repos delete $SOURCE_CODE_REPOBorra los archivos y la carpeta que creaste:
rm -rf ~/ci-cd-for-data-processing-workflow rm -rf ~/$SOURCE_CODE_REPO rm -rf ~/result-download¿Qué sigue?
- Obtén más información sobre la entrega continua tipo GitOps con Cloud Build.
- Aprende a usar una canalización de CI/CD para los flujos de trabajo de procesamiento de datos.
- Obtén más información sobre los Patrones comunes de casos prácticos de Dataflow.
- Obtenga más información sobre la Ingeniería de lanzamientos.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.