Dans Vector Search, vous pouvez limiter les recherches de correspondances vectorielles à un sous-ensemble de l'index à l'aide de règles booléennes. Les prédicats booléens indiquent à Vector Search quels vecteurs ignorer dans l'index. Sur cette page, vous découvrirez le fonctionnement du filtrage, vous consulterez des exemples et découvrirez comment interroger efficacement vos données en fonction de la similarité vectorielle.
Vector Search vous permet de limiter les résultats en fonction de restrictions catégorielles et numériques. L'ajout de restrictions ou le "filtrage" des résultats d'index est utile pour plusieurs raisons, telles que les exemples suivants :
Amélioration de la pertinence des résultats : la recherche vectorielle est un outil puissant pour rechercher des éléments sémantiquement similaires. Le filtrage permet de supprimer des résultats de recherche non pertinents, tels que les articles dont la langue, la catégorie, le prix ou la plage de dates ne sont pas corrects.
Nombre réduit de résultats : la recherche vectorielle peut renvoyer un grand nombre de résultats, en particulier pour les ensembles de données volumineux. Le filtrage peut être utilisé pour réduire le nombre de résultats à un nombre plus gérable, tout en renvoyant les résultats les plus pertinents.
Résultats segmentés : le filtrage peut être utilisé pour personnaliser les résultats de recherche en fonction des besoins et des préférences de l'utilisateur. Par exemple, un utilisateur peut vouloir filtrer les résultats pour n'inclure que les articles auxquels il a donné une note élevée par le passé ou qui se situent dans une gamme de prix spécifique.
Attributs vectoriels
Dans une recherche de similarité vectorielle sur une base de données de vecteurs, chaque vecteur est décrit par zéro ou plusieurs attributs. Ces attributs sont appelés jetons pour les restrictions de jetons et valeurs pour les restrictions numériques. Ces restrictions peuvent s'appliquer à chacune des catégories d'attributs, également appelées espaces de noms.
Dans l'exemple d'application suivant, les vecteurs sont tagués avec un color, un price et un shape :
color,priceetshapesont des espaces de noms.redetbluesont des jetons de l'espace de nomscolor.squareetcirclesont des jetons de l'espace de nomsshape.100et50sont des valeurs de l'espace de nomsprice.
Spécifier des attributs vectoriels
- Pour spécifier un "cercle rouge" :
{color: red}, {shape: circle}. - Pour spécifier un "carré rouge ou bleu" :
{color: red, blue}, {shape: square}. - Pour spécifier un objet sans couleur, omettez l'espace de noms "color" dans le champ
restricts. - Pour spécifier des restrictions numériques pour un objet, notez l'espace de noms et la valeur dans le champ approprié pour le type. La valeur int doit être spécifiée dans
value_int, la valeur float dansvalue_floatet la valeur double dansvalue_double. Un seul type de nombre doit être utilisé pour un espace de noms donné.
Pour en savoir plus sur le schéma utilisé pour spécifier ces données, consultez la section Spécifier des espaces de noms et des jetons dans les données d'entrée.
Requêtes
- Les requêtes expriment un opérateur logique AND sur les espaces de noms et un opérateur logique OR dans chaque espace de noms. Une requête spécifiant
{color: red, blue}, {shape: square, circle}correspond à tous les points de base de données qui répondent à(red || blue) && (square || circle). - Une requête spécifiant
{color: red}correspond à tous les objetsredde n'importe quel genre, sans restriction surshape. - Les restrictions numériques dans les requêtes nécessitent
namespace, l'une des valeurs numériques devalue_int,value_floatetvalue_double, ainsi que l'opérateurop. - L'opérateur
opest l'un des suivants :LESS,LESS_EQUAL,EQUAL,GREATER_EQUALetGREATER. Par exemple, si l'opérateurLESS_EQUALest utilisé, les points de données sont éligibles si leur valeur est inférieure ou égale à celle utilisée dans la requête.
Les exemples de code suivants identifient les attributs vectoriels dans l'exemple d'application :
[
{
"namespace": "price",
"value_int": 20,
"op": "LESS"
},
{
"namespace": "length",
"value_float": 0.3,
"op": "GREATER_EQUAL"
},
{
"namespace": "width",
"value_double": 0.5,
"op": "EQUAL"
}
]
Liste de blocage
Pour permettre des scénarios plus avancés, Google accepte une forme de négation appelée jetons de liste de blocage. Lorsqu'une requête refuse un jeton, les correspondances sont exclues pour tous les points de données associés au jeton refusé. Si un espace de noms de requête ne contient que des jetons sur liste de blocage, tous les points qui ne sont pas explicitement ajoutés à la liste de blocage correspondent, de la même manière qu'un espace de noms vide correspond à tous les points.
Les points de données peuvent également ajouter un jeton à une liste de blocage, à l'exclusion des correspondances avec toute requête spécifiant ce jeton.
Par exemple, définissez les points de données suivants avec les jetons spécifiés :
A: {} // empty set matches everything
B: {red} // only a 'red' token
C: {blue} // only a 'blue' token
D: {orange} // only an 'orange' token
E: {red, blue} // multiple tokens
F: {red, !blue} // deny the 'blue' token
G: {red, blue, !blue} // An unlikely edge-case
H: {!blue} // deny-only (similar to empty-set)
Le système se comporte comme suit :
- Les espaces de noms de requêtes vides sont des caractères génériques de correspondance. Par exemple, Q:
{}correspond à DB:{color:red}. Les espaces de noms de points de données vides ne sont pas des caractères génériques de correspondance à tous les critères. Par exemple, Q:
{color:red}ne correspond pas à DB:{}.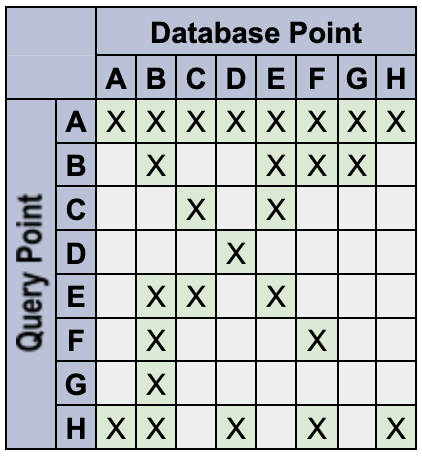
Spécifier des espaces de noms et des jetons ou des valeurs dans les données d'entrée
Pour savoir comment structurer les données d'entrée dans leur ensemble, consultez la section Format et structure des données d'entrée.
Les onglets suivants montrent comment spécifier les espaces de noms et les jetons associés à chaque vecteur d'entrée.
JSON
Pour chaque enregistrement de vecteur, ajoutez un champ appelé
restrictsafin de contenir un tableau d'objets pour lequel chaque objet est un espace de noms.- Chaque objet doit comporter un champ nommé
namespace. Ce champ correspond à l'espace de nomsTokenNamespace.namespace. - La valeur du champ
allow, s'il est présent, est un tableau de chaînes. Ce tableau de chaînes correspond à la listeTokenNamespace.string_tokens. - La valeur du champ
deny, s'il est présent, est un tableau de chaînes. Ce tableau de chaînes correspond à la listeTokenNamespace.string_denylist_tokens.
- Chaque objet doit comporter un champ nommé
Voici deux exemples d'enregistrements au format JSON :
[
{
"id": "42",
"embedding": [
0.5,
1
],
"restricts": [
{
"namespace": "class",
"allow": [
"cat",
"pet"
]
},
{
"namespace": "category",
"allow": [
"feline"
]
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"dimensions": [
1,
4
]
},
"restricts": [
{
"namespace": "class",
"allow": [
"dog",
"pet"
]
},
{
"namespace": "category",
"allow": [
"canine"
]
}
]
}
]
Pour chaque enregistrement de vecteur, ajoutez un champ appelé
numeric_restrictsafin de contenir un tableau d'objets pour lequel chaque objet est une restriction numérique.- Chaque objet doit comporter un champ nommé
namespace. Ce champ correspond à l'espace de nomsNumericRestrictNamespace.namespace. - Chaque objet doit avoir l'une des valeurs suivantes :
value_int,value_floatouvalue_double. - Chaque objet ne doit pas comporter de champ nommé
op. Ce champ est réservé aux requêtes.
- Chaque objet doit comporter un champ nommé
Voici deux exemples d'enregistrements au format JSON :
[
{
"id": "42",
"embedding": [
0.5,
1
],
"numeric_restricts": [
{
"namespace": "size",
"value_int": 3
},
{
"namespace": "ratio",
"value_float": 0.1
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"numeric_restricts": [
{
"namespace": "weight",
"value_double": 0.3
}
]
}
}
]
Avro
Les enregistrements Avro utilisent le schéma suivant :
{
"type": "record",
"name": "FeatureVector",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "embedding",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "sparse_embedding",
"type": [
"null",
{
"type": "record",
"name": "sparse_embedding",
"fields": [
{
"name": "values",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "dimensions",
"type": {
"type": "array",
"items": "long"
}
}
]
}
]
},
{
"name": "restricts",
"type": [
"null",
{
"type": "array",
"items": {
"type": "record",
"name": "Restrict",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "allow",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
},
{
"name": "deny",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
}
]
}
}
]
},
{
"name": "numeric_restricts",
"type": [
"null",
{
"type": "array",
"items": {
"name": "NumericRestrict",
"type": "record",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "value_int",
"type": [ "null", "int" ],
"default": null
},
{
"name": "value_float",
"type": [ "null", "float" ],
"default": null
},
{
"name": "value_double",
"type": [ "null", "double" ],
"default": null
}
]
}
}
],
"default": null
},
{
"name": "crowding_tag",
"type": [
"null",
"string"
]
}
]
}
CSV
Restrictions de jeton
Pour chaque enregistrement de vecteur, ajoutez des paires au format
name=valueséparées par des virgules pour spécifier les restrictions d'espace de noms de jeton. Le même nom peut être répété s'il existe plusieurs valeurs dans un espace de noms.Par exemple,
color=red,color=bluereprésente ceTokenNamespace:{ "namespace": "color" "string_tokens": ["red", "blue"] }Pour chaque enregistrement de vecteur, ajoutez des paires au format
name=!valueséparées par des virgules pour spécifier la valeur exclue pour les restrictions d'espace de noms de jeton.Par exemple,
color=!redreprésente ceTokenNamespace:{ "namespace": "color" "string_blacklist_tokens": ["red"] }
Restrictions numériques
Pour chaque enregistrement de vecteur, ajoutez des paires au format
#name=numericValueséparées par des virgules avec un suffixe de type numérique pour spécifier les restrictions d'espace de noms numérique.Le suffixe de type numérique est
ipour "int",fpour "float" etdpour "double". Le même nom ne doit pas être répété, car une seule valeur doit être associée par espace de noms.Par exemple,
#size=3ireprésente ceNumericRestrictNamespace:{ "namespace": "size" "value_int": 3 }#ratio=0.1freprésente ceNumericRestrictNamespace:{ "namespace": "ratio" "value_float": 0.1 }#weight=0.3dreprésente ceNumericRestriction:{ "namespace": "weight" "value_double": 0.3 }Voici un exemple de point de données avec
id: "6",embedding: [7, -8.1],sparse_embedding: {values: [0.1, -0.2, 0.5],dimensions: [40, 901, 1111]}}, le tag de regroupementtest, la liste d'autorisation de jetonscolor: red, blue, la liste de blocage des jetonscolor: purple, et la restriction numérique deratioavec0.1à virgule flottante :6,7,-8.1,40:0.1,901:-0.2,1111:0.5,crowding_tag=test,color=red,color=blue,color=!purple, ratio=0.1f