La ricerca vettoriale supporta la ricerca ibrida, un pattern di architettura popolare nel recupero delle informazioni (IR) che combina la ricerca semantica e la ricerca per parole chiave (chiamata anche ricerca basata su token). Con la ricerca ibrida, gli sviluppatori possono sfruttare il meglio dei due approcci, fornendo in modo efficace una qualità di ricerca superiore.
Questa pagina spiega i concetti di ricerca ibrida, ricerca semantica e ricerca basata su token e include esempi di come configurare la ricerca basata su token e la ricerca ibrida:
- Perché la ricerca ibrida è importante?
- Esempio: come utilizzare la ricerca basata su token
- Esempio: come utilizzare la ricerca ibrida
- Iniziare a utilizzare la ricerca ibrida
- Concetti aggiuntivi
Perché la ricerca ibrida è importante?
Come descritto in Panoramica di Vector Search, la ricerca semantica con Vector Search può trovare elementi con somiglianza semantica utilizzando le query.
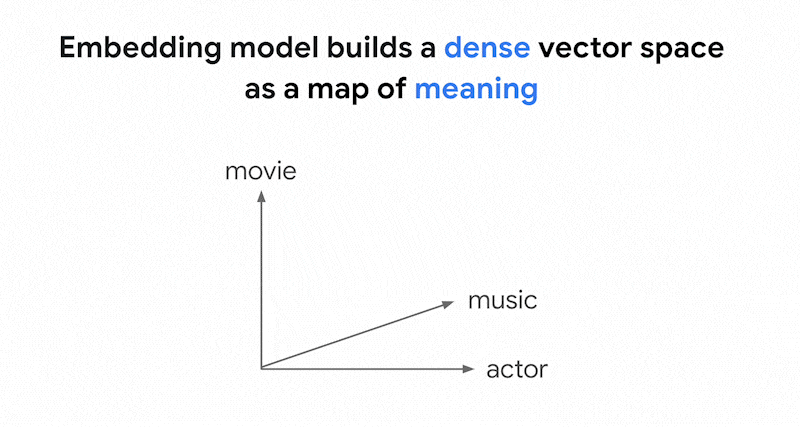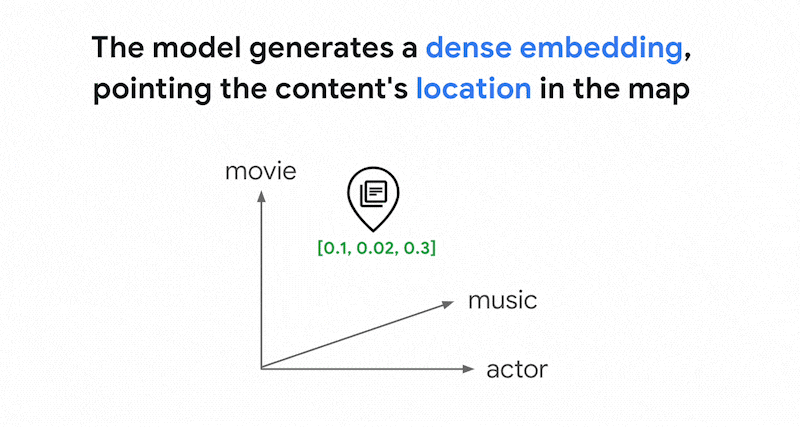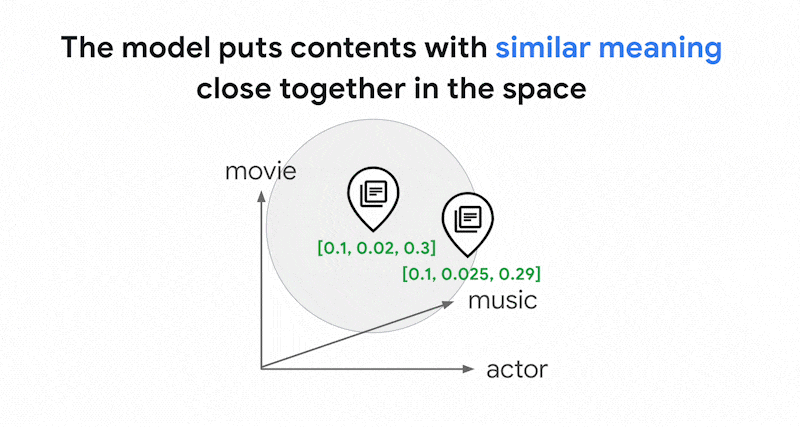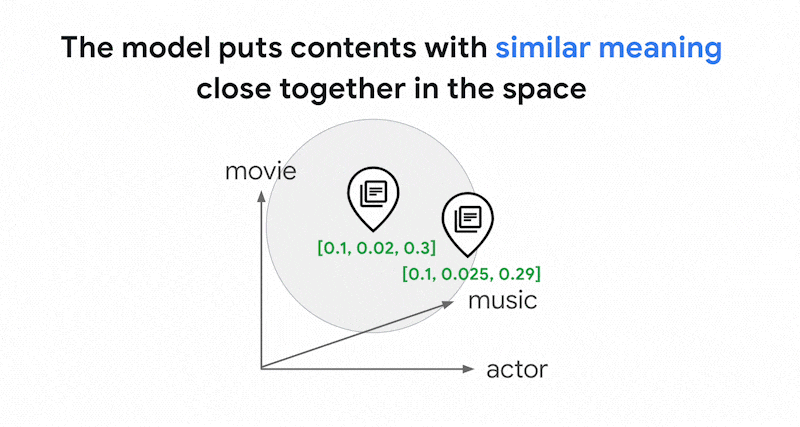
I modelli di embedding come Vertex AI
Embeddings creano uno spazio vettoriale come
mappa dei significati dei contenuti. Ogni incorporamento di testo o multimodale è una posizione nella
mappa che rappresenta il significato di alcuni contenuti. Ad esempio, quando un modello di incorporamento prende un testo che parla di film per il 10%, di musica per il 2% e di attori per il 30%, potrebbe rappresentare questo testo con un incorporamento [0.1, 0.02,
0.3]. Con la ricerca vettoriale, puoi trovare rapidamente altri embedding nelle vicinanze. Questa ricerca per significato dei contenuti è chiamata ricerca semantica.
La ricerca semantica con incorporamenti e la ricerca vettoriale possono contribuire a rendere i sistemi IT intelligenti come bibliotecari o personale di negozio esperti. Gli incorporamenti possono essere utilizzati per collegare diversi dati aziendali ai loro significati, ad esempio query e risultati di ricerca, testi e immagini, attività degli utenti e prodotti consigliati, testi in inglese e testi in giapponese oppure dati dei sensori e condizioni di avviso. Grazie a questa funzionalità, esiste un'ampia gamma di casi d'uso per gli incorporamenti.
Perché combinare la ricerca semantica con la ricerca basata su parole chiave?
La ricerca semantica non copre tutti i possibili requisiti per le applicazioni di recupero di informazioni, come la Retrieval-Augmented Generation (RAG). La ricerca semantica può trovare solo dati che il modello di incorporamento può interpretare. Ad esempio, le query o i set di dati con numeri di prodotto o SKU arbitrari, nomi di prodotti nuovi di zecca aggiunti di recente e nomi in codice proprietari aziendali non funzionano con la ricerca semantica perché non sono inclusi nel set di dati di addestramento del modello di incorporamento. Questi dati sono chiamati "fuori dominio".
In questi casi, devi combinare la ricerca semantica con la ricerca basata su parole chiave (chiamata anche ricerca basata su token) per formare una ricerca ibrida. Con la ricerca ibrida, puoi sfruttare sia la ricerca semantica che quella basata su token per ottenere una qualità superiore della ricerca.
Uno dei sistemi di ricerca ibrida più popolari è la Ricerca Google. Il servizio ha incorporato la ricerca semantica nel 2015 con il modello RankBrain, oltre al suo algoritmo di ricerca di parole chiave basato su token. Con l'introduzione della ricerca ibrida, la Ricerca Google è stata in grado di migliorare significativamente la qualità della ricerca soddisfacendo i due requisiti: ricerca per significato e ricerca per parola chiave.
In passato, creare un motore di ricerca ibrido era un compito complesso. Proprio come con la Ricerca Google, devi creare e gestire due diversi tipi di motori di ricerca (ricerca semantica e ricerca basata su token) e unire e classificare i risultati. Con il supporto della ricerca ibrida in Vector Search, puoi creare il tuo sistema di ricerca ibrida con un unico indice Vector Search, personalizzato in base ai requisiti della tua attività.
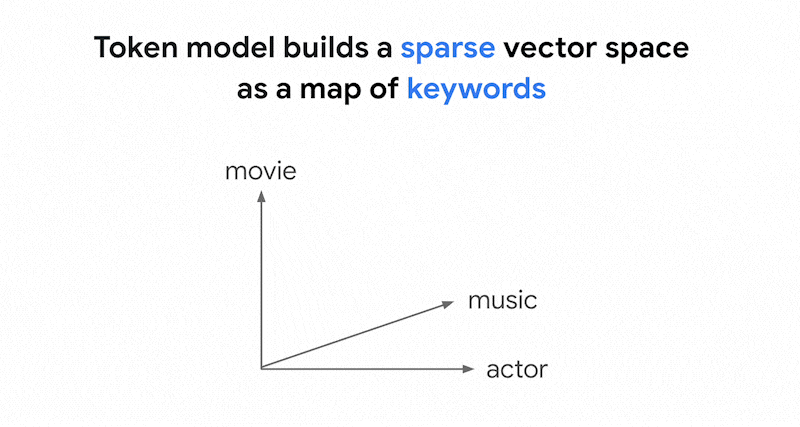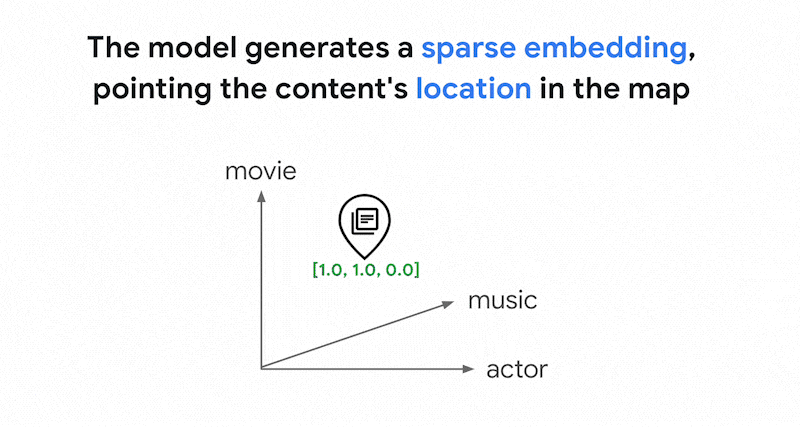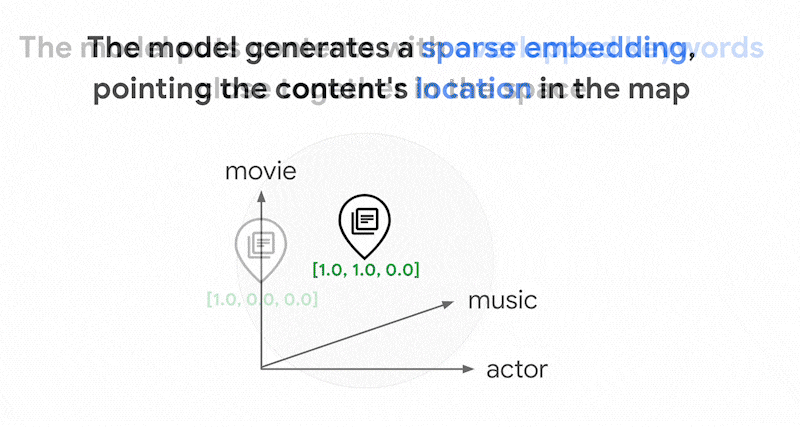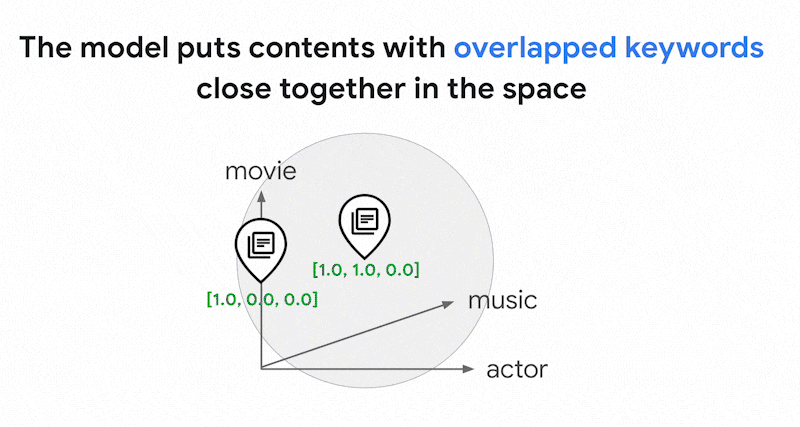
Come funziona la ricerca basata su token
Come funziona la ricerca basata su token in Vector Search? Dopo aver diviso il testo in token (come parole o sottoparole), puoi utilizzare algoritmi di incorporamento sparsi popolari come TF-IDF, BM25 o SPLADE per generare l'incorporamento sparso per il testo.
Una spiegazione semplificata degli incorporamenti sparsi è che si tratta di vettori che rappresentano il numero di volte in cui ogni parola o sub-parola compare nel testo. Gli incorporamenti sparsi tipici non tengono conto della semantica del testo.

Nei testi potrebbero essere utilizzate migliaia di parole diverse. Pertanto, questo embedding di solito ha decine di migliaia di dimensioni, con solo alcune dimensioni che hanno valori diversi da zero. Per questo motivo vengono chiamati incorporamenti "sparati". La maggior parte dei valori è pari a zero. Questo spazio di incorporamento sparso funziona come una mappa di parole chiave, simile a un indice di libri.
In questo spazio di incorporamento sparso, puoi trovare incorporamenti simili esaminando il vicinato di un incorporamento di query. Questi incorporamenti sono simili in termini di distribuzione delle parole chiave utilizzate nei testi.
Questo è il meccanismo di base della ricerca basata su token con embedding sparsi. Con la ricerca ibrida in Vector Search, puoi combinare embedding densi e sparsi in un unico indice vettoriale ed eseguire query con embedding densi, sparsi o entrambi. Il risultato è una combinazione di ricerca semantica e risultati di ricerca basati su token.
La ricerca ibrida offre anche una latenza delle query inferiore rispetto a un motore di ricerca basato su token con una progettazione di indice invertito. Proprio come la ricerca vettoriale per la ricerca semantica, ogni query con incorporamenti densi o sparsi termina in pochi millisecondi, anche con milioni o miliardi di elementi.
Esempio: come utilizzare la ricerca basata su token
Per spiegare come utilizzare la ricerca basata su token, le sezioni seguenti includono esempi di codice che generano embedding sparsi e creano un indice con questi su Vector Search.
Per provare questo codice campione, utilizza il blocco note: Combining Semantic & Keyword Search: A Hybrid Search Tutorial with Vertex AI Vector Search.
Il primo passaggio consiste nel preparare un file di dati per creare un indice per gli incorporamenti sparsi, in base al formato dei dati descritto in Formato e struttura dei dati di input.
In JSON, il file di dati ha il seguente aspetto:
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
Ogni elemento deve avere una proprietà sparse_embedding con proprietà values e
dimensions. Gli embedding sparsi hanno migliaia di dimensioni con
pochi valori diversi da zero. Questo formato dei dati funziona in modo efficiente perché contiene
solo i valori diversi da zero con le relative posizioni nello spazio.
Prepara un set di dati di esempio
Come set di dati di esempio, utilizzeremo il set di dati Google Merch Shop, che contiene circa 200 righe di prodotti con brand Google.
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
Prepara un vectorizer TF-IDF
Con questo set di dati, addestreremo un vectorizer, un modello che genera embedding sparsi da un testo. Questo esempio utilizza TfidfVectorizer in scikit-learn, un vectorizer di base che utilizza l'algoritmo TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
La variabile corpus contiene un elenco di 200 nomi di articoli, ad esempio "Adesivo
Google" o "Spilla del dinosauro di Chrome". Poi, il codice li passa al vectorizer chiamando la funzione fit_transform(). A questo punto, il vectorizer si prepara a
generare embedding sparsi.
Il vectorizer TF-IDF cerca di dare un peso maggiore alle parole caratteristiche nel set di dati (come "Camicie" o "Dino") rispetto alle parole banali (come "Il", "un" o "di") e conta quante volte queste parole caratteristiche vengono utilizzate nel documento specificato. Ogni valore di un embedding sparso rappresenta la frequenza di ogni parola in base ai conteggi. Per ulteriori informazioni su TF-IDF, consulta Come funzionano TF-IDF e TfidfVectorizer?
In questo esempio, per semplicità, utilizziamo la tokenizzazione di base a livello di parola e la vettorizzazione TF-IDF. Nello sviluppo della produzione, puoi scegliere qualsiasi altra opzione per tokenizzazioni e vettorizzazioni per generare incorporamenti sparse in base ai tuoi requisiti. Per i tokenizer, in molti casi i tokenizer di subword hanno un buon rendimento rispetto alla tokenizzazione a livello di parola e sono scelte popolari. Per i vettorizzatori, BM25 è popolare in quanto versione migliorata di TF-IDF. SPLADE è un altro algoritmo di vettorizzazione diffuso che prende in considerazione alcune semantiche per l'incorporamento sparso.
Recuperare un embedding sparso
Per semplificare l'utilizzo del vectorizer con Vector Search, definiremo
una funzione wrapper, get_sparse_embedding():
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
Questa funzione passa il parametro "text" al vectorizer per generare un embedding
sparso. Poi convertilo nel formato {"values": ...., "dimensions": ...}
menzionato in precedenza per creare un indice sparso Vector Search.
Puoi testare questa funzione:
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
Dovrebbe essere restituito il seguente embedding sparso:
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
Crea un file di dati di input
Per questo esempio, genereremo incorporamenti sparsi per tutti i 200 elementi.
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
Questo codice genera la seguente riga per ogni elemento:
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
Salvali come file JSONL "items.json" e caricali in un bucket Cloud Storage.
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gcloud storage cp items.json $BUCKET_URI
Crea un indice di incorporamento sparso in Vector Search
Successivamente, creeremo e implementeremo un indice di incorporamento sparso in Vector Search. Si tratta della stessa procedura documentata nella guida rapida di Vector Search.
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
Per utilizzare l'indice, devi creare un endpoint indice. Funziona come un'istanza server che accetta richieste di query per il tuo indice.
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
Con l'endpoint indice, esegui il deployment dell'indice specificando un ID indice di cui è stato eseguito il deployment univoco.
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
Dopo aver atteso il deployment, siamo pronti a eseguire una query di test.
Eseguire una query con un indice di incorporamento sparso
Per eseguire una query con un indice di incorporamento sparso, devi creare un oggetto HybridQuery per incapsulare l'incorporamento sparso del testo della query, come nell'esempio seguente:
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
Questo codice di esempio utilizza il testo "Bambini" per la query. Ora esegui una query con l'oggetto
HybridQuery.
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
Dovresti ottenere un output simile al seguente:
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
Dei 200 elementi, il risultato contiene i nomi degli elementi che includono la parola chiave "Bambini".
Esempio: come utilizzare la ricerca ibrida
Questo esempio combina la ricerca basata su token con la ricerca semantica per creare una ricerca ibrida in Vector Search.
Come creare un indice ibrido
Per creare un indice ibrido, ogni elemento deve avere sia "embedding" (per l'embedding denso) sia "sparse_embedding":
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
La funzione get_dense_embedding() utilizza l'API Vertex AI Embedding per generare l'embedding di testo con 768 dimensioni. Vengono generati incorporamenti densi e sparsi nel
seguente formato:
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
Il resto della procedura è uguale a quella descritta in Esempio: come utilizzare la ricerca basata su token: carica il file JSONL nel bucket Cloud Storage, crea un indice di ricerca vettoriale con il file e implementa l'indice nell'endpoint dell'indice.
Eseguire una query ibrida
Dopo aver eseguito il deployment dell'indice ibrido, puoi eseguire una query ibrida:
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
Per il testo della query "Bambini", genera incorporamenti densi e sparsi per la
parola e incapsulali nell'oggetto HybridQuery. La differenza rispetto al
precedente HybridQuery è costituita da due parametri aggiuntivi: dense_embedding e
rrf_ranking_alpha.
Questa volta, stampiamo le distanze per ogni elemento:
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
In ogni oggetto neighbor, esiste una proprietà distance che indica la distanza
tra la query e l'elemento con l'incorporamento denso e una proprietà sparse_distance
che indica la distanza con l'incorporamento sparso. Questi valori sono
distanze invertite, quindi un valore più alto indica una distanza più breve.
Se esegui una query con HybridQuery, ottieni il seguente risultato:
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
Oltre ai risultati di ricerca basati su token che contengono la parola chiave "Bambini", sono inclusi anche i risultati di ricerca semantica. Ad esempio, "Google White Classic Youth Tee" è incluso perché il modello di incorporamento sa che "Youth" e "Kids" sono semanticamente simili.
Per unire i risultati della ricerca semantica e basata su token, la ricerca ibrida utilizza
Reciprocal Rank Fusion
(RRF). Per saperne di più su RRF e su come specificare il parametro rrf_ranking_alpha, consulta Che cos'è la fusione del ranking reciproco?
Re-ranking
RRF fornisce un modo per unire la classificazione dei risultati di ricerca semantica e basata su token. In molti sistemi di recupero delle informazioni o di suggerimenti di produzione, i risultati verranno sottoposti a ulteriori algoritmi di classificazione di precisione, il cosiddetto reranking. Grazie alla combinazione del recupero rapido a livello di millisecondo con la ricerca vettoriale e al ranking di precisione dei risultati, puoi creare sistemi multistadio che offrono una qualità di ricerca o un rendimento dei consigli superiori.
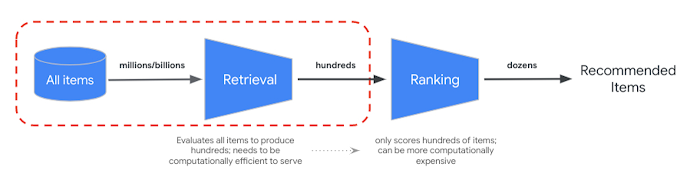
L'API Vertex AI Ranking fornisce un modo per implementare il ranking in base alla pertinenza generica tra il testo della query e i testi dei risultati di ricerca con il modello preaddestrato. TensorFlow Ranking fornisce anche un'introduzione su come progettare e addestrare modelli di learning to rank (LTR) per il riordinamento avanzato che può essere personalizzato per vari requisiti aziendali.
Inizia a utilizzare la ricerca ibrida
Le seguenti risorse possono aiutarti a iniziare a utilizzare la ricerca ibrida in Ricerca vettoriale.
Risorse per la ricerca ibrida
- Combining Semantic & Keyword Search: A Hybrid Search Tutorial with Vertex AI Vector Search: notebook di esempio per iniziare con la ricerca ibrida
- Formato e struttura dei dati di input: formato dei dati di input per la creazione dell'indice di incorporamento sparso
- Esegui query sull'indice pubblico per ottenere i vicini più vicini: come eseguire query con la ricerca ibrida
- Reciprocal Rank Fusion supera Condorcet e i metodi di apprendimento della classificazione individuale: discussione dell'algoritmo RRF
Risorse per la ricerca vettoriale
Concetti aggiuntivi
Le sezioni seguenti descrivono in dettaglio TF-IDF e TfidVectorizer, Reciprocal Rank Fusion e il parametro alpha.
Come funzionano TF-IDF e TfidfVectorizer?
La funzione fit_transform() esegue due importanti processi dell'algoritmo TF-IDF:
Adatta: il vectorizer calcola la frequenza inversa del documento (IDF) per ogni termine del vocabolario. L'IDF riflette l'importanza di un termine nell'intero corpus. I termini rari ottengono punteggi IDF più elevati:
IDF(t) = log_e(Total number of documents / Number of documents containing term t)Trasforma:
- Tokenizzazione: suddivide i documenti in singoli termini (parole o frasi)
Calcolo della frequenza del termine (TF): conta la frequenza con cui ogni termine viene visualizzato in ogni documento con:
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)Calcolo TF-IDF: combina la TF per ogni termine con l'IDF precalcolato per creare un punteggio TF-IDF. Questo punteggio rappresenta l'importanza di un termine in un documento specifico rispetto all'intero corpus.
TF-IDF(t, d) = TF(t, d) * IDF(t)Il vectorizer TF-IDF tenta di assegnare un peso maggiore alle parole distintive nel set di dati, ad esempio "Camicie" o "Dino", rispetto alle parole banali, ad esempio "Il", "un" o "di", e conta quante volte queste parole distintive vengono utilizzate nel documento specificato. Ogni valore di un incorporamento sparso rappresenta la frequenza di ogni parola in base ai conteggi.
Che cos'è Reciprocal Rank Fusion?
Per unire i risultati della ricerca semantica e basata su token, la ricerca ibrida utilizza Reciprocal Rank Fusion (RRF). RRF è un algoritmo per combinare più elenchi classificati di elementi in un'unica classificazione unificata. È una tecnica molto diffusa per unire i risultati di ricerca provenienti da fonti o metodi di recupero diversi, soprattutto nei sistemi di ricerca ibridi e nei modelli linguistici di grandi dimensioni.
Nel caso della ricerca ibrida di Vector Search, la distanza densa e la distanza sparsa vengono misurate in spazi diversi e non possono essere confrontate direttamente tra loro. Pertanto, RRF funziona in modo efficace per unire e classificare i risultati dei due spazi diversi.
Ecco come funziona il RRF:
- Rango reciproco: per ogni elemento di un elenco classificato, calcola il rango reciproco. Ciò significa prendere l'inverso della posizione (classifica) dell'elemento nell'elenco. Ad esempio, l'elemento classificato al primo posto ottiene un rango reciproco di 1/1 = 1, mentre l'elemento classificato al secondo posto ottiene 1/2 = 0,5.
- Somma dei ranghi reciproci: somma i ranghi reciproci di ogni elemento in tutti gli elenchi classificati. In questo modo viene assegnato un punteggio finale a ogni elemento.
- Ordina per punteggio finale: ordina gli elementi in base al punteggio finale in ordine decrescente. Gli elementi con i punteggi più alti sono considerati i più pertinenti o importanti.
In breve, gli elementi con ranking più elevato nei risultati densi e sparsi verranno spostati in cima all'elenco. Pertanto, l'articolo "Occhiali da sole blu per bambini Google" si trova in cima perché ha un ranking più alto sia nei risultati di ricerca densi che in quelli sparsi. Elementi come "T-shirt classica bianca Google per ragazzi" hanno un ranking basso perché hanno solo ranking nel risultato di ricerca denso.
Comportamento del parametro alfa
L'esempio di come utilizzare la ricerca ibrida imposta il parametro rrf_ranking_alpha
su 0,5 durante la creazione dell'oggetto HybridQuery. Puoi specificare una ponderazione per
classificare i risultati di ricerca densa e sparsa utilizzando i seguenti valori per
rrf_ranking_alpha:
1o non specificato:la ricerca ibrida utilizza solo risultati di ricerca densi e ignora quelli sparsi.0: la ricerca ibrida utilizza solo risultati di ricerca sparsi e ignora i risultati di ricerca densi.0a1:la ricerca ibrida unisce i risultati densi e sparsi con il peso specificato dal valore. 0,5 significa che verranno unite con lo stesso peso.