Che cos'è la Retrieval-Augmented Generation (RAG)?
La RAG, acronimo di Retrieval-Augmented Generation, è un framework di AI che combina i punti di forza dei tradizionali sistemi di recupero di informazioni (come i database e la ricerca) con le capacità dei modelli linguistici di grandi dimensioni (LLM) generativi. Grazie alla combinazione dei tuoi dati e delle tue conoscenze del mondo con le competenze linguistiche degli LLM, la generazione eseguita con grounding è più accurata, aggiornata e pertinente alle tue esigenze specifiche. Dai un'occhiata a questo ebook per scoprire la tua verità aziendale.
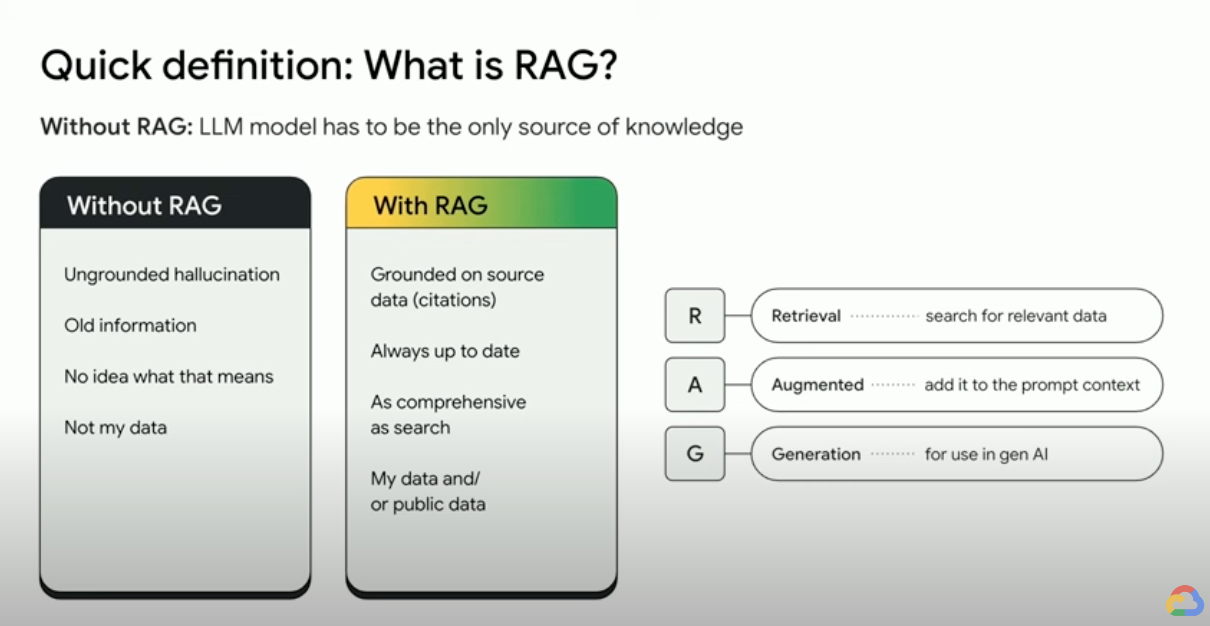
Come funziona la Retrieval Augmented Generation (RAG)?
Le RAG operano con alcuni passaggi principali per contribuire a migliorare gli output dell'AI generativa.
- Recupero e pre-elaborazione: le RAG sfruttano potenti algoritmi di ricerca per eseguire query su dati esterni, come pagine web, knowledge base e database. Una volta recuperate, le informazioni pertinenti vengono sottoposte a pre-elaborazione, tra cui tokenizzazione, stemming e rimozione delle parole di interruzione.
- Generazione con grounding: le informazioni recuperate pre-elaborate vengono quindi incorporate perfettamente nell'LLM preaddestrato. Questa integrazione migliora il contesto dell'LLM, fornendo una comprensione più completa dell'argomento. Questo contesto aumentato consente all'LLM di generare risposte più precise, informative e coinvolgenti.
Perché utilizzare la RAG?
La RAG offre diversi vantaggi rispetto ai metodi tradizionali di generazione del testo, soprattutto quando si tratta di informazioni oggettive o risposte basate sui dati. Ecco alcuni motivi principali per cui l'utilizzo della RAG può essere utile:
Accesso a informazioni aggiornate
Gli LLM sono limitati ai dati per cui sono stati preaddestrati. Questo porta a risposte obsolete e potenzialmente inaccurate. La RAG risolve questo problema fornendo informazioni aggiornate agli LLM.
Fondatezza fattuale
Gli LLM sono strumenti potenti per generare testo creativo e coinvolgente, ma a volte possono avere difficoltà con l'accuratezza oggettiva. Questo perché gli LLM vengono addestrati su enormi quantità di dati di testo, che potrebbero contenere inesattezze o bias.
Fornire "fatti" all'LLM come parte del prompt di input può mitigare le allucinazioni dell'AI generativa. Il punto cruciale di questo approccio è garantire che i fatti più rilevanti vengano forniti all'LLM e che l'output dell'LLM sia interamente basato su questi fatti, rispondendo al contempo alla domanda dell'utente e rispettando le istruzioni del sistema e i vincoli di sicurezza.
Utilizzare la finestra di contesto estesa (LCW, long context window) di Gemini è un ottimo modo per fornire materiali di origine al modello LLM. Se devi fornire più informazioni di quelle che rientrano nella LCW o se devi fare lo scale up delle prestazioni, puoi utilizzare un approccio RAG che ridurrà il numero di token, facendoti risparmiare tempo e denaro.
Ricerca con database vettoriali e ricalcolatori (re-ranker) di pertinenza
Le RAG di solito recuperano i fatti tramite la ricerca e i motori di ricerca moderni ora sfruttano i database vettoriali per recuperare in modo efficiente i documenti pertinenti. I database vettoriali archiviano i documenti come embedding in uno spazio con molte dimensioni, consentendo un recupero veloce e accurato in base alla somiglianza semantica. Gli embedding multimodali possono essere utilizzati per immagini, audio, video e altro ancora. Inoltre questi embedding multimediali possono essere recuperati insieme ai text embedding o agli embedding multilingue.
Motori di ricerca avanzati come Agent Search sulla piattaforma agentica Gemini Enterprise utilizzano insieme la ricerca semantica e la ricerca per parole chiave (detta ricerca ibrida) e un ricalcolatore che assegna un punteggio ai risultati di ricerca per garantire che i risultati restituiti principali siano i più pertinenti. Inoltre, le ricerche funzionano meglio con una query chiara e mirata senza errori di ortografia; pertanto, prima della ricerca, i motori di ricerca sofisticati trasformeranno una query e correggeranno gli errori di ortografia.
Pertinenza, accuratezza e qualità
Il meccanismo di recupero nella RAG è di fondamentale importanza. È necessaria la migliore ricerca semantica su una knowledge base selezionata per garantire che le informazioni recuperate siano pertinenti alla query di input o al contesto. Se le informazioni recuperate sono irrilevanti, la generazione potrebbe essere basata su fatti fondati ma fuori tema o errata.
Mediante l'ottimizzazione o l'ingegneria del prompt dell'LLM per generare testo interamente basato sulle conoscenze recuperate, la RAG aiuta a ridurre al minimo le contraddizioni e le incoerenze nel testo generato. Questo migliora significativamente la qualità del testo generato e l'esperienza utente.
La valutazione del modello nella piattaforma agentica Gemini Enterprise ora valuta il testo generato dall'LLM e i frammenti recuperati in base a metriche come "coerenza", "fluidità", "fondatezza", "sicurezza", "rispetto delle istruzioni", "qualità della risposta alle domande" e altro ancora. Queste metriche ti aiutano a misurare il testo basato su grounding che ottieni dall'LLM (per alcune metriche si tratta di un confronto con una risposta basata su dati di fatto che hai fornito). L'implementazione di queste valutazioni ti fornisce una misurazione di base e puoi ottimizzare la qualità RAG configurando il motore di ricerca, curando i dati di origine, migliorando le strategie di analisi o suddivisione del layout di origine o perfezionando la domanda dell'utente prima della ricerca. Un approccio RAG Ops basato sulle metriche come questo ti aiuterà a ottenere un RAG di alta qualità e una generazione con grounding solida.
RAG, agenti e chatbot
RAG e grounding possono essere integrati in qualsiasi applicazione o agente LLM che necessiti di accedere a dati aggiornati, privati o specializzati. Accedendo a informazioni esterne, i chatbot e gli agente conversazionali basati su RAG sfruttano la conoscenza esterna per fornire risposte più complete, informative e sensibili al contesto, migliorando l'esperienza utente complessiva.
I tuoi dati e il tuo caso d'uso sono ciò che differenzia ciò che stai creando con l'AI generativa. RAG e grounding portano i tuoi dati agli LLM in modo efficiente e scalabile.
Quali prodotti e servizi Google Cloud sono correlati alla RAG?
I seguenti prodotti Google Cloud sono correlati alla Retrieval Augmented Generation (RAG):
 Motore RAG di Gemini Enterprise Agent PlatformFramework di dati per sviluppare applicazioni LLM con aggiunta del contesto e facilitazione della Retrieval-Augmented Generation
Motore RAG di Gemini Enterprise Agent PlatformFramework di dati per sviluppare applicazioni LLM con aggiunta del contesto e facilitazione della Retrieval-Augmented Generation- Ricerca agenti sulla piattaforma agentica Gemini EnterpriseAgent Search è la Ricerca Google per i tuoi dati, un generatore di ricerca e RAG completamente gestito e pronto all'uso.
 Ricerca vettoriale su Gemini Enterprise Agent PlatformL'indice vettoriale ad alte prestazioni che alimenta Agent Search; consente la ricerca e il recupero semantici e ibridi da enormi raccolte di embedding con un richiamo elevato e una frequenza di query elevata.
Ricerca vettoriale su Gemini Enterprise Agent PlatformL'indice vettoriale ad alte prestazioni che alimenta Agent Search; consente la ricerca e il recupero semantici e ibridi da enormi raccolte di embedding con un richiamo elevato e una frequenza di query elevata. BigQuerySet di dati di grandi dimensioni che puoi utilizzare per addestrare modelli di machine learning, inclusi i modelli Vector Search su Agent Platform.
BigQuerySet di dati di grandi dimensioni che puoi utilizzare per addestrare modelli di machine learning, inclusi i modelli Vector Search su Agent Platform.- API Grounded GenerationLa modalità ad alta fedeltà di Gemini si basa sulla Ricerca Google o sui fatti incorporati oppure puoi utilizzare il tuo motore di ricerca preferito.
 AlloyDB AIEsegui i modelli in Agent Platform e accedi a questi modelli nella tua applicazione utilizzando query SQL note. Utilizza i modelli Google, come Gemini, o i tuoi modelli personalizzati.
AlloyDB AIEsegui i modelli in Agent Platform e accedi a questi modelli nella tua applicazione utilizzando query SQL note. Utilizza i modelli Google, come Gemini, o i tuoi modelli personalizzati.
Per approfondire
Scopri di più sull'utilizzo della Retrieval Augmented Generation (RAG) con queste risorse.
- RAG basati sulla tecnologia della Ricerca Google
- RAG con database su Google Cloud
- API per creare i tuoi sistemi di ricerca e Retrieval-Augmented Generation (RAG)
- Come usare RAG in BigQuery per rafforzare gli LLM
- Esempio di codice e guida rapida per acquisire familiarità con RAG
- Infrastruttura per un'applicazione di AI generativa compatibile con RAG utilizzando GKE
Fai un passo avanti
Inizia a creare su Google Cloud con 300 $ di crediti senza costi e oltre 20 prodotti sempre senza costi.
Hai bisogno di aiuto per iniziare?
Contatta il team di venditaCollabora con un partner di fiducia
Trova un partnerContinua la navigazione
Visualizza tutti i prodotti


















