Vertex AI では、大規模なモデル トレーニングの運用を可能にするマネージド トレーニング サービスを利用できます。Vertex AI を使用すると、Google Cloud インフラストラクチャで、あらゆる ML フレームワークに基づくトレーニング アプリケーションを実行できます。Vertex AI には、次の一般的な ML フレームワークについて、モデルのトレーニングと提供の準備プロセスを簡素化するサポートも統合されています。
このページでは、Vertex AI でのカスタム トレーニングのメリット、関連するワークフロー、利用可能なさまざまなトレーニング オプションについて説明します。
Vertex AI による大規模なトレーニングの運用
モデルのトレーニングの運用にはさまざまな課題があります。課題としては、モデルのトレーニングに必要な時間と費用、コンピューティング インフラストラクチャの管理に必要なスキルの深さ、エンタープライズ レベルのセキュリティを提供する必要性などがあります。Vertex AI は、こうした課題に対処すると同時に、他にも多くのメリットをもたらします
フルマネージドのコンピューティング インフラストラクチャ
|
|
Vertex AI でのモデル トレーニングは、物理インフラストラクチャの管理を必要としないフルマネージド サービスです。サーバーのプロビジョニングや管理を行うことなく ML モデルをトレーニングできます。お支払は、使用したコンピューティング リソース分だけです。Vertex AI では、ジョブのロギング、キューイング、モニタリングも行われます。 |
高パフォーマンス
|
|
Vertex AI トレーニング ジョブは ML モデルのトレーニング用に最適化されており、トレーニング アプリケーションを GKE クラスタで直接実行するよりも高速なパフォーマンスを実現できます。また、Cloud Profiler を使用して、トレーニング ジョブのパフォーマンスのボトルネックを特定し、デバッグすることもできます。 |
分散トレーニング
|
|
Rudction Server は、Vertex AI の all-reduce アルゴリズムであり、NVIDIA 画像処理装置(GPU)上でのマルチノード分散トレーニングのスループットを向上させ、レイテンシを削減できます。この最適化により、大規模なトレーニング ジョブを遂行する時間と費用を削減できます。 |
ハイパーパラメータの最適化
|
|
ハイパーパラメータ チューニング ジョブでは、さまざまなハイパーパラメータ値を使用して、トレーニング アプリケーションのトライアルを何度も実行します。テストする値の範囲を指定すると、Vertex AI はその範囲内でモデルに最適な値を検出します。 |
エンタープライズ セキュリティ
|
|
Vertex AI は、次のエンタープライズ セキュリティ機能を備えています。
|
ML オペレーション(MLOps)のインテグレーション
|
|
Vertex AI には、次の目的に使用できる統合された MLOps ツールと機能が用意されています。
|
カスタム トレーニングのワークフロー
次の図では、Vertex AI でのカスタム トレーニング ワークフローの概要を示します。以降のセクションでは、各ステップを詳しく説明します。
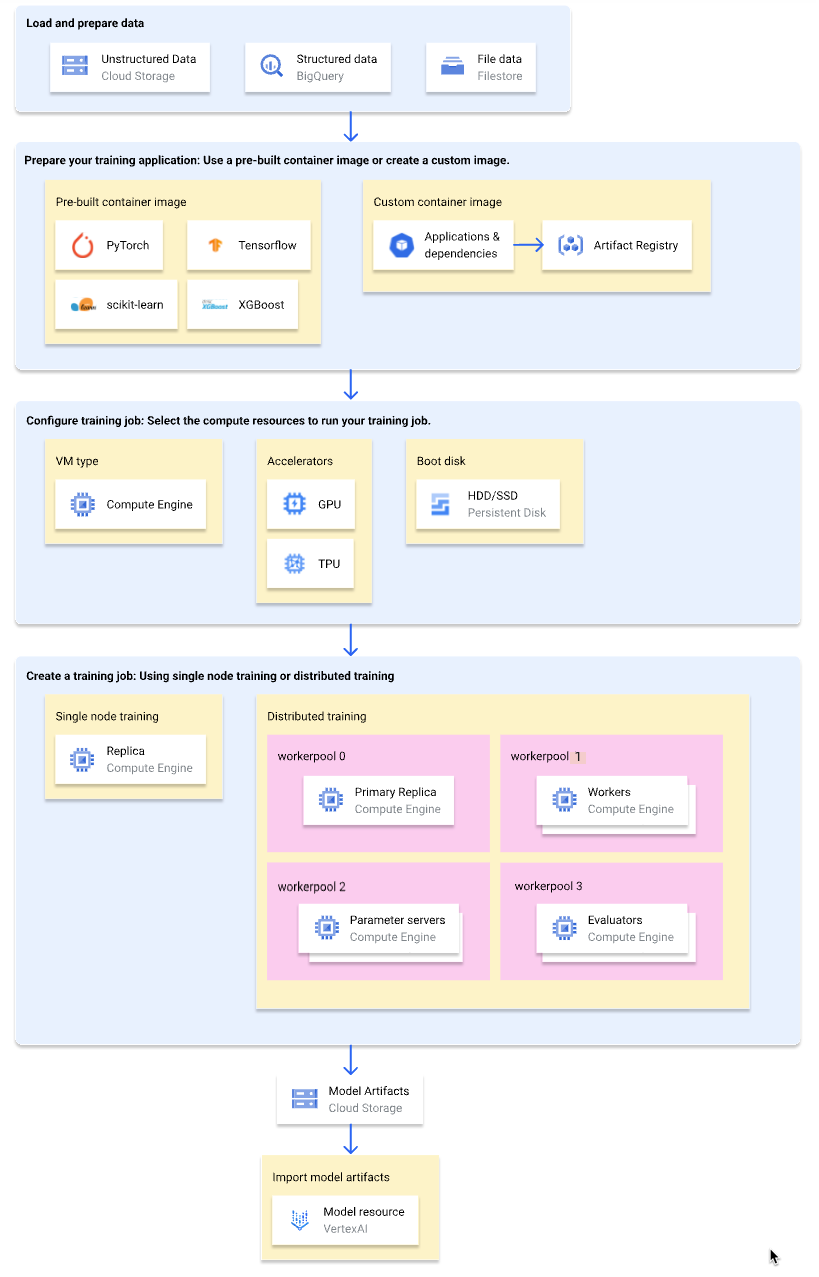
トレーニング データの読み込みと準備
最適なパフォーマンスとサポートを実現するために、次のいずれかの Google Cloud サービスをデータソースとして使用します。
これらのサービスの比較については、データ準備の概要をご覧ください。
トレーニング パイプラインを使用してモデルをトレーニングする場合は、データソースとして Vertex AI マネージド データセットを指定することもできます。同じデータセットを使用してカスタムモデルと AutoML モデルをトレーニングすると、2 つのモデルのパフォーマンスを比較できます。
トレーニング アプリケーションを準備する
Vertex AI で使用するトレーニング アプリケーションを準備する手順は次のとおりです。
- Vertex AI のトレーニング コードのベスト プラクティスを実装します。
- 使用するコンテナ イメージのタイプを決定します。
- 選択したコンテナ イメージのタイプに基づいて、トレーニング アプリケーションをサポートされている形式にパッケージ化します。
トレーニング コードのベスト プラクティスを実装する
トレーニング アプリケーションでは、Vertex AI のトレーニング コードのベスト プラクティスを実装する必要があります。これらのベスト プラクティスは、トレーニング アプリケーションの以下の機能に関連します。
- Google Cloud サービスへのアクセス。
- 入力データの読み込み。
- テスト追跡の自動ロギングを有効にする。
- モデル アーティファクトをエクスポートする。
- Vertex AI の環境変数を使用する。
- VM の再起動に対する復元力を確保する。
コンテナタイプを選択する
Vertex AI は、トレーニング アプリケーションを Docker コンテナ イメージ内で実行します。Docker コンテナ イメージは、コードとすべての依存関係が組み込まれた自己完結型のソフトウェア パッケージで、ほぼすべてのコンピューティング環境で実行できます。使用するビルド済みコンテナ イメージの URI を指定するか、トレーニング アプリケーションと依存関係がプリインストールされているカスタム コンテナ イメージを作成してアップロードできます。
次の表では、ビルド済みコンテナ イメージとカスタム コンテナ イメージの違いを示します。
| 仕様 | ビルド済みコンテナ イメージ | カスタム コンテナ イメージ |
|---|---|---|
| ML フレームワーク | 各コンテナ イメージは ML フレームワークに固有のものです。 | 任意の ML フレームワークを使用するか、何も使用しません。 |
| ML フレームワークのバージョン | 各コンテナ イメージは ML フレームワークのバージョンに固有のものです。 | マイナー バージョンやナイトリー ビルドなど、どの ML フレームワーク バージョンでも使用できます。 |
| アプリケーションの依存関係 | ML フレームワークに共通の依存関係がプリインストールされています。トレーニング アプリケーションにインストールする追加の依存関係を指定できます。 | トレーニング アプリケーションに必要な依存関係をプリインストールします。 |
| アプリケーションの配信形式 |
|
カスタム コンテナ イメージにトレーニング アプリケーションをプリインストールします。 |
| セットアップの手間 | 低 | 高 |
| 推奨する用途 | ビルド済みのコンテナ イメージがある ML フレームワークとフレームワーク バージョンに基づく Python トレーニング アプリケーション。 |
|
トレーニング アプリケーションをパッケージ化する
使用するコンテナ イメージのタイプを決定した後は、コンテナ イメージのタイプに基づいてトレーニング アプリケーションを以下のいずれかの形式にパッケージ化します。
ビルド済みコンテナで使用する 1 つの Python ファイル
トレーニング アプリケーションを 1 つの Python ファイルとして記述し、Vertex AI SDK for Python を使用して
CustomJobクラスまたはCustomTrainingJobクラスを作成します。この Python ファイルは、Python ソース ディストリビューションにパッケージ化され、ビルド済みのコンテナ イメージにインストールされます。トレーニング アプリケーションを 1 つの Python ファイルとして提供することは、プロトタイピングに適しています。本番環境のトレーニング アプリケーションでは、トレーニング アプリケーションを複数のファイルに配置することになると予想されます。ビルド済みコンテナで使用する Python ソース ディストリビューション
1 つ以上の Python ソース ディストリビューションにトレーニング アプリケーションをパッケージ化し、Cloud Storage バケットにアップロードします。Vertex AI は、トレーニング ジョブの作成時にソース ディストリビューションをビルド済みコンテナ イメージにインストールします。
カスタム コンテナ イメージ
トレーニング アプリケーションと依存関係がプリインストールされた独自の Docker コンテナ イメージを作成し、Artifact Registry にアップロードします。トレーニング アプリケーションが Python で記述されている場合は、1 つの Google Cloud CLI コマンドでこれらの手順を実施できます。
トレーニング ジョブを構成する
Vertex AI トレーニング ジョブは、次のタスクを実行します。
- 1 つ(単一ノード トレーニング)または複数(分散トレーニング)の仮想マシン(VM)をプロビジョニングします。
- プロビジョニングされた VM でコンテナ化されたトレーニング アプリケーションを実行します。
- トレーニング ジョブの完了後に VM を削除します。
Vertex AI には、トレーニング アプリケーションを実行するために 3 種類のトレーニング ジョブが用意されています。
-
カスタムジョブ(
CustomJob)はトレーニング アプリケーションを実行します。ビルド済みのコンテナ イメージを使用している場合、モデル アーティファクトは指定された Cloud Storage バケットに出力されます。カスタム コンテナ イメージの場合、トレーニング アプリケーションは他の場所にモデル アーティファクトを出力することもできます。 -
ハイパーパラメータ チューニング ジョブ(
HyperparameterTuningJob)は、最適なパフォーマンスのハイパーパラメータ値でモデル アーティファクトを生成するまで、さまざまなハイパーパラメータ値を使用して、トレーニング アプリケーションのトライアルを何度も実行します。テストするハイパーパラメータ値の範囲と最適化する指標を指定します。 -
トレーニング パイプライン(
CustomTrainingJob)は、カスタムジョブまたはハイパーパラメータ チューニング ジョブを実行し、必要に応じてモデル アーティファクトを Vertex AI にエクスポートしてモデルリソースを作成します。データソースとして Vertex AI マネージド データセットを指定できます。
トレーニング ジョブを作成するときに、トレーニング アプリケーションの実行に使用するコンピューティング リソースを指定し、コンテナ設定を構成します。
コンピューティングの構成
トレーニング ジョブに使用するコンピューティング リソースを指定します。Vertex AI は、トレーニング ジョブが 1 つの VM で実行される単一ノード トレーニングと、トレーニング ジョブが複数の VM で実行される分散トレーニングをサポートしています。
トレーニング ジョブに指定できるコンピューティング リソースは次のとおりです。
VM マシンタイプ
マシンタイプによって、CPU、メモリサイズ、帯域幅が異なります。
画像処理装置(GPU)
A2 または N1 タイプの VM には、1 つ以上の GPU を追加できます。トレーニング アプリケーションが GPU を使用するように設計されている場合、GPU を追加すると、パフォーマンスが大幅に向上します。
Tensor Processing Unit(TPU)
TPU は、ML ワークロードの高速化を目的として設計されています。トレーニングに TPU VM を使用する場合は、ワーカープールを 1 つだけ指定できます。そのワーカープールは、レプリカを 1 つだけ持つことができます。
ブートディスク
ブートディスクには SSD(デフォルト)または HDD を使用できます。トレーニング アプリケーションがディスクの読み取りと書き込みを行う場合は、SSD を使用するとパフォーマンスを改善できます。トレーニング アプリケーションがディスクに書き込む一時データの量に基づいて、ブートディスクのサイズを指定することもできます。ブートディスクのサイズは、100 GiB(デフォルト)~64,000 GiB です。ワーカープール内の VM は、すべて同じ種類とサイズのブートディスクを使用しなければなりません。
コンテナの構成
ビルド済みのコンテナ イメージを使用するか、カスタム コンテナ イメージを使用するかによって、異なるコンテナ構成を作成する必要があります。
ビルド済みコンテナの構成:
- 使用するビルド済みコンテナ イメージの URI を指定します。
- トレーニング アプリケーションが Python ソース ディストリビューションとしてパッケージ化されている場合は、パッケージが置かれている Cloud Storage URI を指定します。
- トレーニング アプリケーションのエントリ ポイント モジュールを指定します。
- 省略可: トレーニング アプリケーションのエントリ ポイント モジュールに渡すコマンドライン引数のリストを指定します。
カスタム コンテナ構成:
- カスタム コンテナ イメージの URI を指定します。Artifact Registry または Docker Hub の URI を使用できます。
- 省略可: コンテナ イメージの
ENTRYPOINT手順またはCMD手順をオーバーライドします。
トレーニング ジョブを作成する
データとトレーニング アプリケーションの準備ができたら、次のいずれかのトレーニング ジョブを作成して、トレーニング アプリケーションを実行します。
トレーニング ジョブの作成には、 Google Cloud コンソール、Google Cloud CLI、Vertex AI SDK for Python、Vertex AI API のいずれかを使用できます。
(省略可)Vertex AI にモデル アーティファクトをインポートする
トレーニング アプリケーションは、1 つ以上のモデル アーティファクトを指定の場所(通常は Cloud Storage バケット)に出力します。モデル アーティファクトから Vertex AI で推論を取得する前に、まずモデル アーティファクトを Vertex AI Model Registry にインポートします。
トレーニング用のコンテナ イメージと同様、Vertex AI では、推論にビルド済みコンテナ イメージを使用するか、カスタム コンテナ イメージを使用するかを選択できます。お使いの ML フレームワークとフレームワーク バージョンで推論用のビルド済みコンテナ イメージを利用できる場合は、ビルド済みコンテナ イメージの使用をおすすめします。
次のステップ
- モデルから推論を取得する。
- モデルを評価する。
- Hello カスタム トレーニング チュートリアルを試して、TensorFlow Keras 画像分類モデルを Vertex AI でトレーニングするための手順を確認する。