Tabular Workflows es un conjunto de flujos de trabajo integrados, totalmente gestionados y escalables para el aprendizaje automático integral con datos tabulares. Aprovecha la tecnología de Google para desarrollar modelos y te ofrece opciones de personalización para que se adapte a tus necesidades.
Ventajas
- Totalmente gestionado: no tienes que preocuparte por las actualizaciones, las dependencias ni los conflictos.
- Fácil de escalar: no es necesario rediseñar la infraestructura a medida que aumentan las cargas de trabajo o los conjuntos de datos.
- Rendimiento optimizado: el hardware adecuado se configura automáticamente según los requisitos del flujo de trabajo.
- Integración profunda: la compatibilidad con los productos de la suite MLOps de Vertex AI, como Vertex AI Pipelines y Vertex AI Experiments, te permite realizar muchos experimentos en poco tiempo.
Información técnica
Cada flujo de trabajo es una instancia gestionada de Vertex AI Pipelines.
Vertex AI Pipelines es un servicio sin servidor que ejecuta flujos de procesamiento de Kubeflow. Puedes usar las pipelines para automatizar y monitorizar tus tareas de aprendizaje automático y preparación de datos. Cada paso de una pipeline realiza una parte del flujo de trabajo de la canalización. Por ejemplo, una canalización puede incluir pasos para dividir datos, transformar tipos de datos y entrenar un modelo. Como los pasos son instancias de componentes de flujo de trabajo, tienen entradas, salidas y una imagen de contenedor. Las entradas de los pasos se pueden definir a partir de las entradas de la canalización o pueden depender de la salida de otros pasos de la canalización. Estas dependencias definen el flujo de trabajo de la canalización como un grafo acíclico dirigido.
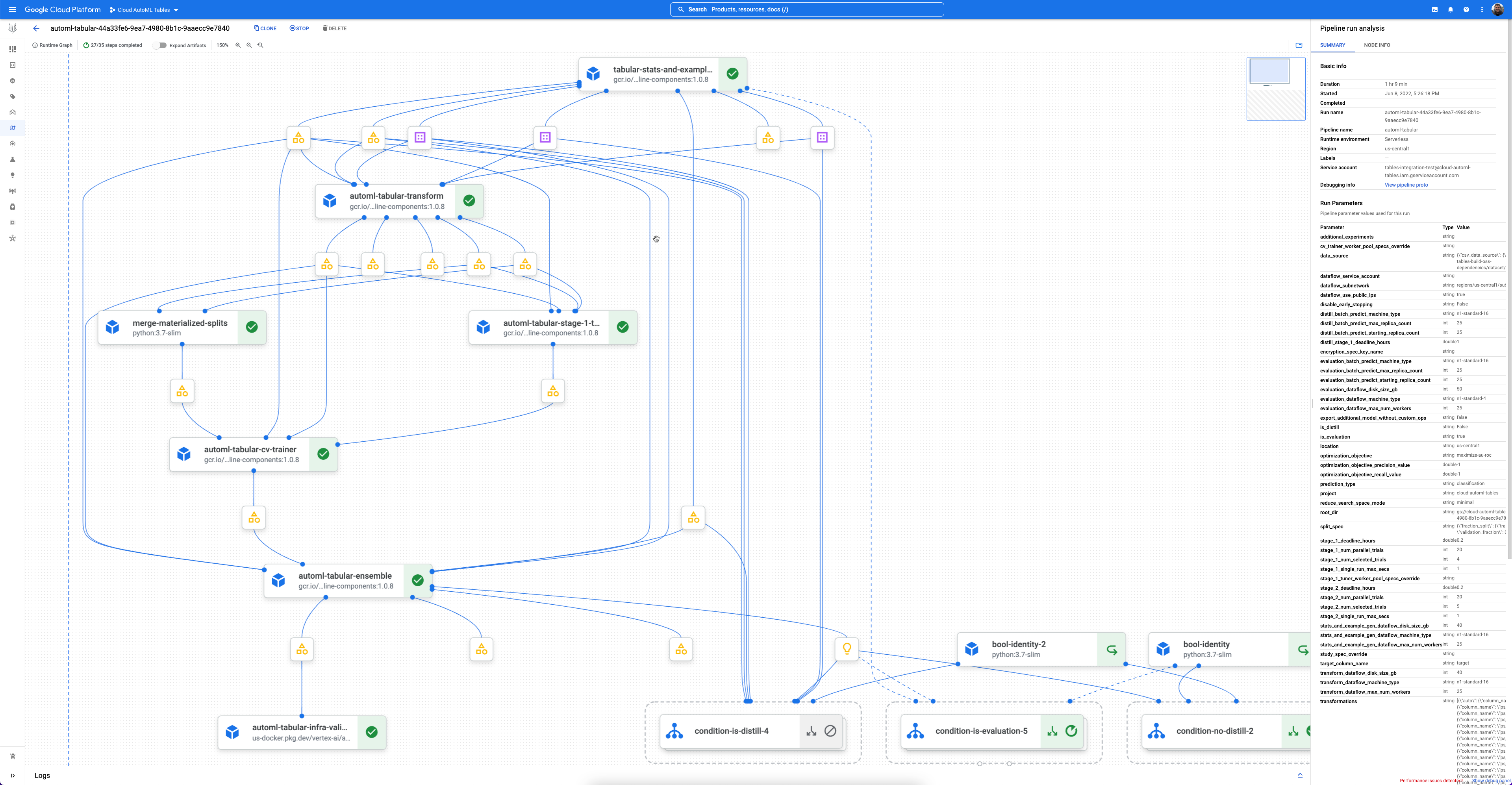
Empezar
En la mayoría de los casos, defina y ejecute la canalización con el Google Cloud SDK de componentes de canalización. El siguiente código de ejemplo ilustra este proceso. Ten en cuenta que la implementación real del código puede variar.
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
Para obtener ejemplos de Colab y cuadernos, ponte en contacto con tu representante de ventas o rellena un formulario de solicitud.
Gestión de versiones y mantenimiento
Los flujos de trabajo tabulares tienen un sistema de control de versiones eficaz que permite realizar actualizaciones y mejoras continuas sin que se produzcan cambios en tus aplicaciones.
Cada flujo de trabajo se lanza y se actualiza como parte del Google Cloud SDK de componentes de la canalización. Las actualizaciones y modificaciones de cualquier flujo de trabajo se publican como nuevas versiones de ese flujo de trabajo. Las versiones anteriores de cada flujo de trabajo siempre están disponibles a través de las versiones anteriores del SDK. Si la versión del SDK está fijada, también lo estará la versión del flujo de trabajo.
Flujos de trabajo disponibles
Vertex AI ofrece los siguientes flujos de trabajo tabulares:
| Nombre | Tipo | Disponibilidad |
|---|---|---|
| Feature Transform Engine | Ingeniería de funciones | Vista previa pública |
| AutoML de principio a fin | Clasificación y regresión | Disponible de forma general |
| TabNet | Clasificación y regresión | Vista previa pública |
| Amplia y detallada | Clasificación y regresión | Vista previa pública |
| Previsiones | Previsión | Vista previa pública |
Para obtener más información y cuadernos de ejemplo, ponte en contacto con tu representante de ventas o rellena un formulario de solicitud.
Feature Transform Engine
Feature Transform Engine selecciona y transforma las características. Si la selección de funciones está habilitada, Feature Transform Engine crea un conjunto de funciones importantes clasificadas. Si las transformaciones de funciones están habilitadas, Feature Transform Engine procesa las funciones para asegurarse de que la entrada para el entrenamiento y el servicio del modelo sea coherente. Feature Transform Engine se puede usar de forma independiente o junto con cualquiera de los flujos de trabajo de entrenamiento tabular. Es compatible con frameworks de TensorFlow y de otro tipo.
Para obtener más información, consulta Ingeniería de funciones.
Flujos de trabajo tabulares para clasificación y regresión
Flujo de trabajo tabular para AutoML integral
El flujo de trabajo tabular de AutoML integral es una canalización de AutoML completa para tareas de clasificación y regresión. Es similar a la API AutoML, pero te permite elegir qué quieres controlar y qué quieres automatizar. En lugar de tener controles para toda la canalización, tienes controles para cada paso de la canalización. Estos controles de la canalización incluyen lo siguiente:
- División de datos
- Ingeniería de funciones
- Búsqueda de arquitectura
- Preparación de modelos
- Ensamblado de modelos
- Destilación de modelos
Ventajas
- Admite conjuntos de datos de gran tamaño de varios terabytes y hasta 1000 columnas.
- Te permite mejorar la estabilidad y reducir el tiempo de entrenamiento limitando el espacio de búsqueda de tipos de arquitectura u omitiendo la búsqueda de arquitectura.
- Te permite mejorar la velocidad de entrenamiento seleccionando manualmente el hardware que se va a usar para el entrenamiento y la búsqueda de arquitectura.
- Te permite reducir el tamaño del modelo y mejorar la latencia con la destilación o cambiando el tamaño del conjunto.
- Cada componente de AutoML se puede inspeccionar en una interfaz de gráfico de canalizaciones potente que te permite ver las tablas de datos transformadas, las arquitecturas de modelos evaluadas y muchos más detalles.
- Cada componente de AutoML obtiene más flexibilidad y transparencia, como la posibilidad de personalizar parámetros y hardware, ver el estado del proceso y los registros, entre otras opciones.
Entrada/Salida
- Toma como entrada una tabla de BigQuery o un archivo CSV de Cloud Storage.
- Genera un modelo de Vertex AI como salida.
- Los resultados intermedios incluyen estadísticas y divisiones de conjuntos de datos.
Para obtener más información, consulta Flujo de trabajo tabular para AutoML de principio a fin.
Flujo de trabajo tabular para TabNet
Tabular Workflow for TabNet es un flujo de procesamiento que puedes usar para entrenar modelos de clasificación o regresión. TabNet usa la atención secuencial para elegir las características que se deben tener en cuenta en cada paso de la decisión. Esto favorece la interpretabilidad y un aprendizaje más eficiente, ya que la capacidad de aprendizaje se utiliza para las funciones más destacadas.
Ventajas
- Selecciona automáticamente el espacio de búsqueda de hiperparámetros adecuado en función del tamaño del conjunto de datos, el tipo de inferencia y el presupuesto de entrenamiento.
- Integrado con Vertex AI. El modelo entrenado es un modelo de Vertex AI. Puedes ejecutar inferencias por lotes o desplegar el modelo para hacer inferencias online de inmediato.
- Proporciona una interpretabilidad inherente del modelo. Puedes consultar qué funciones ha usado TabNet para tomar su decisión.
- Admite el entrenamiento con GPU.
Entrada/Salida
Toma como entrada una tabla de BigQuery o un archivo CSV de Cloud Storage y proporciona un modelo de Vertex AI como salida.
Para obtener más información, consulta Flujo de trabajo tabular de TabNet.
Flujo de trabajo tabular para modelos profundos y amplios
Tabular Workflow for Wide & Deep es un flujo de procesamiento que puedes usar para entrenar modelos de clasificación o regresión. Wide & Deep entrena conjuntamente modelos lineales amplios y redes neuronales profundas. Combina las ventajas de la memorización y la generalización. En algunos experimentos online, los resultados mostraron que Wide & Deep aumentó significativamente las adquisiciones de aplicaciones de Google Store en comparación con los modelos de solo ancho y solo profundidad.
Ventajas
- Integrado con Vertex AI. El modelo entrenado es un modelo de Vertex AI. Puedes ejecutar inferencias por lotes o desplegar el modelo para hacer inferencias online de inmediato.
Entrada/Salida
Toma como entrada una tabla de BigQuery o un archivo CSV de Cloud Storage y proporciona un modelo de Vertex AI como salida.
Para obtener más información, consulta Flujo de trabajo tabular para formatos anchos y profundos.
Flujos de trabajo tabulares para hacer previsiones
Flujo de trabajo tabular para hacer previsiones
El flujo de trabajo tabular para las previsiones es la canalización completa para las tareas de previsión. Es similar a la API AutoML, pero te permite elegir qué controlar y qué automatizar. En lugar de tener controles para toda la canalización, tienes controles para cada paso de la canalización. Estos controles de la canalización incluyen lo siguiente:
- División de datos
- Ingeniería de funciones
- Búsqueda de arquitectura
- Preparación de modelos
- Ensamblado de modelos
Ventajas
- Admite conjuntos de datos de gran tamaño de hasta 1 TB y 200 columnas.
- Te permite mejorar la estabilidad y reducir el tiempo de entrenamiento limitando el espacio de búsqueda de los tipos de arquitectura o saltándote la búsqueda de arquitectura.
- Te permite mejorar la velocidad de entrenamiento seleccionando manualmente el hardware que se va a usar para el entrenamiento y la búsqueda de arquitectura.
- Te permite reducir el tamaño del modelo y mejorar la latencia cambiando el tamaño del conjunto.
- Cada componente se puede inspeccionar en una interfaz de gráfico de canalizaciones potente que te permite ver las tablas de datos transformadas, las arquitecturas de modelos evaluadas y muchos más detalles.
- Cada componente obtiene más flexibilidad y transparencia, como la posibilidad de personalizar parámetros, hardware, ver el estado del proceso, los registros y más.
Entrada/Salida
- Toma como entrada una tabla de BigQuery o un archivo CSV de Cloud Storage.
- Genera un modelo de Vertex AI como salida.
- Los resultados intermedios incluyen estadísticas y divisiones de conjuntos de datos.
Para obtener más información, consulta Flujo de trabajo tabular para la previsión.
Siguientes pasos
- Consulta información sobre el flujo de trabajo tabular de AutoML de principio a fin.
- Consulta información sobre el flujo de trabajo tabular de TabNet.
- Consulta información sobre el flujo de trabajo tabular para la función de aprendizaje profundo y amplio.
- Consulta información sobre el flujo de trabajo tabular para las previsiones.
- Consulta información sobre la ingeniería de funciones.
- Consulta información sobre los precios de los flujos de trabajo tabulares.