Quando usa um conjunto de dados para preparar um modelo do AutoML, o Vertex AI divide os seus dados em três divisões: uma divisão de preparação, uma divisão de validação e uma divisão de teste. O objetivo principal ao criar divisões de dados é garantir que o conjunto de testes representa com precisão os dados de produção. Isto garante que as métricas de avaliação fornecem um sinal preciso sobre o desempenho do modelo em dados do mundo real.
Esta página aborda a forma como o Vertex AI usa os conjuntos de dados de preparação, validação e teste para preparar um modelo do AutoML. Também descreve as formas como pode controlar a forma como os seus dados são divididos entre estes três conjuntos. Os algoritmos de divisão de dados para classificação e regressão diferem dos algoritmos de divisão de dados para previsão.
Divisões de dados para classificação e regressão
Como são usadas as divisões de dados
As divisões de dados são usadas no processo de preparação da seguinte forma:
Testes de modelos
O conjunto de preparação é usado para preparar modelos com diferentes combinações de opções de pré-processamento, arquitetura e hiperparâmetros. O Vertex AI avalia estes modelos no conjunto de validação para determinar a qualidade, o que orienta a exploração de combinações de opções adicionais. O conjunto de validação também é usado para selecionar o melhor ponto de verificação a partir da avaliação periódica durante a preparação. A Vertex AI usa os melhores parâmetros e arquiteturas determinados na fase de ajuste paralelo para preparar dois modelos de conjunto, conforme descrito abaixo.
Avaliação do modelo
O Vertex AI prepara um modelo de avaliação com os conjuntos de preparação e validação como dados de preparação. A Vertex AI gera as métricas de avaliação do modelo finais neste modelo, usando o conjunto de testes. Esta é a primeira vez no processo que o conjunto de testes é usado. Esta abordagem garante que as métricas de avaliação finais são um reflexo imparcial do desempenho do modelo final preparado em produção.
Modelo de publicação
O Vertex AI prepara um modelo com os conjuntos de preparação, validação e teste para maximizar a quantidade de dados de preparação. Use este modelo para pedir previsões online ou previsões em lote.
Divisão de dados predefinida
Por predefinição, o Vertex AI usa um algoritmo de divisão aleatória para separar os dados nas três divisões de dados. O Vertex AI seleciona aleatoriamente 80% das linhas de dados para o conjunto de preparação, 10% para o conjunto de validação e 10% para o conjunto de teste. Recomendamos a divisão predefinida para conjuntos de dados que:
- Não se altera ao longo do tempo.
- Relativamente equilibrado.
- Distribuídos como os dados usados para previsões em produção.
Para usar a divisão de dados predefinida, aceite a predefinição na Google Cloud consola ou deixe o campo divisão vazio para a API.
Opções para controlar as divisões de dados
Pode controlar que linhas são selecionadas para que divisão através de uma das seguintes abordagens:
- Divisão aleatória: defina as percentagens de divisão e atribua aleatoriamente as linhas de dados.
- Divisão manual: selecione linhas específicas para usar na preparação, na validação e nos testes na coluna de divisão de dados.
- Divisão cronológica: divida os dados por tempo na coluna Hora.
Escolha apenas uma destas opções. Faça a escolha quando preparar o modelo. Algumas destas opções requerem alterações aos dados de preparação (por exemplo, a coluna de divisão de dados ou a coluna de tempo). A inclusão de dados para opções de divisão de dados não exige que use essas opções. Pode continuar a escolher outra opção quando preparar o modelo.
A divisão predefinida não é a melhor escolha se:
Não está a preparar um modelo de previsão, mas os seus dados são sensíveis ao tempo.
Neste caso, use uma divisão cronológica ou uma divisão manual que resulte na utilização dos dados mais recentes como o conjunto de testes.
Os seus dados de teste incluem dados de populações que não vão estar representadas na produção.
Por exemplo, suponha que prepara um modelo com dados de compras de várias lojas. No entanto, sabe que o modelo vai ser usado principalmente para fazer previsões para lojas que não estão nos dados de preparação. Para garantir que o modelo pode generalizar para lojas não vistas, segmente os conjuntos de dados por lojas. Por outras palavras, o conjunto de testes deve incluir apenas lojas diferentes do conjunto de validação, e o conjunto de validação deve incluir apenas lojas diferentes do conjunto de preparação.
As suas classes estão desequilibradas.
Se tiver muito mais exemplos de uma classe do que de outra nos dados de preparação, pode ter de incluir manualmente mais exemplos da classe minoritária nos dados de teste. A Vertex AI não realiza uma amostragem estratificada, pelo que o conjunto de testes pode incluir poucos ou mesmo nenhum exemplo da classe minoritária.
Divisão aleatória
A divisão aleatória também é conhecida como "divisão matemática" ou "divisão de frações".
Por predefinição, as percentagens de dados de preparação usados para os conjuntos de preparação, validação e teste são, respetivamente, 80, 10 e 10. Se usar a Google Cloud consola, pode alterar as percentagens para quaisquer valores que totalizem 100. Se usar a API Vertex AI, use frações que somadas dão 1,0.
Para alterar as percentagens (frações), use o objeto FractionSplit para definir as suas frações.
O Vertex AI seleciona linhas para uma divisão de dados aleatoriamente, mas de forma determinística. Se não estiver satisfeito com a composição das divisões de dados geradas, use uma divisão manual ou altere os dados de treino. A preparação de um novo modelo com os mesmos dados de preparação resulta na mesma divisão de dados.
Divisão manual
A divisão manual também é conhecida como "divisão predefinida".
Uma coluna de divisão de dados permite-lhe selecionar linhas específicas a usar para preparação, validação e testes. Quando criar os dados de preparação, adicione uma coluna que possa conter um dos seguintes valores (com distinção entre maiúsculas e minúsculas):
TRAINVALIDATETESTUNASSIGNED
Os valores nesta coluna têm de ser uma das duas combinações seguintes:
- Todos de
TRAIN,VALIDATEeTEST - Apenas
TESTeUNASSIGNED
Cada linha tem de ter um valor para esta coluna. Não pode ser uma string vazia.
Por exemplo, com todos os conjuntos especificados:
"TRAIN","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "TRAIN","Roger","Rogers","123-45-6789" "VALIDATE","Sarah","Smith","333-33-3333"
Com apenas o conjunto de testes especificado:
"UNASSIGNED","John","Doe","555-55-5555" "TEST","Jane","Doe","444-44-4444" "UNASSIGNED","Roger","Rogers","123-45-6789" "UNASSIGNED","Sarah","Smith","333-33-3333"
A coluna de divisão de dados pode ter qualquer nome de coluna válido. O respetivo tipo de transformação pode ser Categorial, Texto ou Automático.
Se o valor da coluna de divisão de dados for UNASSIGNED, o Vertex AI
atribui automaticamente essa linha ao conjunto de preparação ou validação.
Designar uma coluna como uma coluna de divisão de dados durante a preparação do modelo.
Divisão cronológica
A divisão cronológica também é conhecida como "divisão por data/hora".
Se os seus dados forem dependentes do tempo, pode designar uma coluna como coluna de tempo. A Vertex AI usa a coluna Time para dividir os seus dados. As linhas mais antigas são usadas para a preparação, as seguintes para a validação e as mais recentes para os testes.
O Vertex AI trata cada linha como um exemplo de preparação independente e identicamente distribuído. A definição da coluna Time não altera este comportamento. A coluna Hora é usada apenas para dividir o conjunto de dados.
Se especificar uma coluna Time, inclua um valor para a coluna Time para cada linha no conjunto de dados. Certifique-se de que a coluna Time tem valores distintos suficientes para que os conjuntos de validação e de teste não estejam vazios. Normalmente, pelo menos, 20 valores distintos devem ser suficientes.
Os dados na coluna Hora têm de estar em conformidade com um dos formatos suportados pela transformação de data/hora. No entanto, a coluna Hora pode ter qualquer transformação suportada, porque a transformação afeta apenas a forma como essa coluna é usada na preparação. As transformações não afetam a divisão de dados.
Também pode especificar as percentagens dos dados de treino que são atribuídas a cada conjunto.
Designar uma coluna como uma coluna de tempo durante a preparação do modelo.
Divisões de dados para previsões
Por predefinição, o Vertex AI usa um algoritmo de divisão cronológica para separar os dados de previsão nas três divisões de dados. Recomendamos que use a divisão predefinida. No entanto, se quiser controlar que linhas de dados de preparação são usadas para que divisão, use uma divisão manual.
Como são usadas as divisões de dados
As divisões de dados são usadas no processo de preparação da seguinte forma:
Testes de modelos
O conjunto de preparação é usado para preparar modelos com diferentes combinações de opções de pré-processamento, arquitetura e hiperparâmetros. O Vertex AI avalia estes modelos no conjunto de validação para determinar a qualidade, o que orienta a exploração de combinações de opções adicionais. O conjunto de validação também é usado para selecionar o melhor ponto de verificação a partir da avaliação periódica durante a preparação. A Vertex AI usa os melhores parâmetros e arquiteturas determinados na fase de ajuste paralelo para preparar dois modelos de conjunto, conforme descrito abaixo.
Avaliação do modelo
O Vertex AI prepara um modelo de avaliação com os conjuntos de preparação e validação como dados de preparação. O Vertex AI gera as métricas de avaliação do modelo finais neste modelo, usando o conjunto de testes. Esta é a primeira vez no processo que o conjunto de testes é usado. Esta abordagem garante que as métricas de avaliação finais são um reflexo imparcial do desempenho do modelo final preparado em produção.
Modelo de publicação
O Vertex AI prepara um modelo com o conjunto de preparação e validação. O modelo é validado (para selecionar o melhor ponto de verificação) através do conjunto de testes. O conjunto de testes nunca é usado para o treino no sentido de que a perda é calculada a partir dele. Usa este modelo para obter inferências.
Divisão predefinida
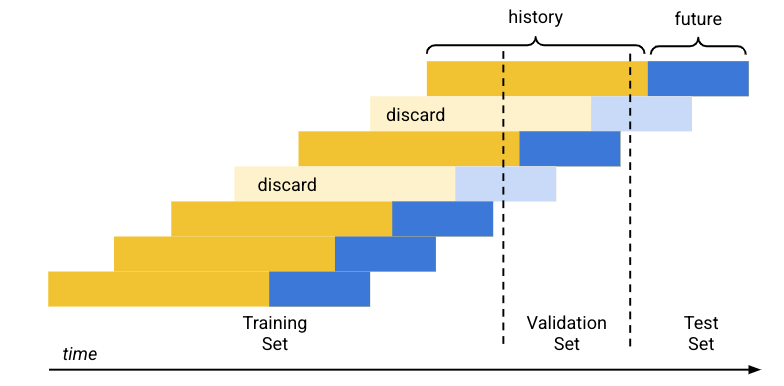
A divisão de dados predefinida (cronológica) funciona da seguinte forma:
- O Vertex AI ordena os dados de preparação por data.
- Usando as percentagens predeterminadas (80/10/10), a Vertex AI separa o período abrangido pelos dados de preparação em três blocos, um para cada conjunto de preparação.
- O Vertex AI adiciona linhas vazias ao início de cada série cronológica para permitir que o modelo aprenda com linhas que não têm histórico suficiente (janela de contexto). O número de linhas adicionadas é o tamanho da janela de contexto definido no momento da formação.
Usando o tamanho do horizonte de previsão definido no momento da preparação, o Vertex AI usa cada linha cujos dados futuros (horizonte de previsão) se enquadram totalmente num dos conjuntos de dados para esse conjunto. (O Vertex AI rejeita linhas cujo horizonte de previsão abrange dois conjuntos para evitar a fuga de dados.)
Divisão manual
Uma coluna de divisão de dados permite-lhe selecionar linhas específicas a usar para preparação, validação e testes. Quando criar os dados de preparação, adicione uma coluna que possa conter um dos seguintes valores (com distinção entre maiúsculas e minúsculas):
TRAINVALIDATETEST
Cada linha tem de ter um valor para esta coluna. Não pode ser uma string vazia.
Por exemplo:
"TRAIN","sku_id_1","2020-09-21","10" "TEST","sku_id_1","2020-09-22","23" "TRAIN","sku_id_2","2020-09-22","3" "VALIDATE","sku_id_2","2020-09-23","45"
A coluna de divisão de dados pode ter qualquer nome de coluna válido. O respetivo tipo de transformação pode ser Categorial, Texto ou Automático.
Designar uma coluna como uma coluna de divisão de dados durante a preparação do modelo.
Certifique-se de que tem cuidado para evitar a fuga de dados entre as suas séries cronológicas.