Questa guida per principianti introduce come ottenere inferenze da modelli personalizzati su Vertex AI.
Obiettivi di apprendimento
Livello di esperienza con Vertex AI: principiante
Tempo di lettura stimato: 15 minuti
Cosa imparerai:
- Vantaggi dell'utilizzo di un servizio di inferenza gestito.
- Come funzionano le inferenze batch in Vertex AI.
- Come funzionano le inferenze online in Vertex AI.
Perché utilizzare un servizio di inferenza gestito?
Immagina di dover creare un modello che prende come input un'immagine
di una pianta e ne prevede la specie. Potresti iniziare addestrando un modello in
un notebook, provando diversi iperparametri e architetture. Quando
hai un modello addestrato, puoi chiamare il metodo predict nel framework ML che preferisci e testare la qualità del modello.
Questo flusso di lavoro è ideale per la sperimentazione, ma quando vuoi utilizzare il modello per ottenere inferenze su molti dati o inferenze a bassa latenza al volo, avrai bisogno di qualcosa di più di un notebook. Ad esempio, supponiamo che tu stia cercando di misurare la biodiversità di un particolare ecosistema e invece di far identificare e contare manualmente le specie vegetali da parte di persone in natura, vuoi utilizzare questo modello di ML per classificare grandi batch di immagini. Se utilizzi un notebook, potresti riscontrare limitazioni di memoria. Inoltre, ottenere inferenze per tutti questi dati è probabilmente un'attività di lunga durata che potrebbe scadere nel notebook.
O se volessi utilizzare questo modello in un'applicazione in cui gli utenti possono caricare immagini di piante e farle identificare immediatamente? Avrai bisogno di un posto per ospitare il modello al di fuori di un blocco note che la tua applicazione può chiamare per un'inferenza. Inoltre, è improbabile che il traffico verso il modello sia costante, quindi ti servirà un servizio in grado di scalare automaticamente quando necessario.
In tutti questi casi, un servizio di inferenza gestito ridurrà le difficoltà di hosting e utilizzo dei tuoi modelli ML. Questa guida fornisce un'introduzione all'ottenimento di inferenze dai modelli ML su Vertex AI. Tieni presente che esistono personalizzazioni, funzionalità e modi aggiuntivi per interagire con il servizio che non sono trattati qui. Questa guida ha lo scopo di fornire una panoramica. Per ulteriori informazioni, consulta la documentazione sulle inferenze di Vertex AI.
Panoramica del servizio di inferenza gestito
Vertex AI supporta le inferenze batch e online.
L'inferenza batch è una richiesta asincrona. È una buona soluzione quando non hai bisogno di una risposta immediata e vuoi elaborare i dati accumulati in un'unica richiesta. Nell'esempio discusso nell'introduzione, questo sarebbe il caso d'uso della biodiversità caratterizzante.
Se vuoi ottenere inferenze a bassa latenza dai dati passati al tuo modello al volo, puoi utilizzare l'inferenza online. Nell'esempio discusso nell'introduzione, questo sarebbe il caso d'uso in cui vuoi incorporare il tuo modello in un'app che aiuti gli utenti a identificare immediatamente le specie vegetali.
Carica il modello in Vertex AI Model Registry
Per utilizzare il servizio di inferenza, il primo passo è caricare il modello di ML addestrato nel registro dei modelli Vertex AI. Si tratta di un registro in cui puoi gestire il ciclo di vita dei tuoi modelli.
Crea una risorsa modello
Quando addestri i modelli con il servizio di addestramento personalizzato Vertex AI, puoi importare automaticamente il modello nel registro al termine del job di addestramento. Se hai saltato questo passaggio o hai addestrato il modello al di fuori di Vertex AI, puoi caricarlo manualmente utilizzando la console Google Cloud o l'SDK Vertex AI per Python indicando una posizione Cloud Storage con gli artefatti del modello salvati. Il formato di questi artefatti del modello potrebbe essere savedmodel.pb, model.joblib e così via, a seconda del framework ML che utilizzi.
Il caricamento degli artefatti in Vertex AI Model Registry crea una risorsa Model, visibile nella console Google Cloud :
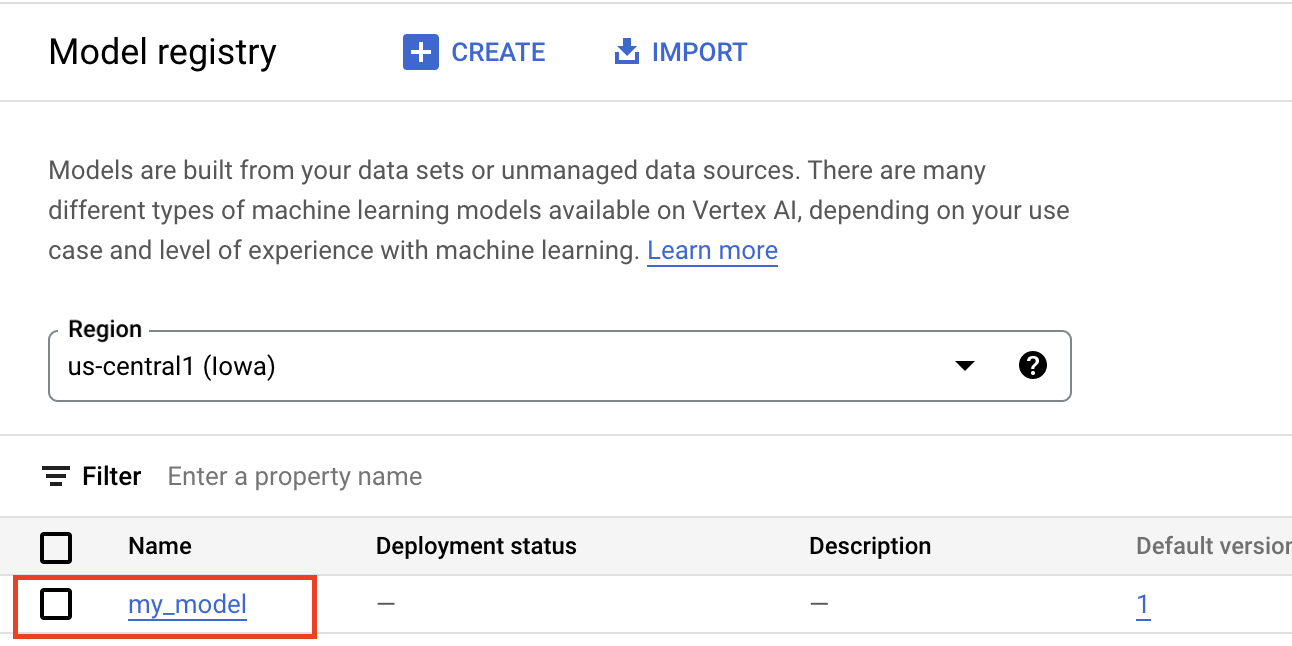
Seleziona un contenitore
Quando importi un modello in Vertex AI Model Registry, devi associarlo a un container affinché Vertex AI possa gestire le richieste di inferenza.
Container predefiniti
Vertex AI fornisce container predefiniti che puoi utilizzare per le inferenze. I container predefiniti sono organizzati per framework ML e versione del framework e forniscono server di inferenza HTTP che puoi utilizzare per fornire inferenze con una configurazione minima. Eseguono solo l'operazione di inferenza del framework di machine learning, quindi se devi pre-elaborare i dati, devi farlo prima di effettuare la richiesta di inferenza. Allo stesso modo, qualsiasi post-elaborazione deve avvenire dopo l'esecuzione della richiesta di inferenza. Per un esempio di utilizzo di un container predefinito, consulta il notebook Serving PyTorch image models with prebuilt containers on Vertex AI.
Container personalizzati
Se il tuo caso d'uso richiede librerie non incluse nei container predefiniti o se vuoi eseguire trasformazioni dei dati personalizzate nell'ambito della richiesta di inferenza, puoi utilizzare un container personalizzato che crei e invii ad Artifact Registry. Sebbene i container personalizzati consentano una maggiore personalizzazione, il container deve eseguire un server HTTP. Nello specifico, il container deve ascoltare e rispondere ai controlli di attività, ai controlli di integrità e alle richieste di inferenza. Nella maggior parte dei casi, utilizzare un container predefinito, se possibile, è l'opzione consigliata e più semplice. Per un esempio di utilizzo di un container personalizzato, consulta il blocco note PyTorch Image Classification Single GPU using Vertex Training with Custom Container.
Routine di inferenza personalizzate
Se il tuo caso d'uso richiede trasformazioni di pre e post-elaborazione personalizzate e non vuoi l'overhead di creazione e manutenzione di un container personalizzato, puoi utilizzare routine di inferenza personalizzate. Con le routine di inferenza personalizzate, puoi fornire le trasformazioni dei dati come codice Python e, dietro le quinte, l'SDK Vertex AI per Python creerà un container personalizzato che puoi testare localmente ed eseguire il deployment su Vertex AI. Per un esempio di utilizzo di routine di inferenza personalizzate, consulta il notebook Custom inference routines with Sklearn
Ottenere inferenze batch
Una volta che il modello si trova in Vertex AI Model Registry, puoi inviare un job di inferenza batch dalla Google Cloud console o dall'SDK Vertex AI per Python. Specificherai la posizione dei dati di origine, nonché la posizione in Cloud Storage o BigQuery in cui vuoi salvare i risultati. Puoi anche specificare il tipo di macchina su cui vuoi che venga eseguito questo job e gli eventuali acceleratori facoltativi. Poiché il servizio di inferenza è completamente gestito, Vertex AI esegue automaticamente il provisioning delle risorse di calcolo, esegue l'attività di inferenza e garantisce l'eliminazione delle risorse di calcolo al termine del job di inferenza. Lo stato dei job di inferenza batch può essere monitorato nella console Google Cloud .
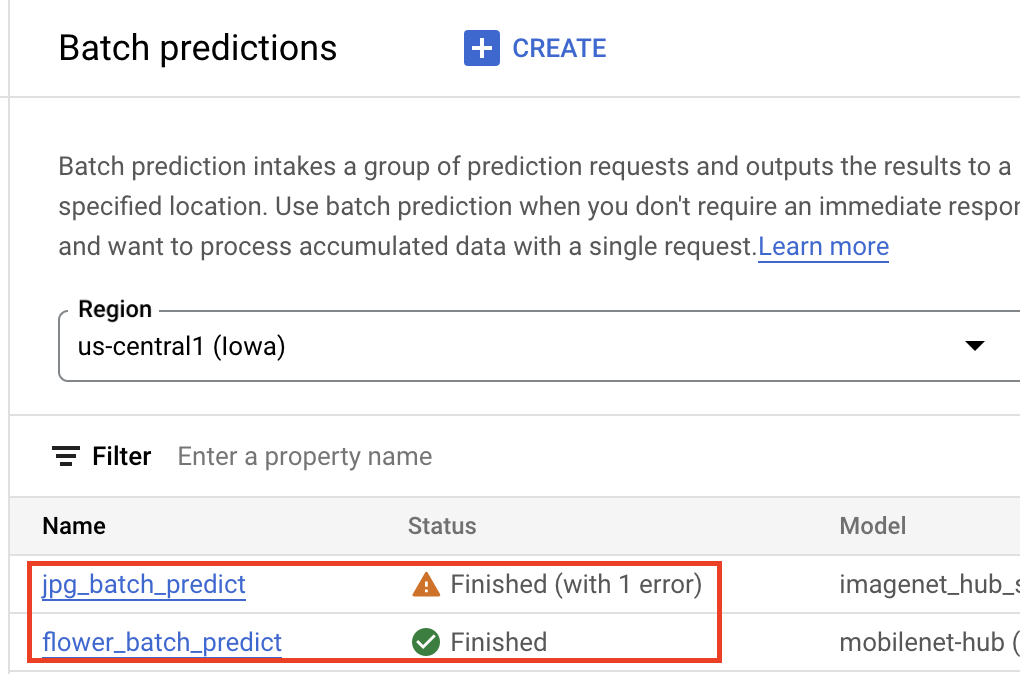
Ottenere inferenze online
Se vuoi ottenere inferenze online, devi eseguire il passaggio aggiuntivo di
deployment del modello
in un endpoint Vertex AI.
In questo modo, gli artefatti del modello vengono associati alle risorse fisiche per un servizio a bassa latenza e viene creata una risorsa DeployedModel.
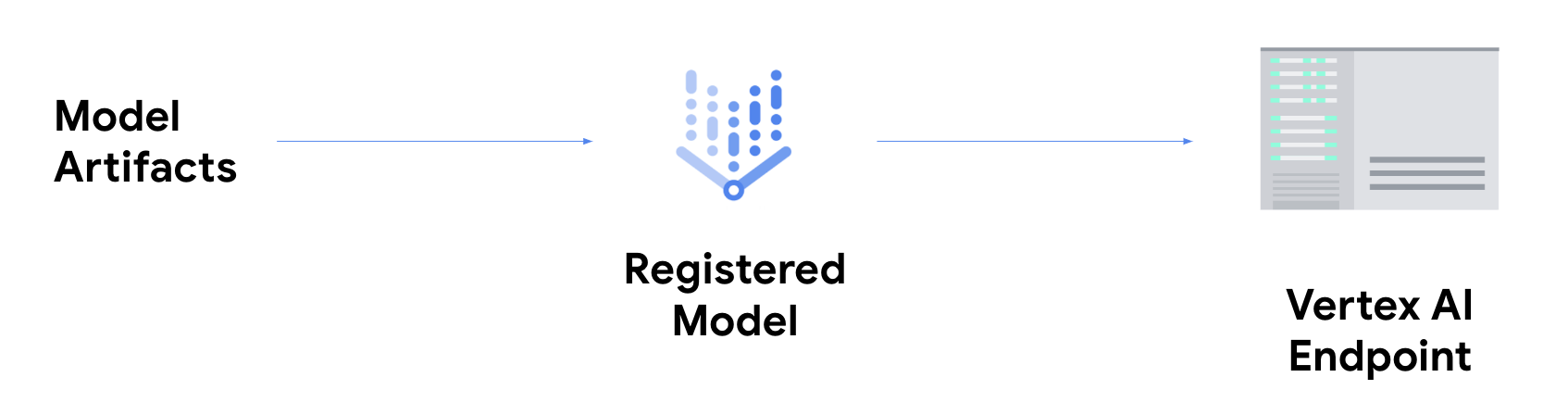
Una volta eseguito il deployment del modello in un endpoint, questo accetta richieste come qualsiasi altro endpoint REST, il che significa che puoi chiamarlo da una funzione Cloud Run, un chatbot, un'app web e così via. Tieni presente che puoi eseguire il deployment di più modelli in un singolo endpoint, suddividendo il traffico tra di loro. Questa funzionalità è utile, ad esempio, se vuoi implementare una nuova versione del modello, ma non vuoi indirizzare immediatamente tutto il traffico al nuovo modello. Puoi anche eseguire il deployment dello stesso modello in più endpoint.
Risorse per ottenere inferenze da modelli personalizzati su Vertex AI
Per scoprire di più sull'hosting e sulla pubblicazione di modelli su Vertex AI, consulta le seguenti risorse o il repository GitHub di esempi di Vertex AI.
- Video su come ottenere le previsioni
- Addestra e pubblica un modello TensorFlow utilizzando un container predefinito
- Serving di modelli di immagini PyTorch con container predefiniti su Vertex AI
- Servire un modello Stable Diffusion utilizzando un container predefinito
- Routine di inferenza personalizzate con Sklearn