Vertex AI의 Ray 클러스터는 자동 확장과 수동 확장이라는 두 가지 확장 옵션을 제공합니다. 자동 확장을 사용하면 클러스터가 Ray 작업 및 행위에 필요한 리소스를 기반으로 워커 노드 수를 자동으로 조정할 수 있습니다. 워크로드가 많고 필요한 리소스가 확실하지 않은 경우 자동 확장이 권장됩니다. 수동 확장을 사용하면 노드를 더 세부적으로 제어할 수 있습니다.
자동 확장은 워크로드 비용을 줄일 수 있지만 노드 실행 오버헤드를 추가하며 구성하기가 까다로울 수 있습니다. Ray를 처음 사용하는 경우 자동 확장 처리가 아닌 클러스터로 시작하고 수동 확장 기능을 사용하세요.
자동 확장
작업자 풀의 최소 복제본 수 (min_replica_count) 및 최대 복제본 수 (max_replica_count)를 지정하여 Ray 클러스터의 자동 확장 기능을 사용 설정합니다.
다음에 유의하세요.
- 모든 작업자 풀의 자동 확장 사양을 구성합니다.
- 커스텀 업스케일링 및 다운스케일링 속도는 지원되지 않습니다. 기본값은 Ray 문서의 업스케일링 및 다운스케일링 속도를 참조하세요.
작업자 풀 자동 확장 사양 설정
Google Cloud 콘솔 또는 Vertex AI SDK for Python을 사용하여 Ray 클러스터의 자동 확장 기능을 사용 설정합니다.
Vertex AI SDK의 Ray
from google.cloud import aiplatform import vertex_ray from vertex_ray import AutoscalingSpec autoscaling_spec = AutoscalingSpec( min_replica_count=1, max_replica_count=3, ) head_node_type = Resources( machine_type="n1-standard-16", node_count=1, ) worker_node_types = [Resources( machine_type="n1-standard-16", accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, autoscaling_spec=autoscaling_spec, )] # Create the Ray cluster on Vertex AI CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, worker_node_types=worker_node_types, ... )
콘솔
OSS Ray 권장사항에 따라 Ray 헤드 노드에서 논리적 CPU 수를 0으로 설정하면 헤드 노드에서 워크로드가 강제로 실행되지 않습니다.
Google Cloud 콘솔에서 Vertex AI 기반 Ray 페이지로 이동합니다.
클러스터 만들기를 클릭하여 클러스터 만들기 패널을 엽니다.
클러스터 만들기 패널의 각 단계에서 기본 클러스터 정보를 검토하거나 바꿉니다. 계속을 클릭하여 각 단계를 완료합니다.
- 이름 및 리전에서 이름을 지정하고 클러스터의 위치를 선택합니다.
컴퓨팅 설정에서 머신 유형, 가속기 유형 및 수, 디스크 유형 및 크기, 복제본 수를 포함하여 헤드 노드에서 Ray 클러스터의 구성을 지정합니다. 원하는 경우 커스텀 이미지 URI를 추가하여 커스텀 컨테이너 이미지를 지정하여 기본 컨테이너 이미지에서 제공하지 않는 Python 종속 항목을 추가할 수 있습니다. 커스텀 이미지를 참고하세요.
고급 옵션에서 다음 작업을 할 수 있습니다.
- 자체 암호화 키를 지정합니다.
- 커스텀 서비스 계정을 지정합니다.
- 학습 중에 워크로드의 리소스 통계를 모니터링할 필요가 없는 경우 측정항목 수집을 사용 중지합니다.
자동 확장 작업자 풀이 있는 클러스터를 만들려면 작업자 풀의 최대 복제본 수를 지정합니다.
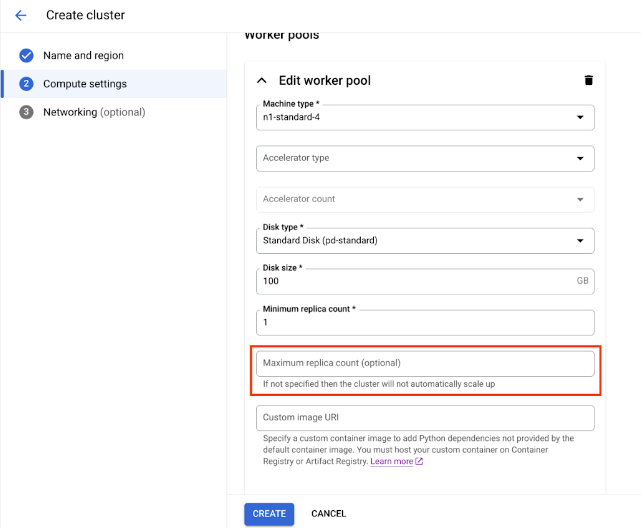
만들기를 클릭합니다.
수동 확장
Vertex AI 기반 Ray 클러스터에서 워크로드가 급증하거나 감소하면 수요에 맞게 복제본 수를 수동으로 확장합니다. 예를 들어 용량이 초과된 경우 작업자 풀을 축소하여 비용을 절감합니다.
VPC 피어링의 제한사항
클러스터를 확장할 때 기존 작업자 풀의 복제본 수만 변경할 수 있습니다. 예를 들어 클러스터에서 작업자 풀을 추가 또는 삭제하거나 작업자 풀의 머신 유형을 변경할 수 없습니다. 또한 작업자 풀에 대한 복제본 수는 1보다 작을 수 없습니다.
VPC 피어링 연결을 사용하여 클러스터에 연결하는 경우 최대 노드 수에 제한이 있습니다. 최대 노드 수는 클러스터를 만들 때 클러스터에 있던 노드 수에 따라 다릅니다. 자세한 내용은 최대 노드 수 계산을 참고하세요. 이 최대 수에는 작업자 풀뿐만 아니라 헤드 노드도 포함됩니다. 기본값 네트워크 구성을 사용하는 경우 노드 수는 클러스터 만들기 문서에 설명된 상한값을 초과할 수 없습니다.
서브넷 할당 권장사항
비공개 서비스 액세스 (PSA)를 사용하여 Vertex AI에 Ray를 배포할 때는 클러스터가 확장될 수 있는 최대 노드 수를 수용할 수 있도록 할당된 IP 주소 범위가 충분히 크고 연속적인지 확인하는 것이 중요합니다. PSA 연결에 예약된 IP 범위가 너무 작거나 조각화되면 IP 소진이 발생하여 배포가 실패할 수 있습니다.
또는 IP 소비를 /28 서브넷으로 줄이는 Private Service Connect 인터페이스를 사용하여 Vertex AI에 Ray를 배포하는 것이 좋습니다.
비공개 서비스 액세스 모니터링
네트워크 분석기를 사용하는 것이 좋습니다. 네트워크 분석기는 Google Cloud의 Network Intelligence Center 내에 있는 진단 도구로, Virtual Private Cloud (VPC) 네트워크 구성을 자동으로 모니터링하여 잘못된 구성과 최적화되지 않은 설정을 감지합니다. 네트워크 분석기는 지속적으로 작동하며, 서비스 가용성에 영향을 미치기 전에 네트워크 문제를 파악, 진단, 해결할 수 있도록 테스트를 적극적으로 실행하고 유용한 정보를 생성합니다.
네트워크 분석기는 Private Service Access (PSA)에 사용되는 서브넷을 모니터링할 수 있으며 관련 특정 통계를 제공합니다. 이는 PSA를 사용하는 Cloud SQL, Memorystore, Vertex AI와 같은 서비스를 관리하는 데 중요한 기능입니다.
네트워크 분석기가 PSA 서브넷을 모니터링하는 기본 방법은 할당된 범위에 대한 IP 주소 사용률 통계를 제공하는 것입니다.
PSA 범위 사용률: 네트워크 분석기는 PSA에 할당한 전용 CIDR 블록 내의 IP 주소 할당 비율을 적극적으로 추적합니다. 관리형 서비스 (예: Vertex AI)를 만들면 Google에서 할당된 블록에서 IP 범위를 가져와 서비스 프로듀서 VPC와 서브넷을 만들기 때문에 이는 중요합니다.
사전 대응 알림: PSA 할당 범위의 IP 주소 사용률이 특정 기준점 (예: 75%)을 초과하면 네트워크 분석기에서 경고 통계를 생성합니다. 이렇게 하면 잠재적인 용량 문제가 사전에 알림으로 표시되므로 새 서비스 리소스에 사용할 수 있는 주소가 부족해지기 전에 할당된 IP 범위를 확장할 수 있습니다.
비공개 서비스 액세스 서브넷 업데이트
Vertex AI의 Ray 배포의 경우 PSA 연결에 /16 또는 /17 CIDR 블록을 할당하는 것이 좋습니다. 이를 통해 상당한 확장성을 지원할 수 있는 충분히 큰 연속 IP 주소 블록이 제공되어 각각 최대 65,536개 또는 32,768개의 고유 IP 주소를 수용할 수 있습니다. 이렇게 하면 대규모 Ray 클러스터에서도 IP 소진을 방지할 수 있습니다.
할당된 IP 주소 공간이 소진된 경우 Google Cloud 는 다음 오류를 반환합니다.
서브네트워크를 만들 수 없습니다. 할당된 IP 범위에서 여유 블록을 찾을 수 없습니다.
현재 서브넷 범위를 확장하거나 향후 성장을 수용할 수 있는 범위를 할당하는 것이 좋습니다.
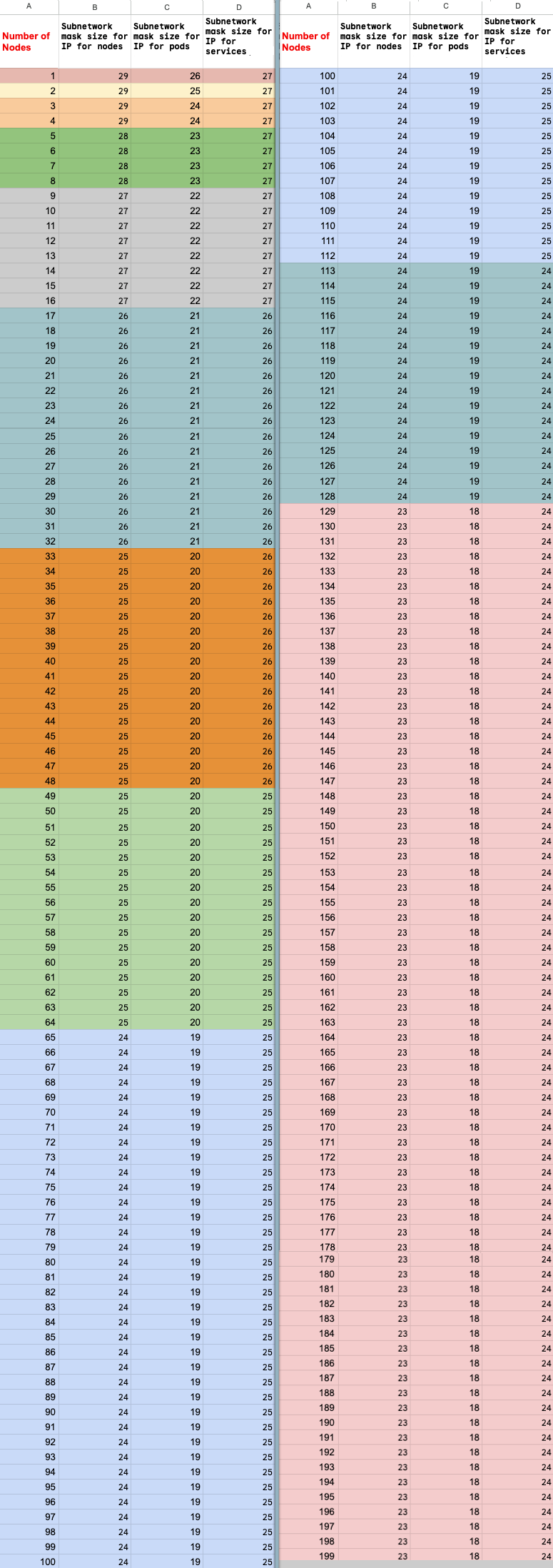
최대 노드 수 계산
비공개 서비스 액세스 (VPC 피어링)를 사용하여 노드에 연결하는 경우, f(x) = min(29, (32 -
ceiling(log2(x)))라고 가정하고 다음 수식을 사용하여 최대 노드 수 (M)를 초과하지 않는지 확인하세요.
f(2 * M) = f(2 * N)f(64 * M) = f(64 * N)f(max(32, 16 + M)) = f(max(32, 16 + N))
수직 확장할 수 있는 Vertex AI 기반 Ray 클러스터의 최대 총 노드 수(M)는 설정한 초기 총 노드 수(N)에 따라 다릅니다. Vertex AI 기반 Ray 클러스터를 만든 후 총 노드 수를 P에서 M(포함) 사이의 값으로 확장할 수 있습니다. 여기서 P는 클러스터의 풀 수입니다.
클러스터의 초기 총 노드 수와 수직 확장 타겟 수는 동일한 색상 블록에 있어야 합니다.
복제본 수 업데이트
Google Cloud 콘솔 또는 Vertex AI SDK for Python을 사용하여 작업자 풀의 복제본 수를 업데이트합니다. 클러스터에 여러 작업자 풀이 포함된 경우 단일 요청에서 각 복제본 수를 개별적으로 변경할 수 있습니다.
Vertex AI SDK의 Ray
import vertexai import vertex_ray vertexai.init() cluster = vertex_ray.get_ray_cluster("CLUSTER_NAME") # Get the resource name. cluster_resource_name = cluster.cluster_resource_name # Create the new worker pools new_worker_node_types = [] for worker_node_type in cluster.worker_node_types: worker_node_type.node_count = REPLICA_COUNT # new worker pool size new_worker_node_types.append(worker_node_type) # Make update call updated_cluster_resource_name = vertex_ray.update_ray_cluster( cluster_resource_name=cluster_resource_name, worker_node_types=new_worker_node_types, )
콘솔
Google Cloud 콘솔에서 Vertex AI 기반 Ray 페이지로 이동합니다.
클러스터 목록에서 수정할 클러스터를 클릭합니다.
클러스터 세부정보 페이지에서 클러스터 수정을 클릭합니다.
클러스터 수정 창에서 업데이트할 작업자 풀을 선택한 다음 복제본 수를 수정합니다.
업데이트를 클릭합니다.
클러스터가 업데이트될 때까지 몇 분 정도 기다립니다. 업데이트가 완료되면 클러스터 세부정보 페이지에서 업데이트된 복제본 수를 확인할 수 있습니다.
만들기를 클릭합니다.