本页面介绍如何将 Vertex AI Model Monitoring 与 Vertex Explainable AI 搭配使用来检测分类和数值输入特征的特征归因偏差和偏移。
基于特征归因的监控概览
特征归因指出了模型中每个特征对每个给定实例的预测结果的影响程度。请求预测时,您会获得适合您模型的预测值。请求说明时,您会获得预测结果以及特征归因信息。
归因得分与特征对模型预测结果的贡献成正比。它们通常是有符号的,表明某个特征是否有助于提高或降低预测。所有特征的归因必须添加到模型的预测分数中。
通过监控特征归因,模型监控功能会跟踪特征归因相对于模型预测结果随时间的变化情况。关键特征的归因分数发生变化通常表明该特征发生了某种形式的变化,并且可能会影响模型预测结果的准确率。
如需了解特征归因得分的计算方式,请参阅特征归因方法。
特征归因训练-应用偏差和预测偏移
在您为启用了 Vertex Explainable AI 的模型创建监控作业时,Model Monitoring 会监控特征分布和特征归因的偏差或偏移。如需了解特征分布偏差和偏移,请参阅 Vertex AI Model Monitoring 简介。
对于功能归因:
如果生产环境中的特征归因分数与原始训练数据中的特征归因分数不同,则会发生训练-应用偏差。
如果生产环境中的特征归因分数随时间发生显著变化,则会发生预测偏移。
如果您为模型提供原始训练数据集,则可以启用偏差检测;否则,您应启用偏移检测。您还可以同时启用偏差和偏移检测。
前提条件
如需将模型监控与 Vertex Explainable AI 搭配使用,请完成以下操作:
如果您要启用偏差检测,请将训练数据或训练数据集的批量说明作业的输出上传到 Cloud Storage 或 BigQuery。获取数据的 URI 链接。对于偏移检测,不需要训练数据或说明基准。
在 Vertex AI 中准备好可用的模型,可以是表格 AutoML 或导入的表格自定义训练类型:
AutoML 表格模型会自动配置 Vertex Explainable AI,因此您可以直接跳至启用偏差或偏移检测。请注意,仅支持分类和回归模型。
在创建、导入或部署模型时,必须针对 Vertex Explainable AI 配置导入的自定义训练模型。
在创建、导入或部署模型时配置模型以使用 Vertex Explainable AI。必须为模型填充
ExplanationSpec.ExplanationParameters字段。可选:对于自定义训练模型,请将模型的分析实例架构上传到 Cloud Storage。Model Monitoring 要求架构开始监控过程并计算偏差检测的基准分布。如果您在作业创建期间未提供架构,则作业会保持待处理状态,直到 Model Monitoring 可以自动解析模型收到的前 1,000 个预测请求中的架构。
启用偏差或偏移检测
如需设置偏差检测或偏移检测,请创建模型部署监控作业:
控制台
如需使用Google Cloud 控制台创建模型部署监控作业,请创建端点:
在 Google Cloud 控制台中,前往 Vertex AI 端点页面。
点击创建端点。
在新建端点窗格中,为您的端点命名并设置区域。
点击继续。
在模型名称字段中,选择导入的自定义训练或表格 AutoML 模型。
在版本字段中,选择模型的版本。
点击继续。
在模型监控窗格中,确保为此端点启用模型监控功能处于开启状态。您配置的任何监控设置都会应用于部署到端点的所有模型。
输入监控作业显示名称。
输入监控时长。
在通知电子邮件地址部分,输入一个或多个以英文逗号分隔的电子邮件地址,以便在模型超出提醒阈值时接收提醒。
(可选)在通知渠道部分,选择 Cloud Monitoring 渠道,以便在模型超出提醒阈值时接收提醒。您可以选择现有的 Cloud Monitoring 渠道,也可以通过点击管理通知渠道来创建一个新的 Cloud Monitoring 渠道。控制台支持 PagerDuty、Slack 和 Pub/Sub 通知渠道。
输入采样率。
可选:输入预测输入架构和分析输入架构。
点击继续。此时系统会打开监控目标窗格,其中包含偏差或偏移检测选项:
偏差检测
- 选择训练-应用偏差检测。
- 在训练数据源下,提供训练数据源。
- 在目标列下,输入要训练模型以进行预测的训练数据中的列名称。此字段已从监控分析中排除。
- 可选:在提醒阈值下,指定触发提醒的阈值。如需了解如何设置阈值的格式,请将鼠标指针放在 帮助图标上。
- 点击创建。
偏移检测
- 选择预测偏移检测。
- 可选:在提醒阈值下,指定触发提醒的阈值。如需了解如何设置阈值的格式,请将鼠标指针放在 帮助图标上。
- 点击创建。
gcloud
如需使用 gcloud CLI 创建模型部署监控作业,请先将模型部署到端点。
监控作业配置适用于某个端点下所有已部署的模型。
运行 gcloud ai model-monitoring-jobs create 命令:
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ --feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \ --prediction-sampling-rate=SAMPLING_RATE \ --monitoring-frequency=MONITORING_FREQUENCY \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
其中:
PROJECT_ID 是您的 Google Cloud 项目的 ID。 例如
my-project。REGION 是监控作业的位置。 例如
us-central1。MONITORING_JOB_NAME 是监控作业的名称。 例如
my-job。EMAIL_ADDRESS 是您要接收模型监控提醒的电子邮件地址。 例如
example@example.com。ENDPOINT_ID 是在其下部署模型的端点的 ID。例如
1234567890987654321。可选:FEATURE_1=THRESHOLD_1 是您要监控的每个特征的提醒阈值。例如,如果您指定
Age=0.4,则当Age特征的输入分布和基准分布之间的 [统计距离][stat-distance] 超过 0.4 时,模型监控会记录提醒。可选:SAMPLING_RATE 是您要记录的传入预测请求的比例。例如
0.5。如果未指定,则模型监控会记录所有预测请求。可选:MONITORING_FREQUENCY 是您希望监控作业在最近记录的输入上运行的频率。最小粒度为 1 小时。默认值为 24 小时。例如
2。(只有偏差检测才需要)TARGET_FIELD 是模型正在预测的字段。此字段已从监控分析中排除。例如
housing-price。(只有偏差检测才需要)BIGQUERY_URI 是存储在 BigQuery 中的训练数据集的链接,格式如下:
bq://\PROJECT.\DATASET.\TABLE
例如
bq://\my-project.\housing-data.\san-francisco。您可以将
bigquery-uri标志替换为训练数据集的备用链接:对于存储在 Cloud Storage 存储桶中的 CSV 文件,请使用
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME。对于存储在 Cloud Storage 存储桶中的 TFRecord 文件,请使用
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME。对于 [表格 AutoML 代管式数据集][dataset-id],请使用
--dataset=DATASET_ID。
Python SDK
如需了解完整的端到端 Model Monitoring API 工作流,请参阅示例笔记本。
REST API
如果您尚未将模型部署到端点,请执行此操作。
获取端点信息,以检索已部署模型的 ID。请注意 DEPLOYED_MODEL_ID,这是响应中的
deployedModels.id值。创建模型监控作业请求。以下说明展示了如何使用归因创建偏移检测的基本监控作业。对于偏差检测,请将
explanationBaseline对象添加到请求 JSON 正文中的explanationConfig字段,并提供以下内容之一:训练数据集的批量说明作业的输出。
服务在其上运行
BatchExplain作业以生成基准的TrainingDataset。
如需了解详情,请参阅监控作业参考文档。
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:您的 Google Cloud 项目的 ID。例如
my-project。 - LOCATION:监控作业的位置。例如
us-central1。 - MONITORING_JOB_NAME:监控作业的名称。例如
my-job。 - PROJECT_NUMBER:您的 Google Cloud 项目的编号。例如
1234567890。 - ENDPOINT_ID:部署了模型的端点的 ID。例如
1234567890。 - DEPLOYED_MODEL_ID:已部署模型的 ID。
- FEATURE:VALUE:您要监控的每个特征的提醒阈值。例如
"housing-latitude": {"value": 0.4}。 当输入特征分布与其对应的基准之间的统计距离超过指定的阈值时,系统会记录提醒。默认情况下,每个分类和数值特征都会受监控,并且阈值为 0.3。 - EMAIL_ADDRESS:您要接收模型监控提醒的电子邮件地址。例如
example@example.com。 - NOTIFICATION_CHANNELS:您要在其中接收模型监控提醒的 Cloud Monitoring 通知渠道列表。使用通知渠道的资源名称,您可以通过列出项目中的通知渠道进行检索。例如
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568"。
请求 JSON 正文:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, "explanationConfig": { "enableFeatureAttributes": true } } }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] } }如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }
创建监控作业后,模型监控功能会将传入的预测请求记录在系统生成的名为 PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict 的 BigQuery 表中。如果启用了请求-响应日志记录,则模型监控功能会将传入请求记录到用于请求-响应日志记录的同一 BigQuery 表中。
请参阅使用模型监控功能,了解如何执行以下可选任务:
更新模型监控作业。
为模型监控作业配置提醒
为异常值配置提醒。
分析特征归因偏差和偏移数据
您可以使用 Google Cloud 控制台直观呈现每个受监控特征的特征归因,并了解哪些更改导致偏差或偏移。如需了解如何分析特征分布数据,请参阅分析偏差和偏移数据。
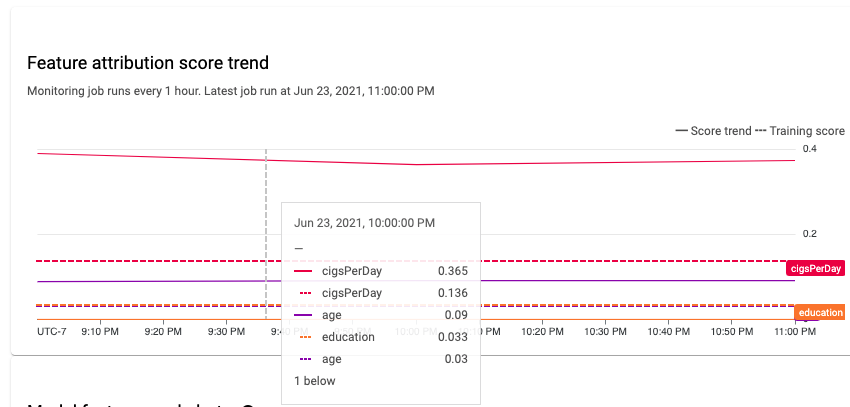
在稳定的机器学习系统中,特征的相对重要性通常在一段时间内保持相对稳定。如果某个重要特征的重要性下降,则可能表示该特征发生了一些变化。特征重要性偏移或偏差的常见原因包括:
- 数据源更改。
- 数据架构和日志记录更改。
- 最终用户组合和/或行为更改(例如,由于季节性变化或离群值事件而发生变化)。
- 通过另一个机器学习模型生成的特征的上游更改。以下是一些示例:
- 导致覆盖率增加或减少的模型更新(整体或单个分类值)。
- 模型性能的变化(改变特征的含义)。
- 更新到该数据流水线,这可能会降低总体覆盖率。
此外,在分析特征归因偏差和偏移数据时,请考虑以下事项:
跟踪最重要的特征。特征归因的大幅变化表示特征对预测的贡献发生了变化。由于预测分数等于特征贡献的总和,因此最重要的特征的重大归因偏移通常表示模型预测出现重大偏移。
监控所有特征表示法。无论底层特征类型如何,特征归因始终是数值。由于它们的可加性,多维特征(例如嵌入)的归因可以通过添加跨维度的归因来减少为单个数值。这样,您就可以对所有特征类型使用标准的单变量偏移检测方法。
说明特征交互。特征归因说明了特征对预测的贡献,无论是单独使用还是通过与其他特征的交互。如果特征与其他特征的交互发生变化,则特征的归因分布也会发生变化,即使特征的边缘分布保持不变。
监控特征组。由于归因是可加的,因此您可以将归因添加到相关特征,以获取特征组的归因。例如,在信用贷款模型中,可以将贷款类型相关的所有特征(例如,“grade”“sub_grade”“purpose”)的归因进行组合以获取单个贷款归因。随后可以跟踪该组级层归因,以监控特征组的更改。
后续步骤
- 按照 API 文档使用模型监控。
- 按照 gcloud CLI 文档使用模型监控。
- 在 Colab 中试用示例笔记本或在 GitHub 上查看示例笔记本。
- 了解模型监控如何计算训练-应用偏差和预测偏移。