이 페이지에서는 Vertex Explainable AI와 함께 Vertex AI Model Monitoring을 사용하여 범주 및 숫자 입력 특성의 특성 기여에 대한 편향 및 드리프트를 감지하는 방법을 설명합니다.
특성 기여 기반 모니터링 개요
특성 기여 분석은 모델의 각 특성이 각 인스턴스의 예측에 기여한 정도를 나타냅니다. 예측을 요청하면 예측 값이 모델에 적절하게 표시됩니다. 설명을 요청하면 특성 기여 분석 정보와 함께 예측이 표시됩니다.
기여 분석 점수는 모델의 예측에 대한 특성의 기여도에 비례합니다. 이러한 점수는 일반적으로 특성이 예측을 푸시하는 데 도움이 되는지 여부가 표시되어 있습니다. 모든 특성에 대한 기여 분석은 모델의 예측 점수를 합산해야 합니다.
특성 기여 분석을 모니터링하면 Model Monitoring이 시간 경과에 따른 모델의 예측에 대한 특성 기여 분석의 변화를 추적합니다. 주요 특성의 기여 분석 점수 변화가 발생하면 특성이 모델 예측의 정확성에 영향을 미칠 수 있는 방식으로 변경되었다는 신호입니다.
특징 기여 분석 점수 계산 방법에 대한 자세한 내용은 특성 기여 분석 방법을 참조하세요.
특성 기여 분석 학습-서빙 편향 및 예측 드리프트
Vertex Explainable AI가 사용 설정된 모델에 대한 모니터링 작업을 만들면 모델 모니터링에서 특성 분포와 특성 기여 분석 모두의 편향 또는 드리프트를 모니터링합니다. 특성 분포 편향 및 드리프트에 대한 자세한 내용은 Vertex AI Model Monitoring 소개를 참조하세요.
특성 기여 분석의 경우:
학습-서빙 편향은 프로덕션의 특성 기여 분석 점수가 원본 학습 데이터의 특성 기여 분석 점수와 다른 경우 발생합니다.
예측 드리프트는 프로덕션 환경에서 특성의 기여 분석 점수가 시간에 따라 크게 달라지는 경우에 발생합니다.
모델의 원래 학습 데이터 세트를 제공하면 편향 감지를 사용 설정할 수 있습니다. 이를 제공하지 않을 경우 드리프트 감지를 사용 설정해야 합니다. 또한 편향 및 드리프트 감지 모두 사용 설정할 수 있습니다.
기본 요건
Vertex Explainable AI에서 Model Monitoring을 사용하려면 다음을 완료하세요.
편향 감지를 사용 설정하는 경우 학습 데이터 또는 학습 데이터 세트에 대한 일괄 설명 작업의 출력을 Cloud Storage 또는 BigQuery에 업로드합니다. 데이터에 대한 URI 링크를 가져옵니다. 드리프트 감지의 경우에는 학습 데이터 또는 설명 기준이 필요하지 않습니다.
Vertex AI에 테이블 형식 AutoML 또는 가져온 테이블 형식 커스텀 학습 유형의 사용할 수 있는 모델이 있어야 합니다.
AutoML 테이블 형식 모델에는 Vertex Explainable AI가 자동으로 구성되어 있으므로, 편향 또는 드리프트 감지 사용 설정을 건너뛸 수 있습니다. 분류 및 회귀 모델만 지원됩니다.
모델을 만들거나, 가져오거나, 배포할 때, 가져온 커스텀 학습 모델을 Vertex Explainable AI에 맞게 구성해야 합니다.
모델을 생성, 가져오기, 배포할 때 Vertex Explainable AI를 사용하도록 모델을 구성하세요. 모델의
ExplanationSpec.ExplanationParameters필드가 채워져야 합니다.(선택사항) 커스텀 학습 모델의 경우 모델의 분석 인스턴스 스키마를 Cloud Storage에 업로드합니다. Model Monitoring에서 모니터링 프로세스를 시작하고 편향 감지의 기준 분포를 계산하려면 스키마가 필요합니다. 작업 생성 중 스키마를 제공하지 않으면 Model Monitoring에서 모델이 수신하는 처음 1,000개의 예측 요청에서 스키마를 자동으로 파싱할 수 있을 때까지 작업이 대기 중 상태로 유지됩니다.
편향 또는 드리프트 감지 사용 설정
편향 감지 또는 드리프트 감지를 설정하려면 모델 배포 모니터링 작업을 만듭니다.
Console
Google Cloud 콘솔을 사용하여 모델 배포 모니터링 작업을 만들려면 엔드포인트를 만듭니다.
Google Cloud 콘솔에서 Vertex AI 엔드포인트 페이지로 이동합니다.
엔드포인트 만들기를 클릭합니다.
새 엔드포인트 창에서 엔드포인트의 이름을 지정하고 리전을 설정합니다.
계속을 클릭합니다.
모델 이름 필드에서 가져온 커스텀 학습 또는 테이블 형식 AutoML 모델을 선택합니다.
버전 필드에서 모델 버전을 선택합니다.
계속을 클릭합니다.
Model Monitoring 창에서 이 엔드포인트에 Model Monitoring 사용 설정이 켜져 있는지 확인합니다. 구성한 모니터링 설정이 엔드포인트에 배포된 모든 모델에 적용됩니다.
모니터링 작업 표시 이름을 입력합니다.
모니터링 기간 길이를 입력합니다.
알림 이메일의 경우 모델이 알림 기준을 초과하면 알림을 받을 하나 이상의 이메일 주소를 쉼표로 구분하여 입력합니다.
(선택사항) 알림 채널에서 모델이 알림 기준을 초과할 때 알림을 수신할 Cloud Monitoring 채널을 선택합니다. 기존 Cloud Monitoring 채널을 선택하거나 알림 채널 관리를 클릭하여 새 채널을 만들 수 있습니다. 콘솔에서는 PagerDuty, Slack, Pub/Sub 알림 채널이 지원됩니다.
샘플링 레이트를 입력합니다.
(선택사항) 예측 입력 스키마 및 분석 입력 스키마를 입력합니다.
계속을 클릭합니다. 편향 또는 드리프트 감지 옵션이 있는 모니터링 목표 창이 열립니다.
편향 감지
- 학습-서빙 편향 감지를 선택하세요.
- 학습 데이터 소스에서 학습 데이터 소스를 제공합니다.
- 타겟 열에서 모델이 예측하도록 학습시킨 학습 데이터의 열 이름을 입력합니다. 이 필드는 모니터링 분석에서 제외됩니다.
- (선택사항) 알림 기준 아래에서 알림을 트리거할 기준점을 지정합니다. 기준점의 형식을 지정하는 방법에 대한 자세한 내용은 도움말 아이콘 위에 마우스 포인터를 올려놓으세요.
- 만들기를 클릭합니다.
드리프트 감지
- 예측 드리프트 감지를 선택하세요.
- (선택사항) 알림 기준 아래에서 알림을 트리거할 기준점을 지정합니다. 기준점의 형식을 지정하는 방법에 대한 자세한 내용은 도움말 아이콘 위에 마우스 포인터를 올려놓으세요.
- 만들기를 클릭합니다.
gcloud
gcloud CLI를 사용하여 모델 배포 모니터링 작업을 만들려면 먼저 모델을 엔드포인트에 배포합니다.
모니터링 작업 구성이 엔드포인트의 배포된 모든 모델에 적용됩니다.
gcloud ai model-monitoring-jobs create 명령어를 실행합니다.
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ --feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \ --prediction-sampling-rate=SAMPLING_RATE \ --monitoring-frequency=MONITORING_FREQUENCY \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
각 항목의 의미는 다음과 같습니다.
PROJECT_ID는 Google Cloud 프로젝트 ID입니다. 예를 들면
my-project입니다.REGION은 모니터링 작업 위치입니다. 예를 들면
us-central1입니다.MONITORING_JOB_NAME은 모니터링 작업 이름입니다. 예를 들면
my-job입니다.EMAIL_ADDRESS는 Model Monitoring에서 알림을 받을 이메일 주소입니다. 예를 들면
example@example.com입니다.ENDPOINT_ID는 모델이 배포되는 엔드포인트의 ID입니다. 예를 들면
1234567890987654321입니다.(선택사항) FEATURE_1=THRESHOLD_1은 모니터링할 각 특성의 알림 기준점입니다. 예를 들어
Age=0.4을 지정하면 모델 모니터링은 0.4를 초과하는Age특성의 입력 및 기준 분포 간의 [통계 거리][stat-distance] 알림을 로깅합니다.(선택사항) SAMPLING_RATE는 로깅할 수신 예측 요청의 비율입니다. 예를 들면
0.5입니다. 지정하지 않으면 Model Monitoring이 모든 예측 요청을 로깅합니다.(선택사항) MONITORING_FREQUENCY는 최근에 로깅된 입력에서 모니터링 작업을 실행할 빈도입니다. 최소 단위는 1시간입니다. 기본값은 24시간입니다. 예를 들면
2입니다.(편향 감지에만 필수) TARGET_FIELD는 모델에서 예측하는 필드입니다. 이 필드는 모니터링 분석에서 제외됩니다. 예를 들면
housing-price입니다.(편향 감지에만 필수) BIGQUERY_URI는 다음 형식을 사용하여 BigQuery에 저장된 학습 데이터 세트의 링크입니다.
bq://\PROJECT.\DATASET.\TABLE
예를 들면
bq://\my-project.\housing-data.\san-francisco입니다.bigquery-uri플래그를 학습 데이터 세트의 대체 링크로 바꾸면 됩니다.Cloud Storage 버킷에 저장된 CSV 파일의 경우
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME을 사용합니다.Cloud Storage 버킷에 저장된 TFRecord 파일의 경우
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME을 사용합니다.[테이블 형식 AutoML 관리형 데이터 세트][dataset-id]에는
--dataset=DATASET_ID를 사용합니다.
Python SDK
완전한 엔드 투 엔드 Model Monitoring API 워크플로에 대한 자세한 내용은 예시 노트북을 참조하세요.
REST API
아직 엔드포인트에 모델을 배포하지 않았다면 배포합니다.
엔드포인트 정보를 가져와 모델의 배포된 모델 ID를 검색합니다. 응답의
deployedModels.id값인 DEPLOYED_MODEL_ID를 확인합니다.모델 모니터링 작업 요청을 만듭니다. 다음 안내에서는 기여 분석으로 드리프트를 감지하기 위한 기본 모니터링 작업을 만드는 방법을 보여줍니다. 편향 감지의 경우 요청 JSON 본문의
explanationConfig필드에explanationBaseline객체를 추가하고 다음 중 하나를 제공합니다.학습 데이터 세트의 일괄 설명 작업 출력입니다.
서비스가 기준 생성을 위해
BatchExplain작업을 실행하는TrainingDataset입니다.
자세한 내용은 Monitoring 작업 참조를 확인하세요.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 예를 들면
my-project입니다. - LOCATION: 모니터링 작업 위치입니다. 예를 들면
us-central1입니다. - MONITORING_JOB_NAME: 모니터링 작업 이름입니다. 예를 들면
my-job입니다. - PROJECT_NUMBER: Google Cloud 프로젝트의 번호입니다. 예를 들면
1234567890입니다. - ENDPOINT_ID: 모델이 배포된 엔드포인트의 ID입니다. 예를 들면
1234567890입니다. - DEPLOYED_MODEL_ID: 배포된 모델의 ID입니다.
- FEATURE:VALUE: 모니터링할 각 특성의 알림 기준점입니다. 예를 들면
"housing-latitude": {"value": 0.4}입니다. 입력 특성 분포와 해당 기준 간의 통계 거리가 지정된 기준점을 초과하면 알림이 로깅됩니다. 기본적으로 모든 범주형 특성 및 숫자형 특성이 모니터링되며 기준점은 0.3입니다. - EMAIL_ADDRESS: Model Monitoring에서 알림을 받을 이메일 주소입니다. 예를 들면
example@example.com입니다. - NOTIFICATION_CHANNELS: Model Monitoring에서 알림을 수신하려는 Cloud Monitoring 알림 채널 목록입니다. 프로젝트의 알림 채널 나열로 검색할 수 있는 알림 채널의 리소스 이름을 사용합니다. 예를 들면
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568"입니다.
JSON 요청 본문:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, "explanationConfig": { "enableFeatureAttributes": true } } }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] } }요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }
모니터링 작업이 생성된 후 Model Monitoring이 PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict라는 생성된 BigQuery 테이블에 수신되는 예측 요청을 로깅합니다.
요청-응답 로깅이 사용 설정된 경우 Model Monitoring이 요청-응답 로깅에 사용된 동일한 BigQuery 테이블에 수신되는 요청을 로깅합니다.
다음과 같은 선택적 작업을 수행하는 방법은 모델 모니터링 사용을 참조하세요.
Model Monitoring 작업 업데이트
Model Monitoring 작업 알림 구성
이상에 대한 알림을 구성합니다.
특성 기여 분석 편향 및 드리프트 데이터 분석
Google Cloud 콘솔을 사용하여 각 모니터링된 특성의 특성 기여 분석을 시각화하고 편향이나 드리프트를 초래하는 변경사항을 확인할 수 있습니다. 특성 배포 데이터 분석에 대한 자세한 내용은 편향 및 드리프트 데이터 분석을 참조하세요.
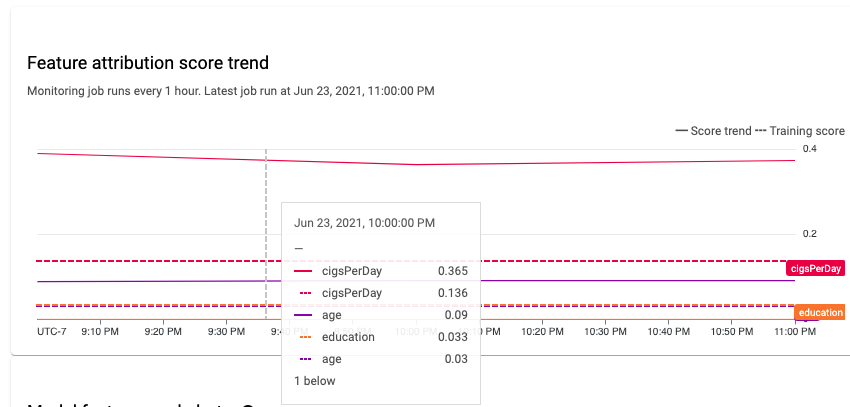
안정적인 머신러닝 시스템에서 특성의 상대적 중요성은 일반적으로 시간이 지나면서 안정적으로 유지됩니다. 중요한 특성의 중요도가 떨어지면 해당 특성의 무언가가 변경되었다는 신호일 수 있습니다. 특성 중요도 드리프트 또는 편향의 일반적인 원인은 다음과 같습니다.
- 데이터 소스 변경사항
- 데이터 스키마 및 로깅 변경사항
- 최종 사용자 조합 또는 행동의 변화(예를 들어 계절적 변화나 이상점 이벤트 때문임)
- 다른 머신러닝 모델로 생성된 특성의 업스트림 변경
다음은 몇 가지 예시입니다.
- 적용 범위(전체 또는 개별 분류 값) 증가 또는 감소를 초래하는 모델 업데이트
- 모델의 성능 변화(특성의 의미 변경)
- 전체 적용 범위가 감소할 수 있는 데이터 파이프라인 업데이트
또한 특성 기여 분석 편향 및 드리프트 데이터를 분석할 때 다음 사항을 고려하세요.
가장 중요한 특성을 추적할 수 있습니다. 특성의 기여 분석이 크게 변경되면 예측에 대한 특성의 기여도가 변경되었다는 의미입니다. 예측 점수는 특성 기여도의 합과 동일하므로 일반적으로 가장 중요한 특성의 큰 기여 분석 드리프트는 모델 예측에서의 큰 드리프트를 나타냅니다.
모든 특성 표현을 모니터링합니다. 특성 기여 분석은 기본 특성 유형에 관계없이 항상 숫자로 표현됩니다. 추가되는 특성으로 인해 차원 간 기여 분석을 더하여 임베딩과 같은 다차원 특성에 대한 기여 분석을 단일 숫자 값으로 줄일 수 있습니다. 이렇게 하면 모든 특성 유형에 표준 일변량 드리프트 감지 방법을 사용할 수 있습니다.
특성 상호작용을 설명합니다. 특성에 대한 기여 분석은 개별적으로 그리고 다른 특성과의 상호 작용을 통해 예측에 대한 기여를 설명합니다. 특성과 다른 특성의 상호작용이 변경되면 특성의 한계 분포는 동일하게 유지되더라도 특성의 기여 분석 분포가 변경됩니다.
특성 그룹을 모니터링합니다. 기여 분석은 누적되므로 관련 특성에 기여 분석을 추가하여 특성 그룹의 기여 분석을 얻을 수 있습니다. 예를 들어 신용 대출 모델에서는 대출 유형과 관련된 모든 특성(예: '등급', '하위_등급', '목적')에 기여 분석을 결합하여 단일 대출 기여 분석을 얻을 수 있습니다. 그 다음 이 그룹 수준 기여 분석을 추적하여 특성 그룹의 변경사항을 모니터링할 수 있습니다.
다음 단계
- API 문서에 따라 Model Monitoring 작업 수행하기
- gcloud CLI 문서에 따라 Model Monitoring 작업 수행하기
- Colab에서 노트북 예시를 사용해 보거나 GitHub에서 보기
- Model Monitoring에서 학습-제공 편향 및 예측 드리프트를 계산하는 방법 알아보기