Questa pagina descrive come utilizzare Vertex AI Model Monitoring con Vertex Explainable AI per rilevare disallineamenti e deviazioni per le attribuzioni delle caratteristiche delle caratteristiche di input categoriche e numeriche.
Panoramica del monitoraggio basato sull'attribuzione delle caratteristiche
Le attribuzioni delle caratteristiche indicano in che misura ogni caratteristica del modello ha contribuito alle previsioni per ogni istanza specificata. Quando richiedi previsioni, ottieni valori previsti in base al tuo modello. Quando richiedi le spiegazioni, ricevi le previsioni insieme alle informazioni sull'attribuzione delle funzionalità.
I punteggi di attribuzione sono proporzionali al contributo della caratteristica alla previsione di un modello. In genere sono firmati, indicando se una funzionalità contribuisce ad aumentare o diminuire la previsione. Le attribuzioni in tutte le funzionalità devono sommarsi al punteggio di previsione del modello.
Monitorando le attribuzioni delle caratteristiche, Model Monitoring tiene traccia delle variazioni dei contributi di una caratteristica alle previsioni di un modello nel tempo. Una variazione del punteggio di attribuzione di una caratteristica chiave spesso indica che la caratteristica è cambiata in un modo che può influire sull'accuratezza delle previsioni del modello.
Per informazioni su come viene calcolato un punteggio di attribuzione delle caratteristiche, vedi Metodi di attribuzione delle caratteristiche.
Disallineamento tra addestramento e distribuzione dell'attribuzione delle caratteristiche e deviazione della previsione
Quando crei un job di monitoraggio per un modello con Vertex Explainable AI abilitato, Model Monitoring monitora lo sbilanciamento o la deriva sia per le distribuzioni delle caratteristiche sia per le attribuzioni delle caratteristiche. Per informazioni su disallineamento e deviazione della distribuzione delle funzionalità, consulta Introduzione a Vertex AI Model Monitoring.
Per le attribuzioni delle caratteristiche:
Il disallineamento addestramento/produzione si verifica quando il punteggio di attribuzione di una funzionalità in produzione si discosta dal punteggio di attribuzione della funzionalità nei dati di addestramento originali.
La deviazione della previsione si verifica quando il punteggio di attribuzione di una caratteristica in produzione cambia in modo significativo nel tempo.
Puoi attivare il rilevamento del disallineamento se fornisci il set di dati di addestramento originale per il modello; in caso contrario, devi attivare il rilevamento della deviazione. Puoi anche attivare il rilevamento di disallineamenti e deviazioni.
Prerequisiti
Per utilizzare Model Monitoring con Vertex Explainable AI, completa quanto segue:
Se abiliti il rilevamento della distorsione, carica i dati di addestramento o l'output di un job di spiegazione batch per il tuo set di dati di addestramento in Cloud Storage o BigQuery. Ottieni il link URI ai dati. Per il rilevamento della deriva, non sono necessari dati di addestramento o una base di riferimento per la spiegazione.
Avere un modello disponibile in Vertex AI di tipo AutoML tabellare o addestramento personalizzato tabellare importato:
Un modello tabulare AutoML ha Vertex Explainable AI configurato automaticamente, quindi puoi passare direttamente all'attivazione del rilevamento di disallineamento o deviazione. Nota che sono supportati solo i modelli di classificazione e regressione.
Un modello con addestramento personalizzato importato deve essere configurato per Vertex Explainable AI quando crei, importi o esegui il deployment del modello.
Configura il modello in modo che utilizzi Vertex Explainable AI quando lo crei, lo importi o lo esegui il deployment. Il campo
ExplanationSpec.ExplanationParametersdeve essere compilato per il modello.(Facoltativo) Per i modelli con addestramento personalizzato, carica lo schema dell'istanza di analisi per il modello su Cloud Storage. Model Monitoring richiede lo schema per iniziare la procedura di monitoraggio e calcolare la distribuzione di base per il rilevamento del disallineamento. Se non fornisci lo schema durante la creazione del job, il job rimane in stato di attesa finché Model Monitoring non è in grado di analizzare automaticamente lo schema dalle prime 1000 richieste di previsione ricevute dal modello.
Attivare il rilevamento di disallineamenti o deviazioni
Per configurare il rilevamento del disallineamento o della deviazione, crea un job di monitoraggio del deployment del modello:
Console
Per creare un job di monitoraggio del deployment del modello utilizzando la consoleGoogle Cloud , crea un endpoint:
Nella console Google Cloud , vai alla pagina Endpoint Vertex AI.
Fai clic su Crea endpoint.
Nel riquadro Nuovo endpoint, assegna un nome all'endpoint e imposta una regione.
Fai clic su Continua.
Nel campo Nome modello, seleziona un modello AutoML tabellare o di addestramento personalizzato importato.
Nel campo Versione, seleziona una versione per il modello.
Fai clic su Continua.
Nel riquadro Monitoraggio del modello, assicurati che l'opzione Abilita il monitoraggio del modello per questo endpoint sia attivata. Le impostazioni di monitoraggio che configuri si applicano a tutti i modelli di cui è stato eseguito il deployment nell'endpoint.
Inserisci un Nome visualizzato del job di monitoraggio.
Inserisci una durata della finestra di monitoraggio.
Per Email di notifica, inserisci uno o più indirizzi email separati da virgole per ricevere avvisi quando un modello supera una soglia di avviso.
(Facoltativo) Per Canali di notifica, seleziona i canali Cloud Monitoring per ricevere avvisi quando un modello supera una soglia di avviso. Puoi selezionare i canali Cloud Monitoring esistenti o crearne uno nuovo facendo clic su Gestisci canali di notifica. La console supporta i canali di notifica PagerDuty, Slack e Pub/Sub.
Inserisci una Frequenza di campionamento.
(Facoltativo) Inserisci lo schema di input della previsione e lo schema di input dell'analisi.
Fai clic su Continua. Si apre il riquadro Obiettivo monitoraggio, con le opzioni per il rilevamento di disallineamento o deviazione:
Rilevamento del disallineamento
- Seleziona Rilevamento del disallineamento addestramento/produzione.
- In Origine dati di addestramento, fornisci un'origine dati di addestramento.
- In Colonna target, inserisci il nome della colonna nei dati di addestramento che il modello è addestrato a prevedere. Questo campo è escluso dall'analisi di monitoraggio.
- (Facoltativo) In Soglie di avviso, specifica le soglie in corrispondenza delle quali attivare gli avvisi. Per informazioni su come formattare le soglie, passa il puntatore sopra l'icona della guida .
- Fai clic su Crea.
Rilevamento della deviazione
- Seleziona Rilevamento della deviazione della previsione.
- (Facoltativo) In Soglie di avviso, specifica le soglie in corrispondenza delle quali attivare gli avvisi. Per informazioni su come formattare le soglie, passa il puntatore sopra l'icona della guida .
- Fai clic su Crea.
gcloud
Per creare un job di monitoraggio del deployment del modello utilizzando gcloud CLI, esegui prima il deployment del modello su un endpoint.
Una configurazione del job di monitoraggio si applica a tutti i modelli di cui è stato eseguito il deployment in un endpoint.
Esegui il comando gcloud ai model-monitoring-jobs create:
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ --feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \ --prediction-sampling-rate=SAMPLING_RATE \ --monitoring-frequency=MONITORING_FREQUENCY \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
dove:
PROJECT_ID è l'ID del tuo progetto Google Cloud . Ad esempio,
my-project.REGION è la posizione del job di monitoraggio. Ad esempio,
us-central1.MONITORING_JOB_NAME è il nome del job di monitoraggio. Ad esempio,
my-job.EMAIL_ADDRESS è l'indirizzo email a cui vuoi ricevere gli avvisi di Model Monitoring. Ad esempio,
example@example.com.ENDPOINT_ID è l'ID dell'endpoint in cui viene eseguito il deployment del modello. Ad esempio,
1234567890987654321.(Facoltativo) FEATURE_1=THRESHOLD_1 è la soglia di avviso per ogni caratteristica che vuoi monitorare. Ad esempio, se specifichi
Age=0.4, Model Monitoring registra un avviso quando la [distanza statistica][stat-distance] tra le distribuzioni di input e di base per la caratteristicaAgesupera 0,4.(Facoltativo) SAMPLING_RATE è la frazione delle richieste di previsione in arrivo che vuoi registrare. Ad esempio,
0.5. Se non specificato, Model Monitoring registra tutte le richieste di previsione.(Facoltativo) MONITORING_FREQUENCY è la frequenza con cui vuoi che il job di monitoraggio venga eseguito sugli input registrati di recente. La granularità minima è 1 ora. Il valore predefinito è 24 ore. Ad esempio,
2.(obbligatorio solo per il rilevamento del disallineamento) TARGET_FIELD è il campo che viene previsto dal modello. Questo campo è escluso dall'analisi di monitoraggio. Ad esempio,
housing-price.(obbligatorio solo per il rilevamento dell'asimmetria) BIGQUERY_URI è il link al set di dati di addestramento archiviato in BigQuery, utilizzando il seguente formato:
bq://\PROJECT.\DATASET.\TABLE
Ad esempio,
bq://\my-project.\housing-data.\san-francisco.Puoi sostituire il flag
bigquery-uricon link alternativi al tuo set di dati di addestramento:Per un file CSV archiviato in un bucket Cloud Storage, utilizza
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Per un file TFRecord archiviato in un bucket Cloud Storage, utilizza
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Per un [set di dati gestito AutoML tabulare][dataset-id], utilizza
--dataset=DATASET_ID.
SDK Python
Per informazioni sul flusso di lavoro completo dell'API Model Monitoring, consulta il notebook di esempio.
API REST
Se non l'hai ancora fatto, esegui il deployment del modello su un endpoint.
Recupera l'ID modello di cui è stato eseguito il deployment per il tuo modello ottenendo le informazioni sull'endpoint. Prendi nota di DEPLOYED_MODEL_ID, che è il valore di
deployedModels.idnella risposta.Crea una richiesta di job di monitoraggio del modello. Le istruzioni riportate di seguito mostrano come creare un job di monitoraggio di base per il rilevamento della deriva con le attribuzioni. Per il rilevamento dell'asimmetria, aggiungi l'oggetto
explanationBaselineal campoexplanationConfignel corpo JSON della richiesta e fornisci uno dei seguenti valori:L'output di un job di spiegazione batch per il set di dati di addestramento.
Un
TrainingDatasetsu cui il servizio esegue un jobBatchExplainper generare una baseline.
Per maggiori dettagli, consulta Riferimento al job di monitoraggio.
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: è l'ID del tuo Google Cloud progetto. Ad esempio,
my-project. - LOCATION: è la località del job di monitoraggio. Ad esempio,
us-central1. - MONITORING_JOB_NAME: è il nome del tuo job di monitoraggio. Ad esempio:
my-job. - PROJECT_NUMBER: è il numero del tuo Google Cloud progetto. Ad esempio,
1234567890. - ENDPOINT_ID è l'ID dell'endpoint in cui viene eseguito il deployment del modello. Ad esempio:
1234567890. - DEPLOYED_MODEL_ID: è l'ID del modello di cui è stato eseguito il deployment.
- FEATURE:VALUE è la soglia di avviso
per ogni funzionalità che vuoi monitorare. Ad esempio:
"housing-latitude": {"value": 0.4}. Viene registrato un avviso quando la distanza statistica tra la distribuzione delle caratteristiche di input e la relativa base di riferimento supera la soglia specificata. Per impostazione predefinita, ogni caratteristica categorica e numerica viene monitorata, con valori di soglia pari a 0,3. - EMAIL_ADDRESS: è l'indirizzo email a cui vuoi ricevere
avvisi da Model Monitoring. Ad esempio,
example@example.com. - NOTIFICATION_CHANNELS:
un elenco di
canali di notifica di Cloud Monitoring
in cui vuoi ricevere avvisi da Model Monitoring. Utilizza i nomi delle risorse
per i canali di notifica, che puoi recuperare
elencando i canali di notifica
nel tuo progetto. Ad esempio:
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568".
Corpo JSON della richiesta:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, "explanationConfig": { "enableFeatureAttributes": true } } }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] } }Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }
Una volta creato il job di monitoraggio, Model Monitoring registra
le richieste di previsione in entrata in una tabella BigQuery generata denominata
PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict.
Se è abilitato il logging di richieste e risposte,
Model Monitoring registra le richieste in entrata nella stessa
tabella BigQuery utilizzata per il logging di richieste e risposte.
Consulta Utilizzo del monitoraggio del modello per istruzioni su come eseguire le seguenti attività facoltative:
Aggiorna un job di Model Monitoring.
Configurare gli avvisi per il job di monitoraggio del modello
Configura avvisi per le anomalie.
Analizza i dati relativi a disallineamenti e deviazioni delle attribuzioni delle caratteristiche
Puoi utilizzare la Google Cloud console per visualizzare le attribuzioni delle caratteristiche di ogni caratteristica monitorata e scoprire quali modifiche hanno causato distorsioni o deviazioni. Per informazioni sull'analisi dei dati di distribuzione delle caratteristiche, consulta Analizzare i dati di disallineamento e deviazione.
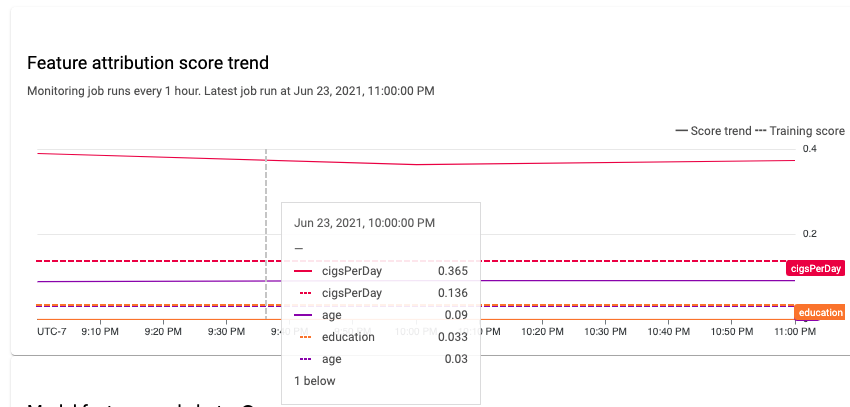
In un sistema di machine learning stabile, l'importanza relativa delle funzionalità in genere rimane relativamente stabile nel tempo. Se l'importanza di una funzionalità importante diminuisce, potrebbe significare che qualcosa è cambiato. Le cause comuni di deriva o distorsione dell'importanza delle funzionalità includono:
- Modifiche all'origine dati.
- Modifiche allo schema dei dati e al logging.
- Modifiche nel comportamento o nella combinazione di utenti finali (ad esempio, a causa di variazioni stagionali o eventi anomali).
- Modifiche upstream nelle funzionalità generate da un altro modello di machine learning.
Ecco alcuni esempi:
- Aggiornamenti del modello che causano un aumento o una diminuzione della copertura (complessiva o per un singolo valore di classificazione).
- Una variazione delle prestazioni del modello (che cambia il significato della funzionalità).
- Aggiornamenti della pipeline di dati, che possono causare una diminuzione della copertura complessiva.
Inoltre, tieni presente quanto segue quando analizzi i dati di disallineamento e deviazione dell'attribuzione delle caratteristiche:
Tieni traccia delle funzionalità più importanti. Una variazione significativa dell'attribuzione a una caratteristica indica che il contributo della caratteristica alla previsione è cambiato. Poiché il punteggio di previsione è uguale alla somma dei contributi delle caratteristiche, una deriva dell'attribuzione elevata delle caratteristiche più importanti di solito indica una deriva elevata nelle previsioni del modello.
Monitora tutte le rappresentazioni delle funzionalità. Le attribuzioni delle caratteristiche sono sempre numeriche, indipendentemente dal tipo di caratteristica sottostante. A causa della loro natura additiva, le attribuzioni a una caratteristica multidimensionale come gli incorporamenti possono essere ridotte a un singolo valore numerico sommando le attribuzioni tra le dimensioni. In questo modo puoi utilizzare metodi standard di rilevamento della deriva univariata per tutti i tipi di caratteristiche.
Tieni conto delle interazioni tra le funzionalità. L'attribuzione a una caratteristica tiene conto del contributo della caratteristica alla previsione, sia individualmente sia per le sue interazioni con altre caratteristiche. Se le interazioni di una funzionalità con altre funzionalità cambiano, le distribuzioni delle attribuzioni a una funzionalità cambiano, anche se la distribuzione marginale della funzionalità rimane invariata.
Monitora i gruppi di funzionalità. Poiché le attribuzioni sono additive, puoi sommare le attribuzioni alle funzionalità correlate per ottenere l'attribuzione di un gruppo di funzionalità. Ad esempio, in un modello di prestito di credito, combina l'attribuzione a tutte le funzionalità correlate al tipo di prestito (ad esempio "grado", "sottogrado", "scopo") per ottenere un'unica attribuzione del prestito. Questa attribuzione a livello di gruppo può essere monitorata per rilevare eventuali modifiche nel gruppo di funzionalità.
Passaggi successivi
- Utilizza Model Monitoring seguendo la documentazione dell'API.
- Utilizza Model Monitoring seguendo la documentazione di gcloud CLI.
- Prova il notebook di esempio in Colab o visualizzalo su GitHub.
- Scopri in che modo il monitoraggio dei modelli calcola il disallineamento tra addestramento e distribuzione e la deviazione della previsione.