En esta página, se describe cómo usar Vertex AI Model Monitoring con Vertex Explainable AI a fin de detectar sesgos y desvíos para las atribuciones de atributos de entrada numéricos y categóricos.
Descripción general de la supervisión basada en la atribución de atributos
Las atribuciones de atributos indican cuánto contribuyó cada atributo del modelo a las predicciones para cada instancia determinada. Cuando solicitas predicciones, obtienes valores previstos según corresponda para el modelo. Cuando solicitas explicaciones, obtienes las predicciones junto con la información de atribución de atributos.
Las puntuaciones de atribución son proporcionales a la contribución del atributo a la predicción de un modelo. Por lo general, se firman, lo que indica si un atributo ayuda a aumentar o reducir la predicción. Las atribuciones en todos los atributos deben sumar la puntuación de predicción del modelo.
Mediante la supervisión de atribuciones de atributos, la supervisión de modelos realiza un seguimiento de los cambios en las contribuciones de una función a las predicciones de un modelo a lo largo del tiempo. Un cambio en la puntuación de atribución de un atributo clave a menudo indica que el atributo cambió de una manera que puede afectar la exactitud de las predicciones del modelo.
Para obtener información sobre cómo se calcula una puntuación de atribución de atributos, consulta Métodos de atribución de atributos.
Sesgo entre el entrenamiento y la entrega de la atribución de atributos y desvío de predicción
Cuando creas un trabajo de supervisión para un modelo con Vertex Explainable AI habilitado, Model Monitoring supervisa el sesgo o el desvío de las distribuciones de atributos y las atribuciones de atributos. Para obtener información sobre el sesgo y el desvío de la distribución de las atributos, consulta Introducción a la supervisión de modelos de Vertex AI.
Para las atribuciones de atributos:
El sesgo entre el entrenamiento y la entrega se produce cuando la puntuación de atribución de un atributo en la producción se desvía de la puntuación de atribución del atributo en los datos de entrenamiento originales.
El desvío de predicción ocurre cuando la puntuación de atribución de un atributo en la producción cambia de manera significativa con el tiempo.
Puedes habilitar la detección de sesgo si proporcionas el conjunto de datos de entrenamiento original para tu modelo. De lo contrario, deberás habilitar la detección de desvío. También puedes habilitar la detección de sesgo y de desvío.
Requisitos previos
Para usar Model Monitoring con Vertex Explainable AI, completa lo siguiente:
Si habilitas la detección de sesgo, sube los datos de entrenamiento o el resultado de un trabajo de explicación por lotes para tu conjunto de datos de entrenamiento a Cloud Storage oBigQuery. Obtén el vínculo del URI a los datos. Para la detección de desvío, los datos de entrenamiento o el modelo de referencia de explicación no son obligatorios.
Ten un modelo disponible en Vertex AI que sea un tipo de entrenamiento personalizado tabular importado o AutoML tabular:
Un modelo tabular de AutoML tiene Vertex Explainable AI configurado de forma automática, por lo que puedes pasar a habilitar la detección de sesgo o desvío. Ten en cuenta que solo se admiten modelos de clasificación y regresión.
Un modelo entrenado personalizado importado debe configurarse para Vertex Explainable AI cuando creas, importas o implementas el modelo.
Configura tu modelo para usar Vertex Explainable AI cuando crees, importes o implementes el modelo. El campo
ExplanationSpec.ExplanationParametersse debe propagar para tu modelo.Opcional: Para los modelos con entrenamiento personalizado, sube el esquema de instancia de análisis de tu modelo a Cloud Storage. El modelo de Monitoring requiere que el esquema comience el proceso de supervisión y calcule la distribución de referencia para la detección de sesgos. Si no proporcionas el esquema durante la creación del trabajo, este permanece en estado pendiente hasta que la supervisión del modelo pueda analizar de forma automática el esquema de las primeras 1,000 solicitudes de predicción que recibe el modelo.
Habilita la detección de desvío o sesgos
Para configurar la detección de sesgo o de desvío, crea un trabajo de supervisión de la implementación del modelo:
Console
Para crear un trabajo de supervisión de la implementación del modelo con la consola deGoogle Cloud , crea un extremo:
En la consola de Google Cloud , ve a la página Extremos de Vertex AI.
Haz clic en Crear extremo.
En el panel Nuevo extremo, asigna un nombre al extremo y configura una región.
Haz clic en Continuar.
En el campo Nombre del modelo, selecciona un entrenamiento personalizado importado o un modelo tabular de AutoML.
En el campo Versión, selecciona una versión para tu modelo.
Haz clic en Continuar.
En el panel Supervisión del modelo, asegúrate de que la opción Habilitar la supervisión de modelos para este extremo esté activada. Cualquier configuración de supervisión que establezcas se aplica a todos los modelos implementados en el extremo.
Ingresa un nombre visible de trabajo de supervisión.
Ingresa una longitud de ventana de supervisión.
En Notificaciones por correo electrónico, ingresa una o más direcciones de correo electrónico separadas por comas para recibir alertas cuando un modelo supere un umbral de alertas.
(Opcional) En Canales de notificaciones, selecciona (Cloud Monitoring) canales para recibir alertas cuando un modelo supere un umbral de alertas. Puedes seleccionar canales existentes de Cloud Monitoring o crear uno nuevo haciendo clic en Administrar canales de notificaciones. La consola es compatible con los canales de notificaciones de PagerDuty, Slack y Pub/Sub.
Ingresa una Tasa de muestreo.
Opcional: Ingresa el Esquema de entrada de predicción y el Esquema de entrada de análisis.
Haz clic en Continuar. Se abrirá el panel Objetivo de supervisión con opciones para la detección de desvíos o sesgos:
Detección de sesgos
- Selecciona Detección de sesgos entre el entrenamiento y la entrega.
- En Fuente de datos de entrenamiento, proporciona una fuente de datos de entrenamiento.
- En Columna objetivo, ingresa el nombre de la columna de los datos de entrenamiento que el modelo está entrenado para predecir. Este campo se excluye del análisis de supervisión.
- Opcional: En Límites de alerta, especifica los límites para activar las alertas. Para obtener información sobre cómo dar formato a los umbrales, mantén el puntero sobre el ícono de ayuda .
- Haz clic en Crear.
Detección de desvíos
- Selecciona Detección de desvío de predicción.
- Opcional: En Límites de alerta, especifica los límites para activar las alertas. Para obtener información sobre cómo dar formato a los umbrales, mantén el puntero sobre el ícono de ayuda .
- Haz clic en Crear.
gcloud
Para crear un trabajo de supervisión de la implementación del modelo con la CLI de gcloud, primero implementa tu modelo en un extremo.
La configuración de un trabajo de supervisión se aplica a todos los modelos implementados en un extremo.
Ejecuta el comando gcloud ai model-monitoring-jobs create:
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ --feature-thresholds=FEATURE_1=THRESHOLD_1,FEATURE_2=THRESHOLD_2 \ --prediction-sampling-rate=SAMPLING_RATE \ --monitoring-frequency=MONITORING_FREQUENCY \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
Donde:
PROJECT_ID es el ID de tu proyecto de Google Cloud . Por ejemplo,
my-project.REGION es la ubicación de tu trabajo de supervisión. Por ejemplo,
us-central1.MONITORING_JOB_NAME es el nombre de tu trabajo de supervisión. Por ejemplo,
my-job.EMAIL_ADDRESS es la dirección de correo electrónico en la que deseas recibir alertas de Model Monitoring. Por ejemplo,
example@example.com.ENDPOINT_ID es el ID del extremo en el que se implementa el modelo. Por ejemplo,
1234567890987654321.Opcional: FEATURE_1=THRESHOLD_1 es el umbral de alertas de cada función que deseas supervisar. Por ejemplo, si especificas
Age=0.4, Model Monitoring registra una alerta cuando [statistical][distance][stat-distance] entre las distribuciones de entrada y del modelo de referencia para el atributoAgesupera 0,4Opcional: SAMPLING_RATE es la fracción de las solicitudes de predicción entrantes que deseas registrar. Por ejemplo,
0.5. Si no se especifica, Model Monitoring registra todas las solicitudes de predicción.Opcional: MONITORING_FREQUENCY es la frecuencia con la que deseas que el trabajo de supervisión se ejecute en las entradas registradas recientemente. El nivel de detalle mínimo es 1 hora. El valor predeterminado es de 24 horas. Por ejemplo,
2.(obligatorio para la detección de sesgo) TARGET_FIELD es el campo que predice el modelo. Este campo se excluye del análisis de supervisión. Por ejemplo,
housing-price.(obligatorio para la detección de sesgo) BIGQUERY_URI es obligatorio para el conjunto de datos de entrenamiento almacenado en BigQuery y usa el siguiente formato:
bq://\PROJECT.\DATASET.\TABLE
Por ejemplo,
bq://\my-project.\housing-data.\san-francisco.Puedes reemplazar la marca
bigquery-uripor vínculos alternativos a tu conjunto de datos de entrenamiento:Para un archivo CSV almacenado en un bucket de Cloud Storage, usa
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Para un archivo TFRecord almacenado en un bucket de Cloud Storage, usa
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Para un [tabular AutoML managed dataset][dataset-id], usa
--dataset=DATASET_ID.
Python SDK
Para obtener información sobre el flujo de trabajo de la API de Model Monitoring de modelo de extremo a extremo, consulta el notebook de ejemplo.
API de REST
Si aún no lo hiciste, implementa tu modelo en un extremo.
Recupera el ID de modelo implementado para tu modelo mediante la obtención de la información del extremo. Ten en cuenta el DEPLOYED_MODEL_ID, que es el valor de
deployedModels.iden la respuesta.Crea una solicitud de trabajo de supervisión de modelo. En las instrucciones que aparecen a continuación, se muestra cómo crear un trabajo de supervisión básico para la detección de desvíos con atribuciones. Para la detección de sesgo, agrega el objeto
explanationBaselineal campoexplanationConfigen el cuerpo JSON de la solicitud y proporciona una de las siguientes opciones:La salida de un trabajo de explicación por lotes para tu conjunto de datos de entrenamiento.
Un
TrainingDataseten la que el servicio ejecuta un trabajoBatchExplainpara generar un modelo de referencia.
Para obtener más detalles, consulta la referencia del trabajo de Monitoring.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- PROJECT_ID: Es el ID de tu proyecto de Google Cloud . Por ejemplo,
my-project. - LOCATION: es la ubicación de tu trabajo de supervisión. Por ejemplo,
us-central1. - MONITORING_JOB_NAME: es el nombre de tu trabajo de supervisión. Por ejemplo:
my-job - PROJECT_NUMBER: Es el número de tu proyecto de Google Cloud . Por ejemplo,
1234567890. - ENDPOINT_ID es el ID para el extremo en el que se implementa tu modelo. Por
ejemplo,
1234567890 - DEPLOYED_MODEL_ID es el ID del modelo implementado.
- FEATURE:VALUE es el umbral de alertas de
cada función que deseas supervisar. Por ejemplo,
"housing-latitude": {"value": 0.4}. Se registra una alerta cuando la distancia estadística entre la distribución de los atributos de entrada y el modelo de referencia correspondiente supera el umbral especificado. De forma predeterminada, se supervisa cada atributo categórico y numérico, con valores de umbral de 0.3. - EMAIL_ADDRESS: es la dirección de correo electrónico en la que deseas recibir alertas de Model Monitoring. Por ejemplo,
example@example.com. - NOTIFICATION_CHANNELS:
Una lista de
canales de notificación de Cloud Monitoring
en los que deseas recibir alertas de Model Monitoring. Usa los nombres de los recursos
para los canales de notificaciones, que puedes recuperar si
enumeras los canales de notificaciones
en tu proyecto. Por ejemplo,
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568".
Cuerpo JSON de la solicitud:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, "explanationConfig": { "enableFeatureAttributes": true } } }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] } }Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }
Una vez que se crea el trabajo de supervisión, Model Monitoring registra las solicitudes de predicción entrantes en una tabla de BigQuery generada con el nombre PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict.
Si el registro de solicitudes y respuestas está habilitado, Model Monitoring registra las solicitudes entrantes en la misma tabla de BigQuery que se usa para el registro de solicitudes y respuestas.
Consulta Usa Model Monitoring para obtener instrucciones sobre cómo realizar las siguientes tareas opcionales:
Actualiza un trabajo de Model Monitoring.
Configura alertas para el trabajo de Model Monitoring
Configura alertas para las anomalías.
Analiza los datos de sesgo y desvío de la atribución de atributos
Puedes usar la Google Cloud consola para visualizar las atribuciones de atributos de cada atributo supervisado y descubrir qué cambios generaron un sesgo o un desvío. Para obtener información sobre el análisis de datos de distribución de características, consulta Analiza datos de sesgo y desvío.
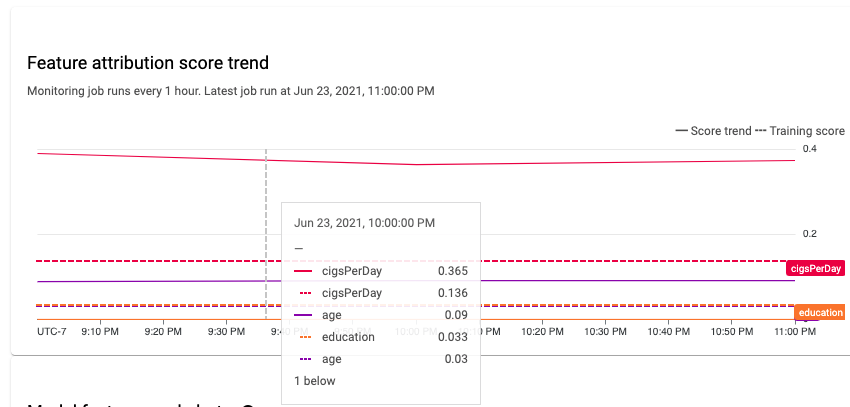
En un sistema de aprendizaje automático estable, la importancia relativa de los atributos suele permanecer relativamente estable en el tiempo. Si un atributo importante disminuye de forma significativa, podría indicar que algo cambió en ese atributo. Las causas comunes de la desviación o el sesgo de la importancia de los atributos incluyen las siguientes:
- Cambios en la fuente de datos.
- Cambios en los registros y el esquema de datos.
- Cambios en la combinación o el comportamiento del usuario final (por ejemplo, debido a cambios estacionales o eventos de valores atípicos).
- Cambios ascendentes en los atributos generados por otro modelo de aprendizaje automático.
Por ejemplo:
- Actualizaciones del modelo que causan un aumento o una disminución de la cobertura (en general o de un valor de clasificación individual).
- Un cambio en el rendimiento del modelo (que cambia el significado del atributo).
- Actualizaciones a la canalización de datos, que pueden causar una disminución de la cobertura general.
Además, ten en cuenta lo siguiente cuando analices datos sesgados y de desvío de la atribución de atributos:
Realiza un seguimiento de los atributos más importantes. Un gran cambio en la atribución de un atributo significa que la contribución de este a la predicción cambió. Debido a que la puntuación de predicción es igual a la suma de las contribuciones de atributos, un gran desvío de atribución de los atributos más importantes por lo general indica un gran desvío en las predicciones del modelo.
Supervisa todas las representaciones de atributos Las atribuciones de atributos siempre son numéricas, sin importar el tipo de atributo subyacente. Debido a su naturaleza aditiva, las atribuciones a un atributo multidimensional (por ejemplo, las incorporaciones) se pueden reducir a un solo valor numérico mediante la suma de las atribuciones entre dimensiones. Esto te permite usar métodos de detección de desvío univarias estándar para todos los tipos de características.
Ten en cuenta las interacciones de los atributos. La atribución a un atributo explica la contribución del atributo a la predicción, tanto de forma individual como por sus interacciones con otros atributos. Si las interacciones de un atributo con otros atributos cambian, las distribuciones de las atribuciones a un atributo cambia, incluso si la distribución marginal del atributo permanece igual.
Supervisa grupos de atributos. Debido a que las atribuciones son aditivas, puedes agregar atribuciones a atributos relacionados para obtener la atribución de un grupo de atributos. Por ejemplo, en un modelo de préstamos de crédito, combina la atribución a todos los atributos relacionados con el tipo de préstamo (por ejemplo, “grado”, “subgrado”, “propósito”) para obtener una sola atribución de préstamo. Se puede hacer un seguimiento de esta atribución a nivel de grupo para supervisar los cambios en el grupo de atributos.
¿Qué sigue?
- Trabaja con la supervisión de modelos según la documentación de la API.
- Trabaja con Model Monitoring según los documentos de la CLI de gcloud.
- Prueba la notebook de ejemplo en Colab o visualízala en GitHub.
- Obtén información sobre cómo Model Monitoring calcula el sesgo entre el entrenamiento y la entrega, y el desvío de predicción.