Cette page explique comment configurer des requêtes de tâches d'inférence par lot pour inclure une analyse Model Monitoring ponctuelle. Pour les inférences par lot, Model Monitoring accepte la détection des décalages de caractéristiques pour les caractéristiques d'entrée catégorielles et numériques.
Pour créer une tâche d'inférence par lot avec une analyse des décalages Model Monitoring, vous devez inclure à la fois vos données d'entrée d'inférence par lot et les données d'entraînement d'origine de votre modèle dans la requête. Vous ne pouvez ajouter une analyse Model Monitoring que lors de la création de tâches d'inférence par lot.
Pour plus d'informations sur les décalages, consultez la Présentation de Model Monitoring.
Pour savoir comment configurer Model Monitoring pour les inférences en ligne (en temps réel), consultez la page Utiliser Model Monitoring.
Prérequis
Pour utiliser la surveillance de modèles avec des inférences par lot, procédez comme suit :
Vous devez disposer d'un modèle disponible dans Vertex AI Model Registry, soit un type tabulaire AutoML, soit un type d'entraînement personnalisé tabulaire.
Importez vos données d'entraînement dans Cloud Storage ou BigQuery et obtenez le lien URI vers les données.
- Pour les modèles entraînés avec AutoML, vous pouvez utiliser à la place l'ID de l'ensemble de données d'entraînement.
La surveillance des modèles compare les données d'entraînement au résultat de l'inférence par lot. Assurez-vous d'utiliser les formats de fichiers compatibles pour les données d'entraînement et le résultat de l'inférence par lot :
Type de modèle Données d'entraînement Résultat de l'inférence par lot Entraînement personnalisé CSV, JSONL, BigQuery, TfRecord(tf.train.Example) JSONL Tabulaire AutoML CSV, JSONL, BigQuery, TfRecord(tf.train.Example) CSV, JSONL, BigQuery, TfRecord(Protobuf.Value) Facultatif : Pour les modèles entraînés personnalisés, importez le schéma de votre modèle dans Cloud Storage. La surveillance des modèles nécessite le schéma afin de calculer la distribution de référence pour détecter les décalages.
Demander une inférence par lot
Vous pouvez utiliser les méthodes suivantes pour ajouter des configurations de Monitoring de modèle aux tâches d'inférence par lot :
Console
Suivez les instructions pour effectuer une requête d'inférence par lot avec la surveillance de modèles activée :
API REST
Suivez les instructions pour effectuer une requête d'inférence par lot à l'aide de l'API REST :
Lorsque vous créez la requête d'inférence par lot, ajoutez la configuration de surveillance de modèles suivante au corps de la requête JSON :
"modelMonitoringConfig": {
"alertConfig": {
"emailAlertConfig": {
"userEmails": "EMAIL_ADDRESS"
},
"notificationChannels": [NOTIFICATION_CHANNELS]
},
"objectiveConfigs": [
{
"trainingDataset": {
"dataFormat": "csv",
"gcsSource": {
"uris": [
"TRAINING_DATASET"
]
}
},
"trainingPredictionSkewDetectionConfig": {
"skewThresholds": {
"FEATURE_1": {
"value": VALUE_1
},
"FEATURE_2": {
"value": VALUE_2
}
}
}
}
]
}
où :
EMAIL_ADDRESS est l'adresse e-mail à laquelle vous souhaitez recevoir des alertes de la surveillance de modèles. Par exemple,
example@example.com.NOTIFICATION_CHANNELS : liste des canaux de notification Cloud Monitoring dans lesquels vous souhaitez recevoir des alertes de la surveillance de modèles. Utilisez les noms de ressources des canaux de notification, que vous pouvez récupérer en répertoriant les canaux de notification de votre projet. Exemple :
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568".TRAINING_DATASET est le lien vers l'ensemble de données d'entraînement stocké dans Cloud Storage.
- Pour utiliser un lien vers un ensemble de données d'entraînement BigQuery, remplacez le champ
gcsSourcepar ce qui suit :
"bigquerySource": { { "inputUri": "TRAINING_DATASET" } }- Pour utiliser un lien vers un modèle AutoML, remplacez le champ
gcsSourcepar ce qui suit :
"dataset": "TRAINING_DATASET"
- Pour utiliser un lien vers un ensemble de données d'entraînement BigQuery, remplacez le champ
FEATURE_1:VALUE_1 et FEATURE_2:VALUE_2 est le seuil d'alerte pour chaque caractéristique que vous souhaitez surveiller. Par exemple, si vous spécifiez
Age=0.4, Model Monitoring enregistre une alerte lorsque la distance statistique entre la distribution d'entrée et la distribution de référence de la caractéristiqueAgedépasse 0,4. Par défaut, chaque caractéristique catégorielle et numérique est surveillée, avec des valeurs de seuil de 0,3.
Pour en savoir plus sur les configurations de Model Monitoring, consultez la documentation de référence sur les tâches de surveillance.
Python
Consultez l'exemple de notebook pour exécuter une tâche d'inférence par lot avec Model Monitoring pour un modèle tabulaire personnalisé.
La surveillance de modèles vous informe automatiquement par e-mail des mises à jour et des alertes relatives aux tâches.
Accéder aux métriques de décalage
Vous pouvez utiliser les méthodes suivantes pour accéder aux métriques de décalage pour les tâches d'inférence par lot :
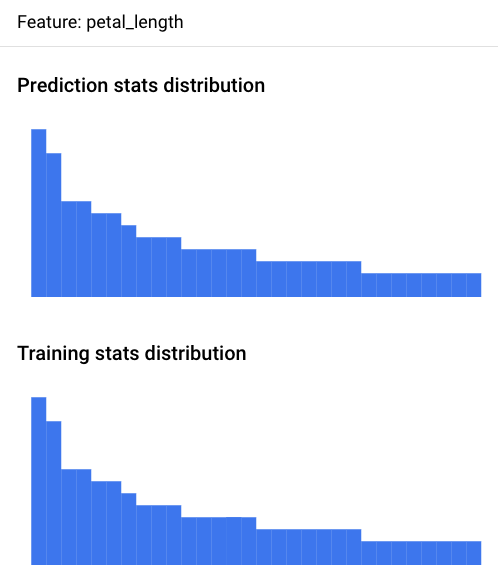
Console (histogramme)
Utilisez la console Google Cloud pour afficher les histogrammes de distribution des caractéristiques pour chaque caractéristique surveillée et identifier les modifications qui ont entraîné un décalage au fil du temps :
Accéder à la page Prédictions par lot :
Sur la page Prédictions par lot, cliquez sur la tâche d'inférence par lot que vous souhaitez analyser.
Cliquez sur l'onglet Alertes Model Monitoring pour afficher la liste des caractéristiques d'entrée du modèle, ainsi que des informations pertinentes, telles que le seuil d'alerte de chaque caractéristique.
Pour analyser une caractéristique, cliquez sur son nom. Une page affiche les histogrammes de distribution des caractéristiques pour cette caractéristique.
Visualiser la distribution des données sous forme d'histogrammes vous permet de vous concentrer rapidement sur les modifications survenues dans les données. Vous pouvez ensuite décider d'ajuster votre pipeline de génération de caractéristiques ou de réentraîner le modèle.
Console (fichier JSON)
Utilisez la console Google Cloud pour accéder aux métriques au format JSON :
Accéder à la page Prédictions par lot :
Cliquez sur le nom du job de surveillance de l'inférence par lot.
Cliquez sur l'onglet Propriétés de la surveillance.
Cliquez sur le lien Répertoire de sortie pour la surveillance, qui vous redirige vers un bucket Cloud Storage.
Cliquez sur le dossier
metrics/.Cliquez sur le dossier
skew/.Cliquez sur le fichier
feature_skew.json, qui vous redirige vers la page Détails de l'objet.Ouvrez le fichier JSON en utilisant l'une des options suivantes :
Cliquez sur Télécharger et ouvrez le fichier dans votre éditeur de texte local.
Utilisez le chemin d'accès au fichier gsutil URI pour exécuter
gcloud storage cat gsutil_URIdans Cloud Shell ou dans votre terminal local.
Le fichier feature_skew.json inclut un dictionnaire dans lequel la clé correspond au nom de la caractéristique et la valeur est le décalage de caractéristique. Exemple :
{
"cnt_ad_reward": 0.670936,
"cnt_challenge_a_friend": 0.737924,
"cnt_completed_5_levels": 0.549467,
"month": 0.293332,
"operating_system": 0.05758,
"user_pseudo_id": 0.1
}
Python
Consultez l'exemple de notebook pour accéder aux métriques de décalage d'un modèle tabulaire personnalisé après avoir exécuté une tâche d'inférence par lot avec la surveillance des modèles.
Déboguer les échecs de surveillance de l'inférence par lot
Si votre tâche de surveillance de l'inférence par lot échoue, vous trouverez des journaux de débogage dans la console Google Cloud :
Accéder à la page Prédictions par lot
Cliquez sur le nom du job de surveillance de l'inférence par lot ayant échoué.
Cliquez sur l'onglet Propriétés de la surveillance.
Cliquez sur le lien Répertoire de sortie pour la surveillance, qui vous redirige vers un bucket Cloud Storage.
Cliquez sur le dossier
logs/.Cliquez sur l'un des fichiers
.INFO, qui vous redirige vers la page Détails des objets.Ouvrez le fichier journaux en utilisant l'une des options suivantes :
Cliquez sur Télécharger et ouvrez le fichier dans votre éditeur de texte local.
Utilisez le chemin d'accès au fichier gsutil URI pour exécuter
gcloud storage cat gsutil_URIdans Cloud Shell ou dans votre terminal local.
Tutoriels sur les notebooks
Grâce à ces tutoriels de bout en bout, vous pouvez apprendre à utiliser Vertex AI Model Monitoring pour obtenir des visualisations et des statistiques sur les modèles.
AutoML
- Vertex AI Model Monitoring pour les modèles tabulaires AutoML
- Vertex AI Model Monitoring pour la prédiction par lot dans des modèles d'image AutoML
- Vertex AI Model Monitoring pour la prédiction en ligne dans les modèles d'image AutoML
Personnalisé
- Vertex AI Model Monitoring pour les modèles tabulaires personnalisés
- Vertex AI Model Monitoring pour les modèles tabulaires personnalisés avec conteneur TensorFlow Serving
Modèles XGBoost
Attributions de caractéristiques Vertex Explainable AI
Inférence par lot
Configuration pour les modèles tabulaires
Étapes suivantes
- Découvrez comment utiliser la surveillance des modèles.
- Découvrez comment Model Monitoring calcule les écarts entraînement/diffusion et les dérives d'inférence.