Cette page présente la surveillance des modèles Vertex AI.
Présentation de la surveillance
Vertex AI Model Monitoring vous permet d'exécuter des jobs de surveillance en fonction des besoins ou à intervalles réguliers afin de suivre la qualité de vos modèles tabulaires. Si vous avez défini des alertes, Vertex AI Model Monitoring vous informe lorsque les métriques dépassent un seuil spécifié.
Supposons, par exemple, que vous disposiez d'un modèle qui prédit la valeur vie client. À mesure que les habitudes des clients changent, les facteurs qui prédisent les dépenses des clients changent également. Par conséquent, les caractéristiques et les valeurs de caractéristiques utilisées auparavant pour entraîner votre modèle peuvent ne plus être pertinentes pour effectuer des inférences aujourd'hui. Cet écart dans les données est appelé la dérive.
Vertex AI Model Monitoring peut surveiller ces dérives et vous avertir lorsque les écarts dépassent un seuil spécifié. Vous pouvez ensuite réévaluer ou réentraîner votre modèle pour vous assurer qu'il se comporte comme prévu.
Par exemple, Vertex AI Model Monitoring peut fournir des représentations visuelles semblables à la figure suivante, qui superpose deux graphiques à partir de deux ensembles de données. Cette représentation visuelle vous permet de comparer rapidement les deux ensembles de données et de voir les écarts.
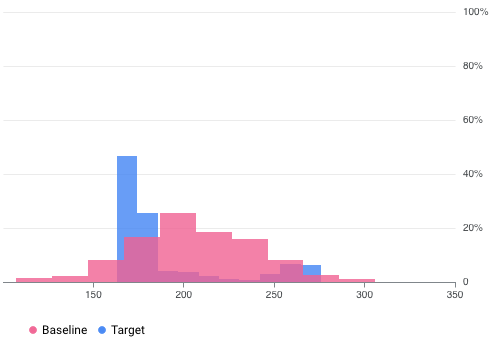
Versions de Vertex AI Model Monitoring
Deux offres Vertex AI Model Monitoring sont disponibles : v2 et v1.
Model Monitoring v2 est disponible en version preview et il s'agit de la dernière offre qui associe tous les jobs de surveillance à une version de modèle. L'offre Model Monitoring v1 est quant à elle en disponibilité générale et configurée sur les points de terminaison Vertex AI.
Si vous avez besoin d'une assistance de niveau production et que vous souhaitez surveiller un modèle déployé sur un point de terminaison Vertex AI, utilisez Model Monitoring v1. Pour tous les autres cas d'utilisation, utilisez Model Monitoring v2, qui fournit toutes les fonctionnalités de Model Monitoring v1, ainsi que d'autres fonctionnalités. Pour en savoir plus, consultez la présentation de chaque version :
Pour les utilisateurs existants de Model Monitoring v1, Model Monitoring v1 est conservé tel quel. Vous n'êtes pas obligé de migrer vers Model Monitoring v2. Si vous souhaitez migrer, vous pouvez utiliser les deux versions simultanément jusqu'à ce que vous ayez entièrement migré vers Model Monitoring v2 afin d'éviter toute discontinuité dans la surveillance pendant la transition.
Présentation de Model Monitoring v2
Model Monitoring v2 vous permet de suivre les métriques au fil du temps après avoir configuré une surveillance de modèle et exécuté des jobs de surveillance. Vous pouvez exécuter des jobs de surveillance à la demande ou configurer des exécutions planifiées. Avec les exécutions planifiées, Model Monitoring exécute automatiquement les jobs de surveillance en fonction d'une planification que vous définissez.
Objectifs de surveillance
Les métriques et les seuils que vous surveillez sont mappés à des objectifs de surveillance. Pour chaque version de modèle, vous pouvez spécifier un ou plusieurs objectifs de surveillance. Le tableau suivant détaille chaque objectif :
| Objectif | Description | Types de données des caractéristiques | Métriques acceptées |
|---|---|---|---|
| Dérive des données des caractéristiques d'entrée |
Mesure la distribution des valeurs des caractéristiques d'entrée par rapport à une distribution de données de référence. |
Catégorielle : booléen, chaîne, catégorielle |
|
| Numérique : nombre à virgule flottante, entier | Divergence de Jensen-Shannon | ||
| Dérive des données d'inférence de résultats |
Mesure la distribution des données d'inférences du modèle par rapport à une distribution de données de référence. |
Catégorielle : booléen, chaîne, catégorielle |
|
| Numérique : nombre à virgule flottante, entier | Divergence de Jensen-Shannon | ||
| Attribution des caractéristiques |
Mesure la variation dans la contribution des caractéristiques à l'inférence d'un modèle par rapport à une référence. Par exemple, vous pouvez suivre si une caractéristique très importante perd soudainement de son importance. |
Tous les types de données | Valeur SHAP (SHapley Additive exPlanations) |
Dérive des caractéristiques d'entrée et de l'inférence de sortie
Une fois qu'un modèle est déployé en production, les données d'entrée peuvent différer de celles utilisées pour entraîner le modèle, ou la distribution des données de caractéristiques en production peut changer considérablement au fil du temps. Model Monitoring v2 peut surveiller les changements de distribution des données de production par rapport aux données d'entraînement, ou permettre de suivre l'évolution de la distribution des données de production au fil du temps.
De même, pour les données d'inférence, Model Monitoring v2 peut surveiller les changements de distribution des résultats prévus par rapport à la distribution des données d'entraînement ou des données de production au fil du temps.
Attribution des caractéristiques
Les attributions de caractéristiques indiquent dans quelle mesure chaque caractéristique de votre modèle a contribué aux inférences pour chaque instance donnée. Les scores d'attribution sont proportionnels à la contribution de la caractéristique à l'inférence d'un modèle. Ils sont généralement signés, ce qui indique si une caractéristique contribue à améliorer ou à affaiblir l'inférence. Les attributions sur l'ensemble des caractéristiques doivent totaliser le score d'inférence du modèle.
En surveillant les attributions de caractéristiques, Model Monitoring v2 suit les changements dans les contributions d'une caractéristique aux inférences d'un modèle au fil du temps. Une modification du score d'attribution d'une caractéristique clé indique souvent que la caractéristique a changé d'une manière susceptible d'affecter la précision des inférences du modèle.
Pour en savoir plus sur les attributions et les métriques des caractéristiques, consultez les sections Explications basées sur des caractéristiques et Méthode d'échantillonnage de valeurs de Shapley.
Configurer Model Monitoring v2
Vous devez d'abord enregistrer vos modèles dans Vertex AI Model Registry. Si vous diffusez des modèles en dehors de Vertex AI, vous n'avez pas besoin d'importer l'artefact de modèle. Vous devez ensuite créer une surveillance de modèle, que vous associez à une version de modèle, puis définir le schéma de votre modèle. Pour certains modèles, tels que les modèles AutoML, le schéma vous est fourni.
Dans la surveillance de modèle, vous pouvez éventuellement spécifier des configurations par défaut telles que des objectifs de surveillance, un ensemble de données d'entraînement, l'emplacement des résultats de surveillance et les paramètres de notification. Pour en savoir plus, consultez la section Configurer la surveillance des modèles.
Une fois que vous avez créé une surveillance de modèle, vous pouvez exécuter un job de surveillance à la demande ou planifier des jobs standards pour une surveillance continue. Lorsque vous exécutez un job, Model Monitoring utilise la configuration par défaut définie dans la surveillance du modèle, sauf si vous fournissez une configuration de surveillance différente. Par exemple, si vous fournissez différents objectifs de surveillance ou un autre ensemble de données de comparaison, Model Monitoring utilise les configurations du job au lieu de la configuration par défaut de la surveillance de modèle. Pour en savoir plus, consultez la section Exécuter un job de surveillance.
Tarifs
L'utilisation de Model Monitoring v2 ne vous est pas facturée pendant la période de preview. Vous êtes toujours facturé pour l'utilisation d'autres services, tels que Cloud Storage, BigQuery, les inférences par lot Vertex AI, Vertex Explainable AI et Cloud Logging.
Tutoriels sur les notebooks
Les tutoriels suivants montrent comment utiliser le SDK Vertex AI pour Python afin de configurer Model Monitoring v2 pour votre modèle.
Model Monitoring v2 : job d'inférence par lot de modèle personnalisé
Model Monitoring v2 : inférence en ligne de modèle personnalisé
Model Monitoring v2 : modèles en dehors de Vertex AI
Présentation de Model Monitoring v1
Pour vous aider à maintenir les performances d'un modèle, Model Monitoring v1 surveille les données d'entrée d'inférence du modèle pour connaître les décalages et les dérives des caractéristiques :
Un décalage entraînement/diffusion se produit lorsque la distribution des données de caractéristiques en production est différente de la distribution des données de caractéristique utilisée pour entraîner le modèle. Si les données d'entraînement d'origine sont disponibles, vous pouvez activer la détection des écarts pour surveiller les décalages d'entraînement/diffusion de vos modèles.
Une dérive de l'inférence se produit lorsque la distribution des données de caractéristiques en production change de manière significative au fil du temps. Si les données d'entraînement d'origine ne sont pas disponibles, vous pouvez activer la détection de écarts pour surveiller les changements des données entrées au fil du temps.
Vous pouvez activer la détection des écarts et des décalages.
Model Monitoring v1 accepte la détection des décalages et des dérives des caractéristiques pour les caractéristiques catégorielles et numériques.
Les caractéristiques de type catégorique sont des données limitées par le nombre de valeurs possibles, généralement regroupées par propriétés qualitatives. Par exemple, des catégories telles que le type de produit, le pays ou le type de client.
Les caractéristiques numériques sont des données qui peuvent être n'importe quelle valeur numérique. Par exemple, le poids et la hauteur.
Une fois que le décalage ou la dérive d'une caractéristique d'un modèle dépasse le seuil d'alerte que vous avez défini, Model Monitoring v1 vous envoie une alerte par e-mail. Vous pouvez également afficher les distributions de chaque caractéristique au fil du temps pour déterminer si vous devez réentraîner votre modèle.
Calculer la dérive
Pour détecter la dérive pour la v1, Vertex AI Model Monitoring utilise TensorFlow Data Validation (TFDV) pour calculer les distributions et les scores de distance.
Calculez la distribution statistique de référence :
Pour la détection des écarts, la référence correspond à la distribution statistique des valeurs de la caractéristique dans les données d'entraînement.
Pour la détection de la dérive, la référence correspond à la distribution statistique des valeurs de caractéristique récemment observées en production.
Les distributions des caractéristiques catégorielles et numériques sont calculées comme suit :
Pour les caractéristiques catégorielles, la distribution calculée est le nombre ou le pourcentage d'instances de chaque valeur possible de la caractéristique.
Pour les caractéristiques numériques, Vertex AI Model Monitoring divise la plage de valeurs de caractéristiques possibles en intervalles égaux et calcule le nombre ou le pourcentage de valeurs de caractéristiques qui tombe dans chaque intervalle.
La référence est calculée lorsque vous créez un job Vertex AI Model Monitoring et n'est recalculée que si vous mettez à jour l'ensemble de données d'entraînement du job.
Calculez la distribution statistique des dernières valeurs de caractéristiques observées en production.
Comparez la distribution des dernières valeurs de caractéristiques en production à la distribution de référence en calculant un score de distance :
Pour les caractéristiques de type catégorique, le score de distance est calculé à l'aide de la distance L-infini.
Pour les caractéristiques numériques, le score de distance est calculé à l'aide de la divergence Jensen-Shannon.
Lorsque le score de distance entre deux distributions statistiques dépasse le seuil que vous spécifiez, Vertex AI Model Monitoring identifie l'anomalie en tant que décalage ou dérive.
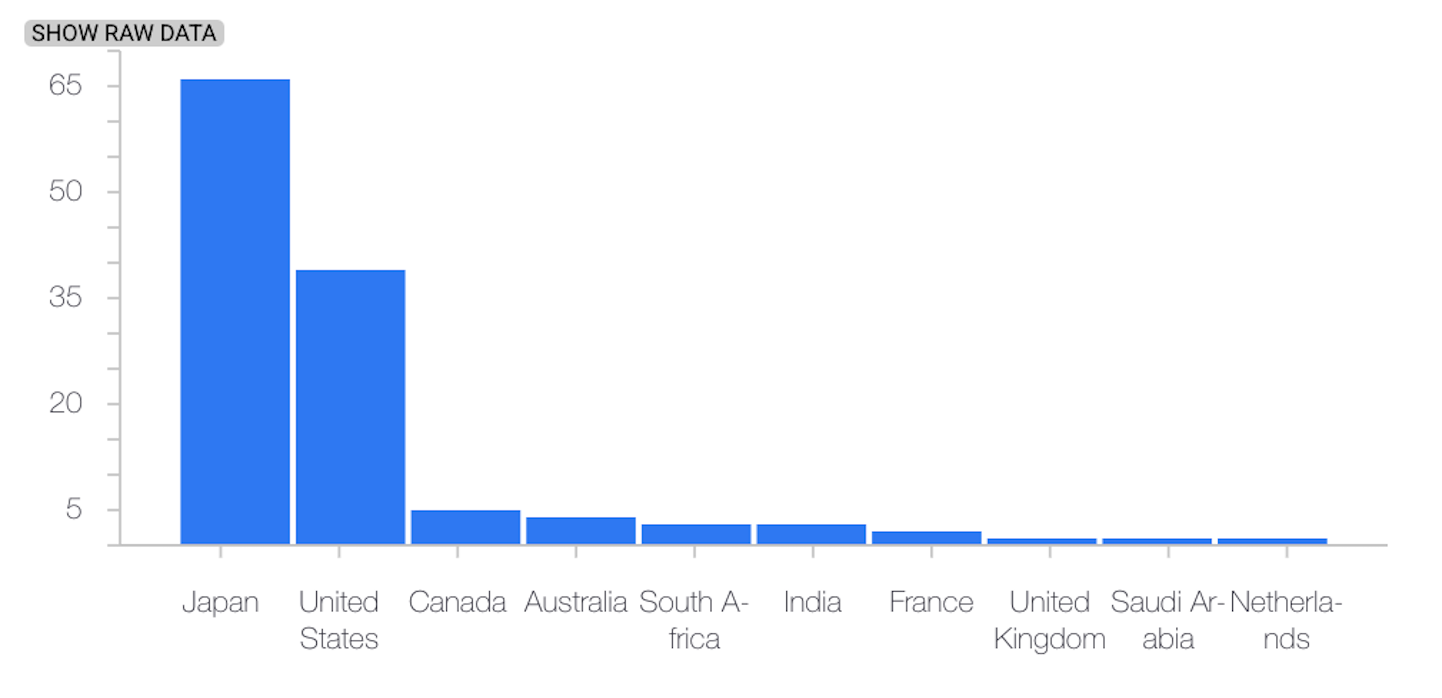
L'exemple suivant montre un décalage ou un écart entre la distribution de référence et la dernière distribution d'une caractéristique catégorielle :
Distribution de référence
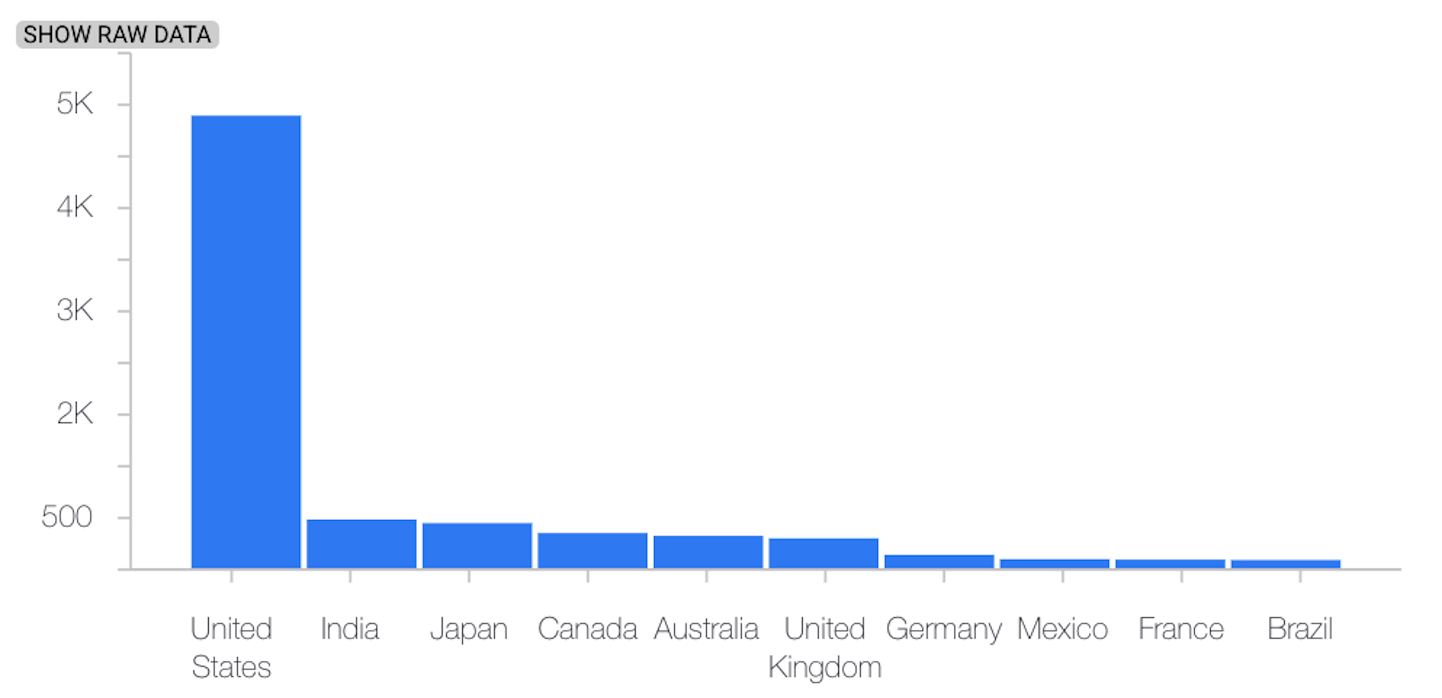
Dernière distribution
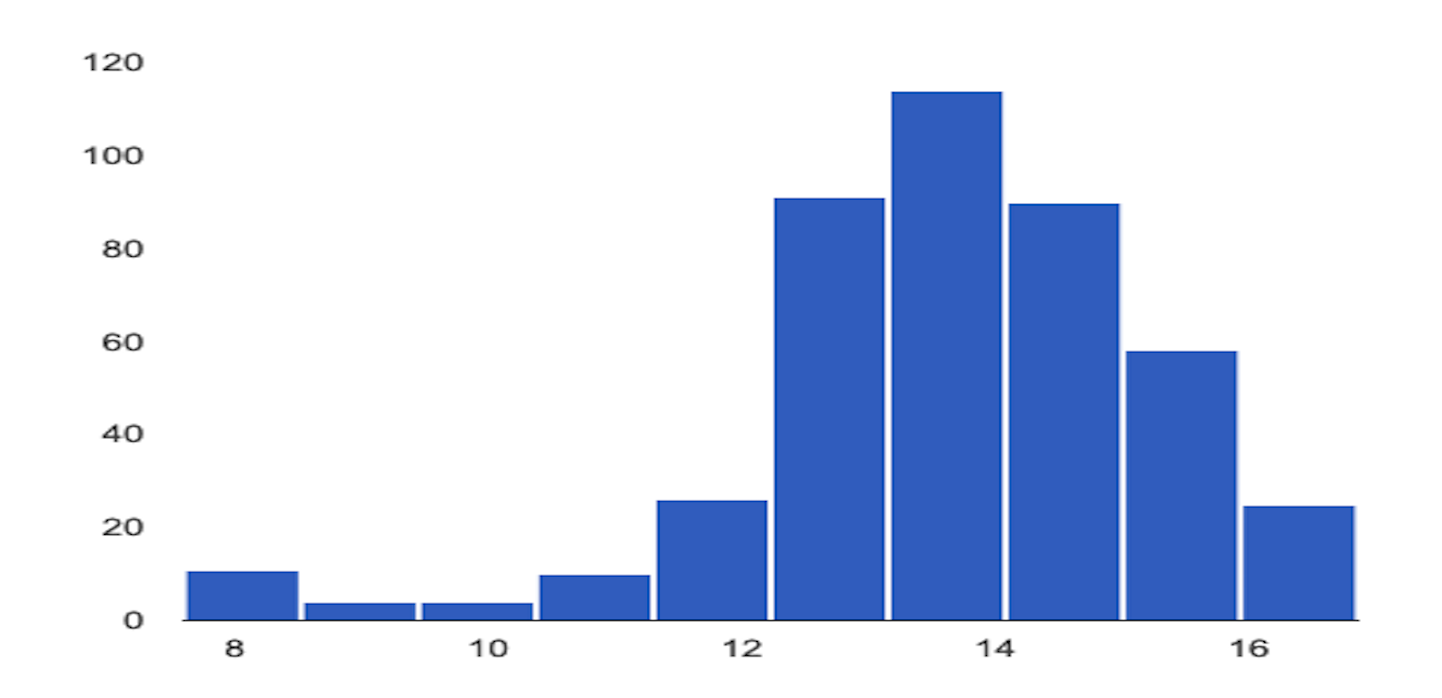
L'exemple suivant montre un décalage ou écart entre la distribution de référence et la dernière distribution d'une caractéristique numérique :
Distribution de référence
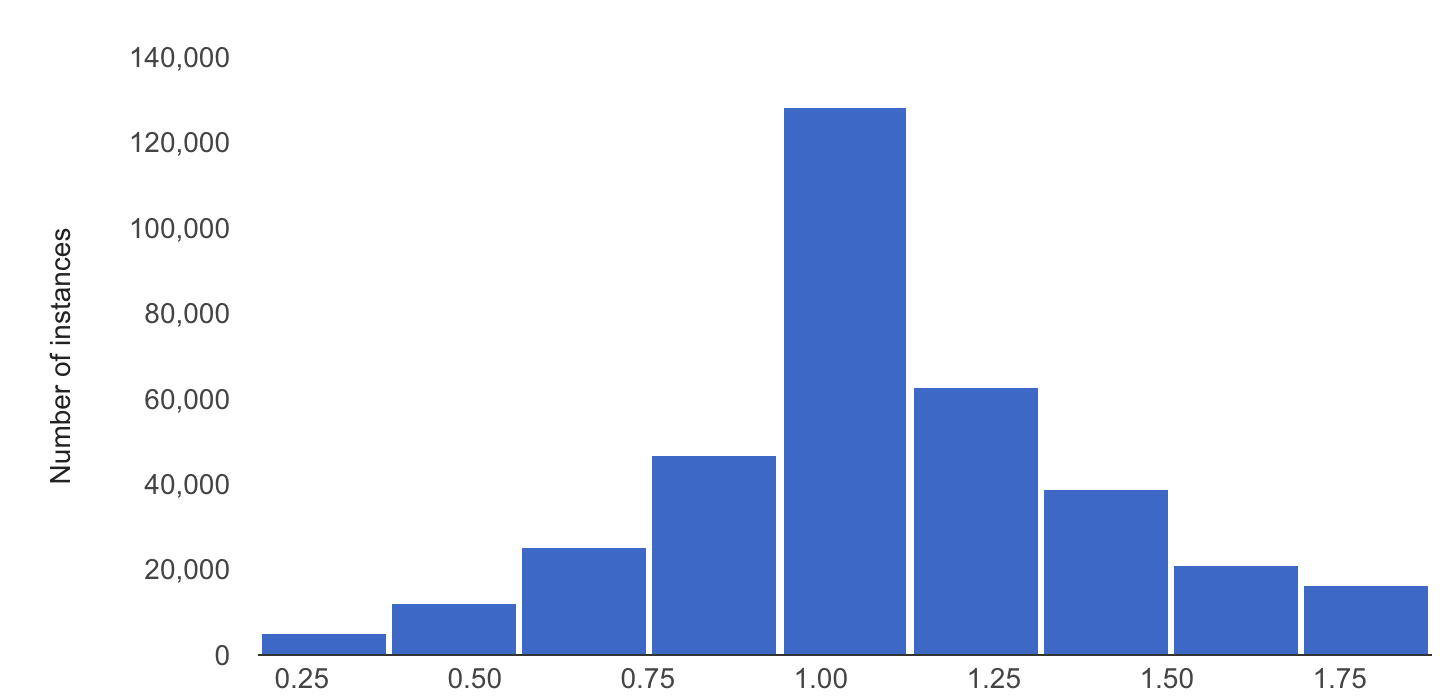
Dernière distribution
Éléments à prendre en compte lors de l'utilisation de la surveillance des modèles
Pour plus de rentabilité, vous pouvez définir un taux d'échantillonnage des requêtes d'inférence pour surveiller un sous-ensemble d'entrées de production d'un modèle.
Vous pouvez définir une fréquence à laquelle les entrées récemment enregistrées d'un modèle déployé sont surveillées pour détecter tout écart ou décalage. La fréquence de surveillance détermine la période, ou taille de la fenêtre de surveillance, des données journalisées analysées à chaque exécution de la surveillance.
Vous pouvez spécifier des seuils d'alerte pour chaque fonctionnalité que vous souhaitez surveiller. Une alerte est consignée lorsque la distance statistique entre la distribution des caractéristiques d'entrée et la référence correspondante dépasse le seuil spécifié. Par défaut, chaque caractéristique catégorielle et numérique est surveillée, avec des valeurs de seuil de 0.3.
Un point de terminaison d'inférence en ligne peut héberger plusieurs modèles. Lorsque vous activez la détection d'écart ou de décalage sur un point de terminaison, les paramètres de configuration suivants sont partagés sur tous les modèles hébergés sur ce point de terminaison :
- Type de détection
- Fréquence de surveillance
- Fraction des requêtes d'entrée surveillées
Pour les autres paramètres de configuration, vous pouvez définir des valeurs différentes pour chaque modèle.