A pesquisa vetorial é um mecanismo de pesquisa vetorial poderoso criado com a tecnologia inovadora desenvolvida pelo Google Research. Aproveitando o algoritmo ScaNN, a Pesquisa vetorial permite criar sistemas de pesquisa e recomendação de última geração, além de aplicativos de IA generativa.
Você pode aproveitar a mesma pesquisa e tecnologia que impulsionam os principais produtos do Google, incluindo a Pesquisa Google, o YouTube e o Google Play. Isso significa que você tem a escalabilidade, a disponibilidade e o desempenho necessários para processar conjuntos de dados massivos e gerar resultados extremamente rápidos em escala global. Com a pesquisa vetorial, você tem uma solução empresarial para implementar recursos de pesquisa semântica de última geração nos seus próprios aplicativos.

|

|

Infinite Fleurs: descubra a criatividade assistida por IA em toda a sua plenitude |

|
Primeiros passos
Demonstração interativa do Vector Search: confira a demonstração ao vivo para conferir um exemplo realista do que a tecnologia de pesquisa vetorial pode fazer e começar a usar o Vector Search.
Guia de início rápido da Pesquisa de vetor: teste a Pesquisa de vetor em 30 minutos criando, implantando e consultando um índice de pesquisa de vetor usando um conjunto de dados de exemplo. Este tutorial aborda a configuração, a preparação de dados, a criação de índices, a implantação, a consulta e a limpeza.
Antes de começar: prepare as embeddings escolhendo e treinando um modelo e preparando os dados. Em seguida, escolha um endpoint público ou privado para implantar o índice de consulta.
Preços e calculadora de preços da Pesquisa Vetorial: os preços da Pesquisa Vetorial incluem o custo das máquinas virtuais usadas para hospedar índices implantados, além das despesas de criação e atualização de índices. Mesmo uma configuração mínima (menos de US $100 por mês) pode acomodar um alto rendimento para casos de uso de tamanho moderado. Para estimar seus custos mensais:
- Acesse a calculadora de preços do Google Cloud.
- Clique em Adicionar à estimativa.
- Pesquise a Vertex AI.
- Clique no botão Vertex AI.
- Escolha Vertex AI Vector Search no menu suspenso Tipo de serviço.
- Mantenha as configurações padrão ou defina as suas. O custo estimado por mês é mostrado no painel Detalhes do custo.
Documentação
Gerenciar índices e endpoints
Tópicos avançados
Casos de uso e blogs
A tecnologia de pesquisa vetorial está se tornando um hub central para empresas que usam IA. Assim como os bancos de dados relacionais funcionam em sistemas de TI, ele conecta vários elementos de negócios, como documentos, conteúdo, produtos, usuários, eventos e outras entidades com base na relevância. Além de pesquisar mídias convencionais, como documentos e imagens, o Vector Search também pode gerar recomendações inteligentes, associar problemas de negócios a soluções e até vincular sinais de IoT a alertas de monitoramento. É uma ferramenta versátil e essencial para navegar pelo cenário crescente de dados corporativos com tecnologia de IA.
|
Pesquisa / Recuperação de informações
Sistemas |
Como a pesquisa vetorial da Vertex AI ajuda a desbloquear apps de IA generativa de alto desempenho: A pesquisa vetorial alimenta diversos aplicativos, incluindo e-commerce, sistemas RAG e mecanismos de recomendação, além de chatbots, pesquisa multimodal e muito mais. A pesquisa híbrida melhora ainda mais os resultados para termos de nicho. Clientes como Bloomreach, eBay e Mercado Livre usam a Vertex AI por causa da performance, escalabilidade e custo-benefício, alcançando benefícios como pesquisa mais rápida e mais conversões. O eBay usa a Pesquisa de vetores para recomendações: Destaca como o eBay usa a Pesquisa de vetores para o sistema de recomendação. Essa tecnologia permite que o eBay encontre produtos semelhantes no catálogo extenso, melhorando a experiência do usuário. O Mercari usa a tecnologia de pesquisa de vetor do Google para criar um novo mercado: Explica como o Mercari usa a pesquisa de vetor para melhorar a nova plataforma de mercado. A pesquisa de vetores é o recurso que gera as recomendações da plataforma, ajudando os usuários a encontrar produtos relevantes com mais eficiência. Embeddings da Vertex AI para texto: embasamento de LLMs facilitado:se concentra em embasamento de LLMs usando embeddings da Vertex AI para dados de texto. A pesquisa vetorial desempenha um papel importante na busca de trechos de texto relevantes que garantem que as respostas do modelo sejam baseadas em informações factuais. O que é a pesquisa multimodal: "LLMs com visão" mudam os negócios: Discute a pesquisa multimodal, que combina LLMs com compreensão visual. Ele explica como a Pesquisa vetorial processa e compara dados de texto e imagem, permitindo experiências de pesquisa mais abrangentes. Ative a pesquisa multimodal em grande escala: combine texto e imagem com a Vertex AI:descreve como criar um mecanismo de pesquisa multimodal com a Vertex AI que combina a pesquisa de texto e de imagem usando um método de conjunto de classificação recíproca ponderada. Isso melhora a experiência do usuário e oferece resultados mais relevantes. Como dimensionar a recuperação profunda com os recomendadores do TensorFlow e a Pesquisa Vetorial: explica como criar um sistema de recomendação de playlists usando os recomendadores do TensorFlow e a Pesquisa Vetorial, cobrindo modelos de recuperação profunda, treinamento, implantação e dimensionamento. |
|
IA generativa: recuperação para RAG e agentes |
Vertex AI e Denodo desbloqueiam dados corporativos com a IA generativa: mostra como a integração da Vertex AI com o Denodo permite que as empresas usem a IA generativa para gerar insights com base nos dados. A pesquisa de vetor é fundamental para acessar e analisar dados relevantes de maneira eficiente em um ambiente empresarial. Natureza infinita e a natureza dos setores: essa demonstração "selvagem" mostra as diversas possibilidades da IA: mostra uma demonstração que ilustra o potencial da IA em diferentes setores. Ele usa a pesquisa vetorial para oferecer recomendações generativas e pesquisa semântica multimodal. Infinite Fleurs: descubra a criatividade assistida por IA em toda a sua plenitude: O Infinite Fleurs do Google, um experimento de IA que usa a pesquisa por vetor, modelos Gemini e Imagen, gera buquês de flores exclusivos com base nas solicitações do usuário. Essa tecnologia mostra o potencial da IA para inspirar a criatividade em vários setores. LlamaIndex para RAG no Google Cloud: descreve como usar o LlamaIndex para facilitar a geração aumentada de recuperação (RAG) com modelos de linguagem grandes. O LlamaIndex usa a pesquisa vetorial para extrair informações relevantes de uma base de conhecimento, resultando em respostas mais precisas e adequadas ao contexto. RAG e endereçamento na Vertex AI: examina a RAG e as técnicas de endereçamento na Vertex AI. A pesquisa vetorial ajuda a identificar informações de base relevantes durante a recuperação, o que torna o conteúdo gerado mais preciso e confiável. Vector Search no LangChain:oferece um guia para usar a Vector Search com o LangChain para criar e implantar um índice de banco de dados de vetores para dados de texto, incluindo respostas a perguntas e processamento de PDFs. |
|
BI, análise de dados, monitoramento e muito mais |
Como ativar a IA em tempo real com a ingestão de streaming na Vertex AI: analisa a atualização de streaming na pesquisa de vetor e como ela oferece recursos de IA em tempo real. Essa tecnologia permite o processamento e a análise em tempo real dos fluxos de dados recebidos. |
Recursos relacionados
Você pode usar os seguintes recursos para começar a usar a pesquisa vetorial:
Notebooks e soluções

|

|
|
Introdução à pesquisa vetorial da Vertex AI:oferece uma visão geral da pesquisa vetorial. Ele foi desenvolvido para usuários iniciantes na plataforma que querem começar a usar rapidamente. |
Introdução aos embeddings de texto e à pesquisa vetorial:apresenta embeddings de texto e a pesquisa vetorial. Ele explica como essas tecnologias funcionam e como elas podem ser usadas para melhorar os resultados da pesquisa. |

|

|
|
Combinando pesquisa semântica e de palavras-chave: um tutorial de pesquisa híbrida com a pesquisa vetorial da Vertex AI: fornece instruções sobre como usar a pesquisa vetorial para pesquisa híbrida. Ele aborda as etapas envolvidas na configuração de um sistema de pesquisa híbrida. |
Mecanismo de RAG da Vertex AI com a Pesquisa Vetorial:explora o uso do mecanismo de RAG da Vertex AI com a Pesquisa Vetorial. Ele discute os benefícios de usar essas duas tecnologias juntas e fornece exemplos de como elas podem ser usadas em aplicativos reais. |

|
|
|
Infraestrutura para um aplicativo de IA generativa com capacidade de RAG usando a Vertex AI e a Vector Search:detalha a arquitetura para criar um aplicativo de IA generativa e RAG usando a Vector Search, o Cloud Run e o Cloud Storage, cobrindo casos de uso, escolhas de design e principais considerações. |
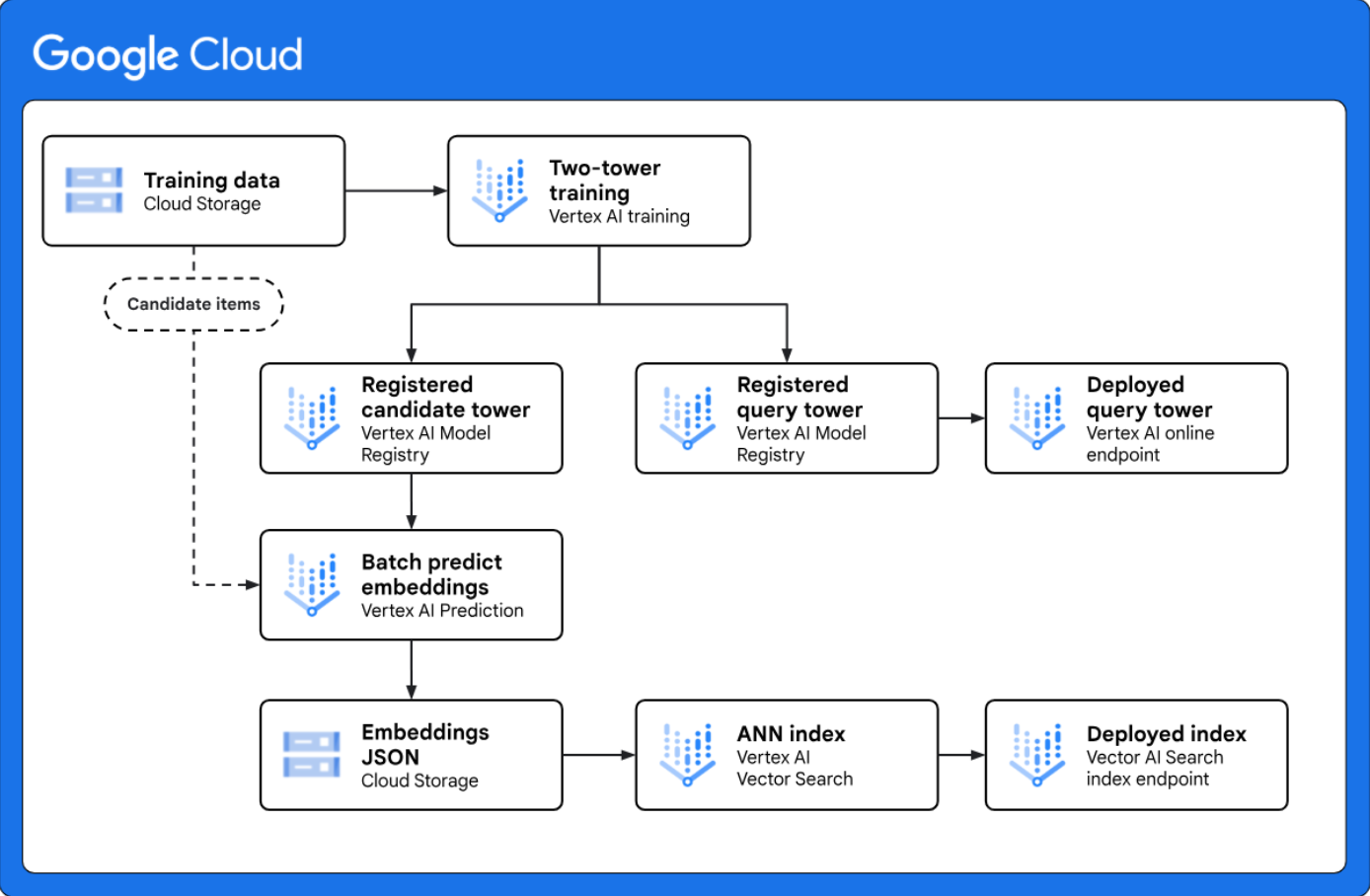
<p"> Implementar a recuperação de duas torres para geração de candidatos em grande escala:fornece uma arquitetura de referência que mostra como implementar um fluxo de trabalho de geração de candidatos de duas torres completo com a Vertex AI. O modelo de duas torres é uma técnica de recuperação poderosa para casos de uso de personalização, porque aprende a semelhança semântica entre duas entidades diferentes, como consultas da Web e itens candidatos. </p"> |
Treinamento
Introdução à pesquisa vetorial e aos embeddings A pesquisa vetorial é usada para encontrar itens semelhantes ou relacionados. Ele pode ser usado para recomendações, pesquisa, chatbots e classificação de texto. O processo envolve a criação de embeddings, o upload deles para Google Cloude a indexação para consulta. Este laboratório se concentra em embeddings de texto usando a Vertex AI, mas os embeddings podem ser gerados para outros tipos de dados.
Pesquisa vetorial e embeddings Este curso apresenta a Pesquisa vetorial e descreve como ela pode ser usada para criar um aplicativo de pesquisa com APIs de modelo de linguagem grande (LLM) para embeddings. O curso é composto de aulas conceituais sobre pesquisa vetorial e embeddings de texto, demonstrações práticas de como criar pesquisas vetoriais na Vertex AI e um laboratório prático.
Como entender e aplicar embeddings de texto
A API Embeddings da Vertex AI gera embeddings de texto, que são
representações numéricas de texto usadas para tarefas como identificar itens semelhantes.
Neste curso, você vai usar embeddings de texto para tarefas como classificação e pesquisa semântica e combinar a pesquisa semântica com LLMs para criar sistemas de resposta a perguntas usando a Vertex AI.
Curso intensivo de aprendizado de máquina: embeddings Este curso apresenta embeddings de palavras, contrastando-as com representações esparsas. Ele explora métodos para conseguir embeddings e diferencia embeddings estáticos e contextuais.
Produtos relacionados
Incorporações da Vertex AI Fornece uma visão geral da API Embeddings. Casos de uso de embedding de texto e multimodal, além de links para outros recursos e serviços Google Cloud relacionados.
API de classificação de aplicativos de IA A API de classificação classifica novamente os documentos com base na relevância de uma consulta usando um modelo de linguagem pré-treinado, fornecendo pontuações precisas. É ideal para melhorar os resultados da pesquisa de várias fontes, incluindo a Pesquisa vetorial.
Vertex AI Feature Store Permite gerenciar e disponibilizar dados de recursos usando o BigQuery como fonte de dados. Ele provisiona recursos para a disponibilização on-line, atuando como uma camada de metadados para disponibilizar os valores de recursos mais recentes diretamente do BigQuery. O Feature Store permite a recuperação instantânea de valores de recursos para os itens que a Vector Store retornou para consultas.
Vertex AI Pipelines O Vertex AI Pipelines permite a automação, o monitoramento e a governança dos seus sistemas de ML de forma serverless, orquestrando fluxos de trabalho de ML com pipelines de ML. É possível executar pipelines de ML definidos usando o Kubeflow Pipelines ou o framework do TensorFlow Extended (TFX) em lotes. Os pipelines permitem criar pipelines automatizados para gerar incorporações, criar e atualizar índices de pesquisa de vetores e formar uma configuração de MLOps para sistemas de pesquisa e recomendação de produção.
Recursos de análise detalhada
Como melhorar seu caso de uso de IA generativa com embeddings e tipos de tarefas da Vertex AI Foca na melhoria de aplicativos de IA generativa usando embeddings e tipos de tarefas da Vertex AI. A pesquisa vetorial pode ser usada com embeddings de tipo de tarefa para melhorar o contexto e a precisão do conteúdo gerado, encontrando informações mais relevantes.
TensorFlow Recommenders Uma biblioteca de código aberto para criar sistemas de recomendação. Ele simplifica o processo de preparação de dados até a implantação e oferece suporte à criação de modelos flexíveis. O TFRS oferece tutoriais e recursos e permite a criação de modelos de recomendação sofisticados.
TensorFlow Ranking O TensorFlow Ranking é uma biblioteca de código aberto para criar modelos neurais de aprendizado para classificação (LTR, na sigla em inglês) escalonáveis. Ele oferece suporte a várias funções de perda e métricas de classificação, com aplicações em pesquisa, recomendação e outros campos. A biblioteca é desenvolvida ativamente pela IA do Google.
Anúncio do ScaNN: uma pesquisa eficiente de similaridade vetorial O ScaNN do Google, um algoritmo para pesquisa eficiente de similaridade vetorial, utiliza uma técnica inovadora para melhorar a precisão e a velocidade na busca de vizinhos mais próximos. Ele supera os métodos atuais e tem amplas aplicações em tarefas de aprendizado de máquina que exigem pesquisa semântica. Os esforços de pesquisa do Google abrangem várias áreas, incluindo o ML básico e os impactos sociais da IA.
SOAR: novos algoritmos para uma pesquisa vetorial ainda mais rápida com o ScaNN O algoritmo SOAR do Google melhora a eficiência da pesquisa vetorial com a introdução de redundância controlada, permitindo pesquisas mais rápidas com índices menores. O SOAR atribui vetores a vários clusters, criando caminhos de pesquisa "backup" para melhorar o desempenho.
Vídeos relacionados
Começar a usar a pesquisa de vetores com a Vertex AI
A Pesquisa Vetorial é uma ferramenta poderosa para criar aplicativos com tecnologia de IA. Este vídeo apresenta a tecnologia e oferece um guia explicativo para começar.
Saiba mais sobre a pesquisa híbrida com a pesquisa vetorial
A pesquisa vetorial pode ser usada para pesquisa híbrida, permitindo combinar a potência da pesquisa vetorial com a flexibilidade e a velocidade de um mecanismo de pesquisa convencional. Este vídeo apresenta a pesquisa híbrida e mostra como usar a Pesquisa vetorial para esse tipo de pesquisa.
Você já está usando a Pesquisa Vetorial! Como ser um especialista
Você sabia que provavelmente usa a pesquisa vetorial todos os dias sem perceber? Seja para encontrar um produto nas redes sociais ou descobrir uma música que está na sua cabeça, a pesquisa vetorial é a magia da IA por trás dessas experiências cotidianas.
A nova incorporação de "tipo de tarefa" da equipe do DeepMind melhora a qualidade da pesquisa de RAG
Melhore a precisão e a relevância dos seus sistemas de RAG com novos embeddings de tipo de tarefa desenvolvidos pela equipe do Google DeepMind. Assista e saiba mais sobre os desafios comuns na qualidade da pesquisa RAG e como as embeddings de tipo de tarefa podem superar a lacuna semântica entre perguntas e respostas, o que resulta em recuperação mais eficaz e desempenho aprimorado da RAG.
Terminologia de pesquisa de vetor
Esta lista contém algumas terminologias importantes que você precisa entender para usar a Pesquisa de vetor:
Vetor: um vetor é uma lista de valores flutuantes com magnitude e direção. Ele pode ser usado para representar qualquer tipo de dados, como números, pontos no espaço e direções.
Embedding: um embedding é um tipo de vetor usado para representar dados de uma forma que captura o significado semântico deles. Geralmente, os embeddings são criados com técnicas de machine learning e costumam ser usados no processamento de linguagem natural (PLN) e em outros aplicativos de machine learning.
Embeddings densos: representam o significado semântico do texto, usando matrizes que contêm principalmente valores diferentes de zero. Com embeddings densos, resultados de pesquisa semelhantes podem ser retornados com base na semelhança semântica.
Embeddings esparsos: representam a sintaxe de texto, usando matrizes de alta dimensão que contêm pouquíssimos valores diferentes de zero em comparação a embeddings densos. Os embeddings esparsos são frequentemente usados para pesquisas de palavras-chave.
Pesquisa híbrida: usam embeddings densos e esparsos, permitindo pesquisar com base em uma combinação de pesquisa por palavra-chave e pesquisa semântica. A pesquisa vetorial oferece suporte a pesquisas baseadas em embeddings densos, embeddings esparsos e pesquisa híbrida.
Índice: um conjunto de vetores implantados juntos para a pesquisa por similaridade. Os vetores podem ser adicionados ou removidos de um índice. As consultas de pesquisa por similaridade são emitidas para um índice específico e pesquisam os vetores dele.
Informações empíricas: termo que se refere à verificação da precisão do aprendizado de máquina em relação ao mundo real, como um conjunto de dados de informações empíricas.
Recall: a porcentagem de vizinhos mais próximos retornados pelo índice que são vizinhos mais próximos reais. Por exemplo, se uma consulta de vizinho mais próxima de 20 vizinhos mais próximos retornou 19 dos vizinhos mais próximos, o recall será de 19/20x100 = 95%.
Restringir: recurso que limita as pesquisas a um subconjunto do índice usando regras booleanas. A restrição também é chamada de "filtro". Com a Pesquisa vetorial, você pode usar a filtragem numérica e a filtragem de atributos de texto.