A pesquisa vetorial oferece suporte à pesquisa híbrida, um padrão de arquitetura conhecido na recuperação de informações (IR, na sigla em inglês) que combina pesquisa semântica e pesquisa por palavra-chave (também chamada de pesquisa baseada em token). Com a pesquisa híbrida, os desenvolvedores podem aproveitar o melhor das duas abordagens, oferecendo uma qualidade de pesquisa superior.
Nesta página, explicamos os conceitos de pesquisa híbrida, semântica e baseada em token e apresentamos exemplos de como configurar a pesquisa híbrida e baseada em token:
- Por que a pesquisa híbrida é importante?
- Exemplo: como usar a pesquisa baseada em tokens
- Exemplo: como usar a pesquisa híbrida
- Começar a usar a pesquisa híbrida
- Outros conceitos
Por que a pesquisa híbrida é importante?
Conforme descrito na Visão geral da pesquisa vetorial, a pesquisa semântica com a Pesquisa vetorial pode encontrar itens com semelhança semântica usando consultas.
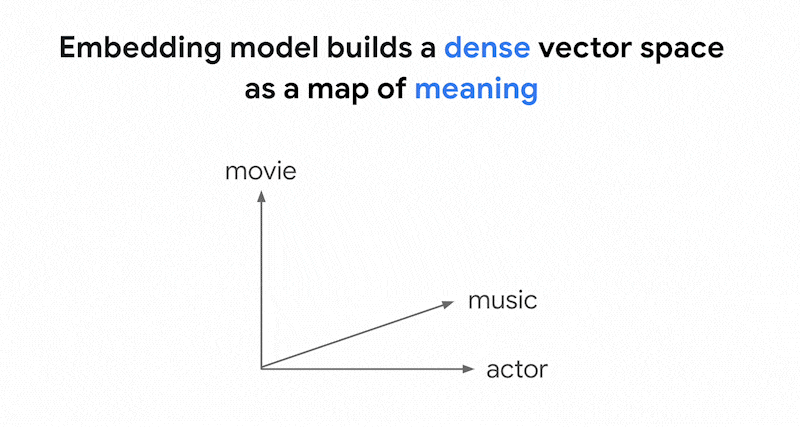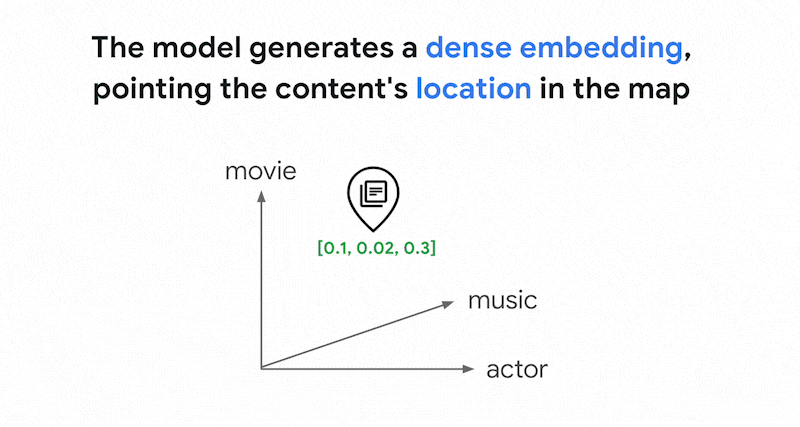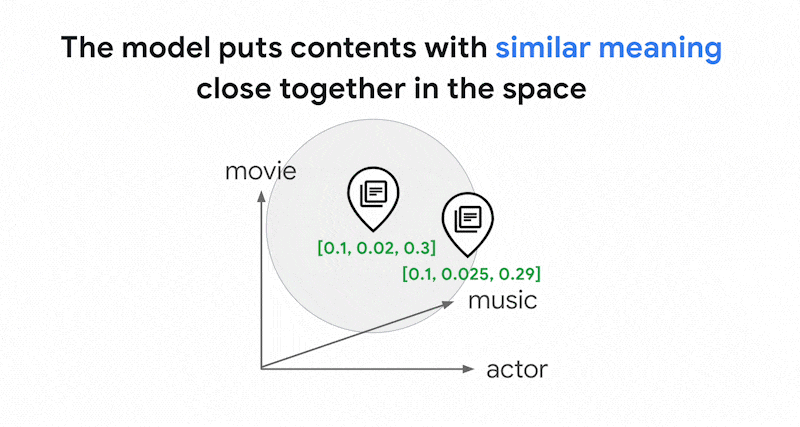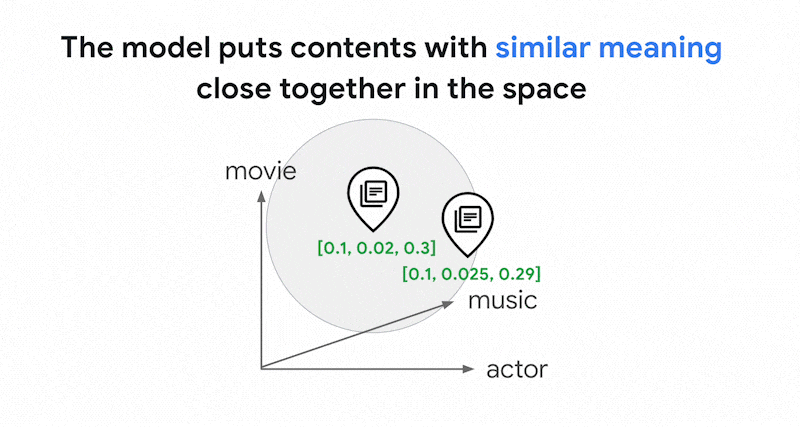
Os modelos de embedding, como os embeddings da Vertex AI, criam um espaço vetorial como um mapa de significados do conteúdo. Cada embedding de texto ou multimodal é um local no
mapa que representa o significado de algum conteúdo. Como exemplo simplificado, quando
um modelo de embedding usa um texto que discute filmes em 10%, música em 2% e
atores em 30%, ele pode representar esse texto com um embedding [0.1, 0.02,
0.3]. Com a pesquisa vetorial, você pode encontrar rapidamente outros embeddings na vizinhança. Essa pesquisa por significado do conteúdo é chamada de pesquisa semântica.
A pesquisa semântica com embeddings e a pesquisa vetorial podem ajudar a tornar os sistemas de TI tão inteligentes quanto bibliotecários experientes ou funcionários de lojas. Os embeddings podem ser usados para vincular diferentes dados de negócios aos significados deles. Por exemplo, consultas e resultados de pesquisa, textos e imagens, atividades do usuário e produtos recomendados, textos em inglês e em japonês ou dados de sensores e condições de alerta. Com essa capacidade, há uma grande variedade de casos de uso para embeddings.
Por que combinar a pesquisa semântica com a pesquisa baseada em palavras-chave?
A pesquisa semântica não abrange todos os requisitos possíveis para aplicativos de recuperação de informações, como a geração aumentada de recuperação (RAG). A pesquisa semântica só encontra dados que o modelo de embedding consegue entender. Por exemplo, consultas ou conjuntos de dados com números ou SKUs de produtos arbitrários, nomes de produtos novos que foram adicionados recentemente e nomes de código proprietários corporativos não funcionam com a pesquisa semântica porque não estão incluídos no conjunto de dados de treinamento do modelo de embedding. Esses dados são chamados de "fora do domínio".
Nesses casos, é necessário combinar a pesquisa semântica com a pesquisa baseada em palavras-chave (também chamada de baseada em token) para formar uma pesquisa híbrida. Com a pesquisa híbrida, você pode aproveitar a pesquisa semântica e baseada em tokens para melhorar a qualidade da pesquisa.
Um dos sistemas de pesquisa híbrida mais conhecidos é a Pesquisa Google. O serviço incorporou a pesquisa semântica em 2015 com o modelo RankBrain, além do algoritmo de pesquisa de palavras-chave baseado em tokens. Com a introdução da pesquisa híbrida, a Pesquisa Google conseguiu melhorar significativamente a qualidade das pesquisas ao atender aos dois requisitos: pesquisa por significado e pesquisa por palavra-chave.
No passado, criar um mecanismo de pesquisa híbrido era uma tarefa complexa. Assim como na Pesquisa Google, você precisa criar e operar dois tipos diferentes de mecanismos de pesquisa (pesquisa semântica e baseada em token) e mesclar e classificar os resultados. Com o suporte à pesquisa híbrida na pesquisa vetorial, você pode criar seu próprio sistema de pesquisa híbrida com um único índice da pesquisa vetorial, personalizado para atender às suas necessidades de negócios.
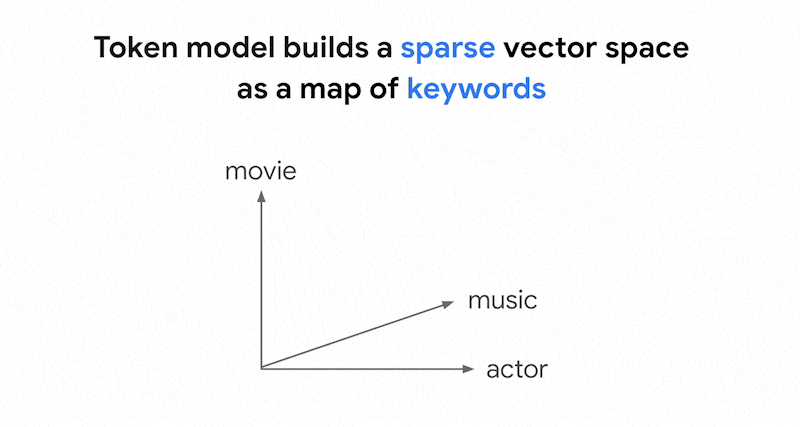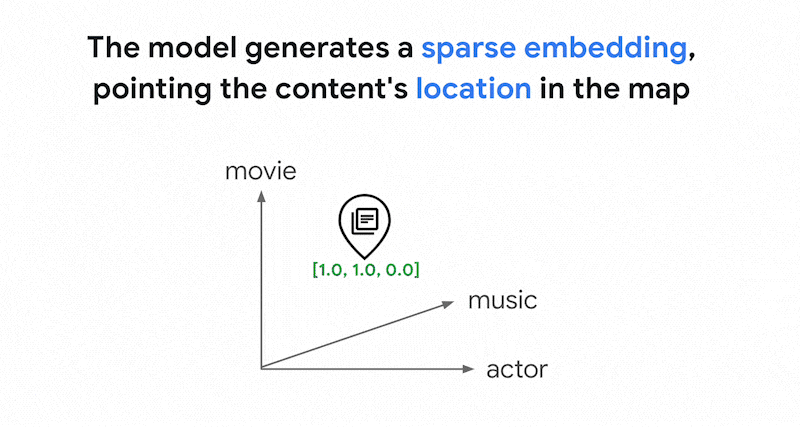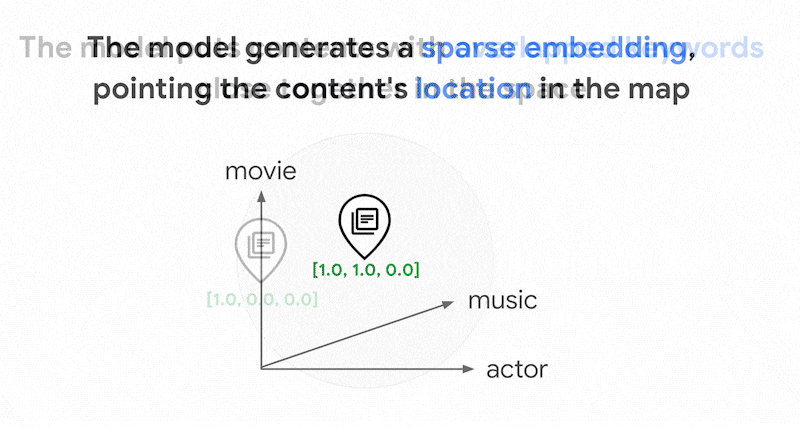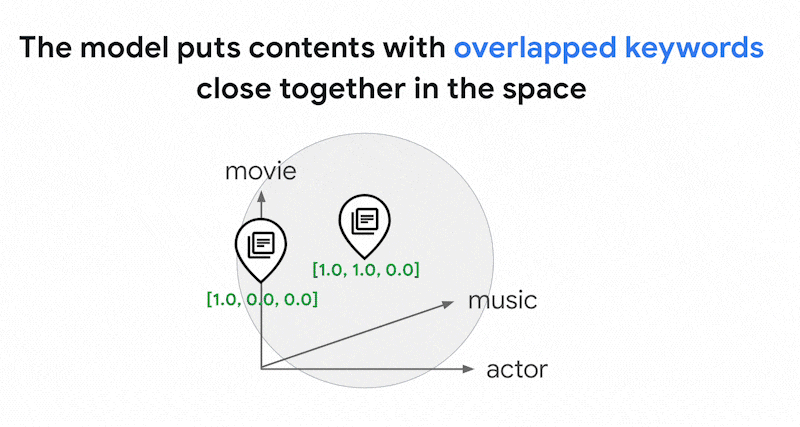
Como a pesquisa baseada em token funciona
Como funciona a pesquisa baseada em tokens na pesquisa vetorial? Depois de dividir o texto em tokens (como palavras ou subpalavras), é possível usar algoritmos de embedding esparsos conhecidos, como TF-IDF, BM25 ou SPLADE, para gerar embeddings esparsos para o texto.
Uma explicação simplificada de embeddings esparsos é que elas são vetores que representam quantas vezes cada palavra ou subpalavra aparece no texto. Os embeddings esparsos típicos não levam em conta a semântica do texto.

Podem haver milhares de palavras diferentes usadas nos textos. Assim, esse embedding geralmente tem dezenas de milhares de dimensões, com apenas algumas dimensões com valores diferentes de zero. É por isso que eles são chamados de "embeddings" "esparsos". A maioria dos valores é zero. Esse espaço de embedding esparso funciona como um mapa de palavras-chave, semelhante a um índice de livros.
Nesse espaço de embedding escasso, é possível encontrar embeddings semelhantes analisando a vizinhança de um embedding de consulta. Esses embeddings são semelhantes em termos de distribuição das palavras-chave usadas nos textos.
Esse é o mecanismo básico da pesquisa baseada em tokens com embeddings esparsos. Com a pesquisa híbrida na pesquisa vetorial, você pode misturar embeddings densos e esparsos em um único índice vetorial e executar consultas com embeddings densos, esparsos ou ambos. O resultado é uma combinação de pesquisa semântica e resultados de pesquisa baseados em tokens.
A pesquisa híbrida também oferece latência de consulta menor em comparação com um mecanismo de pesquisa baseado em token com um design de índice invertido. Assim como a pesquisa vetorial para pesquisa semântica, cada consulta com embeddings densos ou esparsos é concluída em milissegundos, mesmo com milhões ou bilhões de itens.
Exemplo: como usar a pesquisa baseada em tokens
Para explicar como usar a pesquisa baseada em tokens, as seções a seguir incluem exemplos de código que geram embeddings esparsos e criam um índice com eles na pesquisa vetorial.
Para testar este código de exemplo, use o notebook: Combinando pesquisa semântica e de palavras-chave: um tutorial de pesquisa híbrida com a pesquisa vetorial da Vertex AI
A primeira etapa é preparar um arquivo de dados para criar um índice de embeddings esparsos, com base no formato de dados descrito em Formato e estrutura de dados de entrada.
Em JSON, o arquivo de dados tem esta aparência:
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
Cada item precisa ter uma propriedade sparse_embedding com as propriedades values e
dimensions. Os embeddings esparsos têm milhares de dimensões com alguns valores diferentes de zero. Esse formato de dados funciona de maneira eficiente porque contém
os valores diferentes de zero apenas com as posições no espaço.
Preparar um conjunto de dados de amostra
Como exemplo, vamos usar o conjunto de dados Google Merch Shop, que tem cerca de 200 linhas de produtos da marca Google.
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
Preparar um vetorizador TF-IDF
Com esse conjunto de dados, vamos treinar um vetorizador, um modelo que gera embeddings esparsos a partir de um texto. Este exemplo usa o TfidfVectorizer no scikit-learn, que é um vetorizador básico que usa o algoritmo TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
A variável corpus contém uma lista dos 200 nomes de itens, como "Google
Sticker" ou "Chrome Dino Pin". Em seguida, o código os transmite ao vetorizador chamando a função fit_transform(). Com isso, o vetorizador fica pronto para
gerar embeddings esparsos.
O vetorizador TF-IDF tenta dar mais peso às palavras de assinatura no conjunto de dados (como "Shirts" ou "Dino") em comparação com palavras triviais (como "The", "a" ou "of") e conta quantas vezes essas palavras de assinatura são usadas no documento especificado. Cada valor de uma embedding esparsa representa uma frequência de cada palavra com base nas contagens. Para mais informações sobre o TF-IDF, consulte Como o TF-IDF e o TfidfVectorizer funcionam?.
Neste exemplo, usamos a tokenização básica de palavras e a vetorização TF-IDF para simplificar. No desenvolvimento de produção, você pode escolher qualquer outra opção de tokenização e vetorização para gerar embeddings esparsos com base nos seus requisitos. Em muitos casos, os tokenizers de subpalavras têm um bom desempenho em comparação com a tokenização de palavras e são escolhas populares. Para vetorizadores, o BM25 é conhecido como uma versão aprimorada do TF-IDF. SPLADE é outro algoritmo de vetorização conhecido que usa algumas semânticas para o embedding esparso.
Receber um embedding esparso
Para facilitar o uso do vetorizador com a pesquisa vetorial, vamos definir
uma função wrapper, get_sparse_embedding():
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
Essa função transmite o parâmetro "text" ao vetorizador para gerar um
embedding esparso. Em seguida, converta-o para o formato {"values": ...., "dimensions": ...}
mencionado anteriormente para criar um índice de pesquisa vetorial esparsa.
É possível testar essa função:
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
Isso vai gerar o seguinte embedding esparso:
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
Criar um arquivo de dados de entrada
Neste exemplo, vamos gerar embeddings esparsos para todos os 200 itens.
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
Este código gera a seguinte linha para cada item:
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
Em seguida, salve-os como um arquivo JSONL "items.json" e faça upload para um bucket do Cloud Storage.
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gsutil cp items.json $BUCKET_URI
Criar um índice de embeddings esparsos na pesquisa vetorial
Em seguida, vamos criar e implantar um índice de embedding escasso na pesquisa vetorial. Esse é o mesmo procedimento documentado no Guia de início rápido da pesquisa vetorial.
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
Para usar o índice, é preciso criar um endpoint de índice. Ele funciona como uma instância do servidor que aceita solicitações de consulta para o índice.
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
Com o endpoint do índice, implante o índice especificando um ID de índice implantado exclusivo.
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
Após a espera pela implantação, já podemos executar uma consulta de teste.
Executar uma consulta com um índice de embedding esparso
Para executar uma consulta com um índice de embedding esparso, é necessário criar um objeto HybridQuery
para encapsular o embedding esparso do texto da consulta, como no
exemplo abaixo:
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
Este código de exemplo usa o texto "Kids" para a consulta. Agora, execute uma consulta com o
objeto HybridQuery.
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
Isso vai gerar uma saída como esta:
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
Dos 200 itens, o resultado contém os nomes dos itens que têm a palavra-chave "Kids".
Exemplo: como usar a pesquisa híbrida
Este exemplo combina a pesquisa baseada em token com a semântica para criar uma pesquisa híbrida na pesquisa vetorial.
Como criar um índice híbrido
Para criar um índice híbrido, cada item precisa ter "embedding" (para embedding denso) e "sparse_embedding":
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
A função get_dense_embedding() usa a API Embedding da Vertex AI para gerar embedding de texto
com 768 dimensões. Isso gera embeddings densas e esparsas no
formato a seguir:
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
O restante do processo é o mesmo em Exemplo: como usar a pesquisa baseada em token: faça upload do arquivo JSONL para o bucket do Cloud Storage, crie um índice de pesquisa vetorial com o arquivo e implante o índice no endpoint de índice.
Executar uma consulta híbrida
Depois de implantar o índice híbrido, é possível executar uma consulta híbrida:
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
Para o texto da consulta "Kids", gere embeddings densos e esparsos para a
palavra e os encapsule no objeto HybridQuery. A diferença em relação ao
HybridQuery anterior são dois parâmetros adicionais: dense_embedding e
rrf_ranking_alpha.
Desta vez, vamos mostrar as distâncias de cada item:
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
Em cada objeto neighbor, há uma propriedade distance que tem a distância
entre a consulta e o item com o embedding denso e uma propriedade sparse_distance
que tem a distância com o embedding esparso. Esses valores são distâncias invertidas, então um valor maior significa uma distância menor.
Ao executar uma consulta com HybridQuery, você recebe o seguinte resultado:
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
Além dos resultados de pesquisa baseados em token que têm a palavra-chave "Kids", também há resultados de pesquisa semântica incluídos. Por exemplo, o item "Google White Classic Youth Tee" é incluído porque o modelo de embedding sabe que "Youth" e "Kids" são semanticamente semelhantes.
Para mesclar os resultados da pesquisa semântica e baseada em token, a pesquisa híbrida usa a
Fusão de classificação recíproca
(RRF, na sigla em inglês). Para mais
informações sobre a RRF e como especificar o parâmetro rrf_ranking_alpha, consulte O que é a Fusão de
classificação recíproca?.
Reclassificação
O RRF oferece uma maneira de mesclar a classificação dos resultados de pesquisa semântica e baseada em tokens. Em muitos sistemas de recuperação de informações de produção ou de recomendação, os resultados passam por outros algoritmos de classificação de precisão, o que é chamado de reclassificação. Com a combinação da recuperação rápida no nível de milissegundos com a pesquisa vetorial e a reclassificação precisa nos resultados, é possível criar sistemas de vários estágios que oferecem maior qualidade de pesquisa ou desempenho de recomendação.
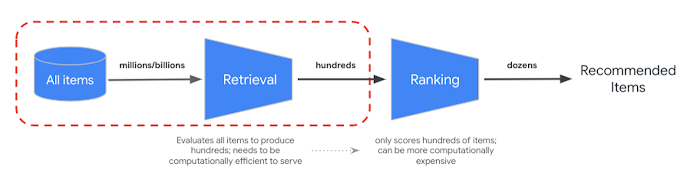
A API Ranking Vertex AI oferece uma maneira de implementar a classificação com base na relevância genérica entre o texto da consulta e os textos dos resultados da pesquisa com o modelo pré-treinado. O TensorFlow Ranking também oferece uma introdução sobre como projetar e treinar modelos de aprendizado de classificação (LTR) para reclassificação avançada que podem ser personalizados para vários requisitos de negócios.
Começar a usar a pesquisa híbrida
Os recursos a seguir podem ajudar você a começar a usar a pesquisa híbrida na pesquisa vetorial.
Recursos da pesquisa híbrida
- Combinando pesquisa semântica e palavras-chave: um tutorial de pesquisa híbrida com a pesquisa vetorial da Vertex AI: notebook de exemplo para começar a usar a pesquisa híbrida.
- Formato e estrutura de dados de entrada: formato de dados de entrada para criar um índice de embeddings esparsos.
- Consultar o índice público para encontrar os vizinhos mais próximos: como executar consultas com a pesquisa híbrida.
- A fusão de classificação recíproca supera o Condorcet e métodos individuais de aprendizagem de classificação: discussão do algoritmo RRF
Recursos da pesquisa vetorial
Outros conceitos
As seções a seguir descrevem TF-IDF e TfidVectorizer, Fusão de classificação recíproca e o parâmetro alfa de maneira mais detalhada.
Como o TF-IDF e o TfidfVectorizer funcionam?
A função fit_transform() executa dois processos importantes do algoritmo TF-IDF:
Fit: o vetorizador calcula a frequência inversa do documento (IDF, na sigla em inglês) para cada termo no vocabulário. O IDF reflete a importância de um termo em todo o corpus. Termos raros têm notas de IDF mais altas:
IDF(t) = log_e(Total number of documents / Number of documents containing term t)Transformar:
- Tokenização: divide os documentos em termos individuais (palavras ou frases).
Cálculo da frequência de termos (TF): conta quantas vezes cada termo aparece em cada documento com:
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)Cálculo de TF-IDF: combina o TF de cada termo com o IDF pré-calculado para criar uma pontuação de TF-IDF. Essa pontuação representa a importância de um termo em um documento específico em relação a todo o corpus.
TF-IDF(t, d) = TF(t, d) * IDF(t)O vetorizador TF-IDF tenta dar mais peso às palavras de assinatura no conjunto de dados, como "Shirts" ou "Dino", em comparação com palavras triviais, como "The", "a" ou "of", e conta quantas vezes essas palavras de assinatura são usadas no documento especificado. Cada valor de um embedding esparso representa uma frequência de cada palavra com base nas contagens.
O que é a Fusão de classificação recíproca?
Para mesclar os resultados da pesquisa semântica e a baseada em tokens, a pesquisa híbrida usa a Fusão de classificação recíproca (RRF, na sigla em inglês). A RRF é um algoritmo para combinar várias listas de itens classificados em uma única classificação unificada. É uma técnica conhecida para mesclar resultados de pesquisa de diferentes fontes ou métodos de recuperação, especialmente em sistemas de pesquisa híbridos e modelos de linguagem grandes.
No caso da pesquisa híbrida da pesquisa vetorial, a distância densa e a distância esparsa são medidas em espaços diferentes e não podem ser comparadas diretamente. Assim, a RRF funciona de maneira eficaz para mesclar e classificar os resultados dos dois espaços diferentes.
Confira como a RRF funciona:
- Classificação recíproca: para cada item em uma lista classificada, calcule a classificação recíproca. Isso significa tomar o inverso da posição (classificação) do item na lista. Por exemplo, o item classificado como número um recebe uma classificação recíproca de 1/1 = 1, e o item classificado como número dois recebe 1/2 = 0,5.
- Soma de classificações recíprocas: some as classificações recíprocas de cada item em todas as listas classificadas. Isso gera uma pontuação final para cada item.
- Ordenar por pontuação final: ordena os itens pela pontuação final em ordem decrescente. Os itens com as pontuações mais altas são considerados os mais relevantes ou importantes.
Em resumo, os itens com classificações mais altas em resultados densos e esparsos são exibidos na parte de cima da lista. Assim, o item "Google Blue Kids Sunglasses" fica no topo porque tem classificações mais altas nos resultados de pesquisa densa e esparsa. Itens como "Google White Classic Youth Tee" têm classificação baixa porque têm classificação apenas no resultado de pesquisa densa.
Como o parâmetro alfa se comporta
O exemplo de como usar a pesquisa híbrida define o parâmetro rrf_ranking_alpha
como 0,5 ao criar o objeto HybridQuery. É possível especificar um peso na
classificação dos resultados de pesquisa densa e esparsa usando os seguintes valores para
rrf_ranking_alpha:
1ou não especificado: a pesquisa híbrida usa apenas resultados de pesquisa densa e ignora resultados de pesquisa esparsa.0: a pesquisa híbrida usa apenas resultados da pesquisa esparsa e ignora resultados da pesquisa densa.0a1: a pesquisa híbrida mescla os resultados densos e esparsos com o peso especificado pelo valor. 0,5 significa que eles serão mesclados com o mesmo peso.