Vertex AI Pipelines è un servizio gestito che ti aiuta a creare, eseguire il deployment e gestire flussi di lavoro di machine learning (ML) end-to-end sulla piattaforma Google Cloud. Fornisce un ambiente serverless per l'esecuzione delle pipeline, in modo da non doverti preoccupare della gestione dell'infrastruttura.
In questo tutorial utilizzerai Vertex AI Pipelines per eseguire un job di addestramento personalizzato e per eseguire il deployment del modello addestrato in Vertex AI, in un ambiente di rete ibrida.
L'intera procedura richiede 2-3 ore, inclusi circa 50 minuti per l'esecuzione della pipeline.
Questo tutorial è destinato ad amministratori di rete aziendali, data scientist e ricercatori che hanno familiarità con Vertex AI, Virtual Private Cloud (VPC), la console Google Cloud e Cloud Shell. La familiarità con Vertex AI Workbench è utile, ma non obbligatoria.
Obiettivi
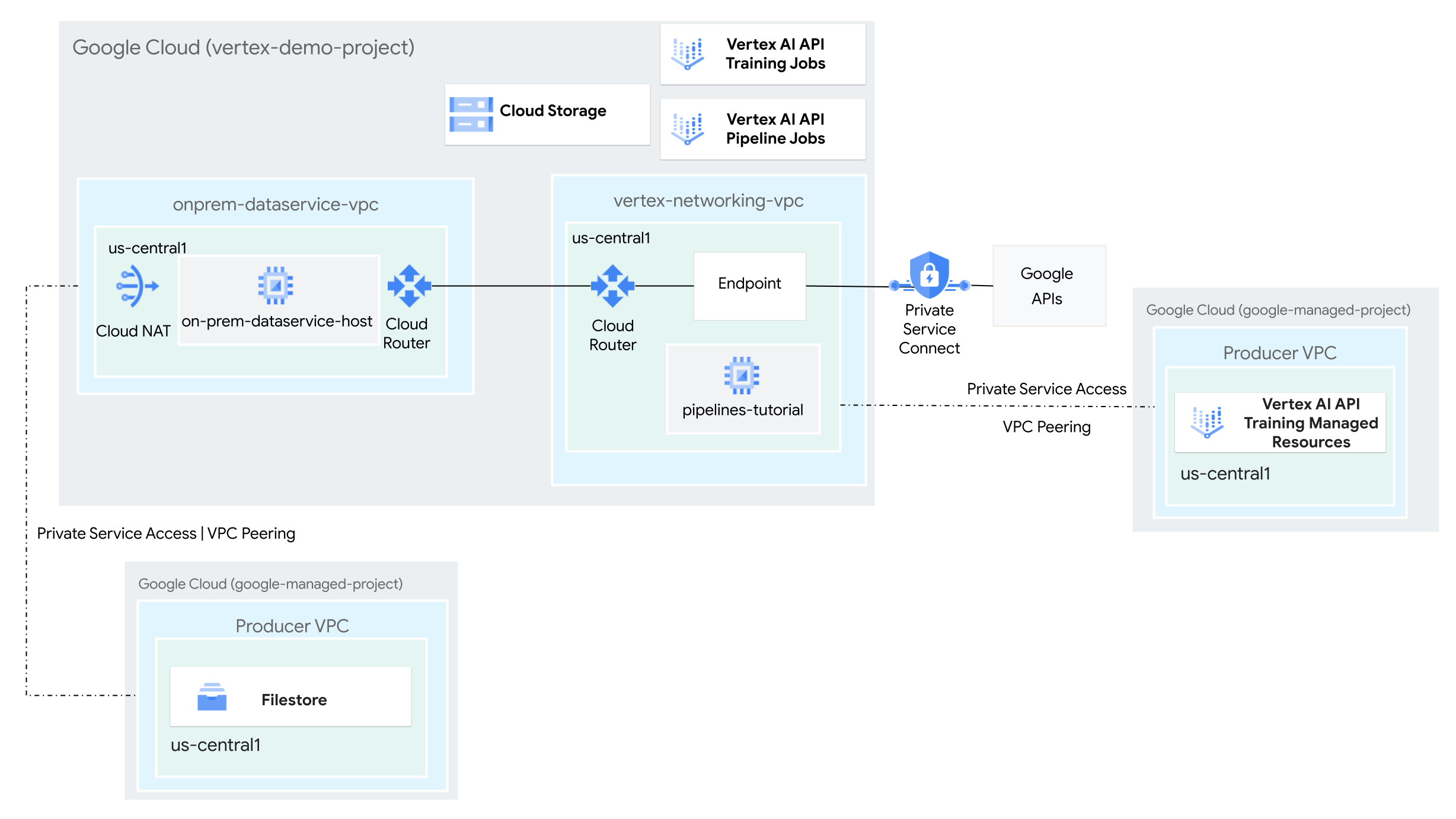
- Crea due reti Virtual Private Cloud (VPC):
- Uno (
vertex-networking-vpc) serve per utilizzare l'API Vertex AI Pipelines per creare e ospitare un modello di pipeline per l'addestramento di un modello di machine learning e il suo deployment in un endpoint. - L'altro (
onprem-dataservice-vpc) rappresenta una rete on-premise.
- Uno (
- Connetti le due reti VPC nel seguente modo:
- Esegui il deployment di gateway VPN ad alta disponibilità, tunnel Cloud VPN e router Cloud per connettere
vertex-networking-vpceonprem-dataservice-vpc. - Crea un endpoint Private Service Connect (PSC) per inoltrare richieste private all'API REST di Vertex AI Pipelines.
- Configura un annuncio di route personalizzato del router Cloud in
vertex-networking-vpcper annunciare le route per l'endpoint Private Service Connect aonprem-dataservice-vpc.
- Esegui il deployment di gateway VPN ad alta disponibilità, tunnel Cloud VPN e router Cloud per connettere
- Crea un'istanza Filestore nella rete VPC
onprem-dataservice-vpce aggiungi i dati di addestramento in una condivisione NFS. - Crea un'applicazione del pacchetto Python per il job di addestramento.
- Crea un modello di job Vertex AI Pipelines per eseguire le seguenti operazioni:
- Crea ed esegui il job di addestramento sui dati della condivisione NFS.
- Importa il modello addestrato e caricalo in Vertex AI Model Registry.
- Crea un endpoint Vertex AI per le previsioni online.
- Esegui il deployment del modello sull'endpoint.
- Carica il modello di pipeline in un repository Artifact Registry.
- Utilizza l'API REST di Vertex AI Pipelines per attivare l'esecuzione di una pipeline da
un host del servizio dati on-premise (
on-prem-dataservice-host).
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Al termine delle attività descritte in questo documento, puoi evitare l'addebito di ulteriori costi eliminando le risorse che hai creato. Per ulteriori informazioni, vedi Pulizia.
Prima di iniziare
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- Apri Cloud Shell per eseguire i comandi elencati in questo tutorial. Cloud Shell è un ambiente shell interattivo per Google Cloud che ti consente di gestire progetti e risorse dal browser web.
- In Cloud Shell, imposta il progetto corrente sul tuo
Google Cloud ID progetto e memorizza lo stesso
ID progetto nella variabile di shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} - Se non sei il proprietario del progetto, chiedi al proprietario del progetto di concederti il ruolo
Amministratore IAM progetto (
roles/resourcemanager.projectIamAdmin). Devi disporre di questo ruolo per concedere i ruoli IAM nel passaggio successivo. -
Make sure that you have the following role or roles on the project: roles/artifactregistry.admin, roles/artifactregistry.repoAdmin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/file.editor, roles/logging.viewer, roles/logging.admin, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/servicemanagement.quotaAdmin, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/storage.objectAdmin, roles/aiplatform.admin, roles/aiplatform.user, roles/aiplatform.viewer, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/resourcemanager.projectIamAdmin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
Vai a IAM - Seleziona il progetto.
- Fai clic su Concedi l'accesso.
-
Nel campo Nuove entità, inserisci il tuo identificatore dell'utente. In genere si tratta dell'indirizzo email di un Account Google.
- Nell'elenco Seleziona un ruolo, seleziona un ruolo.
- Per concedere altri ruoli, fai clic su Aggiungi un altro ruolo e aggiungi ogni ruolo aggiuntivo.
- Fai clic su Salva.
Enable the DNS, Artifact Registry, IAM, Compute Engine, Cloud Logging, Network Connectivity, Notebooks, Cloud Filestore, Service Networking, Service Usage, and Vertex AI APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Crea le reti VPC
In questa sezione, creerai due reti VPC: una per accedere alle API di Google per Vertex AI Pipelines e l'altra per simulare una rete on-premise. In ciascuna delle due reti VPC, crei un router Cloud e un gateway Cloud NAT. Un gateway Cloud NAT fornisce connettività in uscita per le istanze di macchine virtuali (VM) Compute Engine senza indirizzi IP esterni.
In Cloud Shell, esegui i seguenti comandi, sostituendo PROJECT_ID con il tuo ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crea la rete VPC
vertex-networking-vpc:gcloud compute networks create vertex-networking-vpc \ --subnet-mode customNella rete
vertex-networking-vpc, crea una subnet denominatapipeline-networking-subnet1, con un intervallo IPv4 principale di10.0.0.0/24:gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCrea la rete VPC per simulare la rete on-premise (
onprem-dataservice-vpc):gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode customNella rete
onprem-dataservice-vpc, crea una subnet denominataonprem-dataservice-vpc-subnet1, con un intervallo IPv4 principale di172.16.10.0/24:gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
Verifica che le reti VPC siano configurate correttamente
Nella console Google Cloud , vai alla scheda Reti nel progetto attuale nella pagina Reti VPC.
Nell'elenco delle reti VPC, verifica che siano state create le due reti:
vertex-networking-vpceonprem-dataservice-vpc.Fai clic sulla scheda Subnet nel progetto attuale.
Nell'elenco delle subnet VPC, verifica che siano state create le subnet
pipeline-networking-subnet1eonprem-dataservice-vpc-subnet1.
Configura la connettività ibrida
In questa sezione, crei due gateway VPN ad alta disponibilità connessi tra loro. Una si trova nella rete VPC vertex-networking-vpc. L'altro si trova nella rete VPC onprem-dataservice-vpc. Ogni gateway contiene un router Cloud e una coppia di tunnel VPN.
Crea i gateway VPN ad alta disponibilità
In Cloud Shell, crea il gateway VPN ad alta disponibilità per la rete VPC
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Crea il gateway VPN ad alta disponibilità per la rete VPC
onprem-dataservice-vpc:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1Nella console Google Cloud , vai alla scheda Gateway Cloud VPN nella pagina VPN.
Verifica che siano stati creati i due gateway (
vertex-networking-vpn-gw1eonprem-vpn-gw1) e che ognuno abbia due indirizzi IP di interfaccia.
Crea router Cloud e gateway Cloud NAT
In ciascuna delle due reti VPC, crei due router Cloud: uno da utilizzare con Cloud NAT e uno per gestire le sessioni BGP per la VPN ad alta disponibilità.
In Cloud Shell, crea un router Cloud per la rete VPC
vertex-networking-vpcche verrà utilizzata per la VPN:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001Crea un router Cloud per la rete VPC
onprem-dataservice-vpcche verrà utilizzata per la VPN:gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002Crea un router Cloud per la rete VPC
vertex-networking-vpcche verrà utilizzata per Cloud NAT:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Configura un gateway Cloud NAT sul router Cloud:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Crea un router Cloud per la rete VPC
onprem-dataservice-vpcche verrà utilizzata per Cloud NAT:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1Configura un gateway Cloud NAT sul router Cloud:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Nella Google Cloud console, vai alla pagina Cloud Router.
Nell'elenco Router Cloud, verifica che siano stati creati i seguenti router:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
Potresti dover aggiornare la scheda del browser della console Google Cloud per visualizzare i nuovi valori.
Nell'elenco dei router Cloud, fai clic su
cloud-router-us-central1-vertex-nat.Nella pagina Dettagli router, verifica che sia stato creato il gateway Cloud NAT
cloud-nat-us-central1.Fai clic sulla freccia indietro per tornare alla pagina Router Cloud.
Nell'elenco dei router Cloud, fai clic su
cloud-router-us-central1-onprem-nat.Nella pagina Dettagli router, verifica che sia stato creato il gateway Cloud NAT
cloud-nat-us-central1-on-prem.
Crea tunnel VPN
In Cloud Shell, nella rete
vertex-networking-vpc, crea un tunnel VPN denominatovertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0Nella rete
vertex-networking-vpc, crea un tunnel VPN denominatovertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1Nella rete
onprem-dataservice-vpc, crea un tunnel VPN denominatoonprem-dataservice-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0Nella rete
onprem-dataservice-vpc, crea un tunnel VPN denominatoonprem-dataservice-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Nella console Google Cloud , vai alla pagina VPN.
Nell'elenco dei tunnel VPN, verifica che siano stati creati i quattro tunnel VPN.
Definizione di sessioni BGP
Router Cloud utilizza il protocollo BGP (Border Gateway Protocol) per scambiare le route tra la tua rete VPC (in questo caso, vertex-networking-vpc) e la tua rete on-premise (rappresentata da onprem-dataservice-vpc). Su Cloud Router, configuri un'interfaccia e un peer BGP per il tuo router on-premise.
L'abbinamento dell'interfaccia e della configurazione peer BGP crea una sessione BGP.
In questa sezione, creerai due sessioni BGP per vertex-networking-vpc e
due per onprem-dataservice-vpc.
Dopo aver configurato le interfacce e i peer BGP tra i router, questi inizieranno automaticamente a scambiare le route.
Definisci sessioni BGP per vertex-networking-vpc
In Cloud Shell, nella rete
vertex-networking-vpc, crea un'interfaccia BGP pervertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1Nella rete
vertex-networking-vpc, crea un peer BGP perbgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1Nella rete
vertex-networking-vpc, crea un'interfaccia BGP pervertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1Nella rete
vertex-networking-vpc, crea un peer BGP perbgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
Definisci sessioni BGP per onprem-dataservice-vpc
Nella rete
onprem-dataservice-vpc, crea un'interfaccia BGP peronprem-dataservice-vpc-tunnel0:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1Nella rete
onprem-dataservice-vpc, crea un peer BGP perbgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1Nella rete
onprem-dataservice-vpc, crea un'interfaccia BGP peronprem-dataservice-vpc-tunnel1:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1Nella rete
onprem-dataservice-vpc, crea un peer BGP perbgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
Convalida la creazione della sessione BGP
Nella console Google Cloud , vai alla pagina VPN.
Nell'elenco dei tunnel VPN, verifica che il valore nella colonna Stato sessione BGP per ciascun tunnel sia cambiato da Configura sessione BGP a BGP stabilito. Per visualizzare i nuovi valori, potresti dover aggiornare la scheda del browser della console. Google Cloud
Convalida le route apprese onprem-dataservice-vpc
Nella console Google Cloud , vai alla pagina Reti VPC.
Nell'elenco delle reti VPC, fai clic su
onprem-dataservice-vpc.Fai clic sulla scheda Percorsi.
Seleziona us-central1 (Iowa) nell'elenco Regione e fai clic su Visualizza.
Nella colonna Intervallo IP di destinazione, verifica che l'intervallo IP della subnet
pipeline-networking-subnet1(10.0.0.0/24) venga visualizzato due volte.Potresti dover aggiornare la scheda del browser della console Google Cloud per visualizzare entrambe le voci.
Convalida le route apprese vertex-networking-vpc
Fai clic sulla Freccia indietro per tornare alla pagina Reti VPC.
Nell'elenco delle reti VPC, fai clic su
vertex-networking-vpc.Fai clic sulla scheda Percorsi.
Seleziona us-central1 (Iowa) nell'elenco Regione e fai clic su Visualizza.
Nella colonna Intervallo IP di destinazione, verifica che l'intervallo IP della subnet
onprem-dataservice-vpc-subnet1(172.16.10.0/24) venga visualizzato due volte.
Crea un endpoint Private Service Connect per le API di Google
In questa sezione, crei un endpoint Private Service Connect per le API di Google che utilizzerai per accedere all'API REST di Vertex AI Pipelines dalla tua rete on-premise.
In Cloud Shell, prenota un indirizzo IP endpoint consumer che verrà utilizzato per accedere alle API di Google:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcCrea una regola di forwarding per connettere l'endpoint alle API e ai servizi Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Creare annunci di route personalizzati per vertex-networking-vpc
In questa sezione, crei una
pubblicità di route personalizzata
per vertex-networking-vpc-router1 (il router Cloud per
vertex-networking-vpc) per pubblicizzare l'indirizzo IP dell'endpoint PSC
alla rete VPC onprem-dataservice-vpc.
Nella Google Cloud console, vai alla pagina Cloud Router.
Nell'elenco dei router Cloud, fai clic su
vertex-networking-vpc-router1.Nella pagina Dettagli router, fai clic su Modifica.
Nella sezione Route pubblicizzate, per Route, seleziona Crea route personalizzate.
Seleziona la casella di controllo Annuncia tutte le subnet visibili al router Cloud per continuare ad annunciare le subnet disponibili per il router Cloud. L'attivazione di questa opzione simula il comportamento del router Cloud in modalità di annuncio predefinita.
Fai clic su Aggiungi un percorso personalizzato.
In Origine, seleziona Intervallo IP personalizzato.
In Intervallo di indirizzi IP, inserisci il seguente indirizzo IP:
192.168.0.1Per Descrizione, inserisci il seguente testo:
Custom route to advertise Private Service Connect endpoint IP addressFai clic su Fine e poi su Salva.
Verifica che onprem-dataservice-vpc abbia appreso le route annunciate
Nella console Google Cloud , vai alla pagina Route.
Nella scheda Route operative, procedi nel seguente modo:
- In Rete, scegli
onprem-dataservice-vpc. - In Regione, scegli
us-central1 (Iowa). - Fai clic su Visualizza.
Nell'elenco delle route, verifica che siano presenti due voci i cui nomi iniziano con
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0e due che iniziano cononprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1.Se queste voci non vengono visualizzate immediatamente, attendi qualche minuto, quindi aggiorna la scheda del browser della console Google Cloud .
Verifica che due delle voci abbiano un intervallo IP di destinazione di
192.168.0.1/32e due abbiano un intervallo IP di destinazione di10.0.0.0/24.
- In Rete, scegli
Crea una VM nell'istanza in onprem-dataservice-vpc
In questa sezione, creerai un'istanza VM che simula un host del servizio dati on-premise. Seguendo le best practice di Compute Engine e IAM, questa VM utilizza un account di servizio gestito dall'utente anziché il service account predefinito di Compute Engine.
Crea il account di servizio gestito dall'utente per l'istanza VM
In Cloud Shell, esegui i seguenti comandi, sostituendo PROJECT_ID con il tuo ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crea un account di servizio denominato
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"Assegna il ruolo Utente Vertex AI (
roles/aiplatform.user) al account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Assegna il ruolo Visualizzatore Vertex AI (
roles/aiplatform.viewer):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.viewer"Assegna il ruolo Editor Filestore (
roles/file.editor):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/file.editor"Assegna il ruolo Amministratore service account (
roles/iam.serviceAccountAdmin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountAdmin"Assegna il ruolo Utente service account (
roles/iam.serviceAccountUser):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"Assegna il ruolo Artifact Registry Reader (
roles/artifactregistry.reader):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.reader"Assegna il ruolo Amministratore oggetti Storage (
roles/storage.objectAdmin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin"Assegna il ruolo Logging Admin (
roles/logging.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.admin"
Crea l'istanza VM on-prem-dataservice-host
L'istanza VM che crei non ha un indirizzo IP esterno e non consente l'accesso diretto su internet. Per abilitare l'accesso amministrativo alla VM, utilizza l'inoltro TCP di Identity-Aware Proxy (IAP).
In Cloud Shell, crea l'istanza VM
on-prem-dataservice-host:gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crea una regola firewall per consentire a IAP di connettersi alla tua istanza VM:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Aggiorna il file /etc/hosts in modo che punti all'endpoint PSC
In questa sezione, aggiungi una riga al file /etc/hosts che fa sì che le richieste
inviate all'endpoint del servizio pubblico (us-central1-aiplatform.googleapis.com)
vengano reindirizzate all'endpoint PSC (192.168.0.1).
In Cloud Shell, accedi all'istanza VM
on-prem-dataservice-hostutilizzando IAP:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapNell'istanza VM
on-prem-dataservice-host, utilizza un editor di testo comevimonanoper aprire il file/etc/hosts, ad esempio:sudo vim /etc/hostsAggiungi la seguente riga al file:
192.168.0.1 us-central1-aiplatform.googleapis.comQuesta riga assegna l'indirizzo IP dell'endpoint PSC (
192.168.0.1) al nome di dominio completo per l'API Google Vertex AI (us-central1-aiplatform.googleapis.com).Il file modificato dovrebbe avere il seguente aspetto:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleSalva il file come segue:
- Se utilizzi
vim, premi il tastoEsc, quindi digita:wqper salvare il file e uscire. - Se utilizzi
nano, digitaControl+Oe premiEnterper salvare il file, quindi digitaControl+Xper uscire.
- Se utilizzi
Esegui il ping dell'endpoint API Vertex AI nel seguente modo:
ping us-central1-aiplatform.googleapis.comIl comando
pingdovrebbe restituire il seguente output.192.168.0.1è l'indirizzo IP dell'endpoint PSC:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Digita
Control+Cper uscire daping.Digita
exitper uscire dall'istanza VMon-prem-dataservice-hoste tornare al prompt di Cloud Shell.
Configura il networking per un'istanza Filestore
In questa sezione, attivi l'accesso privato ai servizi per la tua rete VPC, in preparazione alla creazione di un'istanza Filestore e al suo montaggio come condivisione Network File System (NFS). Per capire cosa stai facendo in questa sezione e nella successiva, consulta Montare una condivisione NFS per l'addestramento personalizzato e Configurare il peering di rete VPC.
Abilitare l'accesso privato ai servizi su una rete VPC
In questa sezione, crei una connessione Service Networking e la utilizzi
per attivare l'accesso privato ai servizi alla rete VPC onprem-dataservice-vpc tramite il peering di rete VPC.
In Cloud Shell, imposta un intervallo di indirizzi IP riservati utilizzando
gcloud compute addresses create:gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpcStabilisci una connessione in peering tra la rete VPC
onprem-dataservice-vpce Service Networking di Google utilizzandogcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpcAggiorna il peering di rete VPC per abilitare l'importazione e l'esportazione di route personalizzate apprese:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routesNella console Google Cloud , vai alla pagina Peering di reti VPC.
Nell'elenco dei peering VPC, verifica che sia presente una voce per il peering tra
servicenetworking.googleapis.come la rete VPConprem-dataservice-vpc.
Creare annunci di route personalizzati per filestore-subnet
Nella Google Cloud console, vai alla pagina Cloud Router.
Nell'elenco dei router Cloud, fai clic su
onprem-dataservice-vpc-router1.Nella pagina Dettagli router, fai clic su Modifica.
Nella sezione Route pubblicizzate, per Route, seleziona Crea route personalizzate.
Seleziona la casella di controllo Annuncia tutte le subnet visibili al router Cloud per continuare ad annunciare le subnet disponibili per il router Cloud. L'attivazione di questa opzione simula il comportamento del router Cloud in modalità di annuncio predefinita.
Fai clic su Aggiungi un percorso personalizzato.
In Origine, seleziona Intervallo IP personalizzato.
Per Intervallo di indirizzi IP, inserisci il seguente intervallo di indirizzi IP:
10.243.208.0/24Per Descrizione, inserisci il seguente testo:
Filestore reserved IP address rangeFai clic su Fine e poi su Salva.
Crea l'istanza di Filestore nella rete onprem-dataservice-vpc
Dopo aver attivato l'accesso privato ai servizi per la tua rete VPC, crea un'istanza Filestore e monta l'istanza come condivisione NFS per il tuo job di addestramento personalizzato. In questo modo, i job di addestramento possono accedere ai file remoti come se fossero locali, consentendo velocità effettiva elevata e bassa latenza.
Crea l'istanza Filestore
Nella console Google Cloud , vai alla pagina Istanze Filestore.
Fai clic su Crea istanza e configura l'istanza come segue:
Imposta ID istanza su quanto segue:
image-data-instanceImposta Tipo di istanza su Base.
Imposta Tipo di archiviazione su HDD.
Imposta Alloca capacità su 1
TiB.Imposta Regione su us-central1 e Zona su us-central1-c.
Imposta Rete VPC su
onprem-dataservice-vpc.Imposta Intervallo IP allocato su Utilizza un intervallo IP allocato esistente e scegli
filestore-subnet.Imposta Nome condivisione file su:
vol1Imposta Controlli di accesso su Concedi l'accesso a tutti i client della rete VPC.
Fai clic su Crea.
Prendi nota dell'indirizzo IP della nuova istanza di Filestore. Potresti dover aggiornare la scheda del browser della console per visualizzare la nuova istanza. Google Cloud
Monta la condivisione file di Filestore
In Cloud Shell, esegui i seguenti comandi, sostituendo PROJECT_ID con il tuo ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accedi all'istanza VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapInstalla il pacchetto NFS sull'istanza VM:
sudo apt-get update -y sudo apt-get -y install nfs-commonCrea una directory di montaggio per la condivisione file di Filestore:
sudo mkdir -p /mnt/nfsMonta la condivisione file, sostituendo FILESTORE_INSTANCE_IP con l'indirizzo IP dell'istanza Filestore:
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfsSe la connessione scade, verifica di aver fornito l'indirizzo IP corretto dell'istanza Filestore.
Verifica che il montaggio NFS sia andato a buon fine eseguendo questo comando:
df -hVerifica che la condivisione file
/mnt/nfsvenga visualizzata nel risultato:Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfsRendi la condivisione file accessibile modificando le autorizzazioni:
sudo chmod go+rw /mnt/nfs
Scaricare il set di dati nella condivisione file
Nell'istanza VM
on-prem-dataservice-host, scarica il set di dati nella condivisione file:gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursiveIl download richiede diversi minuti.
Verifica che il set di dati sia stato copiato correttamente eseguendo il seguente comando:
sudo du -sh /mnt/nfsL'output previsto è:
104M /mnt/nfsDigita
exitper uscire dall'istanza VMon-prem-dataservice-hoste tornare al prompt di Cloud Shell.
Crea un bucket di staging per la pipeline
Vertex AI Pipelines archivia gli artefatti delle esecuzioni della pipeline utilizzando Cloud Storage. Prima di eseguire la pipeline, devi creare un bucket Cloud Storage per preparare le esecuzioni della pipeline.
In Cloud Shell, crea un bucket Cloud Storage:
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
Crea un account di servizio gestito dall'utente per Vertex AI Workbench
In Cloud Shell, crea un account di servizio:
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Assegna il ruolo Utente Vertex AI (
roles/aiplatform.user) al account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Assegna il ruolo Amministratore Artifact Registry (
artifactregistry.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"Assegna il ruolo Amministratore Storage (
storage.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"
Creare l'applicazione di addestramento Python
In questa sezione, crei un'istanza di Vertex AI Workbench e la utilizzi per creare un pacchetto di applicazione di addestramento personalizzato Python.
crea un'istanza di Vertex AI Workbench
Nella console Google Cloud , vai alla scheda Istanze nella pagina Vertex AI Workbench.
Fai clic su Crea nuovo e poi su Opzioni avanzate.
Viene visualizzata la pagina Nuova istanza.
Nella pagina Nuova istanza, nella sezione Dettagli, fornisci le seguenti informazioni per la nuova istanza e poi fai clic su Continua:
Nome: inserisci quanto segue, sostituendo PROJECT_ID con l'ID progetto:
pipeline-tutorial-PROJECT_IDRegione: seleziona us-central1.
Zona: seleziona us-central1-a.
Deseleziona la casella di controllo Abilita sessioni interattive serverless di Dataproc.
Nella sezione Ambiente, fai clic su Continua.
Nella sezione Tipo di macchina, fornisci quanto segue e poi fai clic su Continua:
- Tipo di macchina: scegli N1, quindi seleziona
n1-standard-4dal menu Tipo di macchina. Shielded VM: seleziona le seguenti caselle di controllo:
- Avvio protetto
- Virtual Trusted Platform Module (vTPM)
- Monitoraggio dell'integrità
- Tipo di macchina: scegli N1, quindi seleziona
Nella sezione Dischi, assicurati che sia selezionata l'opzione Google-managed encryption key, quindi fai clic su Continua:
Nella sezione Networking, fornisci le seguenti informazioni e poi fai clic su Continua:
Networking: seleziona Rete in questo progetto e completa i seguenti passaggi:
Nel campo Rete, seleziona vertex-networking-vpc.
Nel campo Subnet, seleziona pipeline-networking-subnet1.
Deseleziona la casella di controllo Assegna indirizzo IP esterno. La mancata assegnazione di un indirizzo IP esterno impedisce all'istanza di ricevere comunicazioni non richieste da internet o da altre reti VPC.
Seleziona la casella di controllo Consenti accesso proxy.
Nella sezione IAM e sicurezza, fornisci quanto segue e poi fai clic su Continua:
IAM e sicurezza: per concedere a un singolo utente l'accesso all'interfaccia JupyterLab dell'istanza, completa i seguenti passaggi:
- Seleziona Service account (Account di servizio).
- Deseleziona la casella di controllo Usa account di servizio predefinito di Compute Engine.
Questo passaggio è importante perché il account di servizio predefinito di Compute Engine (e quindi il singolo utente che hai appena specificato) potrebbe avere il ruolo Editor (
roles/editor) nel tuo progetto. Nel campo Email service account, inserisci quanto segue sostituendo PROJECT_ID con l'ID progetto:
workbench-sa@PROJECT_ID.iam.gserviceaccount.com(Si tratta dell'indirizzo email del service account personalizzato che hai creato in precedenza.) Questo service account dispone di autorizzazioni limitate.
Per saperne di più sulla concessione dell'accesso, consulta Gestire l'accesso all'interfaccia JupyterLab di un'istanza di Vertex AI Workbench.
Opzioni di sicurezza: deseleziona la seguente casella di controllo:
- Accesso root all'istanza
Seleziona la seguente casella di controllo:
- nbconvert:
nbconvertconsente agli utenti di esportare e scaricare un file notebook come un tipo di file diverso, ad esempio HTML, PDF o LaTeX. Questa impostazione è richiesta da alcuni notebook nel repository GitHub Google Cloud Generative AI.
Deseleziona la seguente casella di controllo:
- Download di file
Seleziona la casella di controllo seguente, a meno che tu non ti trovi in un ambiente di produzione:
- Accesso al terminale: consente l'accesso al terminale all'istanza dall'interfaccia utente di JupyterLab.
Nella sezione Integrità del sistema, deseleziona Upgrade automatico dell'ambiente e fornisci quanto segue:
In Report, seleziona le seguenti caselle di controllo:
- Segnala integrità del sistema
- Segnala metriche personalizzate a Cloud Monitoring
- Installa Cloud Monitoring
- Segnala lo stato del DNS per i domini Google richiesti
Fai clic su Crea e attendi qualche minuto per la creazione dell'istanza di Vertex AI Workbench.
Esegui l'applicazione di addestramento nell'istanza di Vertex AI Workbench
Nella console Google Cloud , vai alla scheda Istanze nella pagina Vertex AI Workbench.
Accanto al nome dell'istanza di Vertex AI Workbench (
pipeline-tutorial-PROJECT_ID), dove PROJECT_ID è l'ID progetto, fai clic su Apri JupyterLab.L'istanza di Vertex AI Workbench si apre in JupyterLab.
Seleziona File > Nuovo > Terminale.
Nel terminale JupyterLab (non Cloud Shell), definisci una variabile di ambiente per il tuo progetto. Sostituisci PROJECT_ID con l'ID progetto:
projectid=PROJECT_IDCrea le directory principali per l'applicazione di addestramento (ancora nel terminale JupyterLab):
mkdir fungi_training_package mkdir fungi_training_package/trainerNel browser dei file, fai doppio clic sulla cartella
fungi_training_packagee poi sulla cartellatrainer.Nel browser dei file , fai clic con il tasto destro del mouse sull'elenco dei file vuoto (sotto l'intestazione Nome) e seleziona Nuovo file.
Fai clic con il tasto destro del mouse sul nuovo file e seleziona Rinomina file.
Rinomina il file da
untitled.txtatask.py.Fai doppio clic sul file
task.pyper aprirlo.Copia il seguente codice in
task.py:# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)Seleziona File > Salva file Python.
Nel terminale JupyterLab, crea un file
__init__.pyin ogni sottodirectory per trasformarla in un pacchetto:touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.pyNel browser dei file , fai doppio clic sulla cartella
fungi_training_package.Seleziona File > Nuovo > File Python.
Fai clic con il tasto destro del mouse sul nuovo file e seleziona Rinomina file.
Rinomina il file da
untitled.pyasetup.py.Fai doppio clic sul file
setup.pyper aprirlo.Copia il seguente codice in
setup.py:from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )Seleziona File > Salva file Python.
Nel terminale, vai alla directory
fungi_training_package:cd fungi_training_packageUtilizza il comando
sdistper creare la distribuzione di origine dell'applicazione di addestramento:python setup.py sdist --formats=gztarVai alla directory principale:
cd ..Verifica di trovarti nella directory corretta:
pwdL'output ha il seguente aspetto:
/home/jupyterCopia il pacchetto Python nel bucket di staging:
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/Verifica che il bucket di staging contenga il pacchetto:
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_packageL'output è:
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
Crea la connessione Service Networking per Vertex AI Pipelines
In questa sezione, crei una connessione Service Networking
che viene utilizzata per stabilire i servizi del producer connessi alla
rete VPC vertex-networking-vpc tramite
il peering di rete VPC. Per ulteriori informazioni, consulta peering di rete VPC.
In Cloud Shell, esegui i seguenti comandi, sostituendo PROJECT_ID con il tuo ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Imposta un intervallo di indirizzi IP riservati utilizzando
gcloud compute addresses create:gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpcStabilisci una connessione in peering tra la rete VPC
vertex-networking-vpce Service Networking di Google utilizzandogcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpcAggiorna la connessione di peering VPC per abilitare l'importazione e l'esportazione di route personalizzate apprese:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
Annuncia la subnet della pipeline dal router Cloud pipeline-networking
Nella Google Cloud console, vai alla pagina Cloud Router.
Nell'elenco dei router Cloud, fai clic su
vertex-networking-vpc-router1.Nella pagina Dettagli router, fai clic su Modifica.
Fai clic su Aggiungi un percorso personalizzato.
In Origine, seleziona Intervallo IP personalizzato.
Per Intervallo di indirizzi IP, inserisci il seguente intervallo di indirizzi IP:
192.168.10.0/24Per Descrizione, inserisci il seguente testo:
Vertex AI Pipelines reserved subnetFai clic su Fine e poi su Salva.
Crea un modello di pipeline e caricalo su Artifact Registry
In questa sezione, creerai e caricherai un modello di pipeline Kubeflow Pipelines (KFP). Questo modello contiene una definizione del flusso di lavoro che può essere riutilizzata più volte, da un singolo utente o da più utenti.
Definisci e compila la pipeline
In Jupyterlab, nel File Browser, fai doppio clic sulla cartella di primo livello.
Seleziona File > Nuovo > Blocco note.
Nel menu Seleziona kernel, seleziona
Python 3 (ipykernel)e fai clic su Seleziona.In una nuova cella del notebook, esegui questo comando per assicurarti di avere l'ultima versione di
pip:!python -m pip install --upgrade pipEsegui il seguente comando per installare l'SDK Google Cloud Pipeline Components dall'indice dei pacchetti Python (PyPI):
!pip install --upgrade google-cloud-pipeline-componentsAl termine dell'installazione, seleziona Kernel > Riavvia kernel per riavviare il kernel e assicurarti che la libreria sia disponibile per l'importazione.
Esegui questo codice in una nuova cella del notebook per definire la pipeline:
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )Esegui questo codice in una nuova cella del notebook per compilare la definizione della pipeline:
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )Nel browser di file, un file denominato
pipeline_config.yamlviene visualizzato nell'elenco dei file.
Crea un repository Artifact Registry
Esegui questo codice in una nuova cella del notebook per creare un repository di artefatti di tipo KFP:
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
Carica il modello di pipeline in Artifact Registry
In questa sezione configurerai un client di registro dell'SDK Kubeflow Pipelines e caricherai il modello di pipeline compilato in Artifact Registry dal tuo notebook JupyterLab.
Nel notebook JupyterLab, esegui il seguente codice per caricare il modello di pipeline, sostituendo PROJECT_ID con il tuo ID progetto:
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})Nella console Google Cloud , per verificare che il modello sia stato caricato, vai a Modelli di Vertex AI Pipelines.
Per aprire il riquadro Seleziona repository, fai clic su Seleziona repository.
Nell'elenco dei repository, fai clic sul repository che hai creato (
fungi-repo), quindi fai clic su Seleziona.Verifica che la tua pipeline (
custom-image-classification-pipeline) venga visualizzata nell'elenco.
Attivare l'esecuzione di una pipeline da on-premise
In questa sezione, ora che il modello di pipeline e il pacchetto di addestramento sono pronti, utilizzi cURL per attivare l'esecuzione di una pipeline dalla tua applicazione on-premise.
Fornisci i parametri della pipeline
Nel notebook JupyterLab, esegui il seguente comando per verificare il nome del modello di pipeline:
print (TEMPLATE_NAME)Il nome del modello restituito è:
custom-image-classification-pipelineEsegui questo comando per ottenere la versione del modello di pipeline:
print (VERSION_NAME)Il nome della versione del modello di pipeline restituito ha questo aspetto:
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7Prendi nota dell'intera stringa del nome della versione.
In Cloud Shell, esegui i seguenti comandi, sostituendo PROJECT_ID con il tuo ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accedi all'istanza VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapNell'istanza VM
on-prem-dataservice-host, utilizza un editor di testo comevimonanoper creare il filerequest_body.json, ad esempio:sudo vim request_body.jsonAggiungi il testo seguente al file
request_body.json:{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.iam.gserviceaccount.com", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }Sostituisci i seguenti valori:
- PROJECT_ID: il tuo ID progetto
- PROJECT_NUMBER: il numero di progetto. Questo è diverso dall'ID progetto. Puoi trovare il numero di progetto nella pagina Impostazioni progetto della console Google Cloud .
- FILESTORE_INSTANCE_IP: l'indirizzo IP dell'istanza Filestore,
ad esempio
10.243.208.2. Puoi trovarlo nella pagina Istanze di Filestore per la tua istanza. - VERSION_NAME: il nome della versione del modello di pipeline (
sha256:...) che hai annotato nel passaggio 2.
Salva il file come segue:
- Se utilizzi
vim, premi il tastoEsc, quindi digita:wqper salvare il file e uscire. - Se utilizzi
nano, digitaControl+Oe premiEnterper salvare il file, quindi digitaControl+Xper uscire.
- Se utilizzi
Inviare un'esecuzione della pipeline dal modello
Nell'istanza VM
on-prem-dataservice-host, esegui il comando seguente, sostituendo PROJECT_ID con il tuo ID progetto:curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobsL'output visualizzato è lungo, ma la cosa principale da cercare è la seguente riga, che indica che il servizio si sta preparando a eseguire la pipeline:
"state": "PIPELINE_STATE_PENDING"L'intera esecuzione della pipeline richiede circa 45-50 minuti.
Nella console Google Cloud , nella sezione Vertex AI, vai alla scheda Esecuzioni nella pagina Pipeline.
Fai clic sul nome dell'esecuzione della pipeline (
custom-image-classification-pipeline).Viene visualizzata la pagina di esecuzione della pipeline e il grafico di runtime della pipeline. Il riepilogo della pipeline viene visualizzato nel riquadro Analisi esecuzione pipeline.
Per informazioni su come interpretare le informazioni visualizzate nel grafico di runtime, incluso come visualizzare i log e utilizzare Vertex ML Metadata per saperne di più sugli artefatti della pipeline, consulta Visualizzare e analizzare i risultati della pipeline.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Puoi eliminare le singole risorse nel progetto nel seguente modo:
Elimina tutte le esecuzioni pipeline nel seguente modo:
Nella console Google Cloud , nella sezione Vertex AI, vai alla scheda Esecuzioni nella pagina Pipeline.
Seleziona le esecuzioni pipeline da eliminare e fai clic su Elimina.
Elimina il modello di pipeline nel seguente modo:
Nella sezione Vertex AI, vai alla scheda I tuoi modelli nella pagina Pipeline.
Accanto al modello di pipeline
custom-image-classification-pipeline, fai clic su Azioni e seleziona Elimina.
Elimina il repository da Artifact Registry nel seguente modo:
Nella pagina Artifact Registry, vai alla scheda Repository.
Seleziona il repository
fungi-repoe fai clic su Elimina.
Annulla il deployment del modello dall'endpoint nel seguente modo:
Nella sezione Vertex AI, vai alla scheda Endpoint nella pagina Previsioni online.
Fai clic su
fungi-image-endpointper andare alla pagina dei dettagli dell'endpoint.Nella riga relativa al tuo modello,
fungi-image-model, fai clic su Azioni e seleziona Annulla il deployment del modello nell'endpoint.Nella finestra di dialogo Annulla il deployment del modello nell'endpoint, fai clic su Annulla il deployment.
Elimina l'endpoint nel seguente modo:
Nella sezione Vertex AI, vai alla scheda Endpoint nella pagina Previsioni online.
Seleziona
fungi-image-endpointe fai clic su Elimina.
Elimina il modello nel seguente modo:
Vai alla pagina Registro dei modelli.
Nella riga del modello
fungi-image-model, fai clic su Azioni e seleziona Elimina modello.
Elimina il bucket di staging nel seguente modo:
Vai alla pagina Cloud Storage.
Seleziona
pipelines-staging-bucket-PROJECT_ID, dove PROJECT_ID è l'ID progetto, e fai clic su Elimina.
Elimina l'istanza di Vertex AI Workbench nel seguente modo:
Nella sezione Vertex AI, vai alla scheda Istanze nella pagina Workbench.
Seleziona l'istanza
pipeline-tutorial-PROJECT_IDVertex AI Workbench, dove PROJECT_ID è l'ID progetto, e fai clic su Elimina.
Elimina l'istanza VM di Compute Engine nel seguente modo:
Vai alla pagina Compute Engine.
Seleziona l'istanza VM
on-prem-dataservice-hoste fai clic su Elimina.
Elimina i tunnel VPN nel seguente modo:
Vai alla pagina VPN.
Nella pagina VPN, fai clic sulla scheda Tunnel Cloud VPN.
Nell'elenco dei tunnel VPN, seleziona i quattro tunnel VPN che hai creato in questo tutorial e fai clic su Elimina.
Elimina i gateway VPN ad alta disponibilità nel seguente modo:
Nella pagina VPN, fai clic sulla scheda Gateway Cloud VPN.
Nell'elenco dei gateway VPN, fai clic su
onprem-vpn-gw1.Nella pagina Dettagli gateway Cloud VPN, fai clic su Elimina gateway VPN.
Fai clic sulla freccia indietro se necessario per tornare all'elenco dei gateway VPN, poi fai clic su
vertex-networking-vpn-gw1.Nella pagina Dettagli gateway Cloud VPN, fai clic su Elimina gateway VPN.
Elimina i router Cloud nel seguente modo:
Vai alla pagina Router Cloud.
Nell'elenco dei router Cloud, seleziona i quattro router che hai creato in questo tutorial.
Per eliminare i router, fai clic su Elimina.
Verranno eliminati anche i due gateway Cloud NAT collegati ai router Cloud.
Elimina le connessioni Service Networking alle reti VPC
vertex-networking-vpceonprem-dataservice-vpcnel seguente modo:Vai alla pagina Peering di rete VPC.
Seleziona
servicenetworking-googleapis-com.Per eliminare le connessioni, fai clic su Elimina.
Elimina la regola di forwarding
pscvertexper la rete VPCvertex-networking-vpcnel seguente modo:Vai alla scheda Frontend della pagina Bilanciamento del carico.
Nell'elenco delle regole di forwarding, fai clic su
pscvertex.Nella pagina Dettagli regola di forwarding globale, fai clic su Elimina.
Elimina l'istanza Filestore nel seguente modo:
Vai alla pagina Filestore.
Seleziona l'istanza
image-data-instance.Per eliminare l'istanza, fai clic su Azioni e poi su Elimina istanza.
Elimina le reti VPC nel seguente modo:
Vai alla pagina Reti VPC.
Nell'elenco delle reti VPC, fai clic su
onprem-dataservice-vpc.Nella pagina Dettagli rete VPC, fai clic su Elimina rete VPC.
L'eliminazione di ogni rete elimina anche le relative subnet, route e regole firewall.
Nell'elenco delle reti VPC, fai clic su
vertex-networking-vpc.Nella pagina Dettagli rete VPC, fai clic su Elimina rete VPC.
Elimina i service account
workbench-saeonprem-user-managed-sanel seguente modo:Vai alla pagina Account di servizio.
Seleziona gli account di servizio
onprem-user-managed-saeworkbench-sae fai clic su Elimina.
Passaggi successivi
Scopri come utilizzare Vertex AI Pipelines per orchestrare il processo di creazione e deployment dei tuoi modelli di machine learning.
Scopri di più sul set di dati deFungi.