Vertex AI Pipelines es un servicio administrado que te ayuda a compilar, implementar y administrar flujos de trabajo de aprendizaje automático (AA) de extremo a extremo en la plataforma de Google Cloud. Proporciona un entorno sin servidores para ejecutar tus canalizaciones, de modo que no tengas que preocuparte por administrar la infraestructura.
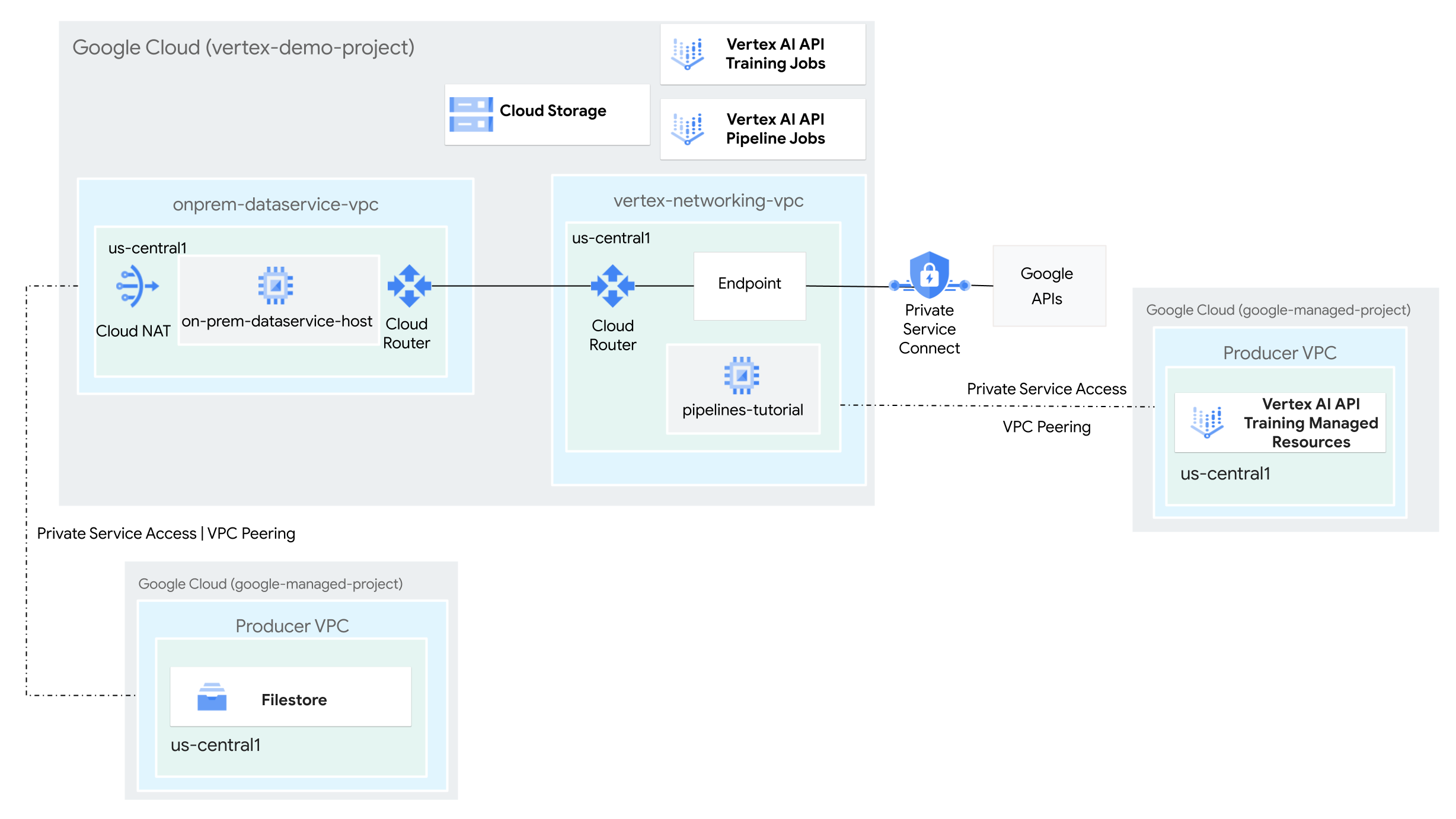
En este instructivo, usarás Vertex AI Pipelines para ejecutar un trabajo de entrenamiento personalizado y, luego, implementar el modelo entrenado en Vertex AI, en un entorno de red híbrida.
Todo el proceso tarda entre dos y tres horas en completarse, incluidos unos 50 minutos para la ejecución de la canalización.
Este instructivo está dirigido a administradores de redes empresariales, investigadores y científicos de datos que estén familiarizados con Vertex AI, la nube privada virtual (VPC), la consola de Google Cloud y Cloud Shell. Estar familiarizado con Vertex AI Workbench es útil, pero no obligatorio.
Objetivos
- Crea dos redes de nube privada virtual (VPC):
- Uno (
vertex-networking-vpc) es para usar la API de Vertex AI Pipelines para crear y alojar una plantilla de canalización para entrenar un modelo de aprendizaje automático y, luego, implementarlo en un extremo. - La otra (
onprem-dataservice-vpc) representa una red local.
- Uno (
- Conecta las dos redes de VPC de la siguiente manera:
- Implementa puertas de enlace de VPN con alta disponibilidad, túneles de Cloud VPN y Cloud Routers para conectar
vertex-networking-vpcyonprem-dataservice-vpc. - Crea un extremo de Private Service Connect (PSC) para reenviar solicitudes privadas a la API de REST de Vertex AI Pipelines.
- Configurar un anuncio de ruta personalizado de Cloud Router en
vertex-networking-vpcpara anunciar rutas en el extremo de Private Service Connect aonprem-dataservice-vpc.
- Implementa puertas de enlace de VPN con alta disponibilidad, túneles de Cloud VPN y Cloud Routers para conectar
- Crea una instancia de Filestore en la red de VPC
onprem-dataservice-vpcy agrégale datos de entrenamiento en un recurso compartido de NFS. - Crea una aplicación de paquete de Python para el trabajo de entrenamiento.
- Crea una plantilla de trabajo de Vertex AI Pipelines para hacer lo siguiente:
- Crea y ejecuta el trabajo de entrenamiento en los datos del recurso compartido de NFS.
- Importa el modelo entrenado y súbelo a Vertex AI Model Registry.
- Crea un extremo de Vertex AI para las predicciones en línea.
- Implementa el modelo en el extremo.
- Sube la plantilla de canalización a un repositorio de Artifact Registry.
- Usa la API de REST de Vertex AI Pipelines para activar una ejecución de canalización desde un host de servicio de datos local (
on-prem-dataservice-host).
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Cuando finalices las tareas que se describen en este documento, puedes borrar los recursos que creaste para evitar que continúe la facturación. Para obtener más información, consulta Cómo realizar una limpieza.
Antes de comenzar
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Abre Cloud Shell para ejecutar los comandos detallados en este instructivo. Cloud Shell es un entorno de shell interactivo para Google Cloud que te permite administrar proyectos y recursos desde el navegador web.
- En Cloud Shell, establece el proyecto actual como el ID del proyecto de Google Cloud; y, luego, almacena el mismo ID del proyecto en la variable de shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} - Si no eres el propietario del proyecto, pídele al propietario que te otorgue el rol de administrador de IAM del proyecto (
roles/resourcemanager.projectIamAdmin). Debes tener este rol para otorgar roles de IAM en el siguiente paso. -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/artifactregistry.admin, roles/artifactregistry.repoAdmin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/file.editor, roles/logging.viewer, roles/logging.admin, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/servicemanagement.quotaAdmin, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/storage.objectAdmin, roles/aiplatform.admin, roles/aiplatform.user, roles/aiplatform.viewer, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/resourcemanager.projectIamAdmingcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
- Replace
PROJECT_IDwith your project ID. -
Replace
USER_IDENTIFIERwith the identifier for your user account. For example,user:myemail@example.com. - Replace
ROLEwith each individual role.
- Replace
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Cloud Logging, Network Connectivity, Notebooks, Cloud Filestore, Service Networking, Service Usage, and Vertex AI APIs:
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com logging.googleapis.com networkconnectivity.googleapis.com notebooks.googleapis.com file.googleapis.com servicenetworking.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.com
Crea las redes de VPC
En esta sección, crearás dos redes de VPC: una para acceder a las APIs de Google para Vertex AI Pipelines y la otra para simular una red local. En cada una de las dos redes de VPC, debes crear un Cloud Router y una puerta de enlace de Cloud NAT. Una puerta de enlace de Cloud NAT proporciona conectividad saliente para las instancias de máquina virtual (VM) de Compute Engine sin direcciones IP externas.
En Cloud Shell, ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crea la red de VPC
vertex-networking-vpcgcloud compute networks create vertex-networking-vpc \ --subnet-mode customEn la red
vertex-networking-vpc, crea una subred llamadapipeline-networking-subnet1, con un rango IPv4 principal de10.0.0.0/24:gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCrea la red de VPC para simular la red local (
onprem-dataservice-vpc):gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode customEn la red
onprem-dataservice-vpc, crea una subred llamadaonprem-dataservice-vpc-subnet1, con un rango IPv4 principal de172.16.10.0/24:gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
Verifica que las redes de VPC estén configuradas de forma correcta
En la consola de Google Cloud, ve a la pestaña Redes en el proyecto actual en la página Redes de VPC.
En la lista de redes de VPC, verifica que se hayan creado las dos redes:
vertex-networking-vpcyonprem-dataservice-vpc.Haz clic en la pestaña Subredes del proyecto actual.
En la lista de subredes de VPC, verifica que se crearon las subredes
pipeline-networking-subnet1yonprem-dataservice-vpc-subnet1.
Configura la conectividad híbrida
En esta sección, crearás dos puertas de enlace de VPN
con alta disponibilidad que están conectadas entre sí. Una reside en la
red de VPC vertex-networking-vpc. La otra se encuentra en la
red de VPC onprem-dataservice-vpc. Cada puerta de enlace contiene un Cloud Router y un par de túneles VPN.
Crea las puertas de enlace de VPN con alta disponibilidad
En Cloud Shell, crea la puerta de enlace de VPN con alta disponibilidad para la red de VPC
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Crea la puerta de enlace de VPN con alta disponibilidad para la red de VPC
onprem-dataservice-vpc:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1En la consola de Google Cloud, ve a la pestaña Puertas de enlace de Cloud VPN en la página VPN.
Verifica que ambas puertas de enlace (
vertex-networking-vpn-gw1yonprem-vpn-gw1) se hayan creado y que cada puerta de enlace tenga dos direcciones IP de interfaz.
Crea Cloud Routers y puertas de enlace Cloud NAT
En cada una de las dos redes de VPC, debes crear dos Cloud Routers: uno para usar con Cloud NAT y otro para administrar sesiones de BGP para la VPN con alta disponibilidad.
En Cloud Shell, crea un Cloud Router para la red de VPC
vertex-networking-vpcque se usará para la VPN:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001Crea un Cloud Router para la red de VPC
onprem-dataservice-vpcque se usará para la VPN:gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002Crea un Cloud Router para la red de VPC
vertex-networking-vpcque se usará para Cloud NAT:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Configura una puerta de enlace de Cloud NAT en el Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Crea un Cloud Router para la red de VPC
onprem-dataservice-vpcque se usará para Cloud NAT:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1Configura una puerta de enlace de Cloud NAT en el Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1En la consola de Google Cloud, ve a la página Cloud Routers.
En la lista de Cloud Routers, verifica que se hayan creado los siguientes routers:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
Es posible que debas actualizar la pestaña del navegador de la consola de Google Cloud para ver los valores nuevos.
En la lista de Cloud Routers, haz clic en
cloud-router-us-central1-vertex-nat.En la página Detalles del router, verifica que se haya creado la puerta de enlace de Cloud NAT
cloud-nat-us-central1.Haz clic en la flecha hacia atrás para volver a la página Cloud Routers.
En la lista de Cloud Routers, haz clic en
cloud-router-us-central1-onprem-nat.En la página Detalles del router, verifica que se haya creado la puerta de enlace de Cloud NAT
cloud-nat-us-central1-on-prem.
Crea túneles VPN
En Cloud Shell, en la red
vertex-networking-vpc, crea un túnel VPN llamadovertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0En la red
vertex-networking-vpc, crea un túnel VPN llamadovertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1En la red
onprem-dataservice-vpc, crea un túnel VPN llamadoonprem-dataservice-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0En la red
onprem-dataservice-vpc, crea un túnel VPN llamadoonprem-dataservice-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1En la consola de Google Cloud, ve a la página VPN.
En la lista de túneles VPN, verifica que se hayan creado los cuatro túneles VPN.
Establece sesiones de BGP
Cloud Router usa el protocolo de puerta de enlace fronteriza (BGP) para intercambiar rutas entre
tu red de VPC (en este caso, vertex-networking-vpc)
y tu red local (representada por onprem-dataservice-vpc). En Cloud Router,
configura una interfaz y un par de BGP para tu router local.
La interfaz y la configuración de par de BGP juntas forman una sesión de BGP.
En esta sección, crearás dos sesiones de BGP para vertex-networking-vpc y
dos para onprem-dataservice-vpc.
Después de que hayas configurado las interfaces y los pares BGP entre tus routers, comenzarán automáticamente a intercambiar rutas.
Establece sesiones de BGP para vertex-networking-vpc
En Cloud Shell, en la red
vertex-networking-vpc, crea una interfaz de BGP paravertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1En la red
vertex-networking-vpc, crea un par de BGP parabgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1En la red
vertex-networking-vpc, crea una interfaz de BGP paravertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1En la red
vertex-networking-vpc, crea un par de BGP parabgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
Establece sesiones de BGP para onprem-dataservice-vpc
En la red
onprem-dataservice-vpc, crea una interfaz de BGP paraonprem-dataservice-vpc-tunnel0:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1En la red
onprem-dataservice-vpc, crea un par de BGP parabgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1En la red
onprem-dataservice-vpc, crea una interfaz de BGP paraonprem-dataservice-vpc-tunnel1:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1En la red
onprem-dataservice-vpc, crea un par de BGP parabgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
Valida la creación de sesiones de BGP
En la consola de Google Cloud, ve a la página VPN.
En la lista de túneles VPN, verifica que el valor en la columna Estado de la sesión de BGP para cada uno de los túneles haya cambiado de Configura la sesión de BGP a BGP establecida. Es posible que debas actualizar la pestaña del navegador de la consola de Google Cloud para ver los valores nuevos.
Valida las rutas aprendidas de onprem-dataservice-vpc
En la consola de Google Cloud, ve a la página Redes de VPC.
En la lista de redes de VPC, haz clic en
onprem-dataservice-vpc.Haz clic en la pestaña Rutas.
Selecciona us-central1 (Iowa) en la lista Región y haz clic en Ver.
En la columna Rango de IP de destino, verifica que el rango de IP (
10.0.0.0/24) de la subredpipeline-networking-subnet1aparezca dos veces.Es posible que debas actualizar la pestaña del navegador de la consola de Google Cloud para ver ambas entradas.
Valida las rutas aprendidas de vertex-networking-vpc
Haz clic en la flecha hacia atrás para regresar a la página Redes de VPC.
En la lista de redes de VPC, haz clic en
vertex-networking-vpc.Haz clic en la pestaña Rutas.
Selecciona us-central1 (Iowa) en la lista Región y haz clic en Ver.
En la columna Rango de IP de destino, verifica que el rango de IP (
172.16.10.0/24) de la subredonprem-dataservice-vpc-subnet1aparezca dos veces.
Crea un extremo de Private Service Connect para las APIs de Google
En esta sección, crearás un extremo de Private Service Connect para las APIs de Google que usarás para acceder a la API de REST de Vertex AI Pipelines desde tu red local.
En Cloud Shell, reserva una dirección IP de extremo del consumidor que se usará para acceder a las APIs de Google:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcCrea una regla de reenvío para conectar el extremo a los servicios y las APIs de Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Crea anuncios de ruta personalizados para vertex-networking-vpc
En esta sección, crearás un
anuncio de ruta personalizado
para vertex-networking-vpc-router1 (el Cloud Router de
vertex-networking-vpc) para anunciar la dirección IP del extremo de
PSC a la red de VPC onprem-dataservice-vpc.
En la consola de Google Cloud, ve a la página Cloud Routers.
En la lista de Cloud Router, haz clic en
vertex-networking-vpc-router1.En la página de detalles del router, haz clic en Editar.
En la sección Rutas anunciadas, en Rutas, selecciona Crear rutas personalizadas.
Selecciona la casilla de verificación Anunciar todas las subredes visibles para Cloud Router. Esto hará que continúe el anuncio de las subredes disponibles en el Cloud Router. Habilitar esta opción imita el comportamiento de Cloud Router en el modo de anuncio predeterminado.
Haz clic en Agregar una ruta personalizada.
En Fuente, selecciona Rango de IP personalizado.
En Rango de direcciones IP, ingresa la siguiente dirección IP:
192.168.0.1En Descripción, ingresa el siguiente texto:
Custom route to advertise Private Service Connect endpoint IP addressHaz clic en Listo y, luego, en Guardar.
Valida que onprem-dataservice-vpc haya aprendido las rutas anunciadas
En la consola de Google Cloud, ve a la página Rutas.
En la pestaña Effective routes, haz lo siguiente:
- En Red, elige
onprem-dataservice-vpc. - En Región, elige
us-central1 (Iowa). - Haz clic en Ver.
En la lista de rutas, verifica que haya dos entradas cuyos nombres comiencen con
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0y dos que comiencen cononprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1.Si estas entradas no aparecen de inmediato, espera unos minutos y, luego, actualiza la pestaña del navegador de la consola de Google Cloud.
Verifica que dos de las entradas tengan un rango de IP de destino de
192.168.0.1/32y dos tengan un rango de IP de destino de10.0.0.0/24.
- En Red, elige
Crea una instancia de VM en onprem-dataservice-vpc
En esta sección, crearás una instancia de VM que simule un host de servicio de datos local. Siguiendo prácticas recomendadas de Compute Engine e IAM, esta VM usa una cuenta de servicio administrada por el usuario en lugar cuenta de servicio predeterminada de la instancia de Compute Engine.
Crea la cuenta de servicio administrada por el usuario para la instancia de VM
En Cloud Shell, ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Crea una cuenta de servicio llamada
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"Asigna el rol de usuario de Vertex AI (
roles/aiplatform.user) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Asigna el rol de Visualizador de Vertex AI (
roles/aiplatform.viewer):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.viewer"Asigna el rol de Editor de Filestore (
roles/file.editor):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/file.editor"Asigna el rol de administrador de cuentas de servicio (
roles/iam.serviceAccountAdmin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountAdmin"Asigna el rol Usuario de cuenta de servicio (
roles/iam.serviceAccountUser).gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"Asigna el rol de Lector de Artifact Registry (
roles/artifactregistry.reader):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.reader"Asigna el rol Administrador de objetos de almacenamiento (
roles/storage.objectAdmin).gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin"Asigna el rol de administrador de Logging (
roles/logging.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.admin"
Crea la instancia de VM on-prem-dataservice-host
La instancia de VM que creas no tiene una dirección IP externa y no permite el acceso directo a través de Internet. Para habilitar el acceso de administrador a la VM, usa el reenvío de TCP de Identity-Aware Proxy (IAP).
En Cloud Shell, crea la instancia de VM
on-prem-dataservice-host:gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crea una regla de firewall para permitir que IAP se conecte a tu instancia de VM:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Actualiza el archivo /etc/hosts para que apunte al extremo de PSC
En esta sección, agregarás una línea al archivo /etc/hosts que hace que las solicitudes
enviadas al extremo del servicio público (us-central1-aiplatform.googleapis.com)
se redireccionen al extremo de PSC (192.168.0.1).
En Cloud Shell, accede a la instancia de VM
on-prem-dataservice-hostcon IAP:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapEn la instancia de VM
on-prem-dataservice-host, usa un editor de texto, comovimonanopara abrir el archivo/etc/hosts, por ejemplo:sudo vim /etc/hostsAgrega la siguiente línea al archivo:
192.168.0.1 us-central1-aiplatform.googleapis.comEsta línea asigna la dirección IP del extremo de PSC (
192.168.0.1) al nombre de dominio completamente calificado para la API de Google de Vertex AI (us-central1-aiplatform.googleapis.com).El archivo editado debería verse de la siguiente manera:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleGuarda el archivo de la siguiente manera:
- Si usas
vim, presiona la teclaEscy, a continuación, escribe:wqpara guardar el archivo y salir. - Si usas
nano, escribeControl+Oy presionaEnterpara guardar el archivo y, luego, escribeControl+Xpara salir.
- Si usas
Haz ping en el extremo de API de Vertex AI de la siguiente manera:
ping us-central1-aiplatform.googleapis.comEl comando
pingdebería devolver el siguiente resultado.192.168.0.1es la dirección IP del extremo de PSC:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Escribe
Control+Cpara salir deping.Escribe
exitpara salir de la instancia de VMon-prem-dataservice-hosty volver al mensaje de Cloud Shell.
Configura las redes para una instancia de Filestore
En esta sección, habilitarás el acceso privado a servicios para tu red de VPC, como preparación para crear una instancia de Filestore y activarla como un recurso compartido del sistema de archivos de red (NFS). Para comprender lo que harás en esta sección y en la siguiente, consulta Cómo activar un recurso compartido de NFS para el entrenamiento personalizado y Cómo configurar el intercambio de tráfico entre redes de VPC.
Habilita el acceso privado a servicios en una red de VPC
En esta sección, crearás una conexión de Service Networking y la usarás
para habilitar el acceso privado a servicios a la red de VPC
onprem-dataservice-vpc a través del intercambio de tráfico entre redes de VPC.
En Cloud Shell, establece un rango de direcciones IP reservadas con
gcloud compute addresses create:gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpcEstablece una conexión de intercambio de tráfico entre la red de VPC de
onprem-dataservice-vpcy las Herramientas de redes de servicios de Google mediantegcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpcActualiza el intercambio de tráfico entre redes de VPC para habilitar la importación y exportación de rutas aprendidas personalizadas:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routesEn la consola de Google Cloud, ve a la página Intercambio de tráfico entre redes de VPC.
En la lista de intercambios de tráfico de VPC, verifica que haya una entrada para el intercambio de tráfico entre
servicenetworking.googleapis.comy la red de VPConprem-dataservice-vpc.
Crea anuncios de ruta personalizados para filestore-subnet
En la consola de Google Cloud, ve a la página Cloud Routers.
En la lista de Cloud Router, haz clic en
onprem-dataservice-vpc-router1.En la página de detalles del router, haz clic en Editar.
En la sección Rutas anunciadas, en Rutas, selecciona Crear rutas personalizadas.
Selecciona la casilla de verificación Anunciar todas las subredes visibles para Cloud Router. Esto hará que continúe el anuncio de las subredes disponibles en el Cloud Router. Habilitar esta opción imita el comportamiento de Cloud Router en el modo de anuncio predeterminado.
Haz clic en Agregar una ruta personalizada.
En Fuente, selecciona Rango de IP personalizado.
En Rango de direcciones IP, ingresa el siguiente rango de direcciones IP:
10.243.208.0/24En Descripción, ingresa el siguiente texto:
Filestore reserved IP address rangeHaz clic en Listo y, luego, en Guardar.
Crea la instancia de Filestore en la red onprem-dataservice-vpc
Después de habilitar el acceso privado a servicios para tu red de VPC, debes crear una instancia de Filestore y activarla como un recurso compartido de NFS para tu trabajo de entrenamiento personalizado. Esto permite que los trabajos accedan a archivos remotos como si fueran locales, lo que permite una alta capacidad de procesamiento y una latencia baja.
Crea la instancia de Filestore
En la consola de Google Cloud, ve a la página Instancias de Filestore.
Haz clic en Crear instancia y configúrala como se indica a continuación:
Establece el ID de instancia en lo siguiente:
image-data-instanceConfigura el Tipo de instancia como Básico.
Configura Tipo de almacenamiento como HDD.
Establece Asigna la capacidad a 1
TiB.Establece la Región en us-central1 y la Zona en us-central1-c.
Establece la red de VPC en
onprem-dataservice-vpc.Configura el Rango de IP asignado como Usar un rango de IP asignado existente y elige
filestore-subnet.Establece el Nombre del archivo compartido en lo siguiente:
vol1Configura Controles de acceso como Otorgar acceso a todos los clientes en la red de VPC.
Haz clic en Crear.
Anota la dirección IP de tu nueva instancia de Filestore. Es posible que debas actualizar la pestaña del navegador de la consola de Google Cloud para ver la instancia nueva.
Activa los archivos compartidos de Filestore
En Cloud Shell, ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accede a la instancia de VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapInstala el paquete NFS en la instancia de VM:
sudo apt-get update -y sudo apt-get -y install nfs-commonCrea un directorio de activación para los archivos compartidos de Filestore:
sudo mkdir -p /mnt/nfsActiva el archivo compartido y reemplaza FILESTORE_INSTANCE_IP por la dirección IP de tu instancia de Filestore:
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfsSi se agota el tiempo de espera de la conexión, verifica la dirección IP correcta de la instancia de Filestore.
Ejecuta el siguiente comando para validar que la activación de NFS se realizó correctamente:
df -hVerifica que los archivos compartidos
/mnt/nfsaparezcan en el resultado:Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfsCambia los permisos para acceder a los archivos compartidos:
sudo chmod go+rw /mnt/nfs
Descarga el conjunto de datos en los archivos compartidos
En la instancia de VM de
on-prem-dataservice-host, descarga el conjunto de datos los archivos compartidos:gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursiveLa descarga tarda varios minutos.
Ejecuta el siguiente comando para confirmar que el conjunto de datos se haya copiado correctamente:
sudo du -sh /mnt/nfsEl resultado esperado es el siguiente:
104M /mnt/nfsEscribe
exitpara salir de la instancia de VMon-prem-dataservice-hosty volver al mensaje de Cloud Shell.
Crea un bucket de etapa de pruebas para tu canalización
Vertex AI Pipelines almacena los artefactos de las ejecuciones de tu canalización mediante Cloud Storage. Antes de ejecutar la canalización, debes crear un bucket de Cloud Storage para ejecuciones de canalizaciones de etapa de pruebas.
En Cloud Shell, crea un bucket de Cloud Storage:
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
Crea una cuenta de servicio administrada por el usuario para Vertex AI Workbench
En Cloud Shell, crea una cuenta de servicio:
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Asigna el rol de usuario de Vertex AI (
roles/aiplatform.user) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Asigna el rol de administrador de Artifact Registry (
artifactregistry.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"Asigna el rol de administrador de almacenamiento (
storage.admin):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"
Crea la aplicación de entrenamiento de Python
En esta sección, crearás una instancia de Vertex AI Workbench y la usarás para crear un paquete de aplicación de entrenamiento personalizado de Python.
Crea una instancia de Vertex AI Workbench
En la consola de Google Cloud, ve a la pestañaInstancias de la página Vertex AI Workbench.
Haz clic en Crear nueva y haz clic en Opciones avanzadas.
Se abrirá la página Instancia nueva.
En la página Instancia nueva, en la sección Detalles, proporciona la siguiente información para tu nueva instancia y haz clic en Continuar:
Nombre: Ingresa lo siguiente y reemplaza PROJECT_ID por el ID del proyecto:
pipeline-tutorial-PROJECT_IDRegión: selecciona us-central1.
Zona: Selecciona us-central1-a.
Desmarca la casilla de verificación Habilitar sesiones interactivas sin servidor de Dataproc.
En la sección Entorno, haz clic en Continuar.
En la sección Tipo de máquina, proporciona lo siguiente y, luego, haz clic en Continuar:
- Tipo de máquina: Elige N1 y, luego, selecciona
n1-standard-4en el menú Tipo de máquina. VM protegida: Selecciona las siguientes casillas de verificación:
- Inicio seguro
- Módulo de plataforma segura virtual (vTPM)
- Supervisión de integridad
- Tipo de máquina: Elige N1 y, luego, selecciona
En la sección Discos, asegúrate de que la Clave de encriptación administrada por Google esté seleccionada y, luego, haz clic en Continuar:
En la sección Herramientas de redes, proporciona lo siguiente y, luego, haz clic en Continuar:
Herramientas de redes: Selecciona Red en este proyecto y completa los siguientes pasos:
En el campo Red, selecciona vertex-networking-vpc.
En el campo Subred, selecciona pipeline-networking-subnet1.
Desmarca la casilla de verificación Asignar dirección IP externa. No asignar una dirección IP externa evita que la instancia reciba comunicaciones no solicitadas de Internet o de otras redes de VPC.
Selecciona la casilla de verificación Permitir el acceso mediante proxies.
En la sección IAM y seguridad, proporciona lo siguiente y, luego, haz clic en Continuar:
IAM y seguridad: Para otorgar acceso a un solo usuario a la interfaz de JupyterLab de la instancia, completa los siguientes pasos:
- Selecciona una cuenta de servicio.
- Desmarca la casilla de verificación Usar la cuenta de servicio predeterminada de Compute Engine.
Este paso es importante, ya que a la cuenta de servicio predeterminada de Compute Engine (y, por lo tanto, al usuario único que acabas de especificar) podría tener el rol de editor (
roles/editor) en tu proyecto. En el campo Correo electrónico de la cuenta de servicio, ingresa lo siguiente y reemplaza PROJECT_ID por el ID del proyecto:
workbench-sa@PROJECT_ID.iam.gserviceaccount.com(Esta es la dirección de correo electrónico de la cuenta de servicio personalizada que creaste antes). Esta cuenta de servicio tiene permisos limitados.
Si quieres obtener más información para otorgar acceso, consulta Administra el acceso a una interfaz de JupyterLab de una instancia de Vertex AI Workbench.
Opciones de seguridad: Desmarca la siguiente casilla de verificación:
- Acceso raíz a la instancia
Selecciona la siguiente casilla de verificación:
- nbconvert:
nbconvertpermite a los usuarios exportar y descargar un archivo de notebook como un tipo de archivo diferente, por ejemplo, HTML, PDF o LaTeX. Algunas de las notebooks del repositorio de GitHub de la IA generativa de Google Cloud requieren esta configuración.
Desmarca la siguiente casilla de verificación:
- Descarga de archivos
Selecciona la siguiente casilla de verificación, a menos que estés en un entorno de producción:
- Acceso a la terminal: Esto habilita el acceso a la terminal a tu instancia desde la interfaz de usuario de JupyterLab.
En la sección Estado del sistema, desactiva Actualización automática del entorno y proporciona lo siguiente:
En Informes, selecciona las siguientes casillas de verificación:
- Genera informes sobre el estado del sistema
- Generar informes sobre las métricas personalizadas en Cloud Monitoring
- Instalar Cloud Monitoring
- Informar el estado de DNS de los dominios de Google obligatorios
Haz clic en Crear y espera unos minutos para que se cree la instancia de Vertex AI Workbench.
Ejecuta la aplicación de entrenamiento en la instancia de Vertex AI Workbench
En la consola de Google Cloud, ve a la pestañaInstancias. de la página Vertex AI Workbench.
Junto al nombre de la instancia de Vertex AI Workbench (
pipeline-tutorial-PROJECT_ID), donde PROJECT_ID es el ID del proyecto, haz clic en Abrir JupyterLab.Tu instancia de Vertex AI Workbench abre JupyterLab.
Selecciona Archivo > Nuevo > Terminal.
En la terminal de JupyterLab (no en Cloud Shell), define una variable de entorno para tu proyecto. Reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_IDCrea los directorios superiores para la aplicación de entrenamiento (aún en la terminal de JupyterLab):
mkdir fungi_training_package mkdir fungi_training_package/trainerEn el navegador de archivos , haz doble clic en la carpeta
fungi_training_packagey, luego, en la carpetatrainer.En el navegador de archivos , haz clic con el botón derecho en la lista de archivos vacía (debajo del encabezado Nombre) y selecciona Nuevo archivo.
Haz clic con el botón derecho en el archivo nuevo y selecciona Cambiar nombre del archivo.
Cambia el nombre del archivo de
untitled.txtatask.py.Haz doble clic en el archivo
task.pypara abrirlo.Copia el siguiente código en
task.py:# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)Selecciona File > Save Python file.
En la terminal de JupyterLab, crea un archivo
__init__.pyen cada subdirectorio para convertirlo en un paquete:touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.pyEn el navegador de archivos , haz doble clic en la nueva carpeta
fungi_training_package.Selecciona File > New > Python file.
Haz clic con el botón derecho en el archivo nuevo y selecciona Cambiar nombre del archivo.
Cambia el nombre del archivo de
untitled.pyasetup.py.Haz doble clic en el archivo
setup.pypara abrirlo.Copia el siguiente código en
setup.py:from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )Selecciona File > Save Python file.
En la terminal, navega al directorio
fungi_training_package:cd fungi_training_packageUsa el comando
sdistpara crear la distribución de fuente de la aplicación de entrenamiento:python setup.py sdist --formats=gztarNavega al directorio principal:
cd ..Verifica que estás en el directorio correcto:
pwdLa salida obtenida se verá así:
/home/jupyterCopia el paquete de Python en el bucket de etapa de pruebas:
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/Verifica que el bucket de etapa de pruebas contenga el paquete:
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_packageEl resultado es el siguiente:
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
Crea la conexión de Service Networking para Vertex AI Pipelines
En esta sección, crearás una conexión de Service Networking que se usa para establecer servicios de productor conectados a la red de VPC vertex-networking-vpc a través del intercambio de tráfico entre redes de VPC. Para obtener más información, consulta Intercambio de tráfico entre redes de VPC.
En Cloud Shell, ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Configura un rango de direcciones IP reservado con
gcloud compute addresses create:gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpcEstablece una conexión de intercambio de tráfico entre la red de VPC de
vertex-networking-vpcy las Herramientas de redes de servicios de Google mediantegcloud services vpc-peerings connect:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpcActualiza la conexión de intercambio de tráfico de VPC para habilitar la importación y exportación de rutas aprendidas personalizadas:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
Anuncia la subred de la canalización desde el Cloud Router de pipeline-networking
En la consola de Google Cloud, ve a la página de Cloud Router.
En la lista de Cloud Router, haz clic en
vertex-networking-vpc-router1.En la página de detalles del router, haz clic en Editar.
Haz clic en Agregar una ruta personalizada.
En Fuente, selecciona Rango de IP personalizado.
En Rango de direcciones IP, ingresa el siguiente rango de direcciones IP:
192.168.10.0/24En Descripción, ingresa el siguiente texto:
Vertex AI Pipelines reserved subnetHaz clic en Listo y, luego, en Guardar.
Crea una plantilla de canalización y súbela a Artifact Registry
En esta sección, crearás y subirás una plantilla de canalización de Kubeflow Pipelines (KFP). Esta plantilla contiene una definición de flujo de trabajo que se puede reutilizar varias veces, por un solo usuario o por varios.
Define y compila la canalización
En JupyterLab, en el Navegador de archivos , haz doble clic en la carpeta de nivel superior.
Select Archivo > Nuevo > Notebook.
En el menú Seleccionar kernel, selecciona
Python 3 (ipykernel)y haz clic en Seleccionar.En una celda de notebook nueva, ejecuta el siguiente comando para asegurarte de que tengas la versión más reciente de
pip:!python -m pip install --upgrade pipEjecuta el siguiente comando para instalar el SDK de componentes de canalización de Google Cloud desde el índice de paquetes de Python (PyPI):
!pip install --upgrade google-cloud-pipeline-componentsCuando finalice la instalación, selecciona Kernel > Reiniciar kernel para reiniciar el kernel y asegúrate de que la biblioteca esté disponible para importar
Ejecuta el siguiente código en una celda nueva del notebook para definir la canalización:
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )Ejecuta el siguiente código en una celda nueva del notebook para compilar la definición de la canalización:
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )En el navegador de archivos , aparece un archivo llamado
pipeline_config.yamlen la lista de archivos.
Crea un repositorio de Artifact Registry
Ejecuta el siguiente código en una celda de notebook nueva para crear un repositorio de artefactos de tipo KFP:
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
Sube la plantilla de canalización a Artifact Registry
En esta sección, configurarás un cliente de registro del SDK de Kubeflow Pipelines y subirás tu plantilla de canalización compilada a Artifact Registry desde tu notebook de JupyterLab.
En tu notebook de JupyterLab, ejecuta el siguiente código para subir la plantilla de canalización y reemplaza PROJECT_ID por el ID de tu proyecto:
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})En la consola de Google Cloud, para verificar que se subió tu plantilla, ve a Plantillas de Vertex AI Pipelines.
Para abrir el panel Seleccionar repositorio, haz clic en Seleccionar repositorio.
En la lista de repositorios, haz clic en el repositorio que creaste (
fungi-repo) y, luego, en Seleccionar.Verifica que tu canalización (
custom-image-classification-pipeline) aparezca en la lista.
Activa una ejecución de canalización de forma local
En esta sección, ahora que tu plantilla de canalización y paquete de entrenamiento están listos, usarás cURL para activar una ejecución de canalización desde tu aplicación local.
Proporciona los parámetros de canalización
En tu notebook de JupyterLab, ejecuta el siguiente comando para verificar el nombre de la plantilla de canalización:
print (TEMPLATE_NAME)El nombre de la plantilla que se muestra es el siguiente:
custom-image-classification-pipelineEjecuta el siguiente comando para obtener la versión de la plantilla de canalización:
print (VERSION_NAME)El nombre de la versión de la plantilla de canalización que se muestra es el siguiente:
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7Anota toda la cadena de nombre de la versión.
En Cloud Shell, ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accede a la instancia de VM
on-prem-dataservice-host:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapEn la instancia de VM
on-prem-dataservice-host, usa un editor de texto, comovimonanopara crear el archivorequest_body.json, por ejemplo:sudo vim request_body.jsonAgrega el siguiente texto al archivo
request_body.json.{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.iam.gserviceaccount.com", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }Reemplaza los siguientes valores:
- PROJECT_ID: El ID de tu proyecto
- PROJECT_NUMBER: Número del proyecto Es diferente del ID del proyecto. Puedes encontrar el número de proyecto en la página Configuración del proyecto del proyecto en la consola de Google Cloud.
- FILESTORE_INSTANCE_IP: Es la dirección IP de la instancia de Filestore, por ejemplo,
10.243.208.2. Puedes encontrarlo en la página Instancias de Filestore de tu instancia. - VERSION_NAME: El nombre de la versión de la plantilla de canalización (
sha256:...) que anotaste en el paso 2.
Guarda el archivo de la siguiente manera:
- Si usas
vim, presiona la teclaEscy, a continuación, escribe:wqpara guardar el archivo y salir. - Si usas
nano, escribeControl+Oy presionaEnterpara guardar el archivo y, luego, escribeControl+Xpara salir.
- Si usas
Crea una ejecución de canalización a partir de tu plantilla
En la instancia de VM
on-prem-dataservice-host, ejecuta el siguiente comando y reemplaza PROJECT_ID por el ID del proyecto:curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobsEl resultado que ves es extenso, pero lo principal que debes buscar es la siguiente línea, que indica que el servicio se está preparando para ejecutar la canalización:
"state": "PIPELINE_STATE_PENDING"La ejecución completa de la canalización tarda entre 45 y 50 minutos.
En la consola de Google Cloud, en la sección Vertex AI, ve a la pestaña Ejecuciones en la página Canalizaciones.
Haz clic en el nombre de la ejecución de tu canalización (
custom-image-classification-pipeline).Aparecerá la página de ejecución de la canalización y el gráfico del entorno de ejecución de la canalización. El resumen de la canalización aparece en el panel Pipeline run analysis.
Si necesitas ayuda para comprender la información que se muestra en el gráfico del tiempo de ejecución, incluida la forma de ver registros y usar Vertex ML Metadata para obtener más información sobre los artefactos de tu canalización, consulta Visualiza y analiza los resultados de las canalizaciones.
Limpia
Para evitar que se apliquen cargos a su cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Puedes borrar los recursos individuales del proyecto de la siguiente manera:
Borra todas las ejecuciones de canalización de la siguiente manera:
En la consola de Google Cloud, en la sección Vertex AI, ve a la pestaña Ejecuciones en la página Canalizaciones.
Selecciona las ejecuciones de canalización que quieres borrar y haz clic en Borrar.
Borra la plantilla de canalización de la siguiente manera:
En la sección Vertex AI, ve a la pestaña Tus plantillas en la página Canalizaciones.
Junto a la plantilla de canalización
custom-image-classification-pipeline, haz clic en Acciones y selecciona Borrar.
Borra el repositorio de Artifact Registry de la siguiente manera:
En la página Artifact Registry, ve a la pestaña Repositories.
Selecciona el repositorio
fungi-repoy haz clic en Borrar.
Anula la implementación del modelo desde el extremo de la siguiente manera:
En la sección Vertex AI, ve a la pestaña Extremos de la página Predicciones en línea.
Haz clic en
fungi-image-endpointpara ir a la página de detalles del extremo.En la fila de tu modelo,
fungi-image-model, haz clic en Acciones y selecciona Anular la implementación del modelo en el extremo.En el cuadro de diálogo Anular la implementación del modelo desde el extremo, haz clic en Anular la implementación.
Borra el extremo de la siguiente manera:
En la sección Vertex AI, ve a la pestaña Extremos de la página Predicciones en línea.
Selecciona
fungi-image-endpointy haz clic en Borrar.
Borra el modelo de la siguiente manera:
Ve a la página Model Registry.
En la fila de tu modelo,
fungi-image-model, haz clic en Acciones y selecciona Borrar modelo.
Borra el bucket de pruebas de la siguiente manera:
Ve a la página Cloud Storage.
Selecciona
pipelines-staging-bucket-PROJECT_ID, donde PROJECT_ID es el ID del proyecto, y haz clic en Borrar.
Borra la instancia de Vertex AI Workbench de la siguiente manera:
En la sección Vertex AI, ve a la pestaña Instancias en la página Workbench.
Selecciona la instancia de Vertex AI Workbench
pipeline-tutorial-PROJECT_ID, en la que PROJECT_ID es el ID del proyecto, y haz clic en Borrar.
Borra la instancia de VM de Compute Engine de la siguiente manera:
Ir a la página Compute Engine
Selecciona la instancia de VM
on-prem-dataservice-hosty haz clic en Borrar.
Borra los túneles VPN de la siguiente manera:
Ir a la página de VPN.
En la página VPN, haz clic en la pestaña Túneles de Cloud VPN.
En la lista de túneles VPN, selecciona los cuatro túneles VPN que creaste en este instructivo y haz clic en Borrar.
Borra las puertas de enlace de VPN con alta disponibilidad de la siguiente manera:
En la página VPN, haz clic en la pestaña Puertas de enlace de Cloud VPN.
En la lista de puertas de enlace de VPN, haz clic en
onprem-vpn-gw1.En la página Detalles de la puerta de enlace de Cloud VPN, haz clic en Borrar puerta de enlace de VPN.
Haz clic en la flecha hacia atrás si es necesario para regresa a la lista de puertas de enlace de VPN y, luego, haz clic en
vertex-networking-vpn-gw1En la página Detalles de la puerta de enlace de Cloud VPN, haz clic en Borrar puerta de enlace de VPN.
Borra los Cloud Routers de la siguiente manera:
Ve a la página Cloud Routers.
En la lista de Cloud Routers, selecciona los cuatro routers que creaste en este instructivo.
Para borrar los routers, haz clic en Borrar.
Esta acción también borrará las dos puertas de enlace de Cloud NAT que están conectadas a los Cloud Routers.
Borra las conexiones de redes de servicios a las redes de VPC
vertex-networking-vpcyonprem-dataservice-vpcde la siguiente manera:Ir a la página Intercambio de tráfico entre redes de VPC.
Selecciona
servicenetworking-googleapis-com.Para borrar las conexiones, haz clic en Borrar.
Borra la regla de reenvío
pscvertexpara la red de VPCvertex-networking-vpcde la siguiente manera:Ve a la pestaña Frontends de la página Balanceo de cargas.
En la lista de reglas de reenvío, haz clic en
pscvertex.En la página Detalles de la regla de reenvío, haz clic en Borrar.
Sigue estos pasos para borrar la instancia de Filestore:
Ir a la página de Filestore
Selecciona la instancia
image-data-instance.Para borrar la instancia, haz clic en Acciones y, luego, en Borrar instancia.
Borra las redes de VPC de la siguiente manera:
Ir a la página de redes de VPC
En la lista de redes de VPC, haz clic en
onprem-dataservice-vpc.En la página Detalles de la red de VPC, haz clic en Borrar la red de VPC.
Borrar cada red también borra sus subredes, rutas y reglas de firewall.
En la lista de redes de VPC, haz clic en
vertex-networking-vpc.En la página Detalles de la red de VPC, haz clic en Borrar la red de VPC.
Borra las cuentas de servicio
workbench-sayonprem-user-managed-sade la siguiente manera:Ve a la página Cuentas de servicio.
Selecciona las cuentas de servicio
onprem-user-managed-sayworkbench-say haz clic en Borrar.
¿Qué sigue?
Aprende a usar Vertex AI Pipelines para organizar el proceso de compilación e implementación de tus modelos de aprendizaje automático.
Obtén información sobre el conjunto de datos de deFungi.