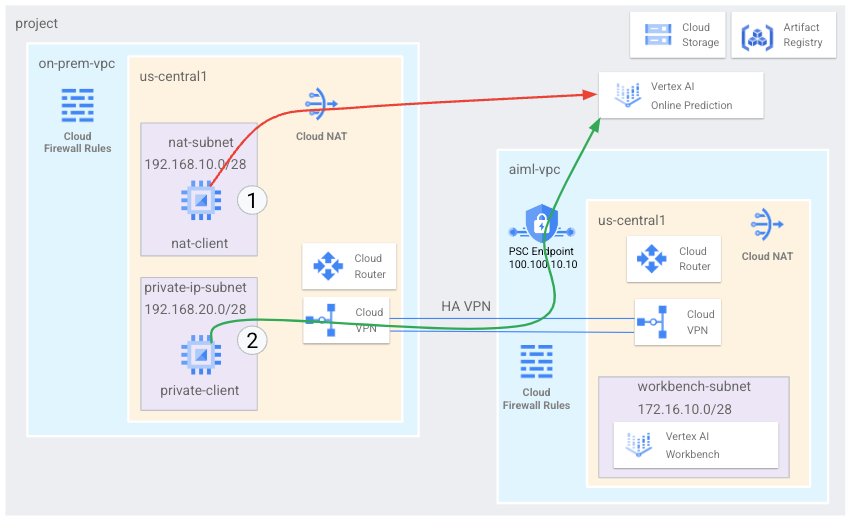
Los hosts locales pueden acceder a un extremo de predicción en línea de Vertex AI, ya sea a través de la Internet pública o de forma privada mediante una arquitectura de red híbrida que usa Private Service Connect (PSC) a través de Cloud VPN o Cloud Interconnect. Ambas opciones ofrecen encriptación SSL/TLS. Sin embargo, la opción privada ofrece un rendimiento mucho mejor y, por lo tanto, se recomienda para aplicaciones esenciales.
En este instructivo, usarás una VPN de alta disponibilidad (VPN con alta disponibilidad) para acceder a un extremo de predicción en línea de forma pública, a través de Cloud NAT y de forma privada, entre dos redes de nube privada virtual que pueden funcionar como una base para la conectividad privada local y de múltiples nubes.
Este instructivo está dirigido a administradores de redes empresariales, investigadores y científicos de datos que estén familiarizados con Vertex AI, la nube privada virtual (VPC), la consola de Google Cloud y Cloud Shell. Estar familiarizado con Vertex AI Workbench es útil, pero no obligatorio.
Objetivos
- Crear dos redes de nube privada virtual (VPC), como se muestra en el diagrama anterior:
- Una (
on-prem-vpc) representa una red local. - La otra (
aiml-vpc) es para compilar y, luego, implementar un modelo de predicción en línea de Vertex AI.
- Una (
- Implementa puertas de enlace de VPN con alta disponibilidad, túneles de Cloud VPN y Cloud Routers para conectar
aiml-vpcyon-prem-vpc. - Compila y, luego, implementa un modelo de predicción en línea de Vertex AI.
- Crea un extremo de Private Service Connect (PSC) para reenviar solicitudes de predicción en línea privadas al modelo implementado.
- Habilita el modo de anuncio personalizado de Cloud Router en
aiml-vpcpara anunciar rutas para el extremo de Private Service Connect aon-prem-vpc. - Crea dos instancias de VM de Compute Engine en
on-prem-vpcpara representar aplicaciones cliente de la siguiente forma:- Una (
nat-client) envía solicitudes de predicción en línea sobre la Internet pública (a través de Cloud NAT). Este método de acceso se indica por una flecha roja y el número 1 en el diagrama. - La otra (
private-client) envía solicitudes de predicción de forma privada a través de VPN con alta disponibilidad. Este método de acceso se indica con una flecha verde y el número 2.
- Una (
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Cuando finalices las tareas que se describen en este documento, puedes borrar los recursos que creaste para evitar que continúe la facturación. Para obtener más información, consulta Cómo realizar una limpieza.
Antes de comenzar
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Abre Cloud Shell para ejecutar los comandos detallados en este instructivo. Cloud Shell es un entorno de shell interactivo para Google Cloud que te permite administrar proyectos y recursos desde el navegador web.
- En Cloud Shell, establece el proyecto actual como el
ID del proyecto Google Cloud y almacena el mismo
ID del proyecto en la variable de shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/appengine.appViewer, roles/artifactregistry.admin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/oauthconfig.editor, roles/resourcemanager.projectIamAdmin, roles/servicemanagement.quotaAdmin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/storage.admin, roles/aiplatform.usergcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
- Replace
PROJECT_IDwith your project ID. -
Replace
USER_IDENTIFIERwith the identifier for your user account. For example,user:myemail@example.com. - Replace
ROLEwith each individual role.
- Replace
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Notebooks, and Vertex AI APIs:
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com notebooks.googleapis.com aiplatform.googleapis.com
Crea las redes de VPC
En esta sección, crearás dos redes de VPC: una para crear un modelo de predicción en línea y, luego, implementarla en un extremo, la otra para el acceso privado a ese extremo. En cada una de las dos redes de VPC, debes crear un Cloud Router y una puerta de enlace de Cloud NAT. Una puerta de enlace de Cloud NAT proporciona conectividad saliente para las instancias de máquina virtual (VM) de Compute Engine sin direcciones IP externas.
Crea la red de VPC para el extremo de predicción en línea (aiml-vpc)
Crea la red de VPC:
gcloud compute networks create aiml-vpc \ --project=$projectid \ --subnet-mode=customCrea una subred llamada
workbench-subnet, con un rango IPv4 principal de172.16.10.0/28gcloud compute networks subnets create workbench-subnet \ --project=$projectid \ --range=172.16.10.0/28 \ --network=aiml-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCrea un Cloud Router regional llamado
cloud-router-us-central1-aiml-nat:gcloud compute routers create cloud-router-us-central1-aiml-nat \ --network aiml-vpc \ --region us-central1Agrega una puerta de enlace de Cloud NAT al Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Crea la red de VPC “local” (on-prem-vpc)
Crea la red de VPC:
gcloud compute networks create on-prem-vpc \ --project=$projectid \ --subnet-mode=customCrea una subred llamada
nat-subnet, con un rango IPv4 principal de192.168.10.0/28gcloud compute networks subnets create nat-subnet \ --project=$projectid \ --range=192.168.10.0/28 \ --network=on-prem-vpc \ --region=us-central1Crea una subred llamada
private-ip-subnet, con un rango IPv4 principal de192.168.20.0/28gcloud compute networks subnets create private-ip-subnet \ --project=$projectid \ --range=192.168.20.0/28 \ --network=on-prem-vpc \ --region=us-central1Crea un Cloud Router regional llamado
cloud-router-us-central1-on-prem-nat:gcloud compute routers create cloud-router-us-central1-on-prem-nat \ --network on-prem-vpc \ --region us-central1Agrega una puerta de enlace de Cloud NAT al Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-on-prem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Crea el extremo de Private Service Connect (PSC)
En esta sección, crearás el extremo de Private Service Connect (PSC)
que usan las instancias de VM en la red on-prem-vpc para acceder al
extremo de predicción en línea a través de la API de Vertex AI.
El extremo de Private Service Connect (PSC) es una dirección IP
interna en la red on-prem-vpc a la que pueden acceder directamente los clientes
de esa red. Este extremo se crea mediante la implementación de una regla de reenvío que dirige el tráfico de red que coincide con la dirección IP del extremo de PSC con un paquete de APIs de Google.
La dirección IP del extremo de PSC (100.100.10.10) se anunciará desde el
Cloud Router aiml-cr-us-central1 como una ruta anunciada personalizada a la red on-prem-vpc en un paso posterior.
Reserva direcciones IP para el extremo de PSC:
gcloud compute addresses create psc-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=100.100.10.10 \ --network=aiml-vpcCrea el extremo de PSC:
gcloud compute forwarding-rules create pscvertex \ --global \ --network=aiml-vpc \ --address=psc-ip \ --target-google-apis-bundle=all-apisEnumera los extremos configurados de PSC y verifica que se haya creado el extremo
pscvertex:gcloud compute forwarding-rules list \ --filter target="(all-apis OR vpc-sc)" --globalObtén los detalles del extremo de PSC configurado y verifica que la dirección IP sea
100.100.10.10:gcloud compute forwarding-rules describe pscvertex \ --global
Configura la conectividad híbrida
En esta sección, crearás dos puertas de enlace de (VPN con alta disponibilidad) que están conectadas entre sí. Cada puerta de enlace contiene un Cloud Router y un par de túneles VPN.
Crea la puerta de enlace de VPN con alta disponibilidad para la red de VPC
aiml-vpc:gcloud compute vpn-gateways create aiml-vpn-gw \ --network=aiml-vpc \ --region=us-central1Crea la puerta de enlace de VPN con alta disponibilidad para la red de VPC
on-prem-vpc:gcloud compute vpn-gateways create on-prem-vpn-gw \ --network=on-prem-vpc \ --region=us-central1En la consola de Google Cloud, ve a la página VPN.
En la página VPN, haz clic en la pestaña Puertas de enlace de Cloud VPN.
En la lista de puertas de enlace de VPN, verifica que existan dos puertas de enlace y que cada una tenga dos direcciones IP.
En Cloud Shell, crea un Cloud Router para la red de nube privada virtual
aiml-vpc:gcloud compute routers create aiml-cr-us-central1 \ --region=us-central1 \ --network=aiml-vpc \ --asn=65001Crea un Cloud Router para la red de nube privada virtual
on-prem-vpc:gcloud compute routers create on-prem-cr-us-central1 \ --region=us-central1 \ --network=on-prem-vpc \ --asn=65002
Crea los túneles VPN para aiml-vpc
Crea un túnel VPN llamado
aiml-vpc-tunnel0:gcloud compute vpn-tunnels create aiml-vpc-tunnel0 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 0Crea un túnel VPN llamado
aiml-vpc-tunnel1:gcloud compute vpn-tunnels create aiml-vpc-tunnel1 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 1
Crea los túneles VPN para on-prem-vpc
Crea un túnel VPN llamado
on-prem-vpc-tunnel0:gcloud compute vpn-tunnels create on-prem-tunnel0 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 0Crea un túnel VPN llamado
on-prem-vpc-tunnel1:gcloud compute vpn-tunnels create on-prem-tunnel1 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 1En la consola de Google Cloud, ve a la página VPN.
En la página VPN, haz clic en la pestaña Túneles de Cloud VPN.
En la lista de túneles VPN, verifica que se hayan configurado cuatro.
Establece sesiones de BGP
Cloud Router usa el protocolo de puerta de enlace fronteriza (BGP) para intercambiar rutas entre tu red de VPC (en este caso, aiml-vpc) y tu red local (representada por on-prem-vpc). En Cloud Router, configura una interfaz y un par de BGP para tu router local.
La interfaz y la configuración de par de BGP juntas forman una sesión de BGP.
En esta sección, crearás dos sesiones de BGP para aiml-vpc y
dos para on-prem-vpc.
Establece sesiones de BGP para aiml-vpc
En Cloud Shell, crea la primera interfaz de BGP:
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel0 \ --region us-central1Crea el primer intercambio de tráfico de BGP:
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel0 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1Crea la segunda interfaz de BGP:
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.2.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel1 \ --region us-central1Crea el segundo intercambio de tráfico de BGP:
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel1 \ --interface if-tunnel2-to-onprem \ --peer-ip-address 169.254.2.2 \ --peer-asn 65002 \ --region us-central1
Establece sesiones de BGP para on-prem-vpc
Crea la primera interfaz de BGP:
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel0-to-aiml-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel0 \ --region us-central1Crea el primer intercambio de tráfico de BGP:
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel0 \ --interface if-tunnel1-to-aiml-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1Crea la segunda interfaz de BGP:
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel1-to-aiml-vpc \ --ip-address 169.254.2.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel1 \ --region us-central1Crea el segundo intercambio de tráfico de BGP:
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel1 \ --interface if-tunnel2-to-aiml-vpc \ --peer-ip-address 169.254.2.1 \ --peer-asn 65001 \ --region us-central1
Valida la creación de sesiones de BGP
En la consola de Google Cloud, ve a la página VPN.
En la página VPN, haz clic en la pestaña Túneles de Cloud VPN.
En la lista de túneles VPN, deberías ver que el valor en la columna Estado de la sesión de BGP para cada uno de los cuatro túneles cambió de Configura la sesión de BGP a BGP establecida. Es posible que debas actualizar la pestaña del navegador de la consola de Google Cloud para ver los valores nuevos.
Valida que aiml-vpc haya aprendido rutas de subred a través de VPN con alta disponibilidad
En la consola de Google Cloud, ve a la página Redes de VPC.
En la lista de redes de VPC, haz clic en
aiml-vpc.Haz clic en la pestaña Rutas.
Selecciona us-central1 (Iowa) en la lista Región y haz clic en Ver.
En la columna Rango de IP de destino, verifica que la red de VPC
aiml-vpcaprendió rutas desde la subrednat-subnetde las redes de VPCon-prem-vpc(192.168.10.0/28) y la subredprivate-ip-subnet(192.168.20.0/28).
Valida que on-prem-vpc haya aprendido rutas de subred a través de VPN con alta disponibilidad
En la consola de Google Cloud, ve a la página Redes de VPC.
En la lista de redes de VPC, haz clic en
on-prem-vpc.Haz clic en la pestaña Rutas.
Selecciona us-central1 (Iowa) en la lista Región y haz clic en Ver.
En la columna Rango de IP de destino, verifica que la red de VPC
on-prem-vpcaprendió rutas desde la subredworkbench-subnetde las redes de VPCaiml-vpc(172.16.10.0/28).
Crea una ruta anunciada personalizada para aiml-vpc
El Cloud Router aiml-cr-us-central1 no anuncia de forma automática
la dirección IP del extremo de Private Service Connect porque la subred
no está configurada en la red de VPC.
Por lo tanto, deberás crear una ruta anunciada personalizada desde
el Cloud Router aiml-cr-us-central para la dirección IP del extremo 100.100.10.10
que se anuncia al entorno local a través de BGP a on-prem-vpc.
En la consola de Google Cloud, ve a la página Cloud Routers.
En la lista de Cloud Router, haz clic en
aiml-cr-us-central1.En la página de detalles del router, haz clic en Editar.
En la sección Rutas anunciadas, en Rutas, selecciona Crear rutas personalizadas.
Haz clic en Agregar una ruta personalizada.
En Fuente, selecciona Rango de IP personalizado.
En Rango de direcciones IP, ingresa
100.100.10.10.En Descripción, ingresa
Private Service Connect Endpoint IP.Haz clic en Listo y, luego, en Guardar.
Valida que on-prem-vpc haya aprendido la dirección IP del extremo de PSC a través de la VPN con alta disponibilidad
En la consola de Google Cloud, ve a la página Redes de VPC.
En la lista de redes de VPC, haz clic en
on-prem-vpc.Haz clic en la pestaña Rutas.
Selecciona us-central1 (Iowa) en la lista Región y haz clic en Ver.
En la columna Rango de IP de destino, verifica que la red de VPC
on-prem-vpchay aprendido la dirección IP del extremo de PSC (100.100.10.10).
Crea una ruta anunciada personalizada para on-prem-vpc
El Cloud Router on-prem-vpc anuncia todas las subredes de forma predeterminada, pero solo se necesita la subred private-ip-subnet.
En la siguiente sección, actualiza los anuncios de ruta del Cloud Router on-prem-cr-us-central1.
En la consola de Google Cloud, ve a la página Cloud Routers.
En la lista de Cloud Router, haz clic en
on-prem-cr-us-central1.En la página de detalles del router, haz clic en Editar.
En la sección Rutas anunciadas, en Rutas, selecciona Crear rutas personalizadas.
Desmarca la casilla de verificación Anunciar todas las subredes visibles para Cloud Router si está seleccionada.
Haz clic en Agregar una ruta personalizada.
En Fuente, selecciona Rango de IP personalizado.
En Rango de direcciones IP, ingresa
192.168.20.0/28.En Descripción, ingresa
Private Service Connect Endpoint IP subnet (private-ip-subnet).Haz clic en Listo y, luego, en Guardar.
Valida que aiml-vpc haya aprendido la ruta private-ip-subnet desde on-prem-vpc.
En la consola de Google Cloud, ve a la página Redes de VPC.
En la lista de redes de VPC, haz clic en
aiml-vpc.Haz clic en la pestaña Rutas.
Selecciona us-central1 (Iowa) en la lista Región y haz clic en Ver.
En la columna Rango de IP de destino, verifica que la red de VPC
aiml-vpchay aprendido la rutaprivate-ip-subnet(192.168.20.0/28).
Crea las instancias de VM de prueba
Crea una cuenta de servicio administrada por el usuario.
Si tienes aplicaciones que necesitan llamar a las APIs de Google Cloud , Google recomienda que conectes una cuenta de servicio administrada por el usuario a la VM en la que se ejecuta la aplicación o la carga de trabajo. Por lo tanto, en esta sección se crea una cuenta de servicio administrada por el usuario para que se aplique a las instancias de VM que crees más adelante en este instructivo.
En Cloud Shell, crea la cuenta de servicio :
gcloud iam service-accounts create gce-vertex-sa \ --description="service account for vertex" \ --display-name="gce-vertex-sa"Asigna el rol de administrador de instancias de Compute (v1) (
roles/compute.instanceAdmin.v1) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/compute.instanceAdmin.v1"Asigna el rol de IAM de usuario de Vertex AI (
roles/aiplatform.user) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"
Crea las instancias de VM de prueba
En este paso, crearás instancias de VM de prueba para validar diferentes métodos para llegar a las APIs de Vertex AI, específicamente:
- La instancia
nat-clientusa Cloud NAT para resolver Vertex AI para acceder al extremo de predicción en línea a través de la Internet pública. - La instancia
private-clientusa la dirección IP de Private Service Connect100.100.10.10para acceder al extremo de predicción en línea a través de una VPN con alta disponibilidad.
Para permitir que Identity-Aware Proxy (IAP) se conecte a tus instancias de VM, crea una regla de firewall que cumpla con lo siguiente:
- Se aplica a todas las instancias de VM que deseas que sean accesibles a través de IAP.
- Permite el tráfico de TCP a través del puerto 22 desde el rango de IP
35.235.240.0/20. Este rango contiene todas las direcciones IP que IAP usa para el reenvío de TCP.
Crea la instancia de VM
nat-client:gcloud compute instances create nat-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=nat-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crea la instancia de VM
private-client:gcloud compute instances create private-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=private-ip-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crea la regla de firewall de IAP:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network on-prem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Crea una instancia de Vertex AI Workbench
Crea una cuenta de servicio administrada por el usuario para Vertex AI Workbench
Cuando creas una instancia de Vertex AI Workbench,
Google recomienda que especifiques una cuenta de servicio administrada por el usuario en lugar
de usar la cuenta de servicio predeterminada de Compute Engine.
Si tu organización no aplica la restricción de la política de la organización iam.automaticIamGrantsForDefaultServiceAccounts, se le otorga el rol de editor a la cuenta de servicio predeterminada de Compute Engine (y, por lo tanto, a cualquier persona que especifiques como usuario de la instancia) (roles/editor) en tu proyectoGoogle Cloud . Para desactivar este comportamiento, consulta Inhabilita la asignación automática de roles para las cuentas de servicio predeterminadas.
En Cloud Shell, crea una cuenta de servicio llamada
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Asigna el rol de IAM de administrador de almacenamiento (
roles/storage.admin) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"Asigna el rol de IAM de usuario de Vertex AI (
roles/aiplatform.user) a la cuenta de servicio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Asigna el rol de IAM de administrador de Artifact Registry a la cuenta de servicio:
gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"
Crea la instancia de Vertex AI Workbench
En Cloud Shell, crea una instancia de Vertex AI Workbench y especifica la cuenta de servicio
workbench-sa:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.com
Crea e implementa un modelo de predicción en línea
Prepare el entorno
En la consola de Google Cloud, ve a la pestañaInstancias. de la página Vertex AI Workbench.
Junto al nombre de la instancia de Vertex AI Workbench (
workbench-tutorial), haz clic en Abrir JupyterLab.Tu instancia de Vertex AI Workbench abre JupyterLab.
En el resto de esta sección, incluso hasta la implementación del modelo, trabajarás en Jupyterlab, no en la consola de Google Cloud o Cloud Shell.
Selecciona Archivo > Nuevo > Terminal.
En la terminal de JupyterLab (no en Cloud Shell), define una variable de entorno para tu proyecto. Reemplaza PROJECT_ID por el ID del proyecto:
PROJECT_ID=PROJECT_IDCrea un directorio nuevo llamado
cpr-codelabycden él (aún en la terminal de JupyterLab):mkdir cpr-codelab cd cpr-codelabEn el navegador de archivos , haz doble clic en la nueva carpeta
cpr-codelab.Si esta carpeta no aparece en el navegador de archivos, actualiza la pestaña del navegador de la consola de Google Cloud console y vuelve a intentarlo.
Select Archivo > Nuevo > Notebook.
En el menú Seleccionar Kernel, selecciona Python [conda env:base] * (Local) y haz clic en Seleccionar.
Cambia el nombre del archivo de notebook nuevo de la siguiente manera:
En el navegador de archivos , haz clic con el botón derecho en el ícono de archivo
Untitled.ipynby, luego, ingresatask.ipynb.Tu directorio
cpr-codelabdebería verse de la siguiente manera:+ cpr-codelab/ + task.ipynbEn los siguientes pasos, crearás tu modelo en el notebook de JupyterLab. Para ello, crea nuevas celdas de notebook, pega los códigos en ellas, y ejecuta las celdas.
Instala las dependencias de la siguiente manera.
Cuando abres tu notebook nuevo, se genera una celda de código predeterminada en la que puedes ingresar el código. Parece
[ ]:seguido de un campo de texto. Ese campo de texto es donde pegas tu código.Pega el siguiente código en la celda y haz clic en Ejecutar las celdas seleccionadas y avanzar para crear un archivo
requirements.txtque se usará como entrada en la celda paso siguiente:%%writefile requirements.txt fastapi uvicorn==0.17.6 joblib~=1.1.1 numpy>=1.17.3, <1.24.0 scikit-learn>=1.2.2 pandas google-cloud-storage>=2.2.1,<3.0.0dev google-cloud-aiplatform[prediction]>=1.18.2En este paso y cada uno de los siguientes, haz agrega una celda de código haciendo clic en Insertar una celda a continuación, pega el código en la celda y haz clic en Ejecutar las celdas seleccionadas y avanza.
Usa
Pippara instalar dependencias en la instancia de notebooks:!pip install -U --user -r requirements.txtCuando finalice la instalación, selecciona Kernel > Reiniciar kernel para reiniciar el kernel y asegúrate de que la biblioteca esté disponible para importar
Pega el siguiente código en una celda de notebook nueva para crear los directorios para almacenar el modelo y los artefactos de procesamiento previo:
USER_SRC_DIR = "src_dir" !mkdir $USER_SRC_DIR !mkdir model_artifacts # copy the requirements to the source dir !cp requirements.txt $USER_SRC_DIR/requirements.txt
En el navegador de archivos , la estructura de tu directorio
cpr-codelabahora debería verse de la siguiente manera:+ cpr-codelab/ + model_artifacts/ + src_dir/ + requirements.txt + requirements.txt + task.ipynb
Entrenar el modelo
Sigue agregando celdas de código al notebook task.ipynb, y pega y
ejecuta el siguiente código en cada celda nueva:
Importa las bibliotecas:
import seaborn as sns import numpy as np import pandas as pd from sklearn import preprocessing from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import make_pipeline from sklearn.compose import make_column_transformer import joblib import logging # set logging to see the docker container logs logging.basicConfig(level=logging.INFO)Define las siguientes variables y reemplaza PROJECT_ID por el ID del proyecto:
REGION = "us-central1" MODEL_ARTIFACT_DIR = "sklearn-model-artifacts" REPOSITORY = "diamonds" IMAGE = "sklearn-image" MODEL_DISPLAY_NAME = "diamonds-cpr" PROJECT_ID = "PROJECT_ID" BUCKET_NAME = "gs://PROJECT_ID-cpr-bucket"Crea un bucket de Cloud Storage:
!gcloud storage buckets create $BUCKET_NAME --location=us-central1Carga los datos desde la biblioteca de Seaborn y, luego, crea dos marcos de datos, uno con las funciones y el otro con la etiqueta:
data = sns.load_dataset('diamonds', cache=True, data_home=None) label = 'price' y_train = data['price'] x_train = data.drop(columns=['price'])Observa los datos de entrenamiento y verifica que cada fila represente un diamante.
x_train.head()Observa las etiquetas, que son los precios correspondientes.
y_train.head()Define una transformación de columna de sklearn para la codificación one-hot los atributos categóricos y escala los atributos numéricos:
column_transform = make_column_transformer( (preprocessing.OneHotEncoder(), [1,2,3]), (preprocessing.StandardScaler(), [0,4,5,6,7,8]))Define el modelo de bosque aleatorio:
regr = RandomForestRegressor(max_depth=10, random_state=0)Crea una canalización de sklearn. Esta canalización toma datos de entrada, los codifica, los escala y los pasa al modelo.
my_pipeline = make_pipeline(column_transform, regr)Entrena el modelo:
my_pipeline.fit(x_train, y_train)Llama al método de predicción en el modelo y pasa una muestra de prueba.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])Es posible que veas advertencias como
"X does not have valid feature names, but", pero las puedes ignorar.Guarda la canalización en el directorio
model_artifactsy cópiala en tu bucket de Cloud Storage:joblib.dump(my_pipeline, 'model_artifacts/model.joblib') !gcloud storage cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Guarda un artefacto de procesamiento previo
Crear un artefacto de procesamiento previo. Este artefacto se cargará en el contenedor personalizado cuando se inicia el servidor del modelo. Tu artefacto de procesamiento previo puede tener casi cualquier forma (como un archivo pickle), pero en este caso, escribirás un diccionario en un archivo JSON:
clarity_dict={"Flawless": "FL", "Internally Flawless": "IF", "Very Very Slightly Included": "VVS1", "Very Slightly Included": "VS2", "Slightly Included": "S12", "Included": "I3"}
Crea un contenedor de entrega personalizado con el servidor de modelo de CPR
El atributo
clarityde nuestros datos de entrenamiento siempre estuvo en el formato formato (es decir, "FL" en lugar de "Flawless"). En el momento de la entrega, verifica que los datos de este atributo también se abrevian. Esto se debe a que nuestro modelo sabe cómo hacer codificación one-hot "FL" pero no "impecable". Escribirás esta lógica personalizada de procesamiento previo más adelante. Por ahora, solo guarda esta tabla de consulta en un archivo JSON y, luego, escríbela en el Bucket de Cloud Storage:import json with open("model_artifacts/preprocessor.json", "w") as f: json.dump(clarity_dict, f) !gcloud storage cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/En el navegador de archivos , la estructura del directorio ahora se debería ver de la siguiente manera:
+ cpr-codelab/ + model_artifacts/ + model.joblib + preprocessor.json + src_dir/ + requirements.txt + requirements.txt + task.ipynbEn tu notebook, pega y ejecuta el siguiente código para crear una subclase de
SklearnPredictory escríbelo en un archivo de Python ensrc_dir/. Ten en cuenta que, en este ejemplo, solo personalizamos la carga, el procesamiento previo, y el procesamiento posterior, y no el método de predicción.%%writefile $USER_SRC_DIR/predictor.py import joblib import numpy as np import json from google.cloud import storage from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor class CprPredictor(SklearnPredictor): def __init__(self): return def load(self, artifacts_uri: str) -> None: """Loads the sklearn pipeline and preprocessing artifact.""" super().load(artifacts_uri) # open preprocessing artifact with open("preprocessor.json", "rb") as f: self._preprocessor = json.load(f) def preprocess(self, prediction_input: np.ndarray) -> np.ndarray: """Performs preprocessing by checking if clarity feature is in abbreviated form.""" inputs = super().preprocess(prediction_input) for sample in inputs: if sample[3] not in self._preprocessor.values(): sample[3] = self._preprocessor[sample[3]] return inputs def postprocess(self, prediction_results: np.ndarray) -> dict: """Performs postprocessing by rounding predictions and converting to str.""" return {"predictions": [f"${value}" for value in np.round(prediction_results)]}Usa el SDK de Vertex AI para Python para compilar la imagen con rutinas de predicción personalizadas. Se generará el Dockerfile y se compilará una imagen para ti.
from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=REGION) import os from google.cloud.aiplatform.prediction import LocalModel from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR local_model = LocalModel.build_cpr_model( USER_SRC_DIR, f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}", predictor=CprPredictor, requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"), )Escribe un archivo de prueba con dos muestras para la predicción. Una de las instancias tiene el nombre abreviado de claridad, pero la otra necesita convertirse primero.
import json sample = {"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]} with open('instances.json', 'w') as fp: json.dump(sample, fp)Implementa un modelo local para probar el contenedor de manera local.
with local_model.deploy_to_local_endpoint( artifact_uri = 'model_artifacts/', # local path to artifacts ) as local_endpoint: predict_response = local_endpoint.predict( request_file='instances.json', headers={"Content-Type": "application/json"}, ) health_check_response = local_endpoint.run_health_check()Puedes ver los resultados de la predicción con lo siguiente:
predict_response.contentEl resultado luce de la siguiente manera:
b'{"predictions": ["$479.0", "$586.0"]}'
Implementa el modelo en el extremo del modelo de predicción en línea
Ahora que probaste el contenedor de manera local, debes enviar la imagen a Artifact Registry y subir el modelo a Vertex AI Model Registry.
Configurar Docker para acceder a Artifact Registry
!gcloud artifacts repositories create {REPOSITORY} \ --repository-format=docker \ --location=us-central1 \ --description="Docker repository" !gcloud auth configure-docker {REGION}-docker.pkg.dev --quietEnvía la imagen.
local_model.push_image()Sube el modelo.
model = aiplatform.Model.upload(local_model = local_model, display_name=MODEL_DISPLAY_NAME, artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)Implementa el modelo:
endpoint = model.deploy(machine_type="n1-standard-2")Espera hasta que el modelo se implemente antes de continuar con el siguiente paso. La implementación tardará entre 10 y 15 minutos.
Prueba el modelo implementado a través de la obtención de una predicción:
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])El resultado luce de la siguiente manera:
Prediction(predictions=['$479.0'], deployed_model_id='3171115779319922688', metadata=None, model_version_id='1', model_resource_name='projects/721032480027/locations/us-central1/models/8554949231515795456', explanations=None)
Valida el acceso a Internet pública para las APIs de Vertex AI
En esta sección, accederás a la instancia de VM nat-client en una pestaña de sesión de Cloud Shell y usarás otra pestaña de sesión para validar la conectividad a las APIs de Vertex AI mediante la ejecución de dig y tcpdump comandos en el dominio us-central1-aiplatform.googleapis.com.
En Cloud Shell (Tab One), ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accede a la instancia de VM
nat-clientcon IAP:gcloud compute ssh nat-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapEjecuta el comando
dig:dig us-central1-aiplatform.googleapis.comDesde la VM de
nat-client(Tab One), ejecuta el siguiente comando para validar la resolución de DNS cuando envías una solicitud de predicción en línea al extremo.sudo tcpdump -i any port 53 -nPara abrir una sesión nueva de Cloud Shell (pestaña dos), haz clic en abrir una pestaña nueva en Cloud Shell.
En la sesión nueva de Cloud Shell (pestaña dos), ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accede a la instancia de VM
nat-client:gcloud compute ssh --zone "us-central1-a" "nat-client" --project "$projectid"Desde la VM
nat-client(pestaña dos), usa un editor de texto, comovimonanopara crear un archivoinstances.json. Debes anteponersudopara tener permiso para escribir en el archivo, por ejemplo:sudo vim instances.jsonAgrega la siguiente cadena de datos al archivo:
{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}Guarda el archivo de la siguiente manera:
- Si usas
vim, presiona la teclaEscy, a continuación, escribe:wqpara guardar el archivo y salir. - Si usas
nano, escribeControl+Oy presionaEnterpara guardar el archivo y, luego, escribeControl+Xpara salir.
- Si usas
Localiza el ID de extremo de la predicción en línea para el Extremo de PSC:
En la consola de Google Cloud, en la sección Vertex AI, ve a la pestaña Extremos de la página Predicción en línea.
Busca la fila del extremo que creaste, que se llama
diamonds-cpr_endpoint.Ubica el ID de extremo de 19 dígitos en la columna ID y cópialo.
En Cloud Shell, desde la VM
nat-client(pestaña dos), ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID de tu proyecto y ENDPOINT_ID por el ID de extremo de PSC:projectid=PROJECT_ID gcloud config set project ${projectid} ENDPOINT_ID=ENDPOINT_IDDesde la VM de
nat-client(pestaña dos), ejecuta el siguiente comando para enviar una solicitud de predicción en línea:curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.json
Ahora que ejecutaste la predicción, verás que los resultados de tcpdump (pestaña uno) muestran la instancia de VM nat-client (192.168.10.2) que realiza una consulta de Cloud DNS a el servidor DNS local (169.254.169.254) para el dominio de la API de Vertex AI (us-central1-aiplatform.googleapis.com). La consulta de DNS muestra direcciones IP virtuales (VIP) públicas para las APIs de Vertex AI.
Valida el acceso privado a las APIs de Vertex AI
En esta sección, accederás a la instancia de VM private-client mediante Identity-Aware Proxy en una sesión nueva de Cloud Shell (pestaña tres) y, luego, validarás la conectividad a las APIs de Vertex AI mediante la ejecución del comando dig en el dominio de Vertex AI (us-central1-aiplatform.googleapis.com)
Para abrir una sesión nueva de Cloud Shell (pestaña tres), haz clic en abrir una pestaña nueva en Cloud Shell. Esta es la pestaña tres.
En la sesión nueva de Cloud Shell (pestaña tres), ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accede a la instancia de VM
private-clientcon IAP:gcloud compute ssh private-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapEjecuta el comando
dig:dig us-central1-aiplatform.googleapis.comEn la instancia de VM
private-client(pestaña tres), usa un editor de texto comovimonanopara agregar la siguiente línea al archivo/etc/hosts:100.100.10.10 us-central1-aiplatform.googleapis.comEsta línea asigna la dirección IP del extremo de PSC (
100.100.10.10) el nombre de dominio completamente calificado para la API de Google de Vertex AI (us-central1-aiplatform.googleapis.com). El archivo editado debería verse de la siguiente manera:127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 100.100.10.10 us-central1-aiplatform.googleapis.com # Added by you 192.168.20.2 private-client.c.$projectid.internal private-client # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleDesde la VM de
private-client(pestaña tres), haz ping en el extremo de Vertex AI y enControl+Cpara salir cuando veas el siguiente resultado:ping us-central1-aiplatform.googleapis.comEl comando
pingmuestra el siguiente resultado que contiene la dirección IP del extremo de PSC:PING us-central1-aiplatform.googleapis.com (100.100.10.10) 56(84) bytes of data.Desde la VM
private-client(pestaña tres), usatcpdumppara ejecutar el siguiente comando para validar la resolución de DNS y la ruta de acceso de los datos IP cuando envíes una solicitud de predicción en línea al extremo:sudo tcpdump -i any port 53 -n or host 100.100.10.10Para abrir una sesión nueva de Cloud Shell (pestaña cuatro), haz clic en Abrir una pestaña nueva en Cloud Shell.
En la sesión nueva de Cloud Shell (pestaña cuatro), ejecuta los siguientes comandos y reemplaza PROJECT_ID por el ID del proyecto:
projectid=PROJECT_ID gcloud config set project ${projectid}En la pestaña cuatro, accede a la instancia
private-client:gcloud compute ssh \ --zone "us-central1-a" "private-client" \ --project "$projectid"Desde la VM de
private-client(pestaña cuatro), con un editor de texto comovimonano, crea un archivoinstances.jsonque contiene la siguiente cadena de datos:{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}En la VM
private-client(pestaña cuatro), ejecuta los siguientes comandos, reemplaza PROJECT_ID por el nombre del proyecto y ENDPOINT_ID por el ID de extremo de PSC:projectid=PROJECT_ID echo $projectid ENDPOINT_ID=ENDPOINT_IDDesde la VM de
private-client(pestaña cuatro), ejecuta el siguiente comando para enviar una solicitud de predicción en línea:curl -v -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.jsonDesde la VM
private-clienten Cloud Shell (pestaña tres), verifica que se haya usado la dirección IP del extremo (100.100.10.10) de PSC para acceder a las APIs de Vertex AI.Desde la terminal
private-clienttcpdumpen la pestaña tres de Cloud Shell, puedes ver que no es necesaria una búsqueda de DNS aus-central1-aiplatform.googleapis.com, ya que la línea que agregaste a/etc/hoststiene prioridad, y se usa la dirección IP PSC100.100.10.10en la ruta de datos.
Limpia
Para evitar que se apliquen cargos a tu Google Cloud cuenta por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Puedes borrar los recursos individuales del proyecto de la siguiente manera:
Borra la instancia de Vertex AI Workbench de la siguiente manera:
En la sección Vertex AI de la consola de Google Cloud, ve a la pestaña Instancias en la página Workbench.
Selecciona la instancia de Vertex AI Workbench
workbench-tutorialy haz clic en Borrar.
Borra la imagen del contenedor de la siguiente manera:
En la consola de Google Cloud, ve a la página Artifact Registry.
Selecciona el contenedor de Docker
diamondsy haz clic en Borrar.
Borra el bucket de almacenamiento de la siguiente manera:
En la consola de Google Cloud, ve a la página de Cloud Storage.
Selecciona tu bucket de almacenamiento y haz clic en Borrar.
Anula la implementación del modelo desde el extremo de la siguiente manera:
En la consola de Google Cloud, en la sección Vertex AI, ve a la página Extremos.
Haz clic en
diamonds-cpr_endpointpara ir a la página de detalles del extremo.En la fila de tu modelo, haz clic en
diamonds-cprAnular la implementación del modelo .En el cuadro de diálogo Anular la implementación del modelo desde el extremo, haz clic en Anular la implementación.
Borra el modelo de la siguiente manera:
En la consola de Google Cloud, en la sección Vertex AI, ve a la página Model Registry.
Selecciona el modelo
diamonds-cpr.Para borrar el modelo, haz clic en . Acciones y, luego, en Borrar modelo.
Borra el extremo de predicción en línea de la siguiente manera:
En la sección Vertex AI de la consola de Google Cloud, ve a la página Predicción en línea.
Selecciona el extremo
diamonds-cpr_endpoint.Para borrar el extremo, haz clic en Acciones y, luego, en Borrar extremo.
En Cloud Shell, ejecuta los siguientes comandos para borrar los recursos restantes.
projectid=PROJECT_ID gcloud config set project ${projectid}gcloud compute forwarding-rules delete pscvertex \ --global \ --quietgcloud compute addresses delete psc-ip \ --global \ --quietgcloud compute networks subnets delete workbench-subnet \ --region=us-central1 \ --quietgcloud compute vpn-tunnels delete aiml-vpc-tunnel0 aiml-vpc-tunnel1 on-prem-tunnel0 on-prem-tunnel1 \ --region=us-central1 \ --quietgcloud compute vpn-gateways delete aiml-vpn-gw on-prem-vpn-gw \ --region=us-central1 \ --quietgcloud compute routers nats delete cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete aiml-cr-us-central1 cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete cloud-router-us-central1-on-prem-nat on-prem-cr-us-central1 \ --region=us-central1 \ --quietgcloud compute instances delete nat-client private-client \ --zone=us-central1-a \ --quietgcloud compute firewall-rules delete ssh-iap-on-prem-vpc \ --quietgcloud compute networks subnets delete nat-subnet private-ip-subnet \ --region=us-central1 \ --quietgcloud compute networks delete on-prem-vpc \ --quietgcloud compute networks delete aiml-vpc \ --quietgcloud iam service-accounts delete gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --quietgcloud iam service-accounts delete workbench-sa@$projectid.iam.gserviceaccount.com \ --quiet
¿Qué sigue?
- Obtén información sobre las opciones de herramientas de redes empresariales para acceder a los extremos y servicios de Vertex AI.
- Obtén información sobre cómo funciona Private Service Connect y por qué ofrece beneficios de rendimiento significativos.
- Obtén más información sobre cómo usar los Controles del servicio de VPC para crear perímetros seguros para permitir o denegar el acceso a Vertex AI y a otras APIs de Google en tu extremo de predicción en línea.
- Obtén más información sobre cómo y por qué usar una zona de reenvío de DNS
en lugar de actualizar el archivo
/etc/hostsa gran escala y los entornos de producción.