オンプレミス ホストは、Vertex AI オンライン予測エンドポイントに公共のインターネットからアクセスできます。また、Cloud VPN または Cloud Interconnect 経由で Private Service Connect(PSC)を使用するハイブリッド ネットワーク アーキテクチャから限定公開でアクセスすることもできます。どちらのオプションも SSL / TLS 暗号化に対応しています。ただし、プライベート オプションはパフォーマンスが大幅に向上するため、クリティカルなアプリケーションに適しています。
このチュートリアルでは、高可用性 VPN(HA VPN)を使用して、Cloud NAT からのオンライン予測エンドポイントへのパブリック アクセス、および、マルチクラウドとオンプレミスのプライベート接続の基盤として機能する 2 つの Virtual Private Cloud ネットワーク間のプライベート アクセスの両方でオンライン予測エンドポイントにアクセスします。
このチュートリアルは、Vertex AI、Virtual Private Cloud(VPC)、Google Cloud コンソール、Cloud Shell に精通している企業のネットワーク管理者、データ サイエンティスト、研究者を対象としています。Vertex AI Workbench の使用経験があると役立ちますが、必須ではありません。
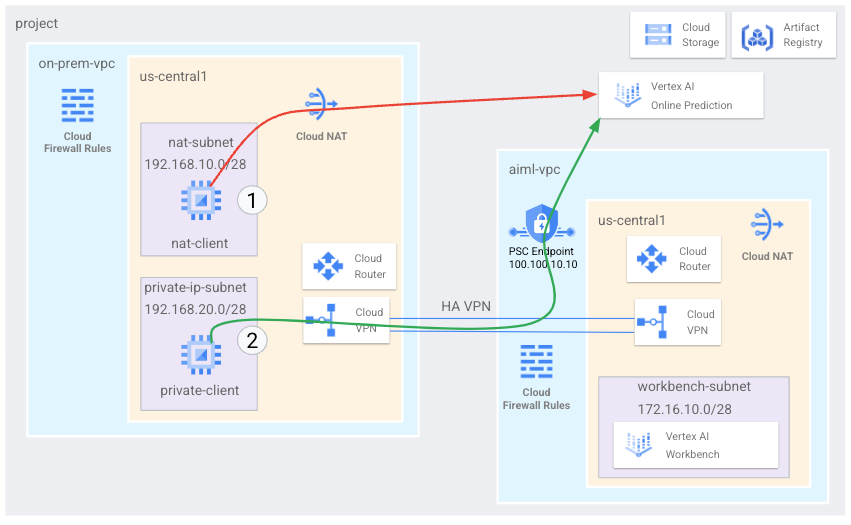
目標
- 上の図のように、2 つの Virtual Private Cloud(VPC)ネットワークを作成します。
- 一つ(
on-prem-vpc)は、オンプレミス ネットワークを表します。 - もう一つ(
aiml-vpc)は、Vertex AI Online Prediction の作成とデプロイに使用します。
- 一つ(
- HA VPN ゲートウェイ、Cloud VPN トンネル、Cloud Router をデプロイして、
aiml-vpcとon-prem-vpcに接続します。 - Vertex AI オンライン予測を作成してデプロイします。
- Private Service Connect(PSC)エンドポイントを作成して、限定公開のオンライン予測リクエストをデプロイ済みモデルに転送します。
- Private Service Connect エンドポイントのルートを
on-prem-vpcに通知するために、aiml-vpcで Cloud Router のカスタム アドバタイズ モードを有効にします。 - クライアント アプリケーションを表す 2 つの Compute Engine VM インスタンスを
on-prem-vpcに作成します。- 一つ(
nat-client)は、公共のインターネットで(Cloud NAT から)オンライン予測リクエストを送信します。図では、このアクセス方法が赤い矢印と番号 1 で示されています。 - もう一つ(
private-client)は、HA VPN で限定公開で予測リクエストを送信します。このアクセス方法は、緑色の矢印と数字 2 で示しています。
- 一つ(
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- このチュートリアルで説明するコマンドを実行するために、Cloud Shell を開きます。Cloud Shell は、ウェブブラウザからプロジェクトやリソースを管理できるインタラクティブなシェル環境です。 Google Cloud
- Cloud Shell で、現在のプロジェクトを Google Cloud プロジェクト ID に設定し、同じプロジェクト ID を
projectidシェル変数に保存します。projectid="PROJECT_ID" gcloud config set project ${projectid} -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/appengine.appViewer, roles/artifactregistry.admin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/oauthconfig.editor, roles/resourcemanager.projectIamAdmin, roles/servicemanagement.quotaAdmin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/storage.admin, roles/aiplatform.usergcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
Replace the following:
PROJECT_ID: your project ID.USER_IDENTIFIER: the identifier for your user account—for example,myemail@example.com.ROLE: the IAM role that you grant to your user account.
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Notebooks, and Vertex AI APIs:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com notebooks.googleapis.com aiplatform.googleapis.com
VPC ネットワークを作成する
このセクションでは、2 つの VPC ネットワークを作成します。一つはオンライン予測モデルの作成とエンドポイントへのデプロイ用、もう一つはそのエンドポイントへのプライベート アクセス用です。2 つの VPC ネットワークに、それぞれ Cloud Router と Cloud NAT ゲートウェイを作成します。Cloud NAT ゲートウェイは、外部 IP アドレスを持たない Compute Engine 仮想マシン(VM)インスタンスの送信接続を提供します。
オンライン予測エンドポイント(aiml-vpc)用の VPC ネットワークを作成する
VPC ネットワークを作成します。
gcloud compute networks create aiml-vpc \ --project=$projectid \ --subnet-mode=customプライマリ IPv4 範囲が
172.16.10.0/28のworkbench-subnetという名前のサブネットを作成します。gcloud compute networks subnets create workbench-subnet \ --project=$projectid \ --range=172.16.10.0/28 \ --network=aiml-vpc \ --region=us-central1 \ --enable-private-ip-google-accesscloud-router-us-central1-aiml-natという名前のリージョン Cloud Router を作成します。gcloud compute routers create cloud-router-us-central1-aiml-nat \ --network aiml-vpc \ --region us-central1Cloud Router に Cloud NAT ゲートウェイを追加します。
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
「オンプレミス」VPC ネットワーク(on-prem-vpc)を作成します。
VPC ネットワークを作成します。
gcloud compute networks create on-prem-vpc \ --project=$projectid \ --subnet-mode=customプライマリ IPv4 範囲が
192.168.10.0/28のnat-subnetという名前のサブネットを作成します。gcloud compute networks subnets create nat-subnet \ --project=$projectid \ --range=192.168.10.0/28 \ --network=on-prem-vpc \ --region=us-central1プライマリ IPv4 範囲が
192.168.20.0/28のprivate-ip-subnetという名前のサブネットを作成します。gcloud compute networks subnets create private-ip-subnet \ --project=$projectid \ --range=192.168.20.0/28 \ --network=on-prem-vpc \ --region=us-central1cloud-router-us-central1-on-prem-natという名前のリージョン Cloud Router を作成します。gcloud compute routers create cloud-router-us-central1-on-prem-nat \ --network on-prem-vpc \ --region us-central1Cloud Router に Cloud NAT ゲートウェイを追加します。
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-on-prem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Private Service Connect(PSC)エンドポイントを作成する
このセクションでは、on-prem-vpc ネットワーク内の VM インスタンスが Vertex AI API を介してオンライン予測エンドポイントにアクセスするために使用する Private Service Connect(PSC)エンドポイントを作成します。Private Service Connect(PSC)エンドポイントは、on-prem-vpc ネットワーク内のクライアントが直接アクセスできる内部 IP アドレスです。このエンドポイントは、PSC エンドポイントの IP アドレスに一致するネットワーク トラフィックを Google API のバンドルに転送する転送ルールをデプロイすることで作成されます。PSC エンドポイントの IP アドレス(100.100.10.10)は、後のステップで、on-prem-vpc ネットワークへのカスタム アドバタイズ ルートとして aiml-cr-us-central1 Cloud Router からアドバタイズされます。
PSC エンドポイントの IP アドレスを予約します。
gcloud compute addresses create psc-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=100.100.10.10 \ --network=aiml-vpcPSC エンドポイントを作成します。
gcloud compute forwarding-rules create pscvertex \ --global \ --network=aiml-vpc \ --address=psc-ip \ --target-google-apis-bundle=all-apis構成した PSC エンドポイントを一覧表示し、
pscvertexエンドポイントが作成されたことを確認します。gcloud compute forwarding-rules list \ --filter target="(all-apis OR vpc-sc)" --global構成された PSC エンドポイントの詳細を取得し、IP アドレスが
100.100.10.10であることを確認します。gcloud compute forwarding-rules describe pscvertex \ --global
ハイブリッド接続を構成する
このセクションでは、相互に接続する 2 つの(HA VPN)ゲートウェイを作成します。各ゲートウェイには、Cloud Router と VPN トンネルのペアが含まれます。
aiml-vpcVPC ネットワークに HA VPN ゲートウェイを作成します。gcloud compute vpn-gateways create aiml-vpn-gw \ --network=aiml-vpc \ --region=us-central1on-prem-vpcVPC ネットワークに HA VPN ゲートウェイを作成します。gcloud compute vpn-gateways create on-prem-vpn-gw \ --network=on-prem-vpc \ --region=us-central1Google Cloud コンソールで、[VPN] ページに移動します。
[VPN] ページで、[Cloud VPN ゲートウェイ] タブをクリックします。
VPN ゲートウェイのリストに 2 つのゲートウェイがあり、それぞれに 2 つの IP アドレスがあることを確認します。
Cloud Shell で、
aiml-vpcVirtual Private Cloud ネットワーク用の Cloud Router を作成します。gcloud compute routers create aiml-cr-us-central1 \ --region=us-central1 \ --network=aiml-vpc \ --asn=65001on-prem-vpcVirtual Private Cloud ネットワーク用の Cloud Router を作成します。gcloud compute routers create on-prem-cr-us-central1 \ --region=us-central1 \ --network=on-prem-vpc \ --asn=65002
aiml-vpc 用の VPN トンネルを作成する
aiml-vpc-tunnel0という名前の VPN トンネルを作成します。gcloud compute vpn-tunnels create aiml-vpc-tunnel0 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 0aiml-vpc-tunnel1という名前の VPN トンネルを作成します。gcloud compute vpn-tunnels create aiml-vpc-tunnel1 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 1
on-prem-vpc 用の VPN トンネルを作成する
on-prem-vpc-tunnel0という名前の VPN トンネルを作成します。gcloud compute vpn-tunnels create on-prem-tunnel0 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 0on-prem-vpc-tunnel1という名前の VPN トンネルを作成します。gcloud compute vpn-tunnels create on-prem-tunnel1 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 1Google Cloud コンソールで、[VPN] ページに移動します。
[VPN] ページで、[Cloud VPN トンネル] タブをクリックします。
VPN トンネルのリストで、4 つの VPN トンネルが確立されていることを確認します。
BGP セッションを確立する
Cloud Router は、Border Gateway Protocol(BGP)を使用して、VPC ネットワーク(この場合は aiml-vpc)とオンプレミス ネットワーク(on-prem-vpc で表される)間のルートを交換します。Cloud Router で、オンプレミス ルーターのインターフェースと BGP ピアを構成します。インターフェースと BGP ピア構成は、BGP セッションを形成します。このセクションでは、aiml-vpc に 2 つ、on-prem-vpc に 2 つの BGP セッションを作成します。
aiml-vpc の BGP セッションを確立する
Cloud Shell で、最初の BGP インターフェースを作成します。
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel0 \ --region us-central1最初の BGP ピアを作成します。
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel0 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central12 つ目の BGP インターフェースを作成します。
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.2.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel1 \ --region us-central12 つ目の BGP ピアを作成します。
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel1 \ --interface if-tunnel2-to-onprem \ --peer-ip-address 169.254.2.2 \ --peer-asn 65002 \ --region us-central1
on-prem-vpc の BGP セッションを確立する
最初の BGP インターフェースを作成します。
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel0-to-aiml-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel0 \ --region us-central1最初の BGP ピアを作成します。
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel0 \ --interface if-tunnel1-to-aiml-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central12 つ目の BGP インターフェースを作成します。
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel1-to-aiml-vpc \ --ip-address 169.254.2.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel1 \ --region us-central12 つ目の BGP ピアを作成します。
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel1 \ --interface if-tunnel2-to-aiml-vpc \ --peer-ip-address 169.254.2.1 \ --peer-asn 65001 \ --region us-central1
BGP セッションの作成を確認する
Google Cloud コンソールで、[VPN] ページに移動します。
[VPN] ページで、[Cloud VPN トンネル] タブをクリックします。
VPN トンネルのリストで、4 つのトンネルのそれぞれの [BGP セッションのステータス] 列の値が、[BGP セッションの構成] から [BGP 確立済み] に変更されたことが確認できるはずです。新しい値を表示するには、 Google Cloud コンソール ブラウザタブを更新する必要があります。
aiml-vpc が HA VPN 経由でサブネット ルートを学習したことを確認する
Google Cloud コンソールの [VPC ネットワーク] ページに移動します。
VPC ネットワークのリストで
aiml-vpcをクリックします。[ルート] タブをクリックします。
[リージョン] リストで [us-central1(アイオワ)] を選択し、[表示] をクリックします。
[宛先 IP 範囲] 列で、
aiml-vpcVPC ネットワークがon-prem-vpcVPC ネットワークのnat-subnetサブネット(192.168.10.0/28)とprivate-ip-subnet(192.168.20.0/28)サブネットからルートを学習したことを確認します。
on-prem-vpc が HA VPN 経由でサブネット ルートを学習したことを確認する
Google Cloud コンソールの [VPC ネットワーク] ページに移動します。
VPC ネットワークのリストで
on-prem-vpcをクリックします。[ルート] タブをクリックします。
[リージョン] リストで [us-central1(アイオワ)] を選択し、[表示] をクリックします。
[宛先 IP 範囲] 列で、
on-prem-vpcVPC ネットワークがaiml-vpcVPC ネットワークのworkbench-subnetサブネット(172.16.10.0/28)からルートを学習したことを確認します。
aiml-vpc のカスタム アドバタイズ ルートを作成する
サブネットが VPC ネットワークで構成されていないため、Private Service Connect エンドポイントの IP アドレスは aiml-cr-us-central1 Cloud Router によって自動的にアドバタイズされません。
したがって、エンドポイント IP アドレス 100.100.10.10 の aiml-cr-us-central Cloud Router から、BGP を介して on-prem-vpc 経由でオンプレミス環境にアドバタイズされるカスタム アドバタイズ ルートを作成する必要があります。
Google Cloud コンソールで [Cloud Router] ページに移動します。
[Cloud Router] リストで
aiml-cr-us-central1をクリックします。[ルーターの詳細] ページで、[ 編集] をクリックします。
[アドバタイズされたルート] セクションの [ルート] で、[カスタムルートの作成] を選択します。
[カスタムルートの追加] をクリックします。
[ソース] で [カスタム IP 範囲] を選択します。
[IP アドレス範囲] に「
100.100.10.10」と入力します。[説明] に「
Private Service Connect Endpoint IP」と入力します。[完了] をクリックし、[保存] をクリックします。
on-prem-vpc が HA VPN 経由で PSC エンドポイント IP アドレスを学習したことを確認する
Google Cloud コンソールの [VPC ネットワーク] ページに移動します。
VPC ネットワークのリストで
on-prem-vpcをクリックします。[ルート] タブをクリックします。
[リージョン] リストで [us-central1(アイオワ)] を選択し、[表示] をクリックします。
[宛先 IP 範囲] 列で、
on-prem-vpcVPC ネットワークが PSC エンドポイントの IP アドレス(100.100.10.10)を学習していることを確認します。
on-prem-vpc のカスタム アドバタイズ ルートを作成する
on-prem-vpc Cloud Router はデフォルトですべてのサブネットをアドバタイズしますが、必要なのは private-ip-subnet サブネットのみです。
次のセクションでは、on-prem-cr-us-central1 Cloud Router からのルート アドバタイズを更新します。
Google Cloud コンソールで [Cloud Router] ページに移動します。
[Cloud Router] リストで
on-prem-cr-us-central1をクリックします。[ルーターの詳細] ページで、[ 編集] をクリックします。
[アドバタイズされたルート] セクションの [ルート] で、[カスタムルートの作成] を選択します。
[Cloud Router に表示されるすべてのサブネットにアドバタイズする] チェックボックスがオンになっている場合は、チェックボックスをクリアします。
[カスタムルートの追加] をクリックします。
[ソース] で [カスタム IP 範囲] を選択します。
[IP アドレス範囲] に「
192.168.20.0/28」と入力します。[説明] に「
Private Service Connect Endpoint IP subnet (private-ip-subnet)」と入力します。[完了] をクリックし、[保存] をクリックします。
aiml-vpc が on-prem-vpc から private-ip-subnet ルートを学習したことを確認する
Google Cloud コンソールの [VPC ネットワーク] ページに移動します。
VPC ネットワークのリストで
aiml-vpcをクリックします。[ルート] タブをクリックします。
[リージョン] リストで [us-central1(アイオワ)] を選択し、[表示] をクリックします。
[送信先 IP 範囲] 列で、
aiml-vpcVPC ネットワークがprivate-ip-subnetルート(192.168.20.0/28)を学習していることを確認します。
テスト用の VM インスタンスを作成する
ユーザーが管理するサービス アカウントを作成する
Google Cloud API を呼び出す必要があるアプリケーションがある場合、Google はアプリケーションまたはワークロードが実行されている VM にユーザー管理のサービス アカウントを接続することをおすすめします。したがって、このセクションでは、このチュートリアルの後半で作成する VM インスタンスに適用するためのユーザー管理のサービス アカウントを作成します。
Cloud Shell で、サービス アカウントを作成します。
gcloud iam service-accounts create gce-vertex-sa \ --description="service account for vertex" \ --display-name="gce-vertex-sa"サービス アカウントに Compute インスタンス管理者(v1)(
roles/compute.instanceAdmin.v1)の IAM ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/compute.instanceAdmin.v1"サービス アカウントに Vertex AI ユーザー(
roles/aiplatform.user)の IAM ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"
テスト用の VM インスタンスを作成する
この手順では、Vertex AI API に到達するためのさまざまなメソッドを検証するテスト VM インスタンスを作成します。具体的には次のとおりです。
nat-clientインスタンスは、Cloud NAT を使用して Vertex AI を解決し、公共のインターネット経由でオンライン予測エンドポイントにアクセスします。private-clientインスタンスは、Private Service Connect IP アドレス100.100.10.10を使用して、HA VPN 経由でオンライン予測エンドポイントにアクセスします。
Identity-Aware Proxy(IAP)に VM インスタンスへの接続を許可するには、次のファイアウォール ルールを作成します。
- IAP からアクセスできるようにするすべての VM インスタンスに適用されます。
- IP 範囲
35.235.240.0/20からポート 22 を経由する TCP トラフィックを許可します。この範囲には、IAP が TCP 転送に使用するすべての IP アドレスが含まれています。
nat-clientVM インスタンスを作成します。gcloud compute instances create nat-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=nat-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"private-clientVM インスタンスを作成します。gcloud compute instances create private-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=private-ip-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"IAP ファイアウォール ルールを作成します。
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network on-prem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Vertex AI Workbench インスタンスを作成する
Vertex AI Workbench のユーザー管理サービス アカウントを作成する
Vertex AI Workbench インスタンスを作成する場合は、Compute Engine のデフォルトのサービス アカウントを使用する代わりに、ユーザー管理のサービス アカウントを指定することを強くおすすめします。組織で iam.automaticIamGrantsForDefaultServiceAccounts 組織のポリシー制約が適用されていない場合、Compute Engine のデフォルトのサービス アカウント(インスタンス ユーザーとして指定するすべてのユーザー)には、Google Cloud プロジェクトの編集者のロール(roles/editor)が付与されます。この動作を無効にするには、デフォルトのサービス アカウントへの自動的なロール付与を無効にするをご覧ください。
Cloud Shell で、
workbench-saという名前のサービス アカウントを作成します。gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"サービス アカウントにストレージ管理者(
roles/storage.admin)の IAM ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"サービス アカウントに Vertex AI ユーザー(
roles/aiplatform.user)の IAM ロールを割り当てます。gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"サービス アカウントに Artifact Registry 管理者の IAM ロールを割り当てます。
gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"
Vertex AI Workbench インスタンスを作成する
Cloud Shell で、
workbench-saサービス アカウントを指定して Vertex AI Workbench インスタンスを作成します。gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.com
オンライン予測モデルを作成してデプロイする
環境を準備する
Google Cloud コンソールで、[Vertex AI Workbench] ページの [インスタンス] タブに移動します。
Vertex AI Workbench インスタンス名(
workbench-tutorial)の横にある [JupyterLab を開く] をクリックします。Vertex AI Workbench インスタンスで JupyterLab が表示されます。
このセクションの残りの部分では、モデルのデプロイまで、Google Cloud コンソールや Cloud Shell ではなく、Jupyterlab で作業します。
[ファイル > 新規 > ターミナル] を選択します。
(Cloud Shell ではなく)JupyterLab ターミナルで、プロジェクトの環境変数を定義します。PROJECT_ID は、プロジェクト ID で置き換えてください。
PROJECT_ID=PROJECT_IDcpr-codelabとcdという新しいディレクトリを(引き続き JupyterLab ターミナルに)作成します。mkdir cpr-codelab cd cpr-codelabファイル ブラウザで、新しい
cpr-codelabフォルダをダブルクリックします。このフォルダがファイル ブラウザに表示されない場合は、 Google Cloudconsole ブラウザタブを更新してからもう一度お試しください。
[File] > [New] > [Notebook] の順に選択します。
[Select Kernel] メニューから [Python [conda env:base] * (Local)] を選択し、[Select] をクリックします。
新しいノートブック ファイルの名前を次のように変更します。
[ファイル ブラウザ] で、
Untitled.ipynbファイル アイコンを右クリックし、「task.ipynb」と入力します。cpr-codelabディレクトリは次のようになります。+ cpr-codelab/ + task.ipynb次の手順では、新しいノートブック セルを作成し、コードを貼り付けてセルを実行することで、Jupyterlab ノートブックでモデルを作成します。
次のように依存関係をインストールします。
新しいノートブックを開くと、コードを入力できるデフォルトのコードセルが表示されます。
[ ]:の後にテキスト フィールドが続いている形式です。そのテキスト フィールドにコードを貼り付けます。次のコードをセルに貼り付け、 [Run the selectedcell and advance] をクリックして、次の手順で入力として使用する
requirements.txtファイルを作成します。%%writefile requirements.txt fastapi uvicorn==0.17.6 joblib~=1.1.1 numpy>=1.17.3, <1.24.0 scikit-learn>=1.2.2 pandas google-cloud-storage>=2.2.1,<3.0.0dev google-cloud-aiplatform[prediction]>=1.18.2このステップと以下の各ステップでは、 [Insert a cell below] を選択し、コードをセルに貼り付けて、 [Run selected cells and advance] をクリックします。
Pipを使用してノートブック インスタンスに依存関係をインストールします。!pip install -U --user -r requirements.txtインストールが完了したら、[Kernel] > [Restart Kernel] の順に選択してカーネルを再起動し、ライブラリをインポートできることを確認します。
次のコードを新しいノートブック セルに貼り付け、モデルと前処理アーティファクトを保存するディレクトリを作成します。
USER_SRC_DIR = "src_dir" !mkdir $USER_SRC_DIR !mkdir model_artifacts # copy the requirements to the source dir !cp requirements.txt $USER_SRC_DIR/requirements.txt
ファイル ブラウザで、
cpr-codelabディレクトリ構造は次のようになります。+ cpr-codelab/ + model_artifacts/ + src_dir/ + requirements.txt + requirements.txt + task.ipynb
モデルをトレーニングする
引き続き task.ipynb ノートブックにコードセルを追加し、新しいセルごとに次のコードを貼り付けて実行します。
ライブラリをインポートします。
import seaborn as sns import numpy as np import pandas as pd from sklearn import preprocessing from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import make_pipeline from sklearn.compose import make_column_transformer import joblib import logging # set logging to see the docker container logs logging.basicConfig(level=logging.INFO)次の変数を定義します。PROJECT_ID は、実際のプロジェクト ID に置き換えます。
REGION = "us-central1" MODEL_ARTIFACT_DIR = "sklearn-model-artifacts" REPOSITORY = "diamonds" IMAGE = "sklearn-image" MODEL_DISPLAY_NAME = "diamonds-cpr" PROJECT_ID = "PROJECT_ID" BUCKET_NAME = "gs://PROJECT_ID-cpr-bucket"Cloud Storage バケットを作成します。
!gcloud storage buckets create $BUCKET_NAME --location=us-central1Seaborn ライブラリからデータを読み込み、2 つのデータフレーム(1 つは特徴付き、もう 1 つはラベル付き)を作成します。
data = sns.load_dataset('diamonds', cache=True, data_home=None) label = 'price' y_train = data['price'] x_train = data.drop(columns=['price'])トレーニング データを調べて、各行が菱形を表していることを確認します。
x_train.head()ラベルを確認します。これは対応する価格です。
y_train.head()sklearn 列変換をワンホット エンコーディングのカテゴリ特徴量に変換するように定義し、数値特徴をスケーリングします。
column_transform = make_column_transformer( (preprocessing.OneHotEncoder(), [1,2,3]), (preprocessing.StandardScaler(), [0,4,5,6,7,8]))ランダム フォレスト モデルを定義します。
regr = RandomForestRegressor(max_depth=10, random_state=0)sklearn パイプラインを作成します。このパイプラインは入力データを受け取り、エンコードとスケーリングを行い、モデルに渡します。
my_pipeline = make_pipeline(column_transform, regr)モデルをトレーニングします。
my_pipeline.fit(x_train, y_train)モデルで predict メソッドを呼び出して、テストサンプルを渡します。
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])"X does not have valid feature names, but"のような警告が表示されることがありますが、無視してかまいません。パイプラインを
model_artifactsディレクトリに保存し、Cloud Storage バケットにコピーします。joblib.dump(my_pipeline, 'model_artifacts/model.joblib') !gcloud storage cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
前処理アーティファクトを保存する
前処理アーティファクトを作成します。このアーティファクトは、モデルサーバーの起動時にカスタム コンテナに読み込まれます。前処理アーティファクトは、ほぼすべての形式(pickle ファイルなど)にできますが、この場合は、JSON ファイルにディクショナリを書き込みます。
clarity_dict={"Flawless": "FL", "Internally Flawless": "IF", "Very Very Slightly Included": "VVS1", "Very Slightly Included": "VS2", "Slightly Included": "S12", "Included": "I3"}
CPR モデルサーバーを使用してカスタム サービング コンテナを構築する
トレーニング データの
clarity特徴は、常に省略形式(「Flawless」ではなく「FL」など)でした。サービス提供時に、この機能のデータも省略されていることを確認します。モデルは「FL」をワンホット エンコードする方法を認識していますが、「Flawless」は認識していないことが要因です。このカスタム前処理ロジックは後で記述します。ここでは、このルックアップ テーブルを JSON ファイルに保存してから、Cloud Storage バケットに書き込みます。import json with open("model_artifacts/preprocessor.json", "w") as f: json.dump(clarity_dict, f) !gcloud storage cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/ファイル ブラウザで、ディレクトリ構造は次のようになります。
+ cpr-codelab/ + model_artifacts/ + model.joblib + preprocessor.json + src_dir/ + requirements.txt + requirements.txt + task.ipynbノートブックに次のコードを貼り付けて実行し、
SklearnPredictorをサブクラス化して、src_dir/の Python ファイルに書き込みます。この例では、読み込み、前処理、後処理の各メソッドのみをカスタマイズし、予測メソッドはカスタマイズしません。%%writefile $USER_SRC_DIR/predictor.py import joblib import numpy as np import json from google.cloud import storage from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor class CprPredictor(SklearnPredictor): def __init__(self): return def load(self, artifacts_uri: str) -> None: """Loads the sklearn pipeline and preprocessing artifact.""" super().load(artifacts_uri) # open preprocessing artifact with open("preprocessor.json", "rb") as f: self._preprocessor = json.load(f) def preprocess(self, prediction_input: np.ndarray) -> np.ndarray: """Performs preprocessing by checking if clarity feature is in abbreviated form.""" inputs = super().preprocess(prediction_input) for sample in inputs: if sample[3] not in self._preprocessor.values(): sample[3] = self._preprocessor[sample[3]] return inputs def postprocess(self, prediction_results: np.ndarray) -> dict: """Performs postprocessing by rounding predictions and converting to str.""" return {"predictions": [f"${value}" for value in np.round(prediction_results)]}Vertex AI SDK for Python でカスタム予測ルーティンを使用してイメージをビルドします。Dockerfile が生成され、イメージがビルドされます。
from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=REGION) import os from google.cloud.aiplatform.prediction import LocalModel from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR local_model = LocalModel.build_cpr_model( USER_SRC_DIR, f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}", predictor=CprPredictor, requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"), )予測用の 2 つのサンプルを含むテストファイルを作成します。一方のインスタンスには明瞭な略称が使われていますが、もう一方のインスタンスは最初に変換する必要があります。
import json sample = {"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]} with open('instances.json', 'w') as fp: json.dump(sample, fp)ローカルモデルをデプロイして、コンテナをローカルでテストします。
with local_model.deploy_to_local_endpoint( artifact_uri = 'model_artifacts/', # local path to artifacts ) as local_endpoint: predict_response = local_endpoint.predict( request_file='instances.json', headers={"Content-Type": "application/json"}, ) health_check_response = local_endpoint.run_health_check()予測結果は、次のコマンドで確認できます。
predict_response.content出力は次のようになります。
b'{"predictions": ["$479.0", "$586.0"]}'
オンライン予測モデル エンドポイントにモデルをデプロイする
コンテナをローカルでテストしたので、次はイメージを Artifact Registry に push し、モデルを Vertex AI Model Registry にアップロードします。
Artifact Registry にアクセスできるように Docker を構成します。
!gcloud artifacts repositories create {REPOSITORY} \ --repository-format=docker \ --location=us-central1 \ --description="Docker repository" !gcloud auth configure-docker {REGION}-docker.pkg.dev --quietイメージを push します。
local_model.push_image()モデルをアップロードします。
model = aiplatform.Model.upload(local_model = local_model, display_name=MODEL_DISPLAY_NAME, artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)モデルをデプロイします。
endpoint = model.deploy(machine_type="n1-standard-2")モデルがデプロイされるまで待ってから次のステップに進みます。デプロイには 10~15 分ほどかかります。
予測を取得して、デプロイされたモデルをテストします。
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])出力は次のようになります。
Prediction(predictions=['$479.0'], deployed_model_id='3171115779319922688', metadata=None, model_version_id='1', model_resource_name='projects/721032480027/locations/us-central1/models/8554949231515795456', explanations=None)
Vertex AI API への公共のインターネット アクセスを確認する
このセクションでは、1 つの Cloud Shell セッションのタブで nat-client VM インスタンスにログインし、別のセッションのタブを使用して dig と tcpdump コマンドをドメイン us-central1-aiplatform.googleapis.com に対して実行することで、Vertex AI API への接続を確認します。
Cloud Shell(タブ 1)で次のコマンドを実行します。ここで、PROJECT_ID は実際のプロジェクト ID に置き換えます。
projectid=PROJECT_ID gcloud config set project ${projectid}IAP を使用して
nat-clientVM インスタンスにログインします。gcloud compute ssh nat-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapdigコマンドを実行します。dig us-central1-aiplatform.googleapis.comnat-clientVM(タブ 1)から次のコマンドを実行して、オンライン予測リクエストをエンドポイントに送信する際に DNS の解決を検証します。sudo tcpdump -i any port 53 -nCloud Shell で [新しいタブを開く] をクリックして、新しい Cloud Shell セッションを開きます(タブ 2)。
新しい Cloud Shell セッション(タブ 2)で、次のコマンドを実行します。ここで、PROJECT_ID は実際のプロジェクト ID に置き換えます。
projectid=PROJECT_ID gcloud config set project ${projectid}nat-clientVM インスタンスにログインします。gcloud compute ssh --zone "us-central1-a" "nat-client" --project "$projectid"nat-clientVM(タブ 2)から、vimやnanoなどのテキスト エディタを使用して、instances.jsonファイルを作成します。ファイルへの書き込み権限を付与するには、sudoを先頭に追加する必要があります。次に例を示します。sudo vim instances.json次のデータ文字列をファイルに追加します。
{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}次のようにファイルを保存します。
vimを使用している場合は、Escキーを押してから、「:wq」と入力してファイルを保存し、終了します。nanoを使用している場合は、「Control+O」と入力してEnterを押してファイルを保存し、「Control+X」と入力して終了します。
PSC エンドポイントのオンライン予測エンドポイント ID を見つけます。
Google Cloud コンソールの Vertex AI セクションで、[オンライン予測] ページの [エンドポイント] タブに移動します。
作成したエンドポイント(
diamonds-cpr_endpointという名前の行)を探します。[ID] 列にある 19 桁のエンドポイント ID を見つけてコピーします。
Cloud Shell の
nat-clientVM(タブ 2)から次のコマンドを実行します。PROJECT_ID はプロジェクト ID に置き換え、ENDPOINT_ID は PSC エンドポイント ID に置き換えます。projectid=PROJECT_ID gcloud config set project ${projectid} ENDPOINT_ID=ENDPOINT_IDnat-clientVM(タブ 2)で、次のコマンドを実行してオンライン予測リクエストを送信します。curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.json
予測を実行したので、tcpdump の結果(タブ 1)には、Vertex AI API ドメイン(us-central1-aiplatform.googleapis.com)のローカル DNS サーバー(169.254.169.254)に対する Cloud DNS クエリを実行している nat-client VM インスタンス(192.168.10.2)が表示されます。DNS クエリは、Vertex AI API のパブリック仮想 IP アドレス(VIP)を返します。
Vertex AI API へのプライベート アクセスを確認する
このセクションでは、新しい Cloud Shell セッション(タブ 3)で Identity-Aware Proxy を使用して private-client VM インスタンスにログインし、Vertex AI ドメイン(us-central1-aiplatform.googleapis.com)に対して dig コマンドを実行して Vertex AI API への接続を確認します。
Cloud Shell で [新しいタブを開く] をクリックして、新しい Cloud Shell セッションを開きます(タブ 3)。これがタブ 3 です。
新しい Cloud Shell セッション(タブ 3)で、次のコマンドを実行します。ここで、PROJECT_ID は実際のプロジェクト ID に置き換えます。
projectid=PROJECT_ID gcloud config set project ${projectid}IAP を使用して
private-clientVM インスタンスにログインします。gcloud compute ssh private-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapdigコマンドを実行します。dig us-central1-aiplatform.googleapis.comprivate-clientVM インスタンス(タブ 3)で、vimやnanoなどのテキスト エディタを使用して、次の行を/etc/hostsファイルに追加します。100.100.10.10 us-central1-aiplatform.googleapis.comこの行では、PSC エンドポイントの IP アドレス(
100.100.10.10)を Vertex AI Google API の完全修飾ドメイン名(us-central1-aiplatform.googleapis.com)に割り当てています。編集後のファイルは次のようになります。127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 100.100.10.10 us-central1-aiplatform.googleapis.com # Added by you 192.168.20.2 private-client.c.$projectid.internal private-client # Added by Google 169.254.169.254 metadata.google.internal # Added by Googleprivate-clientVM(タブ 3)から、Vertex AI エンドポイントに ping を実行し、Control+Cを実行して出力が表示されたら終了します。ping us-central1-aiplatform.googleapis.compingコマンドは、PSC エンドポイントの IP アドレスを含む次の出力を返します。PING us-central1-aiplatform.googleapis.com (100.100.10.10) 56(84) bytes of data.private-clientVM(タブ 3)からtcpdumpを使用して次のコマンドを実行し、オンライン予測リクエストをエンドポイントに送信するときに DNS の解決と IP データパスを検証します。sudo tcpdump -i any port 53 -n or host 100.100.10.10Cloud Shell で [新しいタブを開く] をクリックして、新しい Cloud Shell セッションを開きます(タブ 4)。
新しい Cloud Shell セッション(タブ 4)で次のコマンドを実行します。ここで、PROJECT_ID は実際のプロジェクト ID に置き換えます。
projectid=PROJECT_ID gcloud config set project ${projectid}タブ 4 で、
private-clientインスタンスにログインします。gcloud compute ssh \ --zone "us-central1-a" "private-client" \ --project "$projectid"private-clientVM(タブ 4)から、vimやnanoなどのテキスト エディタを使用して、次のデータ文字列を含むinstances.jsonファイルを作成します。{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}private-clientVM(タブ 4)から次のコマンドを実行します。PROJECT_ID はプロジェクト名に、ENDPOINT_ID は PSC エンドポイント ID に置き換えます。projectid=PROJECT_ID echo $projectid ENDPOINT_ID=ENDPOINT_IDprivate-clientVM(タブ 4)で、次のコマンドを実行してオンライン予測リクエストを送信します。curl -v -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.jsonCloud Shell の
private-clientVM(タブ 3)から、PSC エンドポイントの IP アドレス(100.100.10.10)が Vertex AI API へのアクセスに使用されたことを確認します。Cloud Shell のタブ 3 の
private-clienttcpdumpターミナルから、us-central1-aiplatform.googleapis.comへの DNS ルックアップが不要であることがわかります。/etc/hostsファイルに追加したラインが優先され、PSC の IP アドレス100.100.10.10がデータパスで使用されるからです。
クリーンアップ
このチュートリアルで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクト内の個々のリソースを削除するには、次のように操作します。
次の手順で Vertex AI Workbench インスタンスを削除します。
Google Cloud コンソールの [Vertex AI] セクションで、[ワークベンチ] ページの [インスタンス] タブに移動します。
workbench-tutorialVertex AI Workbench インスタンスを選択して、削除アイコン をクリックします。
次のようにコンテナ イメージを削除します。
Google Cloud コンソールで、[Artifact Registry] ページに移動します。
diamondsDocker コンテナを選択し、 [削除] をクリックします。
次のようにストレージ バケットを削除します。
Google Cloud コンソールで [Cloud Storage] ページに移動します。
ストレージ バケットを選択して、 [削除] をクリックします。
次のように、エンドポイントからモデルのデプロイを解除します。
Google Cloud コンソールの [Vertex AI] セクションで、[エンドポイント] ページに移動します。
[
diamonds-cpr_endpoint] をクリックして、エンドポイントの詳細ページに移動します。モデルの行
diamonds-cprで、[モデルのデプロイ解除 ] をクリックします。[エンドポイントからモデルのデプロイを解除] ダイアログで [デプロイ解除] をクリックします。
次のようにモデルを削除します。
Google Cloud コンソールの [Vertex AI] セクションで、[Model Registry] ページに移動します。
diamonds-cprモデルを選択します。モデルを削除するには、 [アクション] をクリックし、[モデルを削除] をクリックします。
次のようにオンライン予測エンドポイントを削除します。
Google Cloud コンソールの [Vertex AI] セクションで、[オンライン予測] ページに移動します。
diamonds-cpr_endpointエンドポイントを選択します。エンドポイントを削除するには、 [アクション] をクリックしてから、[エンドポイントを削除] をクリックします。
Cloud Shell で次のコマンドを実行して、残りのリソースを削除します。
projectid=PROJECT_ID gcloud config set project ${projectid}gcloud compute forwarding-rules delete pscvertex \ --global \ --quietgcloud compute addresses delete psc-ip \ --global \ --quietgcloud compute networks subnets delete workbench-subnet \ --region=us-central1 \ --quietgcloud compute vpn-tunnels delete aiml-vpc-tunnel0 aiml-vpc-tunnel1 on-prem-tunnel0 on-prem-tunnel1 \ --region=us-central1 \ --quietgcloud compute vpn-gateways delete aiml-vpn-gw on-prem-vpn-gw \ --region=us-central1 \ --quietgcloud compute routers nats delete cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete aiml-cr-us-central1 cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete cloud-router-us-central1-on-prem-nat on-prem-cr-us-central1 \ --region=us-central1 \ --quietgcloud compute instances delete nat-client private-client \ --zone=us-central1-a \ --quietgcloud compute firewall-rules delete ssh-iap-on-prem-vpc \ --quietgcloud compute networks subnets delete nat-subnet private-ip-subnet \ --region=us-central1 \ --quietgcloud compute networks delete on-prem-vpc \ --quietgcloud compute networks delete aiml-vpc \ --quietgcloud iam service-accounts delete gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --quietgcloud iam service-accounts delete workbench-sa@$projectid.iam.gserviceaccount.com \ --quiet
次のステップ
- Vertex AI のエンドポイントとサービスにアクセスするためのエンタープライズ ネットワーキング オプションについて学習する。
- Private Service Connect の仕組みと、大きなパフォーマンス上のメリットが得られる理由を確認する。
- VPC Service Controls を使用して安全な境界を作成する方法を確認して、オンライン予測エンドポイントで Vertex AI と他の Google API へのアクセスを許可または拒否する。
- 大規模な環境と本番環境で
/etc/hostsファイルを更新せずに DNS 転送ゾーンを使用する方法と理由を確認する。