The quality of your training data strongly affects the effectiveness of the model you create, and by extension, the quality of the predictions returned from that model. The key to high-quality training data is ensuring that you have training items that accurately represent the domain you want to make predictions about and that the training items are accurately labeled.
There are three ways to assign labels to your training data items:
- Add the data items to your dataset with their labels already assigned, for example using a commercially available dataset
- Assign labels to the data items using the Google Cloud console
- Request to have human labelers add labels to the data items
Vertex AI data labeling tasks let you work with human labelers to generate highly accurate labels for a collection of data that you can use to train your machine learning models.
For information about pricing of data labeling, see Data labeling.
To request data labeling by human labelers, you create a data labeling job that provides the human labelers with:
- The dataset containing the representative data items to label
- A list of all possible labels to apply to the data items
- A PDF file containing instructions guiding the human labelers through labeling tasks
Using these resources, the human labelers annotate the items in the dataset according to your instructions. When they are done, you can use the annotation set to train a Vertex AI model or export the labeled data items to use in another machine learning environment.
Create a dataset
You provide the human labelers with the data items to label by creating a dataset and importing data items into it. The data items need not be labeled. The data type (image, video, or text) and objective (for example, classification or object tracking) determines the type of annotations the human labelers apply to the data items.
Provide labels
When you create a data labeling task, you list the set of labels you want the human labelers to use to label your images. For example, if you want to classify images based on whether they contain a dog or a cat, you create a label set with two labels: "Dog" and "Cat". And, as noted in the following list, you might also want labels for "Neither" and "Both".
Here are some guidelines for creating a high-quality label set.
- Make each label's display name a meaningful word, such as "dog", "cat", or "building". Do not use abstract names like "label1" and "label2" or unfamiliar acronyms. The more meaningful the label names, the easier it is for human labelers to apply them accurately and consistently.
- Make sure the labels are easily distinguishable from one another. For classification tasks where a single label is applied to each data item, try not to use labels whose meanings overlap. For example, don't have labels for "Sports" and "Baseball".
- For classification tasks, it is usually a good idea to include a label named "other" or "none", to use for data that don't match the other labels. If the only available labels are "dog" and "cat", for example, labelers must label every image with one of those labels. Your custom model is typically more robust if you include images other than dogs or cats in its training data.
- Keep in mind that labelers are most efficient and accurate when you have at most 20 labels defined in the label set. You can include up to 100 labels.
Create instructions
Instructions give the human labelers information about how to apply labels to your data. The instructions should contain sample labeled data and other explicit directions.
Instructions are PDF files. PDF instructions can provide sophisticated directions such as positive and negative examples or descriptions for each case. PDF is also a convenient format for providing instructions for complicated tasks such as image bounding boxes or video object tracking.
Write the instructions, create a PDF file, and save the PDF file in your Cloud Storage bucket.
Provide good instructions
Good instructions are the most important factor in getting good human labeling results. Because you know your use case best, you need to let the human labelers know what you want them to do. Here are some guidelines for creating good instructions:
The human labelers do not have your domain knowledge. The distinctions you ask labelers to make should be easy to understand for someone unfamiliar with your use case.
Avoid making the instructions too long. It is best if a labeler can review and understand the instructions within 20 minutes.
Instructions should describe the concept of the task and provide details about how to label the data. For example, for a bounding box task, describe how you want labelers to draw the bounding box. Should it be a tight box or a loose box? If there are multiple instances of the object, should they draw one bounding box or multiple boxes?
If your instructions have a corresponding label set, they should cover all labels in that set. The label name in the instructions should match the name in the label set.
It often takes several iterations to create good instructions. We recommend having the human labelers work on a small dataset first, then adjust your instructions based on how well the labelers' work matches your expectations.
A good instructions file includes the following sections:
- Label list and description: A list of all the labels you would like to use and the meaning of each label.
- Examples: For each label, give at least three positive examples and one negative example. These examples should cover different cases.
- Cover edge cases. To reduce the need for the labeler to interpret the label,
clarify as many edge cases as you can. For example, if you need to draw a
bounding box for a person, it is better to clarify:
- If there are multiple people, do you need a box for each person?
- If a person is occluded, do you need a box?
- If a person is partially shown in the image, do you need a box?
- If a person is in a picture or painting, do you need a box?
- Describe how to add annotations. For example:
- For a bounding box, do you need a tight box or loose box?
- For text entity extraction, where should the interested entity start and end?
- Clarification on labels. If two labels are similar or easy to mix up, give examples to clarify the difference.
The following examples show what the PDF instructions might include. Labelers will review the instructions before they start the task.

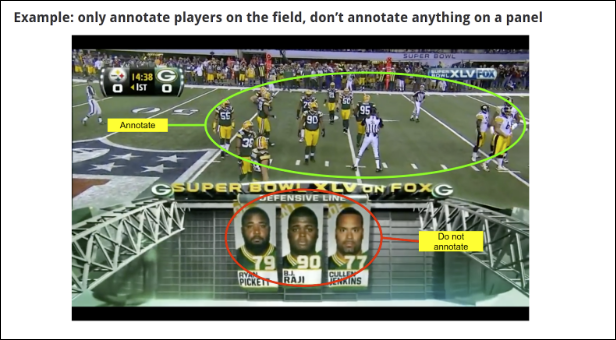
Create a data labeling task
Web UI
You can request data labeling from the Google Cloud console.
In the Google Cloud console, go to the Labeling tasks page.
Click Create.
The New labeling task pane opens.
Enter a name for the labeling task.
Select the dataset whose items you want to have labeled.
If you opened the New labeling task pane from the dataset detail screen, you cannot select a different dataset.
Confirm that the objective is correct.
The Objective box shows the objective for the selected dataset, as determined by its default annotation set. To change the objective, choose a different annotation set.
Choose the annotation set to use for the labeled data.
The labels applied by the human labelers are saved to the selected annotation set. You can choose an existing annotation set or create a new one. If you create a new one, you need to provide a name for it.
Specify whether to use active learning.
Active learning expedites the labeling process by having a human labeler label part of your dataset, then applying machine learning to automatically label the rest.
Click Continue.
Enter the labels for the human labelers to apply. For information about creating a high-quality set of labels, see Designing a label set.
Click Continue.
Enter the path to the instructions for the human labelers. The instructions must be a PDF file stored in a Cloud Storage bucket. For information about creating high-quality instructions, see Designing instructions for human labelers.
Click Continue.
Choose whether to use Google-managed labelers or Provide your own labelers.
If you chose to use Google-managed labelers, click the checkbox to confirm that you have read the pricing guide to understand the cost of labeling.
If you are providing your own labelers, you need to create labeler groups and manage their activities by using the DataCompute Console. Otherwise, choose the labeler group to use for this labeling task.
Choose an existing labeler group from the drop-down list, or choose New labeler group and enter a group name and comma-separated list of email addresses for the group's managers in the text boxes below the drop-down list. Click the checkbox to grant the specified managers access to see your data labeling information.
Specify how many labelers you want to review each item.
By default, one human labeler annotates each data item. However, you can request to have multiple labelers annotate and review each item. Select the number of labelers from the Specialists per data item box.
Click Start Task.
If Start Task is unavailable, review the pages within the New labeling task pane to verify that you've entered all the required information.
You can review the progress of the data labeling task in the Google Cloud console from the Labeling tasks page.
The page shows the status of each requested labeling task. When the Progress column shows 100%, the corresponding dataset is labeled and ready for training a model.
REST
Before using any of the request data, make the following replacements:
- PROJECT_ID: Your project ID
- DISPLAY_NAME: Name for the data labeling job
- DATASET_ID: ID of the dataset containing the items to label
- LABELERS: The number of human labelers you want to have review each data item; valid values are 1, 3, and 5.
- INSTRUCTIONS: The path to the PDF file containing instructions for the human labelers; the file must be in a Cloud Storage bucket accessible from your project
- INPUT_SCHEMA_URI: Path to the schema file for the data item type:
- Image classification single label:
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_classification_single_label_io_format_1.0.0.yaml - Image classification multi-label:
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_classification_multi_label_io_format_1.0.0.yaml - Image object detection:
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml - Text classification single-label:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_classification_single_label_io_format_1.0.0.yaml - Text classification multi-label:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_classification_multi_label_io_format_1.0.0.yaml - Text entity extraction:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_extraction_io_format_1.0.0.yaml - Text sentiment analysis:
gs://google-cloud-aiplatform/schema/dataset/ioformat/text_sentiment_io_format_1.0.0.yaml - Video classification:
gs://google-cloud-aiplatform/schema/dataset/ioformat/video_classification_io_format_1.0.0.yaml - Video object tracking:
gs://google-cloud-aiplatform/schema/dataset/ioformat/video_object_tracking_io_format_1.0.0.yaml
- Image classification single label:
- LABEL_LIST: A comma-separated list of strings, enumerating the labels available to apply to a data item
- ANNOTATION_SET: The name of the annotation set for the labeled data
HTTP method and URL:
POST https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/dataLabelingJobs
Request JSON body:
{
"displayName":"DISPLAY_NAME",
"datasets":"DATASET_ID",
"labelerCount":LABELERS,
"instructionUri":"INSTRUCTIONS",
"inputsSchemaUri":"INPUT_SCHEMA_URI",
"inputs": {
"annotation_specs": [LABEL_LIST]
},
"annotationLabels": {
"aiplatform.googleapis.com/annotation_set_name": "ANNOTATION_SET"
}
}
To send your request, expand one of these options:
You should receive a JSON response similar to the following:
{
"name": "projects/PROJECT_ID/locations/us-central1/dataLabelingJobs/JOB_ID",
"displayName": "DISPLAY_NAME",
"datasets": [
"DATASET_ID"
],
"labelerCount": LABELERS,
"instructionUri": "INSTRUCTIONS",
"inputsSchemaUri": "INPUT_SCHEMA_URI",
"inputs": {
"annotationSpecs": [
LABEL_LIST
]
},
"state": "JOB_STATE_PENDING",
"labelingProgress": "0",
"createTime": "2020-05-30T23:13:49.121133Z",
"updateTime": "2020-05-30T23:13:49.121133Z",
"savedQuery": {
"name": "projects/PROJECT_ID/locations/us-central1/datasets/DATASET_ID/savedQueries/ANNOTATION_SET_ID"
},
"annotationSpecCount": 2
}
DataLabelingJob. You can check the progress of the job by monitoring the
"labelingProgress" element, whose value is the percentage completed.
Java
Additional code samples:Using active learning
Using a custom labeler pool
Python
Additional code samples:Using active learning
Using a custom labeler pool