En este documento, se muestra cómo encontrar las asignaciones de recursos adecuadas del hardware local a Google Cloud. En una situación en la que tus aplicaciones se ejecutan en servidores bare metal y deseas migrarlas a Google Cloud, puedes considerar las siguientes preguntas:
- ¿Cómo se asignan los núcleos físicos (CPU físicas) a las CPU virtuales en Google Cloud? Por ejemplo, ¿cómo se asignan 4 núcleos físicos del servidor bare metal Xeon E5 a las CPU virtuales en Google Cloud?
- ¿Cómo se tienen en cuenta las diferencias de rendimiento entre las diversas plataformas de CPU y las generaciones de procesadores? Por ejemplo, ¿Sandy Bridge de 3.0 GHz es 1.5 veces más rápido que Skylake de 2.0 GHz?
- ¿Cómo se redimensionan los recursos según tus cargas de trabajo? Por ejemplo, ¿cómo puedes optimizar una aplicación con un uso intensivo de memoria y un solo subproceso que se ejecuta en un servidor de varios núcleos?
Sockets, CPU, núcleos y subprocesos
Muchas veces, los términos socket, CPU, núcleo y subproceso se usan de manera indistinta, lo que puede causar confusión cuando migras entre diferentes entornos.
En pocas palabras, un servidor puede tener uno o más sockets. Un socket (también llamado socket de CPU o ranura de CPU) es el conector en la placa madre que aloja un chip de CPU y proporciona conexiones físicas entre la CPU y la placa de circuito.
Una CPU se refiere al circuito integrado (CI) real. La operación fundamental de una CPU es ejecutar una secuencia de instrucciones almacenadas. En un nivel alto, las CPU siguen los pasos de recuperación, decodificación y ejecución, que en conjunto se conocen como el ciclo de instrucciones. En CPU más complejas, se pueden recuperar, decodificar y ejecutar varias instrucciones de forma simultánea.
Cada chip de CPU puede tener uno o más núcleos. En resumen, un núcleo consiste en una unidad de ejecución que recibe instrucciones y realiza acciones según esas instrucciones. En un sistema con hipersubprocesos, un núcleo del procesador físico permite que sus recursos se asignen como varios procesadores lógicos. En otras palabras, cada núcleo del procesador físico se presenta como dos núcleos virtuales (o lógicos) al sistema operativo.
En el siguiente diagrama, se muestra una vista de alto nivel de una CPU de cuatro núcleos con hipersubprocesos habilitados.

En Google Cloud, cada CPU virtual se implementa como un solo hipersubproceso en una de las plataformas de CPU disponibles.
Para encontrar la cantidad total de CPU virtuales (CPU lógicas) en tu sistema, puedes usar la siguiente fórmula:
CPU virtuales = subprocesos por núcleo físico × núcleos físicos por socket × cantidad de sockets
Con el comando lscpu, se recopila información que incluye la cantidad de sockets, CPU, núcleos y subprocesos. También se incluye información sobre el almacenamiento en caché de la CPU, el uso compartido, la familia, el modelo y BogoMips.
Este es un resultado típico:
... Architecture: x86_64 CPU(s): 1 On-line CPU(s) list: 0 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 1 CPU MHz: 2200.000 BogoMIPS: 4400.00 ...
Cuando asignes recursos de CPU entre el entorno existente y Google Cloud, asegúrate de saber cuántos núcleos físicos o virtuales tiene el servidor. Para obtener más información, consulta la sección Asigna recursos.
Frecuencia de reloj de CPU
Para que un programa se ejecute, debe desglosarse en un conjunto de instrucciones que el procesador comprenda. Considera el siguiente programa C que agrega dos números y muestra el resultado:
#include <stdio.h>
int main()
{
int a = 11, b = 8;
printf("%d \n", a+b);
}
En la compilación, el programa se convierte en el siguiente código de ensamblaje:
...
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $11, -8(%rbp)
movl $8, -4(%rbp)
movl -8(%rbp), %edx
movl -4(%rbp), %eax
addl %edx, %eax
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
...
Cada instrucción de ensamblaje en el resultado anterior corresponde a una sola instrucción de máquina. Por ejemplo, la instrucción pushq indica que el contenido del registro RBP debe enviarse a la pila del programa. Durante cada ciclo, una CPU puede realizar una operación básica, como recuperar una instrucción, acceder al contenido de un registro o escribir datos. Si deseas revisar cada etapa del ciclo para agregar dos números, consulta este simulador de CPU.
Ten en cuenta que es posible que cada instrucción de CPU requiera varios ciclos de reloj para ejecutarse. La cantidad promedio de ciclos de reloj requeridos por instrucción para un programa se define mediante ciclos por instrucción (CPI), de la siguiente manera:
ciclos por instrucción = cantidad de ciclos de CPU usados / cantidad de instrucciones ejecutadas
La mayoría de las CPU modernas pueden ejecutar varias instrucciones por ciclo de reloj a través de la canalización de instrucciones. La cantidad promedio de instrucciones ejecutadas por ciclo se define mediante instrucciones por ciclo (IPC), de la siguiente manera:
instrucciones por ciclo = cantidad de instrucciones ejecutadas / cantidad de ciclos de CPU usados
La frecuencia de reloj de la CPU define la cantidad de ciclos de reloj que el procesador puede ejecutar por segundo. Por ejemplo, un procesador de 3.0 GHz puede ejecutar 3 mil millones de ciclos de reloj por segundo. Esto significa que cada ciclo de reloj tarda alrededor de 0.3 nanosegundos en ejecutarse. Durante cada ciclo de reloj, una CPU puede realizar 1 o más instrucciones definidas por IPC.
Por lo general, las frecuencias de reloj se usan para comparar el rendimiento de los procesadores. Según su definición literal (cantidad de ciclos ejecutados por segundo), podrías concluir que una mayor cantidad de ciclos de reloj significa que la CPU puede hacer más trabajo y, por lo tanto, tener un mejor rendimiento. Esta conclusión puede ser válida cuando se comparan las CPU en la misma generación de procesadores. Sin embargo, las frecuencias de reloj no deben usarse como un único indicador de rendimiento cuando se comparan las CPU en diferentes familias de procesadores. Es posible que una CPU de generación nueva proporcione un mejor rendimiento incluso cuando se ejecuta a una frecuencia de reloj más baja que las CPU de generación anterior.
Frecuencias de reloj y rendimiento del sistema
Para comprender mejor el rendimiento de un procesador, es importante observar la cantidad de ciclos de reloj y la cantidad de trabajo que puede hacer una CPU por ciclo. El tiempo total de ejecución de un programa vinculado a la CPU depende de la frecuencia de reloj y otros factores, como la cantidad de instrucciones que se ejecutarán, los ciclos por instrucción o las instrucciones por ciclo, la arquitectura del conjunto de instrucciones, los algoritmos de programación y despacho, y lenguaje de programación que se usa. Estos factores pueden variar de forma significativa de una generación de procesador a otra.
Para comprender cómo la ejecución de la CPU puede variar en dos implementaciones diferentes, considera el ejemplo de un programa factorial simple. Uno de los siguientes programas está escrito en C y otro en Python. Perf (una herramienta de creación de perfiles para Linux) se usa a fin de capturar algunas de las métricas de CPU y kernel.
Programa de C
#include <stdio.h>
int main()
{
int n=7, i;
unsigned int factorial = 1;
for(i=1; i<=n; ++i){
factorial *= i;
}
printf("Factorial of %d = %d", n, factorial);
}
Performance counter stats for './factorial':
...
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
45 page-faults # 0.065 M/sec
1,562,075 cycles # 1.28 GHz
1,764,632 instructions # 1.13 insns per cycle
314,855 branches # 257.907 M/sec
8,144 branch-misses # 2.59% of all branches
...
0.001835982 seconds time elapsed
Programa de Python
num = 7
factorial = 1
for i in range(1,num + 1):
factorial = factorial*i
print("The factorial of",num,"is",factorial)
Performance counter stats for 'python3 factorial.py':
...
7 context-switches # 0.249 K/sec
0 cpu-migrations # 0.000 K/sec
908 page-faults # 0.032 M/sec
144,404,306 cycles # 2.816 GHz
158,878,795 instructions # 1.10 insns per cycle
38,254,589 branches # 746.125 M/sec
945,615 branch-misses # 2.47% of all branches
...
0.029577164 seconds time elapsed
En el resultado destacado, se muestra el tiempo total necesario para ejecutar cada programa. El programa escrito en C se ejecutó alrededor de 15 veces más rápido que el programa escrito en Python (1.8 milisegundos frente a 30 milisegundos). Estas son algunas comparaciones adicionales:
Cambios de contexto: Cuando el programador del sistema necesita ejecutar otro programa o cuando una interrupción activa una ejecución continua, el sistema operativo guarda el contenido del registro de CPU del programa en ejecución y lo configura para la nueva ejecución del programa. No se produjeron cambios de contexto durante la ejecución del programa de C, pero se produjeron 7 cambios de contexto durante la ejecución del programa de Python.
Migraciones de CPU: El sistema operativo intenta mantener el balanceo de cargas de trabajo entre las CPU disponibles en los sistemas de varios procesadores. Este balanceo se realiza de manera periódica y cada vez que una cola de ejecución de CPU está vacía. Durante la prueba, no se observó migración de CPU.
Instrucciones: El programa de C dio como resultado 1.7 millones de instrucciones que se ejecutaron en 1.5 millones de ciclos de CPU (IPC = 1.13, CPI = 0.88), mientras que el programa de Python dio como resultado 158 millones de instrucciones que se ejecutaron en 144 millones de ciclos (IPC = 1.10, CPI = 0.91). Ambos programas llenaron la canalización, lo que permite que la CPU ejecute más de 1 instrucción por ciclo. Pero en comparación con C, la cantidad de instrucciones generadas para Python es alrededor de 90 veces mayor.
Fallas de página: Cada programa tiene una porción de memoria virtual que contiene todas sus instrucciones y datos. Por lo general, no es eficiente copiar todas estas instrucciones en la memoria principal a la vez. Un error de página ocurre cada vez que un programa necesita que se copie parte del contenido de su memoria virtual en la memoria principal. La CPU indica una falla de página a través de una interrupción.
Debido a que el intérprete ejecutable para Python es mucho mayor que para C, la sobrecarga adicional es evidente en términos de ciclos de CPU (1,500,000 para C, 144,000,000 para Python) y de errores de página (45 para C, 908 para Python).
Ramas y omisiones de ramas Para las instrucciones condicionales, la CPU intenta predecir la ruta de ejecución incluso antes de evaluar la condición de ramificación. Este paso es útil para mantener la canalización de instrucciones llena. Este proceso se denomina ejecución especulativa. La ejecución especulativa fue bastante exitosa en las ejecuciones anteriores: el predictor de ramas solo se equivocó un 2.59% de las veces para el programa en C y un 2.47% de las veces para el programa en Python.
Otros factores además de la CPU
Hasta ahora, analizaste varios aspectos de las CPU y su impacto en el rendimiento. Sin embargo, es poco común que una aplicación tenga una ejecución continua en la CPU el 100% del tiempo. A modo de ejemplo, considera el siguiente comando tar que crea un archivo a partir del directorio home de un usuario en Linux:
$ time tar cf archive.tar /home/"$(whoami)"
La salida obtenida se verá así:
real 0m35.798s user 0m1.146s sys 0m6.256s
Estos valores de salida se definen de la siguiente manera:
- tiempo real
- El tiempo real (
real) es la cantidad de tiempo que tarda la ejecución en comenzar. Este tiempo transcurrido incluye segmentos de tiempo que usan otros procesos y el tiempo en que el proceso está bloqueado, por ejemplo, cuando se espera que se completen las operaciones de E/S. - tiempo de usuario
- El tiempo de usuario (
user) es la cantidad de tiempo de CPU empleado en ejecutar el código del espacio del usuario en el proceso. - tiempo del sistema
- El tiempo del sistema (
sys) es la cantidad de tiempo de CPU empleado en ejecutar el código de espacio de kernel en el proceso.
En el ejemplo anterior, el tiempo de usuario es de 1.0 segundos, mientras que el tiempo del sistema es de 6.3 segundos. La diferencia de aproximadamente 28 segundos entre el tiempo real y el tiempo user + sys apunta al tiempo sin CPU que emplea el comando tar.
Un tiempo alto sin CPU para una ejecución indica que el proceso no está vinculado a la CPU. Se dice que el procesamiento se vincula a algo cuando ese recurso es el cuello de botella para lograr el rendimiento esperado. Cuando planificas una migración, es importante tener una visión integral de la aplicación y considerar todos los factores que pueden tener un impacto significativo en el rendimiento.
Función de la carga de trabajo de destino en la migración
A fin de encontrar un punto de partida razonable para la migración, es importante comparar los recursos subyacentes. Puedes realizar comparativas de rendimiento de varias maneras:
Carga de trabajo de destino real: Implementa la aplicación en el entorno de destino y el rendimiento de comparativas de los indicadores clave de rendimiento (KPI). Por ejemplo, los KPI de una aplicación web pueden incluir lo siguiente:
- Tiempo de carga de la aplicación
- Latencias de usuario final para transacciones de extremo a extremo
- Conexiones descartadas
- Cantidad de instancias de entrega para tráfico bajo, promedio y máximo
- Uso de recursos (CPU, RAM, disco y red) de las instancias de entrega
Sin embargo, implementar una aplicación de destino completa (o un subconjunto de ella) puede ser complejo y llevar mucho tiempo. Por lo general, se prefieren las comparativas basadas en programas para las comparativas preliminares.
Comparativas basadas en programas: Las comparativas basadas en programas se centran en componentes individuales de la aplicación en lugar de en el flujo de la aplicación de extremo a extremo. Estas comparativas ejecutan una combinación de perfiles de prueba en el que cada perfil se orienta a un componente de la aplicación. Por ejemplo, los perfiles de prueba para una implementación de pila LAMP pueden incluir Apache Bench, que se usa a fin de comparar el rendimiento del servidor web, y Sysbench, que se usa con el objetivo de comparar MySQL. Por lo general, estas pruebas son más fáciles de configurar que las cargas de trabajo de destino reales y son altamente portátiles en diferentes sistemas operativos y entornos.
Comparativas sintéticas o de kernel: Para probar aspectos intensivos en términos de procesamiento de programas reales, puedes usar comparativas sintéticas como la factorización de matrices o FFT. Por lo general, ejecutas estas pruebas durante la fase inicial de diseño de la aplicación. Son las más adecuadas para comparar solo ciertos aspectos de una máquina, como el estrés de VM y de disco, las sincronizaciones de E/S y la hiperpaginación de caché.
Información sobre tu aplicación
Muchas aplicaciones están vinculadas por CPU, memoria, E/S de disco y E/S de red, o una combinación de estos factores. Por ejemplo, si una aplicación experimenta lentitud debido a la contención en los discos, proporcionar más núcleos a los servidores no mejoraría el rendimiento.
Ten en cuenta que mantener la observabilidad de las aplicaciones en entornos grandes y complejos puede no ser trivial. Existen sistemas de supervisión especializados que pueden realizar un seguimiento de todos los recursos distribuidos en todo el sistema. Por ejemplo, en Google Cloud puedes usar Cloud Monitoring para obtener visibilidad completa del código, las aplicaciones y la infraestructura. Un ejemplo de Cloud Monitoring se analiza más adelante en esta sección, pero primero es una buena idea comprender la supervisión de los recursos típicos del sistema en un servidor independiente.
Muchos servicios como top, IOStat, iPerf y VMStat pueden proporcionar una vista de alto nivel de los recursos de sistema. Por ejemplo, ejecutar top en un sistema Linux produce un resultado como el siguiente:
top - 13:20:42 up 22 days, 5:25, 18 users, load average: 3.93 2.77,3.37 Tasks: 818 total, 1 running, 760 sleeping, 0 stopped, 0 zombie Cpu(s): 88.2%us, 0.0%sy, 0.0%ni, 0.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 49375504k total, 6675048k used, 42700456k free, 276332k buffers Swap: 68157432k total, 0k used, 68157432k free, 5163564k cached
Si el sistema tiene una carga alta y el porcentaje de tiempo de espera es alto, es probable que tengas una aplicación vinculada a E/S. Si el porcentaje de tiempo del usuario o el del sistema, o ambos, son muy altos, es probable que tengas una aplicación vinculada a la CPU.
En el ejemplo anterior, los promedios de carga (para una VM de 4 CPU virtuales) en los últimos 5 minutos, 10 minutos y 15 minutos son 3.93, 2.77 y 3.37, respectivamente. Si combinas estos promedios con el alto porcentaje de tiempo de usuario (88.2%), el tiempo de inactividad bajo (0.3%) y sin tiempo de espera (0.0%), puedes concluir que el sistema está vinculado a la CPU.
Aunque estas herramientas funcionan bien para sistemas independientes, por lo general, no están diseñadas a fin de supervisar entornos grandes y distribuidos. Para supervisar los sistemas de producción, las herramientas como Cloud Monitoring, Nagios, Prometheus y Sysdig pueden proporcionar un análisis profundo del consumo de recursos en tus aplicaciones.
La supervisión del rendimiento de la aplicación durante un período suficiente te permite recopilar datos en varias métricas, como uso de CPU, uso de memoria, E/S de disco y de red, tiempos de ida y vuelta, latencias, tasas de error, y capacidad de procesamiento. Por ejemplo, en los siguientes gráficos de Cloud Monitoring, se muestran las cargas de CPU y los niveles de uso junto con el uso de memoria y de disco para todos los servidores que se ejecutan en un grupo de instancias administrado de Google Cloud. Para obtener más información sobre esta configuración, consulta la descripción general del agente de Cloud Monitoring.
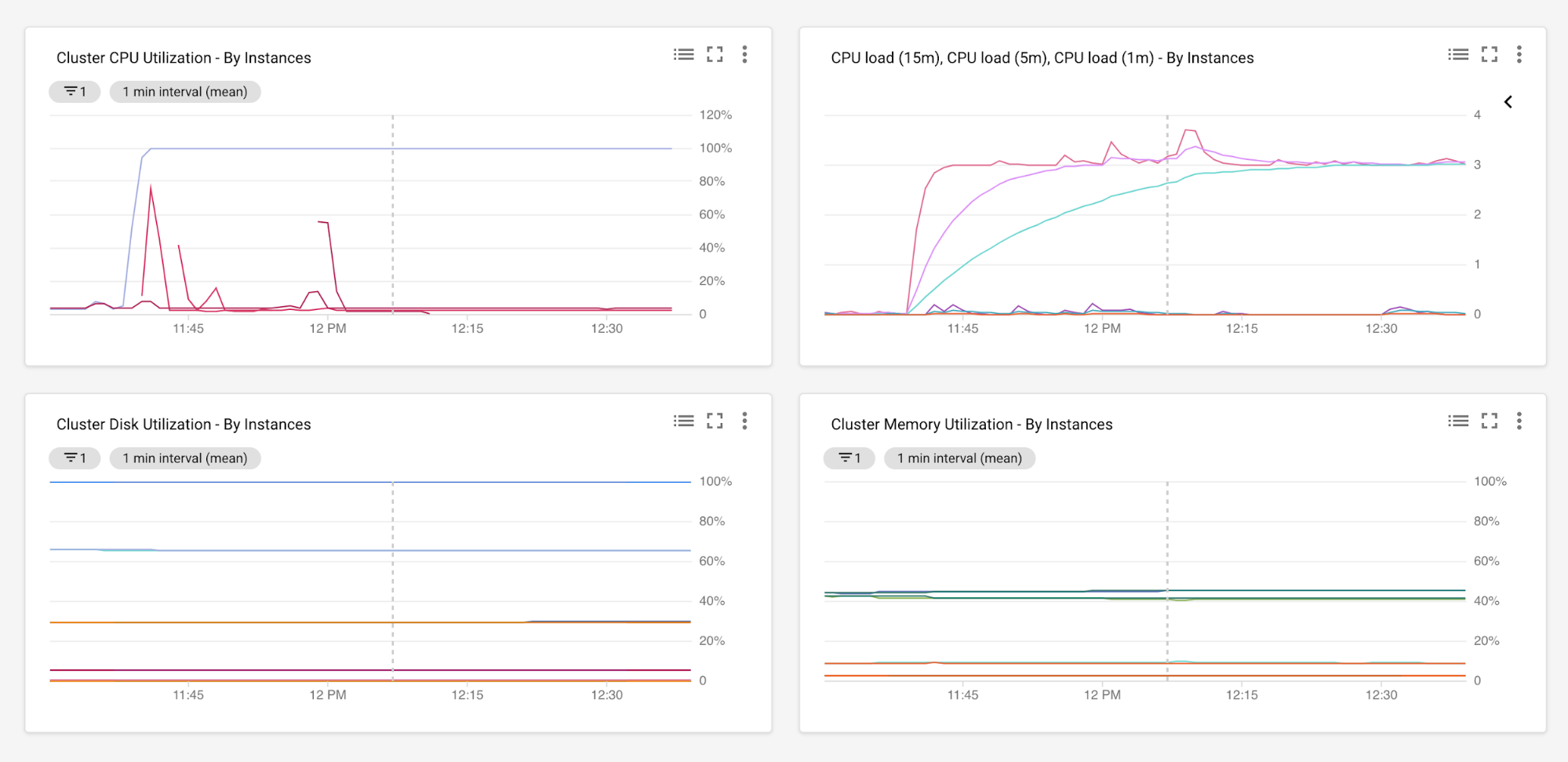
En el análisis, el período de recopilación de datos debe ser lo suficientemente largo como para mostrar el uso máximo y mínimo de los recursos. Luego, puedes analizar los datos recopilados a fin de proporcionar un punto de partida para la planificación de capacidad en el entorno de destino nuevo.
Asigna recursos
En esta sección, se explica cómo establecer el tamaño de los recursos en Google Cloud. Primero, realiza una evaluación de tamaño inicial según los niveles de uso de los recursos existentes. Luego, ejecuta pruebas de comparativas de rendimiento específicas de la aplicación.
Tamaño basado en el uso
Sigue estos pasos para asignar el recuento de núcleos existentes de un servidor a las CPU virtuales en Google Cloud.
Encuentra el recuento de núcleos actual. Consulta el comando
lscpuen la sección anterior.Encuentra el uso de CPU del servidor. El uso de CPU se refiere al tiempo que tarda la CPU cuando está en modo de usuario (
%us) o modo de kernel (%sy). Los procesos agradables (%ni) también pertenecen al modo de usuario, mientras que las interrupciones de software (%si) y las interrupciones de hardware (%hi) se controlan en el modo de kernel. Si la CPU no realiza ninguna de estas acciones, significa que está inactiva o espera a que se complete la E/S. Cuando un proceso espera a que se complete la E/S, no contribuye a los ciclos de CPU.Para calcular el uso actual de la CPU de un servidor, ejecuta el siguiente comando
top:... Cpu(s): 88.2%us, 0.0%sy, 0.0%ni, 0.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...El uso de CPU se define de la siguiente manera:
CPU Usage = %us + %sy + %ni + %hi + %siComo alternativa, puedes usar cualquier herramienta de supervisión, como Cloud Monitoring, que pueda recopilar el inventario y el uso de CPU necesarios. En el caso de las implementaciones de aplicaciones que no son de ajuste de escala automático (es decir, que se ejecutan con una cantidad fija de servidores o más), te recomendamos que uses el uso máximo para el tamaño de CPU. Este enfoque protege los recursos de la aplicación contra las interrupciones cuando las cargas de trabajo están en su punto máximo de uso. En cuanto a las implementaciones de ajuste de escala automático (basadas en el uso de CPU), el uso de CPU promedio es un punto de referencia seguro que se debe considerar para el tamaño. En ese caso, controlas los aumentos del tráfico mediante el escalamiento horizontal de la cantidad de servidores durante el aumento.
Asigna suficiente búfer para que se adapten a cualquier aumento. Cuando establezcas el tamaño de la CPU, incluye suficiente búfer para que se adapte a cualquier procesamiento no programado que pueda causar aumentos inesperados. Por ejemplo, puedes planificar la capacidad de la CPU de modo que haya un margen adicional del 10 al 15% sobre el uso máximo esperado y el uso de CPU máximo no supere el 70%.
Usa la siguiente fórmula para calcular el recuento de núcleos esperado en GCP:
CPU virtuales en Google Cloud = 2 × CEILING [(recuento de núcleos × % de uso) / (2 × % de umbral)]
Estos valores se definen de la siguiente manera:
- recuento de núcleos: Es el conteo de núcleos existentes (como se calculó en el paso 1)
- % de uso: El uso de CPU del servidor (como se calculó en el paso 2).
- % de umbral: El uso máximo de CPU permitido en el servidor después de tener en cuenta el margen suficiente (como se calculó en el paso 3).
Para ver un ejemplo concreto, considera una situación en la que tienes que asignar el recuento de núcleos de un servidor bare metal Xeon E5640 de 4 núcleos que se ejecuta de forma local en las CPU virtuales. Las especificaciones de Xeon E5640 están disponibles de manera pública, pero también puedes confirmar esto mediante la ejecución de un comando como lscpu en el sistema.
Los números se ven de la siguiente manera:
- recuento de núcleos locales existentes = sockets (1) × núcleos (4) × subprocesos por núcleo (2) = 8.
- Supongamos que el uso de CPU (% de uso) observado durante el tráfico máximo es del 40%.
- Existe un aprovisionamiento para un búfer adicional del 30%, es decir, el uso de CPU máximo (% de umbral) no debe superar el 70%.
- CPU virtuales en Google Cloud = 2 × CEILING [(8 × 0.4)/(2 × 0.7)] = 6 CPU virtuales
(es decir, 2 × CEILING [3.2/1.4] = 2 × CEILING [2.28] = 2 × 3 = 6)
Puedes realizar evaluaciones similares para la RAM, el disco, la E/S de red y otros recursos del sistema.
Tamaño basado en el rendimiento
En la sección anterior, se trataron los detalles de la asignación de las CPU físicas a las CPU virtuales según los niveles actuales esperados del uso de CPU. En esta sección, se considera la aplicación que se ejecuta en el servidor.
En esta sección, ejecutarás un conjunto estándar y canónico de pruebas (comparativas basadas en programas) para comparar el rendimiento. Continúa con la situación de ejemplo y considera que estás ejecutando un servidor MySQL en la máquina Xeon E5. En este caso, puedes usar OLTP de Sysbench para comparar el rendimiento de las bases de datos.
Una prueba de lectura y escritura simple en MySQL mediante Sysbench produce el siguiente resultado:
OLTP test statistics:
queries performed:
read: 520982
write: 186058
other: 74424
total: 781464
transactions: 37211 (620.12 per sec.)
deadlocks: 2 (0.03 per sec.)
read/write requests: 707040 (11782.80 per sec.)
other operations: 74424 (1240.27 per sec.)
Test execution summary:
total time: 60.0061s
total number of events: 37211
total time taken by event execution: 359.8158
per-request statistics:
min: 2.77ms
avg: 9.67ms
max: 50.81ms
approx. 95 percentile: 14.63ms
Thread fairness:
events (avg/stddev): 6201.8333/31.78
execution time (avg/stddev): 59.9693/0.00
La ejecución de esta comparativa te permite comparar el rendimiento en términos de cantidad de transacciones por segundo, lecturas o escrituras totales por segundo y tiempo de ejecución de extremo a extremo entre tu entorno actual y Google Cloud. Te recomendamos que ejecutes varias iteraciones de estas pruebas para descartar valores atípicos. Para observar las diferencias de rendimiento en diferentes patrones de carga y tráfico, también puedes repetir estas pruebas con diferentes parámetros, como los niveles de simultaneidad, la duración de las pruebas y la cantidad de usuarios simulados o las variantes de tarifas de Hatch.
Las cifras de rendimiento entre el entorno actual y Google Cloud te ayudarán a justificar aún más la evaluación de capacidad inicial. Si las pruebas comparativas en Google Cloud producen resultados similares o mejores que el entorno existente, puedes ajustar aún más la escala de los recursos según las mejoras de rendimiento. Por otro lado, si las comparativas en el entorno existente son mejores que en Google Cloud, debes hacer lo siguiente:
- Revisar la evaluación de capacidad inicial
- Supervisar los recursos del sistema
- Encontrar posibles áreas de contención (por ejemplo, cuellos de botella identificados en la CPU y la RAM)
- Cambiar el tamaño de los recursos según corresponda
Cuando termines, vuelve a ejecutar las pruebas comparativas específicas de la aplicación.
Comparativas de rendimiento de extremo a extremo
Hasta ahora, observaste una situación simplista que comparó solo el rendimiento de MySQL entre las instalaciones locales y Google Cloud. En esta sección, considerarás la siguiente aplicación distribuida de 3 niveles.

Como se muestra en el diagrama, es probable que ejecutes varias comparativas para alcanzar una evaluación razonable de tu entorno actual y el de Google Cloud. Sin embargo, puede ser difícil establecer qué subconjunto de comparativas estima el rendimiento de tu aplicación con mayor precisión. Además, puede ser una tarea tediosa administrar el proceso de prueba desde la administración de dependencias hasta la instalación de la prueba, la ejecución y la agregación de resultados en diferentes entornos de nube o no basados en la nube. Para tales situaciones, puedes usar PerfKitBenchmarker. PerfKit contiene varios conjuntos de comparativas para medir y comparar diferentes ofertas en varias nubes. También puede ejecutar ciertas comparativas locales a través de máquinas estáticas.
Supongamos que, para la aplicación de 3 niveles del diagrama anterior, deseas ejecutar pruebas a fin de comparar el tiempo de inicio del clúster, la CPU y el rendimiento de la red de VM en Google Cloud. Si usas PerfKitBenchmarker, puedes ejecutar varias iteraciones de perfiles de prueba relevantes, que producen los siguientes resultados:
Tiempo de inicio del clúster: Proporciona una vista del tiempo de inicio de la VM. Esto es muy importante si la aplicación es elástica y espera que se agreguen o quiten instancias como parte del ajuste de escala automático. En el siguiente gráfico, se muestra que los tiempos de inicio de una instancia
n1-standard-4de Compute Engine se mantienen bastante coherentes (hasta el percentil 99) entre 40 a 45 segundos.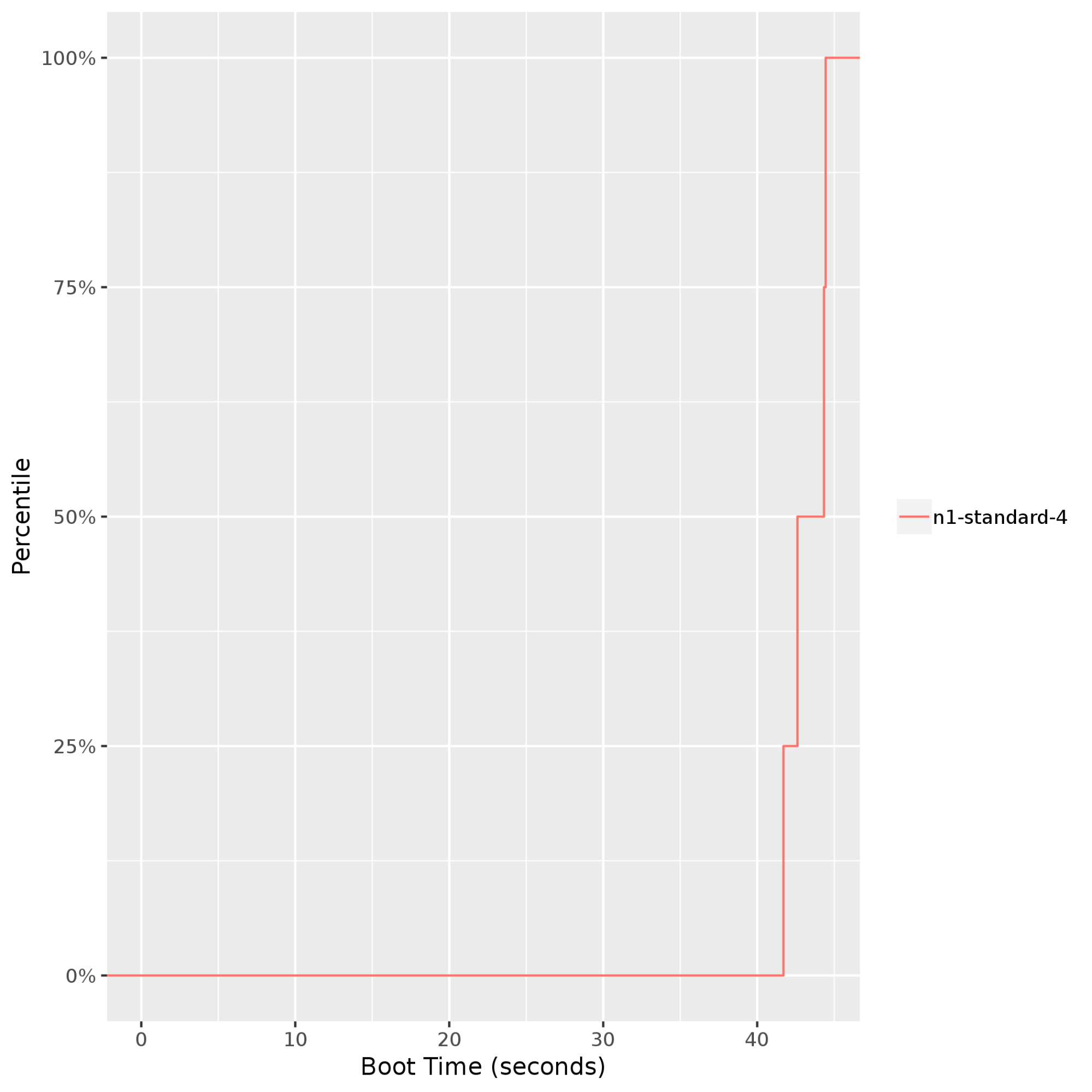
Stress-ng: Mide y compara el rendimiento intensivo del procesamiento cuando se presiona el procesador, el subsistema de memoria y el compilador de un sistema. En el siguiente ejemplo,stress-ngejecuta varias pruebas de esfuerzo, comobsearch,malloc,matrix,mergesortyzliben una instancian1-standard-4de Compute Engine.Stress-ngmide la capacidad de procesamiento de pruebas de esfuerzo mediante operaciones falsas (operaciones bogo) por segundo. Si normalizas las operaciones bogo en diferentes resultados de pruebas de esfuerzo, obtienes el siguiente resultado, que muestra la media geométrica de las operaciones ejecutadas por segundo. En este ejemplo, las operaciones bogo varían de alrededor de 8,000 por segundo en el percentil 50 a cerca de 10,000 por segundo en el percentil 95. Ten en cuenta que las operaciones bogo, en general, se usan para comparar solo el rendimiento de la CPU independiente. Es posible que estas operaciones no sean representativas en tu aplicación.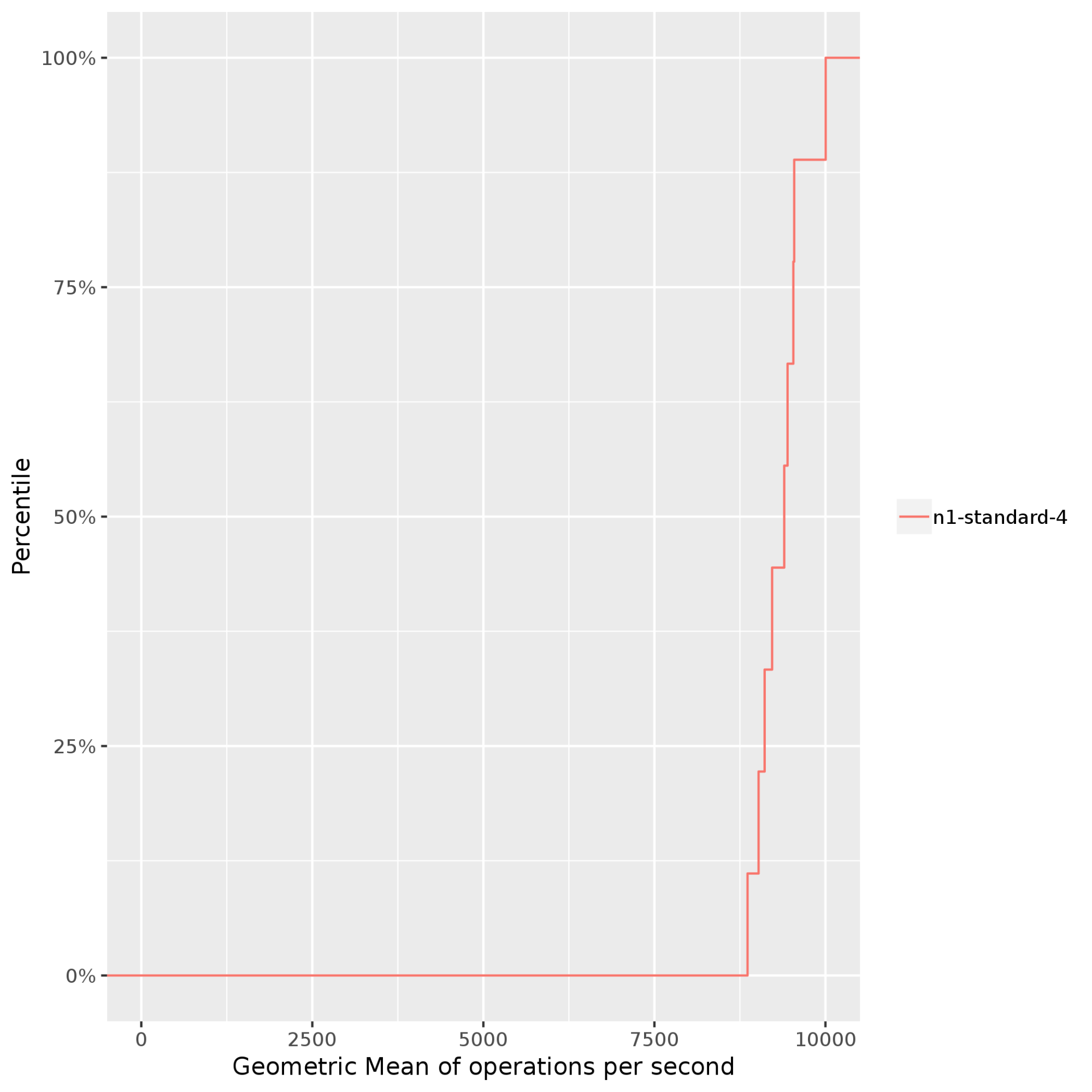
Netperf: Mide la latencia con pruebas de solicitud y respuesta. Las pruebas de solicitud y respuesta se ejecutan en la capa de la aplicación de la pila de red. Este método de prueba de latencia involucra todas las capas de la pila y es preferible a las pruebas de ping para medir la latencia entre VM. En el siguiente gráfico, se muestran las latencias de solicitud y respuesta de TCP (TCP_RR) entre un cliente y un servidor que se ejecutan en la misma zona de Google Cloud. Los valores de TCP_RR varían de alrededor de 70 microsegundos en el percentil 50 a cerca de 130 microsegundos en el percentil 90.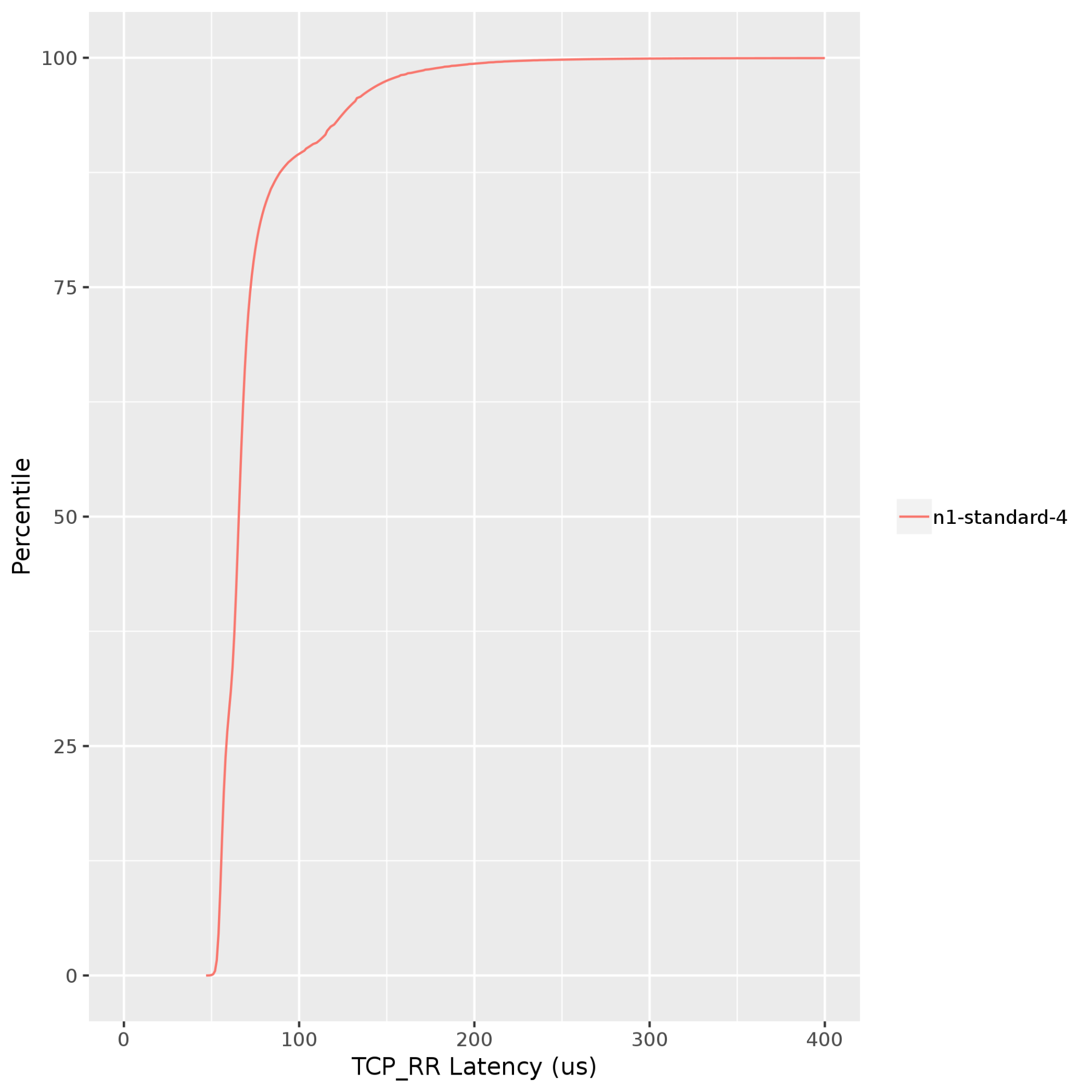
Dada la naturaleza de la carga de trabajo de destino, puedes ejecutar otros perfiles de prueba mediante PerfKit. Para obtener más información, consulta las comparativas admitidas en PerfKit.
Prácticas recomendadas en Google Cloud
Antes de configurar y ejecutar un plan de migración en Google Cloud, te recomendamos seguir las prácticas recomendadas de migración. Estas prácticas son solo un punto de partida. Es posible que debas considerar muchos otros aspectos de tu aplicación, como la separación de dependencias, la introducción de tolerancia a errores, y el escalamiento vertical y reducido según la carga de trabajo de los componentes, y cómo cada uno de esos aspectos se asigna a Google Cloud.
Conoce los límites y las cuotas de Google Cloud. Antes de comenzar formalmente con la evaluación de capacidad, debes comprender algunas consideraciones importantes para la planificación de recursos en Google Cloud, por ejemplo:
- Cuotas de red por instancia
- Rendimiento del disco en Google Cloud
- Plataformas de CPU disponibles en Google Cloud
Enumera los componentes de infraestructura como servicio (IaaS) y plataforma como servicio (PaaS) que se requerirían durante la migración y comprende con claridad cualquier cuota, límite y cualquier ajuste que esté disponible con cada servicio.
Supervisa los recursos de forma continua. La supervisión continua de recursos puede ayudarte a identificar patrones y tendencias en el rendimiento del sistema y las aplicaciones. La supervisión no solo ayuda a establecer el rendimiento del modelo de referencia, sino que también demuestra la necesidad de actualizar y cambiar a una versión inferior del hardware. Google Cloud ofrece varias opciones para implementar soluciones de supervisión de extremo a extremo:
Ajusta el tamaño de las VM. Identifica si una VM está aprovisionada de forma insuficiente o en exceso. Si configuras la supervisión básica como se mencionó antes, se deberían proporcionar estas estadísticas con facilidad. Google Cloud también proporciona recomendaciones de tamaño adecuado según el uso histórico de una instancia. Además, en función de la naturaleza de la carga de trabajo, si los tipos predefinidos de máquina no satisfacen tus necesidades, puedes crear una instancia con la configuración de hardware virtualizada y personalizada.
Usa las herramientas adecuadas. En entornos de gran escala, implementa herramientas automatizadas para minimizar el esfuerzo manual, por ejemplo:
- StratoZone y CloudPhysics para el descubrimiento de aplicaciones y la recopilación de datos de inventario
- Migrate to Virtual Machines a fin de migrar VM a Google Cloud y para pruebas integradas con el objetivo de validar el rendimiento, los ANS y el costo en la nube.
- Database Migration Service para migrar datos y bases de datos a Google Cloud.
- Cloud Deployment Manager para aprovisionar recursos de infraestructura en la nube como código (IaC)
Conclusiones
La migración de recursos de un entorno a otro requiere una planificación cuidadosa. Es importante no mirar los recursos de hardware de forma aislada, sino tener una vista de extremo a extremo de la aplicación. Por ejemplo, en lugar de enfocarse solo en si un procesador Sandy Bridge de 3.0 GHz será el doble de rápido que un procesador Skylake de 1.5 GHz, céntrate en cómo los indicadores clave de rendimiento de la aplicación cambian de una plataforma a otra.
Cuando evalúas los requisitos de asignación de recursos en diferentes entornos, ten en cuenta lo siguiente:
- Los recursos del sistema que limitan a la aplicación (por ejemplo, la CPU, la memoria, el disco o la red)
- El impacto de la infraestructura subyacente (por ejemplo, la generación de procesadores, la velocidad del reloj, el HDD o el SSD) en el rendimiento de la aplicación
- El impacto de las opciones de diseño de arquitectura y software (por ejemplo, las cargas de trabajo multiproceso, las implementaciones fijas o de ajuste de escala automático) en el rendimiento de la aplicación
- Los niveles de uso actuales y esperados de procesamiento, almacenamiento y recursos de red
- Las pruebas de rendimiento más adecuadas que son representativas de la aplicación
La recopilación de datos con estas métricas a través de la supervisión continua te ayuda a determinar un plan de capacidad inicial. Para llevar a cabo un seguimiento, realiza las comparativas de rendimiento adecuadas a fin de ajustar las estimaciones de tamaño iniciales.
¿Qué sigue?
- Obtén más información sobre las prácticas recomendadas para migrar las VM a Google Cloud.
- Lee sobre el centro de migración de Google Cloud.
- Obtén más información sobre Cloud Foundation Toolkit.
- Obtén más información sobre cómo comenzar con la migración de Google Cloud.
- Obtén más información sobre cómo Google Cloud se compara con otras plataformas en la nube.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.