Migração do Oracle para o BigQuery
Este documento fornece orientações gerais sobre como migrar do Oracle para o BigQuery. Descreve as diferenças arquitetónicas fundamentais e sugere formas de migração de armazéns de dados e data marts executados no SGBDR Oracle (incluindo o Exadata) para o BigQuery. Este documento fornece detalhes que também se podem aplicar ao Exadata, ao ExaCC e ao Oracle Autonomous Data Warehouse, uma vez que usam software Oracle compatível.
Este documento destina-se a arquitetos empresariais, DBAs, programadores de aplicações e profissionais de segurança de TI que pretendam migrar do Oracle para o BigQuery e resolver desafios técnicos no processo de migração.
Também pode usar a tradução de SQL em lote para migrar os seus scripts SQL em massa ou a tradução de SQL interativa para traduzir consultas ad hoc. O Oracle SQL, o PL/SQL e o Exadata são suportados por ambas as ferramentas na pré-visualização.
Pré-migração
Para garantir uma migração bem-sucedida do armazém de dados, comece a planear a sua estratégia de migração no início da cronologia do projeto. Para obter informações sobre como planear sistematicamente o seu trabalho de migração, consulte o artigo O que e como migrar: a estrutura de migração.
Planeamento de capacidade do BigQuery
Nos bastidores, o débito de análise no BigQuery é medido em slots. Um slot do BigQuery é a unidade proprietária da Google de capacidade computacional necessária para executar consultas SQL.
O BigQuery calcula continuamente quantos slots são necessários para as consultas à medida que são executadas, mas atribui slots às consultas com base num programador justo.
Pode escolher entre os seguintes modelos de preços quando planear a capacidade dos slots do BigQuery:
Preços a pedido: nos preços a pedido, o BigQuery cobra com base no número de bytes processados (tamanho dos dados), pelo que paga apenas pelas consultas que executa. Para mais informações sobre como o BigQuery determina o tamanho dos dados, consulte o artigo Cálculo do tamanho dos dados. Uma vez que os slots determinam a capacidade de computação subjacente, pode pagar a utilização do BigQuery consoante o número de slots de que precisa (em vez de bytes processados). Por predefinição, Google Cloud os projetos estão limitados a um máximo de 2000 espaços.
Preços baseados na capacidade: Com os preços baseados na capacidade, compra reservas de slots do BigQuery (um mínimo de 100) em vez de pagar pelos bytes processados pelas consultas que executa. Recomendamos os preços baseados na capacidade para cargas de trabalho de armazéns de dados empresariais, que normalmente têm muitas consultas de relatórios e de extrair, carregar e transformar (ELT) simultâneas com um consumo previsível.
Para ajudar na estimativa de ranhuras, recomendamos que configure a monitorização do BigQuery com o Cloud Monitoring e analise os seus registos de auditoria com o BigQuery. Muitos clientes usam o Looker Studio (por exemplo, consulte um exemplo de código aberto de um painel de controlo do Looker Studio), o Looker ou o Tableau como front-ends para visualizar dados de registo de auditoria do BigQuery, especificamente para a utilização de slots em consultas e projetos. Também pode tirar partido dos dados das tabelas do sistema do BigQuery para monitorizar a utilização de slots em tarefas e reservas. Por exemplo, consulte um exemplo de código aberto de um painel de controlo do Looker Studio.
A monitorização e a análise regulares da utilização de slots ajudam a estimar o número total de slots de que a sua organização precisa à medida que cresce no Google Cloud.
Por exemplo, suponha que reserva inicialmente 4000 slots do BigQuery para executar 100 consultas de complexidade média em simultâneo. Se notar tempos de espera elevados nos planos de execução das suas consultas e os painéis de controlo mostrarem uma utilização elevada de slots, isto pode indicar que precisa de slots do BigQuery adicionais para ajudar a suportar as suas cargas de trabalho. Se quiser comprar slots através de compromissos anuais ou de três anos, pode começar a usar as reservas do BigQuery através da Google Cloud consola ou da ferramenta de linha de comandos bq.
Para quaisquer perguntas relacionadas com o seu plano atual e as opções anteriores, contacte o seu representante de vendas.
Segurança em Google Cloud
As secções seguintes descrevem os controlos de segurança comuns da Oracle e como pode garantir que o seu data warehouse permanece protegido num ambiente Google Cloud.
Gestão de identidade e de acesso (IAM)
A Oracle fornece utilizadores, privilégios, funções e perfis para gerir o acesso aos recursos.
O BigQuery usa o IAM para gerir o acesso aos recursos e fornece uma gestão de acesso centralizada aos recursos e às ações. Os tipos de recursos disponíveis no BigQuery incluem organizações, projetos, conjuntos de dados, tabelas e vistas. Na hierarquia de políticas IAM, os conjuntos de dados são recursos secundários dos projetos. Uma tabela herda autorizações do conjunto de dados que a contém.
Para conceder acesso a um recurso, atribua uma ou mais funções a um utilizador, um grupo ou uma conta de serviço. As funções de organização e projeto afetam a capacidade de executar tarefas ou gerir o projeto, enquanto as funções de conjunto de dados afetam a capacidade de aceder ou modificar os dados num projeto.
O IAM fornece os seguintes tipos de funções:
- As funções predefinidas destinam-se a suportar exemplos de utilização comuns e padrões de controlo de acesso. As funções predefinidas oferecem acesso detalhado a um serviço específico e são geridas pela Google Cloud.
As funções básicas incluem as funções de proprietário, editor e leitor.
As funções personalizadas oferecem acesso detalhado de acordo com uma lista de autorizações especificada pelo utilizador.
Quando atribui funções predefinidas e básicas a um utilizador, as autorizações concedidas são uma união das autorizações de cada função individual.
Segurança ao nível da linha
A segurança de etiquetas da Oracle (OLS) permite a restrição do acesso aos dados linha a linha. Um exemplo de utilização típico da segurança ao nível da linha é restringir o acesso de um vendedor às contas que gere. Ao implementar a segurança ao nível da linha, obtém um controlo de acesso detalhado.
Para alcançar a segurança ao nível da linha no BigQuery, pode usar vistas autorizadas e políticas de acesso ao nível da linha. Para mais informações sobre como conceber e implementar estas políticas, consulte o artigo Introdução à segurança ao nível da linha do BigQuery.
Encriptação full disk
A Oracle oferece encriptação de dados transparente (TDE) e encriptação de rede para encriptação de dados inativos e em movimento. A TDE requer a opção de segurança avançada, que é licenciada em separado.
O BigQuery encripta todos os dados em repouso e em trânsito por predefinição, independentemente da origem ou de qualquer outra condição, e esta opção não pode ser desativada. O BigQuery também suporta chaves de encriptação geridas pelo cliente (CMEK) para os utilizadores que pretendam controlar e gerir chaves de encriptação de chaves no Cloud Key Management Service. Para mais informações sobre a encriptação em Google Cloud, consulte Encriptação predefinida em repouso e Encriptação em trânsito.
Ocultação e ocultação de dados
A Oracle usa a ocultação de dados no Real Application Testing e a ocultação de dados, que lhe permite ocultar (ocultar) dados devolvidos por consultas emitidas por aplicações.
O BigQuery suporta ocultação dinâmica de dados ao nível da coluna. Pode usar a ocultação de dados para obscurecer seletivamente os dados das colunas para grupos de utilizadores, ao mesmo tempo que permite o acesso à coluna.
Pode usar a Proteção de dados confidenciais para identificar e ocultar informações de identificação pessoal (IIP) confidenciais no BigQuery.
Comparação entre o BigQuery e o Oracle
Esta secção descreve as principais diferenças entre o BigQuery e o Oracle. Estes destaques ajudam a identificar obstáculos à migração e a planear as alterações necessárias.
Arquitetura do sistema
Uma das principais diferenças entre o Oracle e o BigQuery é que o BigQuery é um EDW na nuvem sem servidor com camadas de armazenamento e computação separadas que podem ser dimensionadas com base nas necessidades da consulta. Dada a natureza da oferta sem servidor do BigQuery, não está limitado por decisões de hardware. Em alternativa, pode pedir mais recursos para as suas consultas e utilizadores através de reservas. O BigQuery também não requer a configuração do software e da infraestrutura subjacentes, como o sistema operativo (SO), os sistemas de rede e os sistemas de armazenamento, incluindo o escalonamento e a elevada disponibilidade. O BigQuery cuida da escalabilidade, da gestão e das operações administrativas. O diagrama seguinte ilustra a hierarquia de armazenamento do BigQuery.
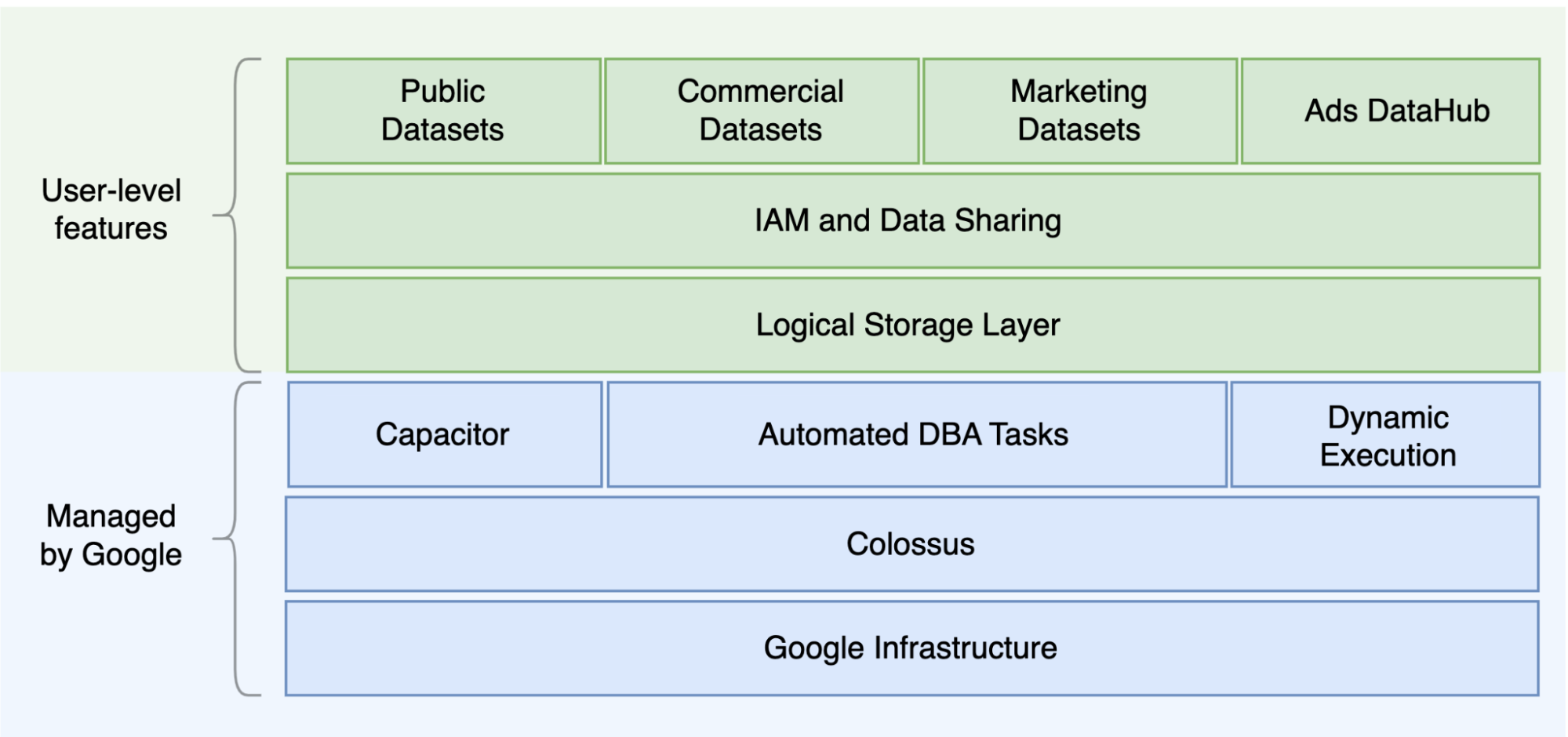
O conhecimento da arquitetura de processamento de consultas e armazenamento subjacente, como a separação entre o armazenamento (Colossus) e a execução de consultas (Dremel), e a forma como oGoogle Cloud aloca recursos (Borg) pode ser útil para compreender as diferenças comportamentais e otimizar o desempenho das consultas e a rentabilidade. Para ver detalhes, consulte as arquiteturas de sistemas de referência para o BigQuery, o Oracle e o Exadata.
Arquitetura de dados e armazenamento
A estrutura de dados e armazenamento é uma parte importante de qualquer sistema de estatísticas de dados, uma vez que afeta o desempenho das consultas, o custo, a escalabilidade e a eficiência.
O BigQuery desvincula o armazenamento de dados e a computação e armazena os dados no Colossus, no qual os dados são comprimidos e armazenados num formato de colunas denominado Capacitor.
O BigQuery opera diretamente em dados comprimidos sem descomprimir através do Capacitor. O BigQuery fornece conjuntos de dados como a abstração de nível mais elevado para organizar o acesso às tabelas, conforme mostrado no diagrama anterior. Os esquemas e as etiquetas podem ser usados para uma maior organização das tabelas. O BigQuery oferece a partição para melhorar o desempenho das consultas e os custos, bem como para gerir o ciclo de vida das informações. Os recursos de armazenamento são atribuídos à medida que os consome e são desatribuídos à medida que remove dados ou elimina tabelas.
O Oracle armazena dados no formato de linhas através do formato de blocos do Oracle organizado em segmentos. Os esquemas (detidos pelos utilizadores) são usados para organizar tabelas e outros objetos da base de dados. A partir do Oracle 12c, a arquitetura multitenant é usada para criar bases de dados conectáveis numa instância de base de dados para maior isolamento. A partição pode ser usada para melhorar o desempenho das consultas e as operações do ciclo de vida das informações. A Oracle oferece várias opções de armazenamento para bases de dados autónomas e Real Application Clusters (RAC), como ASM, um sistema de ficheiros do SO e um sistema de ficheiros de cluster.
O Exadata oferece uma infraestrutura de armazenamento otimizada em servidores de células de armazenamento e permite que os servidores Oracle acedam a estes dados de forma transparente através da utilização do ASM. O Exadata oferece opções de compressão híbrida em colunas (HCC) para que os utilizadores possam comprimir tabelas e partições.
A Oracle requer capacidade de armazenamento pré-aprovisionada, dimensionamento cuidadoso e configurações de incremento automático em segmentos, ficheiros de dados e espaços de tabelas.
Execução e desempenho de consultas
O BigQuery gere o desempenho e a escala ao nível da consulta para maximizar o desempenho em função do custo. O BigQuery usa muitas otimizações, por exemplo:
- Execução de consultas na memória
- Arquitetura de árvore de vários níveis baseada no motor de execução Dremel
- Otimização automática do armazenamento no Capacitor
- 1 petabit por segundo de largura de banda de bissecção total com Jupiter
- Gestão de recursos de dimensionamento automático para fornecer consultas rápidas ao nível de petabytes
O BigQuery recolhe estatísticas de colunas durante o carregamento dos dados e inclui informações de plano de consulta e de tempo de diagnóstico. Os recursos de consulta são atribuídos de acordo com o tipo e a complexidade da consulta. Cada consulta usa um determinado número de ranhuras, que são unidades de cálculo que incluem uma determinada quantidade de CPU e RAM.
A Oracle fornece estatísticas de dados de tarefas de recolha. O otimizador da base de dados usa estatísticas para fornecer planos de execução ideais. Podem ser necessários índices para pesquisas rápidas de linhas e operações de junção. A Oracle também oferece um armazenamento de colunas na memória para estatísticas na memória. O Exadata oferece várias melhorias de desempenho, como a análise inteligente de células, os índices de armazenamento, a cache flash e as ligações InfiniBand entre os servidores de armazenamento e os servidores de base de dados. Os clusters de aplicações reais (RAC) podem ser usados para alcançar a alta disponibilidade do servidor e dimensionar aplicações com utilização intensiva do processador da base de dados usando o mesmo armazenamento subjacente.
A otimização do desempenho das consultas com o Oracle requer uma consideração cuidadosa destas opções e parâmetros da base de dados. A Oracle oferece várias ferramentas, como o histórico de sessões ativas (ASH), o monitor de diagnóstico automático da base de dados (ADDM), relatórios do repositório automático de carga de trabalho (AWR), monitorização de SQL e Tuning Advisor, e consultores de anulação e ajuste de memória para o ajuste de desempenho.
Estatísticas ágeis
No BigQuery, pode permitir que diferentes projetos, utilizadores e grupos consultem conjuntos de dados em diferentes projetos. A separação da execução de consultas permite que as equipas autónomas trabalhem nos respetivos projetos sem afetar outros utilizadores e projetos, separando as quotas de slots e a faturação de consultas de outros projetos e dos projetos que alojam os conjuntos de dados.
Alta disponibilidade, cópias de segurança e recuperação de desastres
A Oracle fornece o Data Guard como uma solução de recuperação de desastres e replicação de bases de dados. Os Real Application Clusters (RAC) podem ser configurados para a disponibilidade do servidor. As cópias de segurança do Recovery Manager (RMAN) podem ser configuradas para cópias de segurança de bases de dados e de registos de arquivo, e também usadas para operações de restauro e recuperação. A funcionalidade Base de dados de retrocesso pode ser usada para retrocessos da base de dados para recuar a base de dados para um ponto específico no tempo. A anulação do espaço de tabelas contém instantâneos de tabelas. É possível consultar antigas imagens instantâneas com a consulta flashback e as cláusulas de consulta "as of" (a partir de) consoante as operações DML/DDL realizadas anteriormente e as definições de retenção de anulação. No Oracle, a integridade total da base de dados deve ser gerida em espaços de tabelas que dependam dos metadados do sistema, da anulação e dos espaços de tabelas correspondentes, porque a consistência forte é importante para a cópia de segurança do Oracle, e os procedimentos de recuperação devem incluir dados primários completos. Pode agendar exportações ao nível do esquema da tabela se não precisar da recuperação num determinado momento no Oracle.
O BigQuery é totalmente gerido e difere dos sistemas de base de dados tradicionais na sua funcionalidade de cópia de segurança completa. Não tem de considerar falhas do servidor, falhas de armazenamento, erros do sistema e corrupções de dados físicos. O BigQuery replica os dados em diferentes centros de dados, consoante a localização do conjunto de dados, para maximizar a fiabilidade e a disponibilidade. A funcionalidade multirregional do BigQuery replica dados em diferentes regiões e protege contra a indisponibilidade de uma única zona na região. A funcionalidade de região única do BigQuery replica os dados em diferentes zonas na mesma região.
O BigQuery permite-lhe consultar instantâneos históricos de tabelas até sete dias e restaurar tabelas eliminadas no prazo de dois dias através da viagem no tempo.
Pode copiar uma tabela eliminada (para a restaurar) através da sintaxe snapshot (dataset.table@timestamp).
Pode exportar dados de tabelas do
BigQuery para necessidades de cópias de segurança adicionais, como a recuperação
de operações acidentais do utilizador. Pode usar uma estratégia de cópia de segurança comprovada e programações usadas para sistemas de data warehouse (DWH) existentes para fazer cópias de segurança.
As operações em lote e a técnica de criação de instantâneos permitem diferentes estratégias de cópia de segurança para o BigQuery, pelo que não precisa de exportar tabelas e partições inalteradas com frequência. Uma cópia de segurança de exportação da partição ou da tabela é suficiente após a conclusão da operação de carregamento ou ETL. Para reduzir o custo da cópia de segurança, pode armazenar ficheiros de exportação no Nearline Storage ou Coldline Storage do Cloud Storage e definir uma política do ciclo de vida para eliminar ficheiros após um determinado período, consoante os requisitos de retenção de dados.
A colocar em cache
O BigQuery oferece uma cache por utilizador e, se os dados não mudarem, os resultados das consultas são colocados em cache durante aproximadamente 24 horas. Se os resultados forem obtidos a partir da cache, a consulta não tem custos.
A Oracle oferece várias caches para dados e resultados de consultas, como buffer cache, result cache, Exadata Flash Cache e in-memory column store.
Ligações
O BigQuery processa a gestão de ligações e não requer que faça nenhuma configuração do lado do servidor. O BigQuery fornece controladores JDBC e
ODBC. Pode usar a
Google Cloud consola ou o
bq command-line tool para consultas
interativas. Pode usar APIs REST e bibliotecas
de cliente para interagir
programaticamente com o BigQuery. Pode associar
o Google Sheets
diretamente ao BigQuery e usar controladores ODBC e JDBC
para estabelecer ligação ao Excel. Se procura um cliente para computador, existem ferramentas gratuitas, como o DBeaver.
A Oracle fornece listeners, serviços, controladores de serviços, vários parâmetros de configuração e otimização, e servidores partilhados e dedicados para processar ligações à base de dados. A Oracle fornece controladores JDBC, JDBC Thin, ODBC, Oracle Client e ligações TNS. Os ouvintes de análise, os endereços IP de análise e o nome de análise são necessários para as configurações de RAC.
Preços e licenciamento
A Oracle requer taxas de licença e suporte com base nas contagens de núcleos para edições da base de dados e opções da base de dados, como RAC, multiinquilino, Active Data Guard, partição, na memória, Real Application Testing, GoldenGate e Spatial and Graph.
O BigQuery oferece opções de preços flexíveis com base na utilização de armazenamento, consultas e inserções por stream. O BigQuery oferece preços baseados na capacidade para clientes que precisam de custos previsíveis e capacidade de slots em regiões específicas. Os espaços usados para inserções de streaming e carregamentos não são contabilizados na capacidade de espaços do projeto. Para decidir quantos slots quer comprar para o seu armazém de dados, consulte o artigo Planeamento da capacidade do BigQuery.
O BigQuery também reduz automaticamente os custos de armazenamento em metade para dados não modificados armazenados durante mais de 90 dias.
Etiquetagem
Os conjuntos de dados, as tabelas e as vistas do BigQuery podem ser etiquetados com pares de chave-valor. As etiquetas podem ser usadas para diferenciar os custos de armazenamento e as cobranças internas.
Monitorização e registo de auditoria
A Oracle oferece diferentes níveis e tipos de opções de auditoria de base de dados e funcionalidades de firewall de base de dados e cofre de auditoria, que são licenciadas em separado. A Oracle fornece o Enterprise Manager para a monitorização de bases de dados.
Para o BigQuery, os registos de auditoria na nuvem são usados para registos de acesso a dados e registos de auditoria, que estão ativados por predefinição. Os registos de acesso aos dados estão disponíveis durante 30 dias, e os outros eventos do sistema e registos de atividade do administrador estão disponíveis durante 400 dias. Se precisar de um período de retenção mais longo, pode exportar registos para o BigQuery, o Cloud Storage ou o Pub/Sub, conforme descrito em Análise de registos de segurança no Google Cloud. Se for necessária a integração com uma ferramenta de monitorização de incidentes existente, pode usar o Pub/Sub para exportações e deve fazer o desenvolvimento personalizado na ferramenta existente para ler registos do Pub/Sub.
Os registos de auditoria incluem todas as chamadas da API, declarações de consultas e estados das tarefas. Pode usar o Cloud Monitoring para monitorizar a atribuição de ranhuras, os bytes analisados em consultas e armazenados, e outras métricas do BigQuery. O plano de consulta e a cronologia do BigQuery podem ser usados para analisar as fases e o desempenho das consultas.
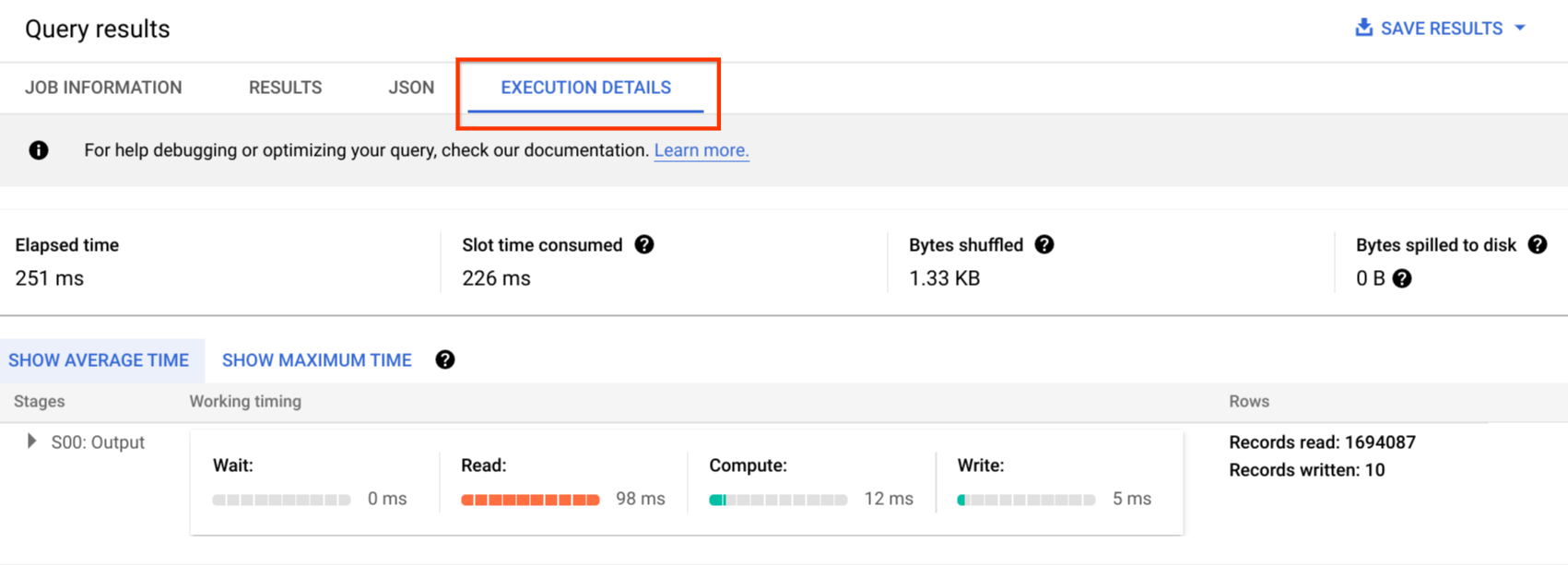
Pode usar a tabela de mensagens de erro para resolver problemas de tarefas de consulta e erros da API. Para distinguir as atribuições de espaços por consulta ou tarefa, pode usar esta utilidade, que é vantajosa para os clientes que usam preços baseados na capacidade e têm muitos projetos distribuídos por várias equipas.
Manutenção, atualizações e versões
O BigQuery é um serviço totalmente gerido e não requer que faça qualquer manutenção ou atualizações. O BigQuery não oferece versões diferentes. As atualizações são contínuas e não requerem tempo de inatividade nem prejudicam o desempenho do sistema. Para mais informações, consulte as Notas de lançamento.
O Oracle e o Exadata exigem que faça atualizações, melhorias e manutenção ao nível da base de dados e da infraestrutura subjacente. Existem muitas versões do Oracle e está previsto o lançamento de uma nova versão principal todos os anos. Embora as novas versões sejam compatíveis com versões anteriores, o desempenho das consultas, o contexto e as funcionalidades podem mudar.
Podem existir aplicações que requerem versões específicas, como 10g, 11g ou 12c. É necessário um planeamento e testes cuidadosos para atualizações importantes da base de dados. A migração de versões diferentes pode incluir diferentes necessidades técnicas de conversão em cláusulas de consulta e objetos de base de dados.
Cargas de trabalho
O Oracle Exadata suporta cargas de trabalho mistas, incluindo cargas de trabalho OLTP. O BigQuery foi concebido para a análise e não para processar cargas de trabalho OLTP. As cargas de trabalho OLTP que usam o mesmo Oracle devem ser migradas para o Cloud SQL, o Spanner ou o Firestore emGoogle Cloud. A Oracle oferece opções adicionais, como Advanced Analytics e Spatial and Graph. Pode ser necessário reescrever estas cargas de trabalho para a migração para o BigQuery. Para mais informações, consulte o artigo Migrar opções da Oracle.
Parâmetros e definições
A Oracle oferece e exige que muitos parâmetros sejam configurados e ajustados nos níveis do SO, base de dados, RAC, ASM e Listener para diferentes cargas de trabalho e aplicações. O BigQuery é um serviço totalmente gerido e não requer que configure parâmetros de inicialização.
Limites e quotas
A Oracle tem limites rígidos e flexíveis com base na infraestrutura, na capacidade de hardware, nos parâmetros, nas versões de software e no licenciamento. O BigQuery tem quotas e limites em ações e objetos específicos.
Aprovisionamento do BigQuery
O BigQuery é uma plataforma como serviço (PaaS) e um armazém de dados de processamento paralelo em grande escala na nuvem. A sua capacidade aumenta e diminui sem qualquer intervenção do utilizador, uma vez que a Google gere o back-end. Consequentemente, ao contrário de muitos sistemas RDBMS, o BigQuery não requer o aprovisionamento de recursos antes da utilização. O BigQuery atribui recursos de armazenamento e de consulta dinamicamente com base nos seus padrões de utilização. Os recursos de armazenamento são atribuídos à medida que os consome e anulados à medida que remove dados ou elimina tabelas. Os recursos de consulta são atribuídos de acordo com o tipo e a complexidade da consulta. Cada consulta usa espaços. É usado um agendador de equidade eventual, pelo que podem existir períodos curtos em que algumas consultas recebem uma quota mais elevada de vagas, mas o agendador acaba por corrigir esta situação.
Em termos de VMs tradicionais, o BigQuery oferece-lhe o equivalente a:
- Faturação por segundo
- Redimensionamento por segundo
Para realizar esta tarefa, o BigQuery faz o seguinte:
- Mantém vastos recursos implementados para evitar ter de dimensionar rapidamente.
- Usa recursos multi-inquilinos para alocar instantaneamente grandes blocos durante segundos de cada vez.
- Aloca recursos de forma eficiente entre utilizadores com economias de escala.
- Cobra apenas os trabalhos que executa, em vez dos recursos implementados, pelo que paga pelos recursos que usa.
Para mais informações acerca dos preços, consulte o artigo Compreender o escalamento rápido e os preços simples do BigQuery.
Migração de esquemas
Para migrar dados do Oracle para o BigQuery, tem de conhecer os tipos de dados do Oracle e as associações do BigQuery.
Tipos de dados da Oracle e mapeamentos do BigQuery
Os tipos de dados da Oracle diferem dos tipos de dados do BigQuery. Para mais informações sobre os tipos de dados do BigQuery, consulte a documentação oficial.
Para uma comparação detalhada entre os tipos de dados do Oracle e do BigQuery, consulte o guia de tradução de SQL do Oracle.
Índices
Em muitas cargas de trabalho analíticas, são usadas tabelas de colunas em vez de armazenamentos de linhas. Isto aumenta significativamente as operações baseadas em colunas e elimina a utilização de índices para a análise em lote. O BigQuery também armazena dados num formato de colunas, pelo que não são necessários índices no BigQuery. Se a carga de trabalho de análise exigir um conjunto único e pequeno de acesso baseado em linhas, o Bigtable pode ser uma alternativa melhor. Se uma carga de trabalho exigir o processamento de transações com consistências relacionais fortes, o Spanner ou o Cloud SQL podem ser alternativas melhores.
Em resumo, não são necessários nem oferecidos índices no BigQuery para a análise em lote. Pode usar a partição ou a agrupamento. Para mais informações sobre como otimizar e melhorar o desempenho das consultas no BigQuery, consulte o artigo Introdução à otimização do desempenho das consultas.
Visualizações
Tal como o Oracle, o BigQuery permite a criação de vistas personalizadas. No entanto, as vistas no BigQuery não suportam declarações DML.
Vistas materializadas
As vistas materializadas são usadas frequentemente para melhorar o tempo de renderização dos relatórios em tipos de relatórios e cargas de trabalho de escrita única e leitura múltipla.
As vistas materializadas são oferecidas no Oracle para aumentar o desempenho das vistas através da simples criação e manutenção de uma tabela para conter o conjunto de dados do resultado da consulta. Existem duas formas de atualizar as vistas materializadas no Oracle: no commit e a pedido.
A funcionalidade de visualização materializada também está disponível no BigQuery. O BigQuery tira partido dos resultados pré-calculados das vistas materializadas e, sempre que possível, lê apenas as alterações delta da tabela base para calcular resultados atualizados.
As funcionalidades de colocação em cache no Looker Studio ou noutras ferramentas de inteligência empresarial modernas também podem melhorar o desempenho e eliminar a necessidade de executar novamente a mesma consulta, o que permite poupar custos.
Particionamento de tabelas
A partição de tabelas é amplamente usada em armazéns de dados Oracle. Ao contrário do Oracle, o BigQuery não suporta a partição hierárquica.
O BigQuery implementa três tipos de particionamento de tabelas que permitem que as consultas especifiquem filtros de predicados com base na coluna de particionamento para reduzir a quantidade de dados analisados.
- Tabelas particionadas por tempo de ingestão: as tabelas são particionadas com base no tempo de ingestão dos dados.
- Tabelas particionadas por coluna:
as tabelas são particionadas com base numa coluna
TIMESTAMPouDATE. - Tabelas particionadas por intervalo de números inteiros: As tabelas são particionadas com base numa coluna de números inteiros.
Para mais informações sobre os limites e as quotas aplicados a tabelas particionadas no BigQuery, consulte o artigo Introdução às tabelas particionadas.
Se as restrições do BigQuery afetarem a funcionalidade da base de dados migrada, considere usar a divisão em vez da partição.
Além disso, o BigQuery não suporta EXCHANGE PARTITION,
SPLIT PARTITION nem a conversão de uma tabela não particionada numa particionada.
Clustering
A agrupagem ajuda a organizar e obter de forma eficiente os dados armazenados em várias colunas que são frequentemente acedidos em conjunto. No entanto, o Oracle e o BigQuery têm circunstâncias diferentes em que o agrupamento funciona melhor. No BigQuery, se uma tabela for frequentemente filtrada e agregada com colunas específicas, use a agrupamento. A clustering pode ser considerada para a migração de tabelas com partições de listas ou organizadas por índice do Oracle.
Tabelas temporárias
As tabelas temporárias são frequentemente usadas em pipelines de ETL da Oracle. Uma tabela temporária contém dados durante uma sessão do utilizador. Estes dados são eliminados automaticamente no final da sessão.
O BigQuery usa tabelas temporárias para colocar em cache os resultados de consultas que não são escritos numa tabela permanente. Após a conclusão de uma consulta, as tabelas temporárias existem durante um máximo de 24 horas. As tabelas são criadas num conjunto de dados especial e têm nomes aleatórios. Também pode criar tabelas temporárias para seu próprio uso. Para mais informações, consulte o artigo Tabelas temporárias.
Tabelas externas
Tal como o Oracle, o BigQuery permite-lhe consultar origens de dados externas. O BigQuery suporta a consulta de dados diretamente das origens de dados externas, incluindo:
- Amazon Simple Storage Service (Amazon S3)
- Armazenamento de blobs do Azure
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google Drive
Modelação de dados
Os modelos de dados em estrela ou floco de neve podem ser eficientes para o armazenamento de estatísticas e são usados frequentemente para armazéns de dados no Oracle Exadata.
As tabelas desnormalizadas eliminam operações de junção dispendiosas e, na maioria dos casos, oferecem um melhor desempenho para a análise no BigQuery. Os modelos de dados em estrela e floco de neve também são suportados pelo BigQuery. Para mais detalhes de design do armazém de dados no BigQuery, consulte o artigo Conceber o esquema.
Formato de linhas vs. formato de colunas e limites do servidor vs. sem servidor
O Oracle usa um formato de linhas em que a linha da tabela é armazenada em blocos de dados, pelo que as colunas desnecessárias são obtidas no bloco para as consultas analíticas, com base na filtragem e agregação de colunas específicas.
O Oracle tem uma arquitetura de partilha total, com dependências de recursos de hardware fixas, como memória e armazenamento, atribuídas ao servidor. Estas são as duas principais forças subjacentes a muitas técnicas de modelagem de dados que evoluíram para melhorar a eficiência do armazenamento e o desempenho das consultas analíticas. Os esquemas de estrela e floco de neve, bem como a modelagem de cofre de dados, são alguns exemplos.
O BigQuery usa um formato de colunas para armazenar dados e não tem limites de armazenamento e memória fixos. Esta arquitetura permite-lhe desnormalizar e criar esquemas com base nas leituras e nas necessidades empresariais, o que reduz a complexidade e melhora a flexibilidade, a escalabilidade e o desempenho.
Desnormalização
Um dos principais objetivos da normalização da base de dados relacional é reduzir a redundância de dados. Embora este modelo seja mais adequado para uma base de dados relacional que use um formato de linha, a desnormalização de dados é preferível para bases de dados de colunas. Para mais informações sobre as vantagens da desnormalização de dados e outras estratégias de otimização de consultas no BigQuery, consulte o artigo Desnormalização.
Técnicas para simplificar o seu esquema existente
A tecnologia do BigQuery tira partido de uma combinação de acesso e processamento de dados em colunas, armazenamento na memória e processamento distribuído para oferecer um desempenho de consultas de qualidade.
Ao criar um esquema de DWH do BigQuery, é melhor criar uma tabela de factos numa estrutura de tabela simples (consolidando todas as tabelas de dimensões num único registo na tabela de factos) para a utilização do armazenamento do que usar várias tabelas de dimensões do DWH. Além de uma menor utilização do armazenamento, ter uma tabela simples no BigQuery resulta numa menor utilização de JOIN. O diagrama seguinte
ilustra um exemplo de como simplificar o seu esquema.
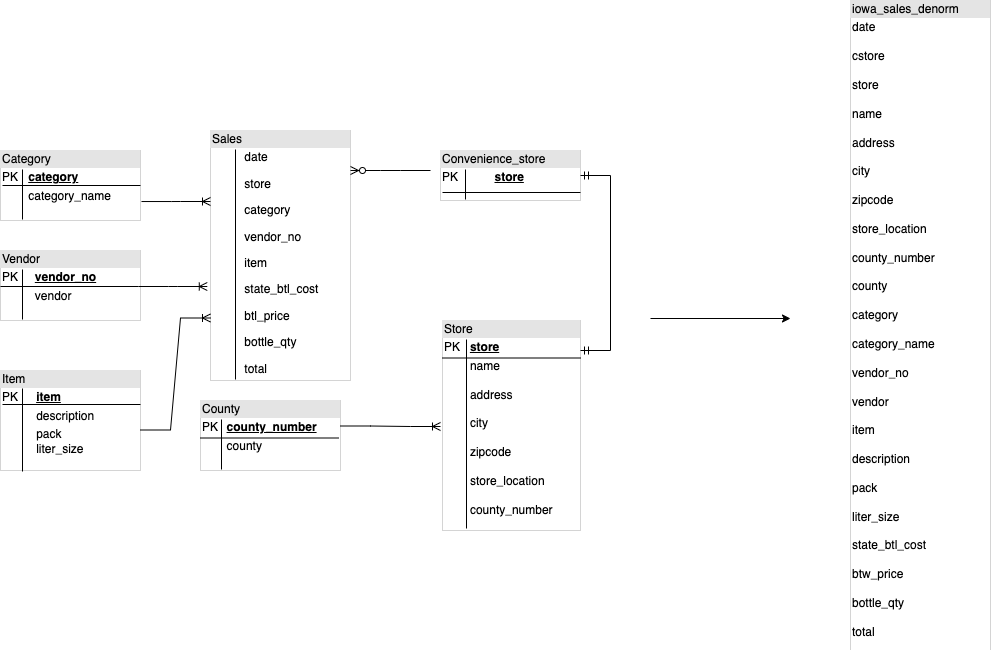
Exemplo de como simplificar um esquema em estrela
A Figura 1 mostra uma base de dados de gestão de vendas fictícia que inclui quatro tabelas:
- Tabela de encomendas/vendas (tabela de factos)
- Tabela de funcionários
- Tabela de localizações
- Tabela de clientes
A chave principal da tabela de vendas é OrderNum, que também contém chaves estrangeiras para as outras três tabelas.
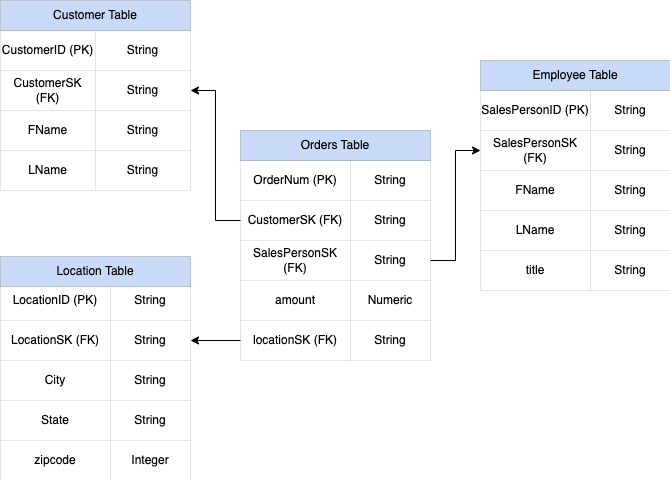
Figura 1: dados de vendas de amostra num esquema em estrela
Dados de exemplo
Conteúdo da tabela de factos/encomendas
| OrderNum | CustomerID | SalesPersonID | valor | Localização |
| O-1 | 1234 | 12 | 234,22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14,66 | 18 | |
| O-4 | 4567 | 4 | 182,00 | 26 |
Conteúdo de tabelas de funcionários
| SalesPersonID | FName | LName | título |
| 1 | Alex | Smith | Vendedor |
| 4 | Lisa | Pinto | Vendedor |
| 12 | João | Pinto | Vendedor |
Conteúdo da tabela de clientes
| CustomerID | FName | LName |
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
Conteúdo da tabela de localizações
| Localização | cidade | cidade | cidade |
| 18 | Bronx | NY | 10452 |
| 26 | Mountain View | CA | 90210 |
| 27 | Chicago | IL | 60613 |
Consulta para reduzir os dados usando LEFT OUTER JOIN
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
Resultado dos dados reduzidos
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | valor | Localização | cidade | estado | código postal |
| O-1 | 1234 | Amanda | Lee | 12 | João | Pinto | 234,22 | 18 | Bronx | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Smith | 192.10 | 27 | Chicago | IL | 60613 |
| O-3 | 12 | João | Pinto | 14,66 | 18 | Bronx | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Pinto | 182,00 | 26 | Montanha
Ver |
CA | 90210 |
Campos aninhados e repetidos
Para conceber e criar um esquema de DWH a partir de um esquema relacional (por exemplo, esquemas em estrela e floco de neve que contêm tabelas de dimensões e factos), o BigQuery apresenta a funcionalidade de campos aninhados e repetidos. Por conseguinte, as relações podem ser preservadas de forma semelhante a um esquema de DWH normalizado (ou parcialmente normalizado) relacional sem afetar o desempenho. Para mais informações, consulte as práticas recomendadas de desempenho.
Para compreender melhor a implementação de campos aninhados e repetidos, consulte um esquema relacional simples de uma tabela CUSTOMERS e uma tabela ORDER/SALES. São duas tabelas diferentes, uma para cada entidade, e as relações são definidas através de uma chave, como uma chave primária e uma chave externa, como a associação entre as tabelas durante a consulta com JOINs. Os campos aninhados e repetidos do BigQuery permitem-lhe preservar a mesma relação entre as entidades numa única tabela. Isto pode ser implementado se tiver todos os dados dos clientes, enquanto os dados das encomendas estão aninhados para cada um dos clientes. Para mais informações, consulte o artigo Especificar
colunas aninhadas e repetidas.
Para converter a estrutura simples num esquema aninhado ou repetido, aninhe os campos da seguinte forma:
CustomerID,FName,LNameaninhados num novo campo denominadoCustomer.SalesPersonID,FName,LNameaninhados num novo campo denominadoSalesperson.LocationID,city,stateezip codeaninhados num novo campo denominadoLocation.
Os campos OrderNum e amount não estão aninhados, uma vez que representam elementos únicos.
Quer tornar o seu esquema suficientemente flexível para permitir que cada encomenda tenha mais do que um cliente: um principal e um secundário. O campo customer está marcado como repetido. O esquema resultante é apresentado na Figura 2, que ilustra campos aninhados e repetidos.
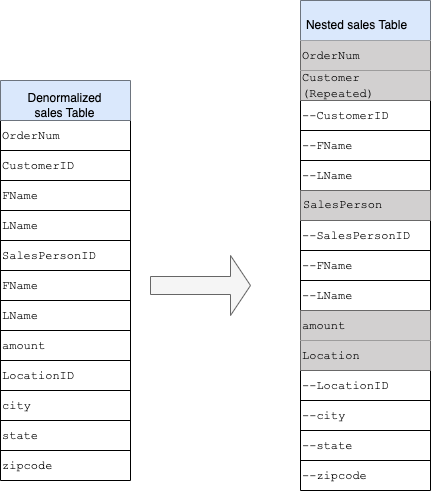
Figura 2: representação lógica de uma estrutura aninhada
Em alguns casos, a desnormalização com campos aninhados e repetidos não leva a melhorias no desempenho. Para mais informações sobre limitações e restrições, consulte o artigo Especifique colunas aninhadas e repetidas em esquemas de tabelas.
Chaves substitutas
É comum identificar linhas com chaves únicas nas tabelas. As sequências são
usadas frequentemente na Oracle para criar estas chaves. No BigQuery, pode criar chaves substitutas através das funções row_number e partition by. Para mais informações, consulte o artigo BigQuery e chaves substitutas: uma abordagem prática.
Acompanhar as alterações e o histórico
Ao planear uma migração do DWH do BigQuery, considere o conceito de dimensões de alteração lenta (SCD). Em geral, o termo SCD descreve o processo de fazer alterações (operações DML) nas tabelas de dimensões.
Por vários motivos, os armazéns de dados tradicionais usam diferentes tipos para processar alterações de dados e manter dados do histórico em dimensões que mudam lentamente. Estes tipos de utilização são necessários devido às limitações de hardware e aos requisitos de eficiência abordados anteriormente. Uma vez que o armazenamento é muito mais barato do que o processamento e é infinitamente escalável, a redundância e a duplicação de dados são incentivadas se resultarem em consultas mais rápidas no BigQuery. Pode usar técnicas de captura instantânea de dados em que todos os dados são carregados em novas partições diárias.
Vistas específicas da função e do utilizador
Use vistas específicas da função e do utilizador quando os utilizadores pertencerem a equipas diferentes e só deverem ver os registos e os resultados de que precisam.
O BigQuery suporta a column- e ao nível da linha. A segurança ao nível da coluna oferece acesso detalhado a colunas confidenciais através de etiquetas de políticas ou da classificação de dados baseada em tipos. Segurança ao nível da linha que lhe permite filtrar dados e ativar o acesso a linhas específicas numa tabela com base nas condições de utilizador qualificadas.
Migração de dados
Esta secção fornece informações sobre a migração de dados do Oracle para o BigQuery, incluindo o carregamento inicial, a captura de dados de alterações (CDC) e as ferramentas e abordagens de ETL/ELT.
Atividades de migração
Recomendamos que faça a migração em fases, identificando casos de utilização adequados para a migração. Existem várias ferramentas e serviços disponíveis para migrar dados do Oracle para o Google Cloud. Embora esta lista não seja exaustiva, dá uma ideia da dimensão e do âmbito do esforço de migração.
Exportar dados do Oracle: para mais informações, consulte os artigos Carregamento inicial e CDC e carregamento com streaming do Oracle para o BigQuery. Podem ser usadas ferramentas de ETL para o carregamento inicial.
Preparação de dados (no Cloud Storage): o Cloud Storage é o local de destino (área de preparação) recomendado para os dados exportados do Oracle. O Cloud Storage foi concebido para uma ingestão rápida e flexível de dados estruturados ou não estruturados.
Processo ETL: para mais informações, consulte o artigo Migração de ETL/ELT.
Carregar dados diretamente para o BigQuery: pode carregar dados para o BigQuery diretamente a partir do Cloud Storage, através do Dataflow ou através de streaming em tempo real. Use o Dataflow quando for necessária a transformação de dados.
Carregamento inicial
A migração dos dados iniciais do data warehouse da Oracle existente para o BigQuery pode ser diferente dos pipelines de ETL/ELT incrementais, consoante o tamanho dos dados e a largura de banda da rede. Os mesmos pipelines ETL/ELT podem ser usados se o tamanho dos dados for de alguns terabytes.
Se os dados tiverem até alguns terabytes, a descarga dos dados e a utilização do gcloud storage
para a transferência podem ser muito mais eficientes do que usar uma metodologia de extração de base de dados programática semelhante a JdbcIO, porque as abordagens programáticas podem precisar de uma otimização do desempenho muito mais detalhada. Se o tamanho dos dados for superior a alguns terabytes e
os dados estiverem armazenados no armazenamento na nuvem ou online (como o Amazon Simple Storage Service [Amazon S3]), considere
usar o Serviço de transferência de dados do BigQuery. Para transferências em grande escala (especialmente transferências com largura de banda de rede limitada), o Transfer
Appliance é uma opção útil.
Restrições para o carregamento inicial
Quando planear a migração de dados, considere o seguinte:
- Tamanho dos dados do DWH da Oracle: o tamanho da origem do seu esquema tem um peso significativo no método de transferência de dados escolhido, especialmente quando o tamanho dos dados é grande (terabytes e superior). Quando o tamanho dos dados é relativamente pequeno, o processo de transferência de dados pode ser concluído em menos passos. Lidar com tamanhos de dados em grande escala torna o processo geral mais complexo.
Tempo de inatividade: é importante decidir se o tempo de inatividade é uma opção para a sua migração para o BigQuery. Para reduzir o tempo de inatividade, pode carregar em massa os dados do histórico estáveis e ter uma solução de CDC para acompanhar as alterações que ocorrem durante o processo de transferência.
Preços: em alguns cenários, pode precisar de ferramentas de integração de terceiros (por exemplo, ferramentas de replicação ou ETL) que exijam licenças adicionais.
Transferência de dados inicial (em lote)
A transferência de dados através de um método de lote indica que os dados seriam exportados de forma consistente num único processo (por exemplo, exportar os dados do esquema do DWH da Oracle para ficheiros CSV, Avro ou Parquet, ou importar para o Cloud Storage para criar conjuntos de dados no BigQuery). Todas as ferramentas e os conceitos de ETL explicados na migração de ETL/ELT podem ser usados para o carregamento inicial.
Se não quiser usar uma ferramenta ETL/ELT para o carregamento inicial, pode escrever
scripts personalizados para exportar dados para ficheiros (CSV, Avro ou Parquet) e carregar esses
dados para o Cloud Storage através do gcloud storage, do Serviço de transferência de dados do BigQuery ou do
Transfer Appliance. Para mais informações sobre a otimização do desempenho de transferências de dados grandes e opções de transferência, consulte o artigo Transferir os seus conjuntos de dados grandes. Em seguida, carregue dados do
Cloud Storage para o BigQuery.
O Cloud Storage é ideal para processar a entrada inicial de dados. O Cloud Storage é um serviço de armazenamento de objetos altamente disponível e duradouro, sem limitações no número de ficheiros, e paga apenas pelo armazenamento que usa. O serviço está otimizado para funcionar com outros Google Cloud serviços, como o BigQuery e o Dataflow.
CDC e carregamento com streaming do Oracle para o BigQuery
Existem várias formas de captar os dados alterados do Oracle. Cada opção tem compromissos, principalmente no impacto no desempenho do sistema de origem, nos requisitos de desenvolvimento e configuração, e nos preços e licenciamento.
CDC baseada em registos
O Oracle GoldenGate é a ferramenta recomendada pela Oracle para extrair registos de repetição e pode usar o GoldenGate for Big Data para transmitir registos para o BigQuery. O GoldenGate requer licenciamento por CPU. Para informações sobre o preço, consulte a lista de preços global da tecnologia Oracle. Se o Oracle GoldenGate for Big Data estiver disponível (caso já tenham sido adquiridas licenças), a utilização do GoldenGate pode ser uma boa opção para criar pipelines de dados para transferir dados (carregamento inicial) e, em seguida, sincronizar todas as modificações de dados.
Oracle XStream
A Oracle armazena todas as confirmações em ficheiros de registo de repetição, e estes ficheiros de repetição podem ser usados para CDC. O Oracle XStream Out é criado com base no LogMiner e fornecido por ferramentas de terceiros, como o Debezium (a partir da versão 0.8) ou comercialmente através de ferramentas como o Striim. A utilização de APIs XStream requer a compra de uma licença para o Oracle GoldenGate, mesmo que o GoldenGate não esteja instalado nem seja usado. O XStream permite-lhe propagar mensagens de streams entre o Oracle e outro software de forma eficiente.
Oracle LogMiner
Não é necessária nenhuma licença especial para o LogMiner. Pode usar a opção LogMiner no conector da comunidade do Debezium. Também está disponível comercialmente através de ferramentas como a Attunity, a Striim ou a StreamSets. O LogMiner pode ter algum impacto no desempenho numa base de dados de origem muito ativa e deve ser usado cuidadosamente nos casos em que o volume de alterações (o tamanho da repetição) seja superior a 10 GB por hora, consoante a capacidade e a utilização da CPU, da memória e de E/S do servidor.
CDC baseada em SQL
Esta é a abordagem de ETL incremental em que as consultas SQL sondam continuamente as tabelas de origem para quaisquer alterações, consoante uma chave de aumento monotónico e uma coluna de data/hora que contém a data de modificação ou inserção mais recente. Se não existir uma chave de aumento
monotónico, a utilização da coluna de data/hora (data de modificação) com uma
pequena precisão (segundos) pode causar registos duplicados ou dados em falta, consoante
o volume e o operador de comparação, como > ou >=.
Para resolver estes problemas, pode usar uma maior precisão nas colunas de data/hora, como seis dígitos fracionários (microssegundos, que é a precisão máxima suportada no BigQuery) ou pode adicionar tarefas de remoção de duplicados no seu pipeline ETL/ELT, consoante as chaves empresariais e as caraterísticas dos dados.
Deve existir um índice na coluna de chave ou data/hora para um melhor desempenho de extração e um menor impacto na base de dados de origem. As operações de eliminação são um desafio para esta metodologia porque devem ser processadas na aplicação de origem de forma suave, como colocar um indicador de eliminação e atualizar last_modified_date. Uma solução alternativa pode ser registar estas operações noutra tabela através de um acionador.
Acionadores
Os acionadores da base de dados podem ser criados em tabelas de origem para registar alterações em tabelas de registo
secundárias. As tabelas de registo podem conter linhas inteiras para acompanhar todas as alterações
das colunas ou podem apenas manter a chave primária com o tipo de operação
(inserir, atualizar ou eliminar). Em seguida, os dados alterados podem ser capturados com uma abordagem baseada em SQL descrita em CDC baseada em SQL. A utilização de acionadores pode
afetar o desempenho das transações e duplicar a latência da operação DML de linha única
se for armazenada uma linha completa. O armazenamento apenas da chave principal pode reduzir esta sobrecarga, mas, nesse caso, é necessária uma operação JOIN com a tabela original na extração baseada em SQL, que não tem em conta a alteração intermédia.
Migração de ETL/ELT
Existem muitas possibilidades para processar ETL/ELT no Google Cloud. As orientações técnicas sobre conversões específicas de cargas de trabalho de ETL não estão no âmbito deste documento. Pode considerar uma abordagem de lift and shift ou reestruturar a sua plataforma de integração de dados, consoante as restrições, como o custo e o tempo. Para mais informações sobre como migrar os pipelines de dados para o Google Cloud Google Cloud e muitos outros conceitos de migração, consulte o artigo Migre pipelines de dados.
Abordagem de recortar e guardar
Se a sua plataforma existente suportar o BigQuery e quiser continuar a usar a sua ferramenta de integração de dados existente:
- Pode manter a plataforma ETL/ELT tal como está e alterar as fases de armazenamento necessárias com o BigQuery nas suas tarefas ETL/ELT.
- Se também quiser migrar a plataforma ETL/ELT, pode perguntar ao seu fornecedor se a respetiva ferramenta tem uma licença no Google Cloud. Se tiver, pode instalá-la no Compute Engine ou consultar o Google Cloud Marketplace. Google Cloud
Para informações sobre os fornecedores de soluções de integração de dados, consulte o artigo Parceiros do BigQuery.
Reestruturação da plataforma ETL/ELT
Se quiser reestruturar as suas pipelines de dados, recomendamos vivamente que considere usar os serviços do Google Cloud Google Cloud.
Cloud Data Fusion
O Cloud Data Fusion é uma oferta CDAP on Google Cloud gerida que oferece uma interface visual com muitos plug-ins para tarefas como arrastar e largar e desenvolvimentos de pipelines. O Cloud Data Fusion pode ser usado para capturar dados de muitos tipos diferentes de sistemas de origem e oferece capacidades de replicação em lote e em streaming. Os plug-ins do Cloud Data Fusion ou da Oracle podem ser usados para capturar dados de um Oracle. Pode usar um plug-in do BigQuery para carregar os dados para o BigQuery e processar as atualizações do esquema.
Não está definido nenhum esquema de saída nos plug-ins de origem e de destino, e select * from também é usado no plug-in de origem para replicar novas colunas.
Pode usar a funcionalidade Wrangle do Cloud Data Fusion para limpar e preparar dados.
Dataflow
O Dataflow é uma plataforma de processamento de dados sem servidor que pode ser dimensionada automaticamente, bem como processar dados em lote e por streaming. O Dataflow pode ser uma boa opção para os programadores de Python e Java que querem programar os respetivos pipelines de dados e usar o mesmo código para cargas de trabalho de streaming e em lote. Use o modelo JDBC para BigQuery para extrair dados das suas bases de dados relacionais Oracle ou outras e carregá-los no BigQuery.
Cloud Composer
O Cloud Composer é um Google Cloud serviço de orquestração de fluxos de trabalho totalmente gerido incorporado no Apache Airflow. Permite-lhe criar, agendar e monitorizar pipelines que abrangem ambientes na nuvem e centros de dados no local. O Cloud Composer oferece operadores e contribuições que podem executar tecnologias multicloud para exemplos de utilização, incluindo extração e carregamentos, transformações de ELT e chamadas de API REST.
O Cloud Composer usa gráficos acíclicos direcionados (DAGs) para agendar e organizar fluxos de trabalho. Para compreender os conceitos gerais do Airflow, consulte os conceitos do Apache Airflow. Para mais informações sobre os DAGs, consulte o artigo Escrever DAGs (fluxos de trabalho). Para ver exemplos de práticas recomendadas de ETL com o Apache Airflow, consulte o site de documentação de práticas recomendadas de ETL com o Airflow¶. Pode substituir o operador Hive no exemplo pelo operador BigQuery e os mesmos conceitos seriam aplicáveis.
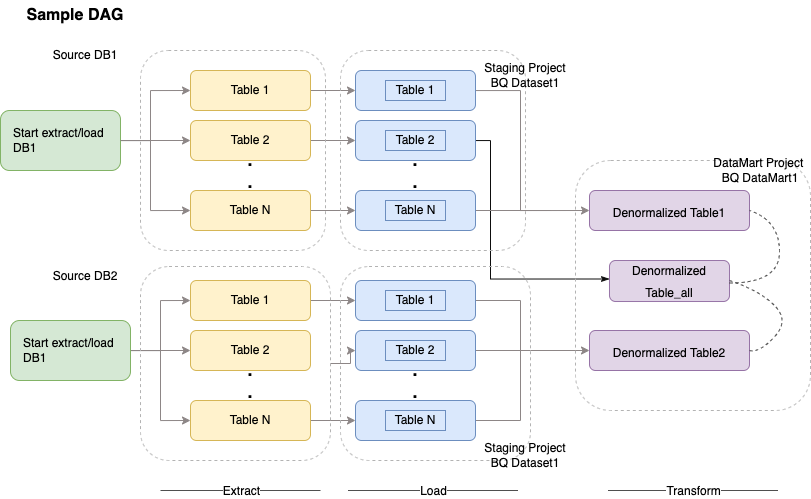
O seguinte exemplo de código é uma parte de alto nível de um exemplo de DAG para o diagrama anterior:
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
O código anterior é fornecido para fins de demonstração e não pode ser usado tal como está.
Dataprep by Trifacta
O Dataprep é um serviço de dados para explorar, limpar e preparar visualmente dados estruturados e não estruturados para análise, relatórios e aprendizagem automática. Exporta os dados de origem para ficheiros JSON ou CSV, transforma os dados através do Dataprep e carrega os dados através do Dataflow. Por exemplo, consulte o artigo Dados da Oracle (ETL) para o BigQuery através do Dataflow e do Dataprep.
Dataproc
O Dataproc é um serviço Hadoop gerido pela Google. Pode usar o Sqoop para exportar dados do Oracle e de muitas bases de dados relacionais para o Cloud Storage como ficheiros Avro e, em seguida, pode carregar ficheiros Avro para o BigQuery através da bq tool. É muito comum instalar ferramentas de ETL, como o CDAP, no Hadoop que usam o JDBC para extrair dados e o Apache Spark ou o MapReduce para transformações dos dados.
Ferramentas de parceiros para a migração de dados
Existem vários fornecedores no espaço de extração, transformação e carregamento (ETL). Os líderes de mercado de ETL, como a Informatica, a Talend, a Matillion, a Infoworks, a Stitch, a Fivetran e a Striim, integraram-se profundamente com o BigQuery e a Oracle, e podem ajudar a extrair, transformar e carregar dados, bem como gerir fluxos de trabalho de processamento.
As ferramentas de ETL existem há muitos anos. Algumas organizações podem considerar conveniente tirar partido de um investimento existente em scripts de ETL fidedignos. Algumas das nossas principais soluções de parceiros estão incluídas no Website de parceiros do BigQuery. Saber quando escolher ferramentas de parceiros em vez de utilitários incorporados depende da sua infraestrutura atual e da familiaridade da sua equipa de TI com o desenvolvimento de pipelines de dados em código Java ou Python.Google Cloud
Migração de ferramentas de Business Intelligence (BI)
O BigQuery suporta um conjunto flexível de soluções de Business Intelligence (BI) para relatórios e análises que pode tirar partido. Para mais informações sobre a migração de ferramentas de BI e a integração do BigQuery, consulte o artigo Vista geral da análise do BigQuery.
Tradução de consultas (SQL)
O GoogleSQL do BigQuery suporta a conformidade com a norma SQL 2011 e tem extensões que suportam consultar dados aninhados e repetidos. Todas as funções e os operadores SQL compatíveis com ANSI podem ser usados com modificações mínimas. Para uma comparação detalhada entre a sintaxe e as funções SQL do Oracle e do BigQuery, consulte a referência de tradução de SQL do Oracle para o BigQuery.
Use a tradução de SQL em lote para migrar o seu código SQL em massa ou a tradução de SQL interativa para traduzir consultas ad hoc.
Opções de migração da Oracle
Esta secção apresenta recomendações e referências de arquitetura para a conversão de aplicações que usam funcionalidades de Oracle Data Mining, R e Spatial and Graph.
Opção Oracle Advanced Analytics
A Oracle oferece opções de análise avançadas para a extração de dados, algoritmos fundamentais de aprendizagem automática (AA) e utilização de R. A opção Advanced Analytics requer licenciamento. Pode escolher a partir de uma lista abrangente de produtos de IA/ML da Google, dependendo das suas necessidades, desde o desenvolvimento à produção em grande escala.
Oracle R Enterprise
O Oracle R Enterprise (ORE), um componente da opção Oracle Advanced Analytics, permite que a linguagem de programação estatística R de código aberto se integre com a base de dados Oracle. Nas implementações de ORE padrão, o R é instalado num servidor Oracle.
Para escalas de dados ou abordagens de armazenamento muito grandes, a integração do R com o BigQuery é uma escolha ideal. Pode usar a biblioteca R de código aberto bigrquery para integrar o R com o BigQuery.
A Google estabeleceu uma parceria com a RStudio para disponibilizar aos utilizadores as ferramentas de ponta da área. O RStudio pode ser usado para aceder a terabytes de dados no BigQuery, ajustar modelos no TensorFlow e executar modelos de aprendizagem automática em grande escala com a AI Platform. No Google Cloud, o R pode ser instalado no Compute Engine em grande escala.
Oracle Data Mining
O Oracle Data Mining (ODM), um componente da opção Oracle Advanced Analytics, permite aos programadores criar modelos de aprendizagem automática através do Oracle PL/SQL Developer no Oracle.
O BigQuery ML permite que os programadores executem muitos tipos diferentes de modelos, como regressão linear, regressão logística binária, regressão logística de várias classes, agrupamento k-means e importações de modelos do TensorFlow. Para mais informações, consulte a Introdução ao BigQuery ML.
A conversão de tarefas ODM pode exigir a reescrita do código. Pode escolher entre as ofertas de produtos de IA da Google abrangentes, como o BigQuery ML, as APIs de IA (Speech-to-Text, Text-to-Speech, Dialogflow, Cloud Translation, Cloud Natural Language API, Cloud Vision, Timeseries Insights API e muito mais) ou o Vertex AI.
O Vertex AI Workbench pode ser usado como um ambiente de desenvolvimento para cientistas de dados e o Vertex AI Training pode ser usado para executar cargas de trabalho de preparação e classificação em grande escala.
Opção espacial e de gráfico
A Oracle oferece a opção Spatial and Graph para consultar geometria e gráficos e requer licenciamento para esta opção. Pode usar as funções de geometria no BigQuery sem custos nem licenças adicionais e usar outras bases de dados de grafos no Google Cloud.
Espacial
O BigQuery oferece funções e tipos de dados de estatísticas geoespaciais. Para mais informações, consulte o artigo Trabalhar com dados de estatísticas geoespaciais. Os tipos de dados espaciais e as funções do Oracle podem ser convertidos em funções de geografia no SQL padrão do BigQuery. As funções de geografia não adicionam custos aos preços padrão do BigQuery.
Gráfico
O JanusGraph é uma solução de base de dados de grafos de código aberto que pode usar o Bigtable como um back-end de armazenamento. Para mais informações, consulte o artigo Executar o JanusGraph no GKE com o Bigtable.
O Neo4j é outra solução de base de dados de grafos fornecida como um Google Cloud serviço que é executado no Google Kubernetes Engine (GKE).
Oracle Application Express
As aplicações Oracle Application Express (APEX) são exclusivas da Oracle e têm de ser reescritas. As funcionalidades de relatórios e visualização de dados podem ser desenvolvidas através do Looker Studio ou do motor de BI, enquanto as funcionalidades ao nível da aplicação, como a criação e a edição de linhas, podem ser desenvolvidas sem programação no AppSheet através do Cloud SQL.
O que se segue?
- Saiba como otimizar cargas de trabalho para a otimização do desempenho geral e a redução de custos.
- Saiba como otimizar o armazenamento no BigQuery.
- Para atualizações do BigQuery, consulte as notas de lançamento.
- Consulte o guia de tradução de SQL da Oracle.