En este documento, se presentan estrategias de recuperación ante desastres (DR) para Microsoft SQL Server orientadas a los arquitectos y los clientes potenciales técnicos que son responsables del diseño y la implementación de la recuperación ante desastres en Google Cloud.
Las bases de datos pueden dejar de estar disponibles por varios motivos, como fallas de hardware o de redes. Para proporcionar acceso continuo a una base de datos durante las fallas, se mantiene una base de datos secundaria, que es una réplica de la base de datos principal. Tener la base de datos secundaria en una ubicación diferente aumenta las posibilidades de que esté disponible cuando la base de datos principal deje de estarlo.
Si la base de datos principal deja de estar disponible, la aplicación de servicio crítico se conecta a una base de datos secundaria y continúa desde el estado de datos coherente más reciente para proporcionar servicios a los usuarios con un tiempo de inactividad mínimo o nulo.
El proceso de hacer que una base de datos secundaria esté disponible cuando falla la base de datos principal se llama recuperación ante desastres (DR) de base de datos. La base de datos secundaria se recupera de la falta de disponibilidad de la base de datos principal. Lo ideal es que la base de datos secundaria tenga el mismo estado coherente que la base de datos principal cuando no está disponible o pierde solo un conjunto mínimo de transacciones recientes de la base de datos principal.
La DR de bases de datos es una función esencial para los clientes empresariales. El factor principal es la continuidad empresarial de las aplicaciones de servicio crítico. Por ejemplo, una aplicación de servicio crítico genera ingresos (comercio electrónico), proporciona servicios continuos y confiables (administración de vuelos o centrales eléctricas) o admite funciones de conservación de la vida (supervisión de pacientes). En todos estos ejemplos, es de suma importancia que la aplicación esté disponible todo el tiempo, ya que se considera un servicio crítico.
La mayoría de los sistemas de administración de bases de datos proporcionan funciones de recuperación ante desastres, incluido Microsoft SQL Server. En este documento de arquitectura, se analiza cómo se implementan las funciones de DR de SQL Server en el contexto de Google Cloud.
Terminología
En las siguientes secciones, se explican los términos que se usan en este documento.
Arquitectura general de DR
En el siguiente diagrama, se ilustra la topología general de la arquitectura de DR.
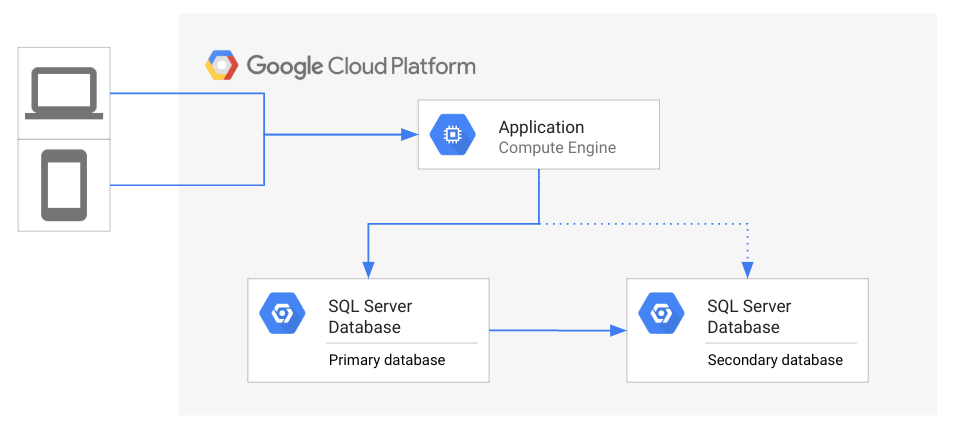
En el diagrama anterior, una aplicación accede a una base de datos principal mientras una base de datos secundaria está en espera y refleja el estado de la base de datos principal. Los clientes acceden a la app que se ejecuta en Google Cloud.
Si la base de datos principal deja de estar disponible, los administradores de bases de datos o los miembros del equipo de operaciones deben decidir iniciar el proceso de recuperación ante desastres. Si se inicia la recuperación ante desastres de la base de datos, la aplicación se vuelve a conectar a la base de datos secundaria. Una vez que se conecte, la aplicación podrá volver a ofrecer prestaciones a sus clientes. En una situación ideal, la aplicación estará disponible en la base de datos secundaria en cuanto sea posible para que los clientes no lleguen a experimentar una interrupción. Una alternativa es esperar a que se pueda volver a acceder a la base de datos principal, en lugar de iniciar la recuperación ante desastres. Por ejemplo, si el desastre es intermitente, es posible que sea más rápido solucionar el problema en lugar de llevar a cabo una conmutación por error.
Bases de datos principal y secundaria
Una o más aplicaciones acceden a una base de datos principal a fin de proporcionar servicios de persistencia para la administración del estado de la aplicación. Una base de datos secundaria está relacionada con una base de datos principal y contiene una réplica de ella. Lo ideal sería que el contenido de la base de datos secundaria tuviera una concordancia exacta con el contenido de la base de datos principal en todo momento. En muchos casos, la base de datos secundaria se retrasa con respecto a la base de datos principal debido a demoras en la aplicación de cambios transaccionales que se realizaron en la base de datos principal. Es posible asociar más de una base de datos secundaria con una principal, según la tecnología de base de datos. SQL Server admite la asociación de más de una base de datos secundaria con una base de datos principal.
Recuperación ante desastres
Si una base de datos principal deja de estar disponible, la DR cambia la función de la base de datos secundaria para que se convierta en la base de datos principal. Si hay más de una base de datos secundaria, una de esas bases de datos se selecciona de forma manual o según una lista de conmutación por error preferida. Las aplicaciones deben volver a conectarse a la nueva base de datos principal para seguir accediendo a su estado. Si la nueva base de datos principal no estaba sincronizada con el último estado conocido de la base de datos principal anterior, la aplicación comienza a funcionar a partir de un estado pasado (también conocido como flashback).
Es importante tener al menos una base de datos secundaria en todo momento para cada base de datos principal. Después de una recuperación ante desastres, asegúrate de configurar una nueva base de datos secundaria para controlar futuras situaciones de recuperación ante desastres.
Conmutación por error, cambio y reversión
Existen varias situaciones en las que se puede intercambiar la función entre una base de datos principal y una secundaria:
- Conmutación por error: es el proceso de cambiar la función de una base de datos secundaria para que se convierta en la base de datos principal nueva y conectar todas las aplicaciones a ella. La conmutación por error no es intencional porque se activa cuando una base de datos principal deja de estar disponible. Puedes configurar la conmutación por error para que se active de forma automática o manual.
- Cambio: a diferencia de la conmutación por error, un cambio de una base de datos principal a una base de datos secundaria (nueva base de datos principal) se activa de manera intencional para realizar pruebas iniciales y mantenimiento programado. Prueba el sistema de DR con un cambio periódico regular a fin de garantizar la dependencia continua de la recuperación ante desastres.
- Reversión: la reversión es el proceso en el que la nueva base de datos principal se convierte en la base de datos secundaria una vez que se reparó la base de datos principal. Una reversión se activa de forma intencional para restablecer el estado que existía antes de que se iniciara la conmutación por error o el cambio. No es estrictamente necesario realizarla, pero se puede hacer en función de los requisitos de recuperación ante desastres, como la localidad o los recursos disponibles.
Google Cloud zonas y regiones
Los recursos como las bases de datos se encuentran en las zonas y regiones, donde cada zona pertenece a una región.Google Cloud Una zona es un dominio de punto único de fallo. Recomendamos implementar un recurso con alta disponibilidad y tolerante a errores en varias zonas dentro de una región.
A fin de protegerte contra la interrupción de toda una región, establece estrategias multirregionales para la recuperación ante desastres. Por ejemplo, la base de datos principal se encuentra en una región, y su base de datos secundaria correspondiente, en otra región.
Modos activos: activo/pasivo y activo/activo
Una base de datos principal es una base de datos abierta para operaciones de lectura y escritura (operaciones DML) a fin de que las aplicaciones que acceden a ella puedan administrar su estado. La base de datos principal se denomina base de datos activa. La base de datos secundaria correspondiente es pasiva porque replica la base de datos principal, pero no está disponible en ninguna aplicación para operaciones de cambio de estado. Después de una conmutación por error o un cambio, la base de datos secundaria se convierte en la nueva base de datos principal y pasa a ser una base de datos activa.
La base de datos principal y la base de datos secundaria pueden ser bases de datos activas si la tecnología de base de datos es compatible con esta función, llamada modo activo-activo. En este caso, las aplicaciones se pueden conectar a cualquiera de ellas, ya que ambas están disponibles para la administración de estados. La recuperación ante desastres en el modo activo-activo no requiere una conmutación por error si solo una de las bases de datos activas deja de estar disponible. Si una base de datos activa no está disponible, la otra base de datos activa seguirá estándolo. El modo activo-activo está fuera del alcance de este artículo porque SQL Server no lo admite.
Modos de espera de las bases de datos: activa, semiactiva, pasiva y sin espera
Para que la base de datos principal sea la base de datos activa, debe estar en ejecución y poder ejecutar declaraciones DML. No es necesario que se ejecute la base de datos secundaria, por lo que se la puede cerrar. Si no está en ejecución, el tiempo que lleva recuperarse de un desastre aumenta porque la nueva base de datos principal debe ponerse en estado de ejecución antes de asumir la función de la nueva base de datos principal.
Existen distintas variaciones para configurar la base de datos secundaria:
- En espera activa: la base de datos secundaria está en funcionamiento y lista para que los clientes se conecten a ella. El último cambio disponible de la base de datos principal siempre se aplica en cuanto esté disponible.
- En espera semiactiva: una base de datos secundaria está activa, pero no todos los cambios de la base de datos principal se aplicaron.
- En espera pasiva: no se está ejecutando una base de datos secundaria. Primero, debe iniciarse y, luego, sincronizarse con el último estado disponible.
- Sin espera: el software de la base de datos primero debe instalarse y, luego, iniciarse antes de aplicar todos los cambios de la base de datos principal. Este modo es el menos costoso porque no consume recursos cuando no es necesario, pero en comparación con los otros modos, lleva más tiempo convertirlo en una nueva base de datos principal.
Estrategias de DR
En las siguientes secciones, se explican las estrategias de DR que admite Microsoft SQL Server.
Dimensiones de la estrategia de recuperación
Hay varias dimensiones clave que debes considerar cuando selecciones o implementes una estrategia de recuperación ante desastres en la base de datos. Cada dimensión tiene un amplio abanico, y el comportamiento y las expectativas de la estrategia de recuperación ante desastres dependen de los puntos que se seleccionen de este abanico. Estas son las dimensiones clave:
- Objetivo de punto de recuperación (RPO): es el período máximo aceptable en el que se pueden perder datos de la aplicación debido a un incidente importante. Esta dimensión varía según las formas en que se usan los datos. El RPO se puede expresar como la duración (segundos, minutos y horas) desde el momento en que la base de datos principal dejó de estar disponible o se puede expresar como estados de procesamiento identificables (la última copia de seguridad completa o la última copia de seguridad incremental). Sin importar cómo se especifique el RPO, la estrategia de recuperación ante desastres debe implementar la medida específica para que se pueda satisfacer el requisito de RPO. El caso más exigente es el de la última transacción confirmada, lo que significa que no debe ocurrir ninguna pérdida de la base de datos principal a la base de datos secundaria.
- Objetivo de tiempo de recuperación (RTO). El período máximo aceptable que la aplicación puede estar sin conexión. Por lo general, este valor se especifica como parte de un Acuerdo de Nivel de Servicio más amplio. El RTO suele expresarse en términos de la duración a partir de la falta de disponibilidad de la base de datos principal. Por ejemplo, la aplicación debe estar completamente operativa en 5 minutos. El caso más exigente es el de la inmediatez para que los usuarios de la aplicación no noten que se produjo la recuperación ante desastres.
- Dominio de punto único de fallo. Depende de ti decidir si una región se considera un dominio de punto único de fallo para los requisitos de la recuperación ante desastres. Si una región es un dominio de punto único de fallo para ti, debes configurar la recuperación ante desastres a fin de que dos o más regiones participen en la configuración real. Si la región que contiene la base de datos principal falla, la base de datos secundaria en otra región se convierte en la base de datos principal nueva. Si se supone que el dominio de un punto único de fallo es una zona, la recuperación ante desastres se puede configurar en todas las zonas de una misma región. Si una zona falla, la recuperación ante desastres usa una segunda zona y pone a disposición la nueva base de datos principal en ella.
Cuando tomas decisiones con respecto a estas dimensiones clave, decides entre el costo y la calidad. Cuanto más bajo sean el RTO y el RPO, más costosa será la solución de recuperación ante desastres, debido a que se usarán más recursos activos. En las siguientes secciones, se analizan varias estrategias de DR alternativas que representan puntos en las dimensiones en el contexto de la base de datos de Microsoft SQL Server.
Estrategias de DR para SQL Server
En el artículo Continuidad empresarial y recuperación de bases de datos - SQL Server, se describen las funciones de disponibilidad que puedes usar para implementar estrategias de recuperación ante desastres.
Aspectos preliminares
SQL Server se ejecuta en Windows y Linux. Sin embargo, no todas las funciones de disponibilidad están disponibles en Linux. SQL Server tiene varias ediciones, pero no todas las funciones de disponibilidad están disponibles en todas ellas.
SQL Server distingue las instancias de las bases de datos. Una instancia es el software de SQL Server en ejecución, mientras que una base de datos es el conjunto de datos que administra una instancia de SQL Server.
Grupos de disponibilidad siempre activados
Los grupos de disponibilidad siempre activados proporcionan protección a nivel de la base de datos. Un grupo de disponibilidad tiene dos o más réplicas. Una réplica es la réplica principal con acceso de lectura y escritura, y las réplicas restantes son réplicas secundarias que pueden proporcionar acceso de lectura. Una instancia de SQL Server independiente administra cada réplica de la base de datos. Un grupo de disponibilidad puede contener una o más bases de datos. La cantidad de bases de datos que se pueden incluir en un grupo de disponibilidad y la cantidad de réplicas secundarias admitidas dependen de la edición de SQL Server. Todas las bases de datos en un grupo de disponibilidad experimentan los mismos cambios de ciclo de vida al mismo tiempo. Los grupos de disponibilidad implementan el modo activo/pasivo porque solo la base de datos principal admite el acceso de escritura.
Cuando ocurre una conmutación por error, una réplica secundaria se convierte en la nueva réplica principal. Debido a que un grupo de disponibilidad incluye instancias de SQL Server independientes, todas las operaciones capturadas en los registros de transacciones están disponibles en las réplicas. Los cambios que no hayan sido capturados en un registro de transacciones, como los inicios de sesión de SQL Server o los trabajos del agente de SQL Server, deben sincronizarse de forma manual. Si deseas proporcionar protección a nivel de la base de datos y para las instancias de SQL Server, debes configurar las instancias de clústeres de conmutación por error (FCI). Esta arquitectura de implementación se analiza más adelante en la sección Instancia de clústeres de conmutación por error siempre activada.
Puedes proteger las apps contra los cambios de funciones si usas un objeto de escucha. Un objeto de escucha es compatible con aplicaciones que se conectan al grupo de disponibilidad. Las aplicaciones no están al tanto de qué instancias de SQL Server administran la base de datos principal o las réplicas secundarias en ningún momento. Los objetos de escucha requieren que los clientes usen, como mínimo, la versión 3.5 de .NET con una actualización, o bien la versión 4.0 o versiones posteriores, como se describe en Continuidad empresarial y recuperación de bases de datos - SQL Server.
Los grupos de disponibilidad se basan en capas subyacentes de abstracción para proporcionar su funcionalidad. Los grupos de disponibilidad se ejecutan en un clúster de conmutación por error de Windows Server (WSFC), como se describe en Clústeres de conmutación por error de Windows Server con SQL Server. Todos los nodos que ejecutan instancias de SQL Server deben ser parte del mismo WSFC.
Las transacciones se envían desde la base de datos principal a todas las réplicas secundarias. Existen dos modos de envío de transacciones: síncrono y asíncrono. Puedes configurar cada réplica de forma independiente para que use uno de los dos modos. En el modo de envío síncrono, la transacción en la base de datos principal solo se completa si se realiza de forma adecuada en todas las réplicas secundarias que se vinculan de forma síncrona. En el modo asíncrono, la transacción en la base de datos principal puede completarse, aunque no se la haya aplicado en todas las réplicas secundarias.
El modo de envío que elijas influirá en los posibles RTO, RPO y el modo de espera. Por ejemplo, si las transacciones se envían a todas las réplicas en modo síncrono, todas las réplicas se estarán exactamente en el mismo estado. El RPO más exigente (la transacción más reciente) se completa, ya que todas las réplicas están completamente sincronizadas. Las réplicas secundarias se encuentran en espera activa para que cualquiera de ellas se pueda usar de inmediato como base de datos principal,
La conmutación por error puede ser automática o manual. Es posible realizar una conmutación por error automática si todas las réplicas están sincronizadas por completo. En el ejemplo anterior, esto es posible, ya que todas las réplicas siempre están sincronizadas por completo.
En el siguiente gráfico, se muestra un grupo de disponibilidad siempre activado en una sola región.
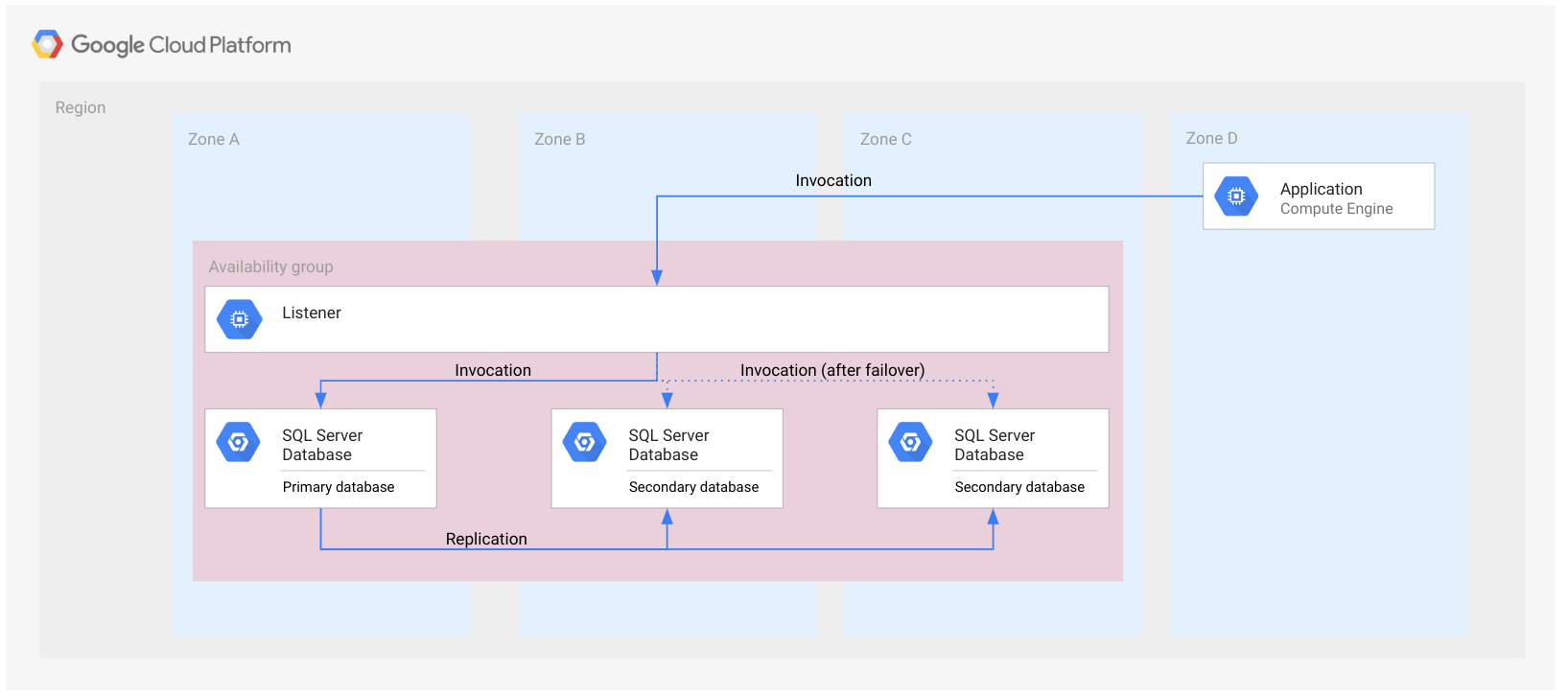
El grupo de disponibilidad se representa como un rectángulo que abarca zonas. Este gráfico solo tiene una finalidad ilustrativa, y en él se indica que todas las bases de datos pertenecen al mismo grupo de disponibilidad. El grupo de disponibilidad no es un recurso de la nube y, por lo tanto, no se implementa en un nodo ni en otro tipo de recurso.
Instancia de clústeres de conmutación por error siempre activada
Para protegerte contra las fallas de nodos, puedes usar instancias de clústeres de conmutación por error (FCI) en lugar de instancias de SQL Server independientes. Hay dos o más nodos que ejecutan instancias de SQL Server para administrar una base de datos (primaria o secundaria). Los nodos que administran una base de datos forman un clúster de conmutación por error. Un nodo del clúster ejecuta de forma activa una instancia de SQL Server, mientras que los demás no ejecutan instancias de SQL Server. Cuando el nodo que ejecuta la instancia de SQL Server falla, otro nodo del clúster inicia una instancia de SQL Server y se hace cargo de la administración de la base de datos (conmutación por error de nodo). Este proceso de inicio automático de una instancia de SQL Server proporciona una funcionalidad de alta disponibilidad.
El clúster de FCI se muestra como una sola unidad, y los clientes que acceden a él no ven la conmutación por error entre nodos, excepto, en ocasiones, durante un período corto de falta de disponibilidad. No hay pérdida de datos cuando se produce una conmutación por error de nodo. Todo lo que se ejecuta dentro de la instancia de SQL Server que generó el error se mueve a otra instancia de SQL Server en el mismo clúster. Por ejemplo, los servicios vinculados o los trabajos del agente de SQL Server se mueven a otra instancia.
Los nodos del clúster de FCI se pueden configurar en diferentes Google Cloud zonas. Esta arquitectura proporciona alta disponibilidad en caso de fallas de nodos y también en fallas de zonas. En la sección sobre las alternativas de implementación de la DR, se analiza un ejemplo de la implementación de esta estrategia.
Aunque diferentes nodos administran la misma base de datos y la comparten, no se requiere almacenamiento común entre los nodos de un clúster de FCI. SQL Server usa la función de espacios de almacenamiento directo (S2D) para administrar bases de datos en discos de nodo dedicados. Para obtener más información, consulta Configura instancias de clústeres de conmutación por error de SQL Server.
En el siguiente figura, se muestra el ejemplo de la sección anterior Grupos de disponibilidad siempre activados con FCI en lugar de instancias independientes de SQL Server. Cada FCI tiene una instancia activa de SQL Server que administra la base de datos.
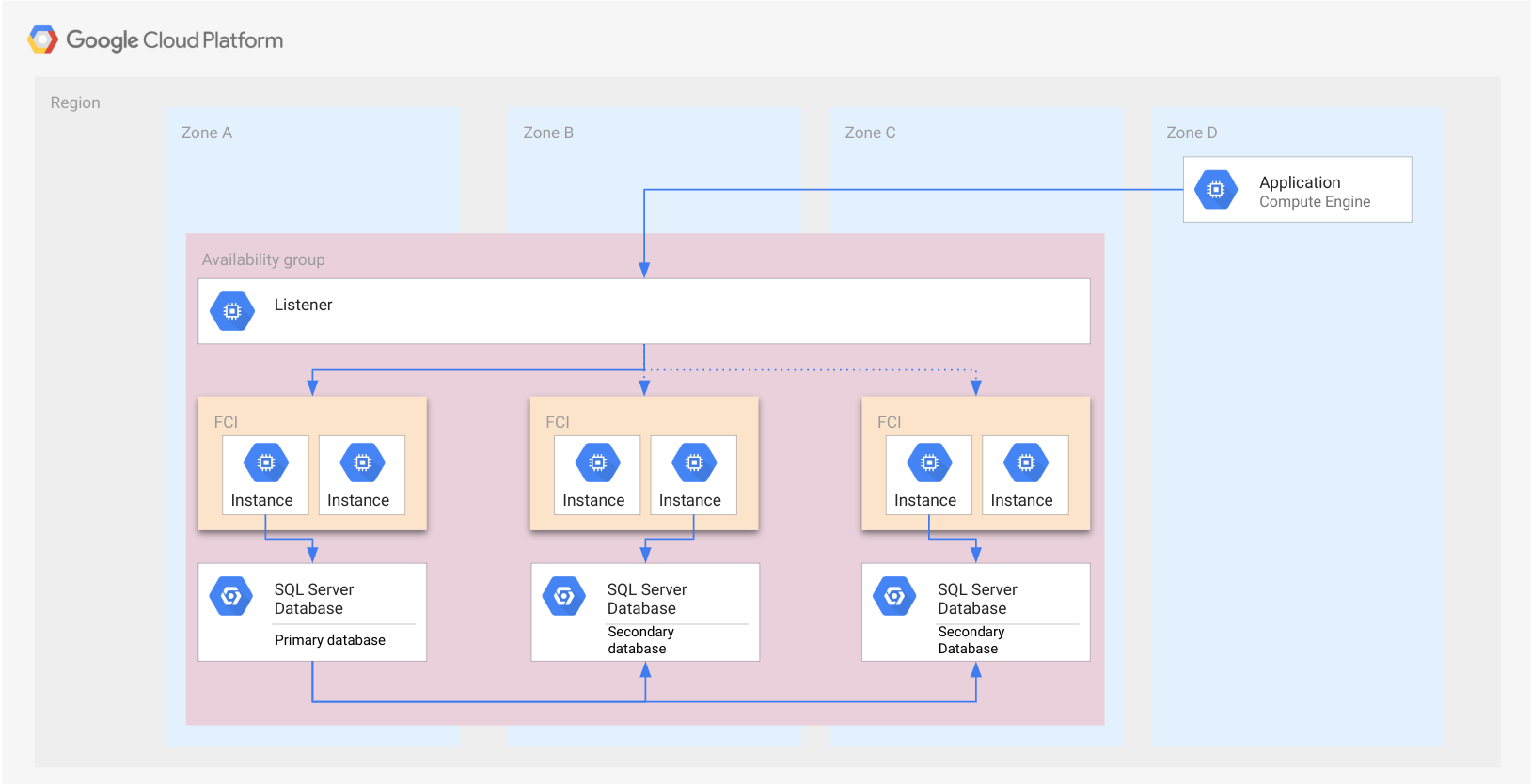
Como en el caso del grupo de disponibilidad, una FCI se representa como un rectángulo. Esto es solo con fines ilustrativos para indicar que todos los nodos pertenecen a la misma FCI. Una FCI no es un recurso de la nube y, por lo tanto, no se implementa en un nodo ni en otro tipo de recurso.
Para acceder a un análisis más detallado, consulta Instancias de clústeres de conmutación por error de siempre activada (SQL Server).
Grupos de disponibilidad distribuidos
Los grupos de disponibilidad distribuidos son un tipo especial de grupo de disponibilidad. Un grupo de disponibilidad distribuido abarca dos grupos de disponibilidad: uno tiene la función de grupo de disponibilidad principal y el otro tiene la función de grupo de disponibilidad secundario. Los grupos de disponibilidad distribuidos pueden reenviar transacciones en modo síncrono y asíncrono desde el grupo de disponibilidad principal hacia el grupo de disponibilidad secundario.
Aunque cada uno de los grupos de disponibilidad tiene su propia base de datos principal, esta no es una implementación de modo activo/activo. Solo la base de datos principal del grupo de disponibilidad principal puede recibir operaciones de escritura. La base de datos principal del grupo de disponibilidad secundario se denomina agente de reenvío. El agente de reenvío recibe las transacciones del grupo de disponibilidad principal y las reenvía a las bases de datos secundarias del grupo de disponibilidad secundario. Una conmutación por error desde el grupo de disponibilidad principal hasta el grupo de disponibilidad secundario haría que la base de datos principal del nuevo grupo de disponibilidad principal fuera accesible para las operaciones de escritura.
Los grupos de disponibilidad principal y secundario no tienen que estar en la misma ubicación ni en el mismo sistema operativo. Sin embargo, cada grupo de disponibilidad debe tener un objeto de escucha instalado. El grupo de disponibilidad distribuido no tiene un objeto de escucha. Los grupos de disponibilidad distribuidos no requieren que los dos grupos de disponibilidad estén en el mismo WSFC. Todas las funciones necesarias para que los grupos de disponibilidad distribuidos funcionen se incluyen en las funciones de SQL Server y no requieren la instalación adicional de los componentes subyacentes.
Un grupo de disponibilidad distribuido abarca exactamente dos grupos de disponibilidad. Un grupo de disponibilidad puede ser parte de dos grupos de disponibilidad distribuidos. Esta posibilidad es compatible con diferentes topologías. Una de ellas es la topología de encadenamiento desde un grupo de disponibilidad hasta otro grupo de disponibilidad en varias ubicaciones. La otra topología es una topología en forma de árbol en la que el grupo de disponibilidad principal forma parte de dos grupos de disponibilidad distribuidos que son independientes y distintos.
Los grupos de disponibilidad distribuidos son el medio principal para implementar la recuperación ante desastres en todos los sistemas operativos. Por ejemplo, el grupo de disponibilidad principal se puede configurar en Windows, y el grupo de disponibilidad secundario correspondiente, en Linux. Ambos grupos de disponibilidad forman un grupo de disponibilidad distribuido.
En el siguiente diagrama, se muestran dos grupos de disponibilidad que forman parte de un grupo de disponibilidad distribuido.
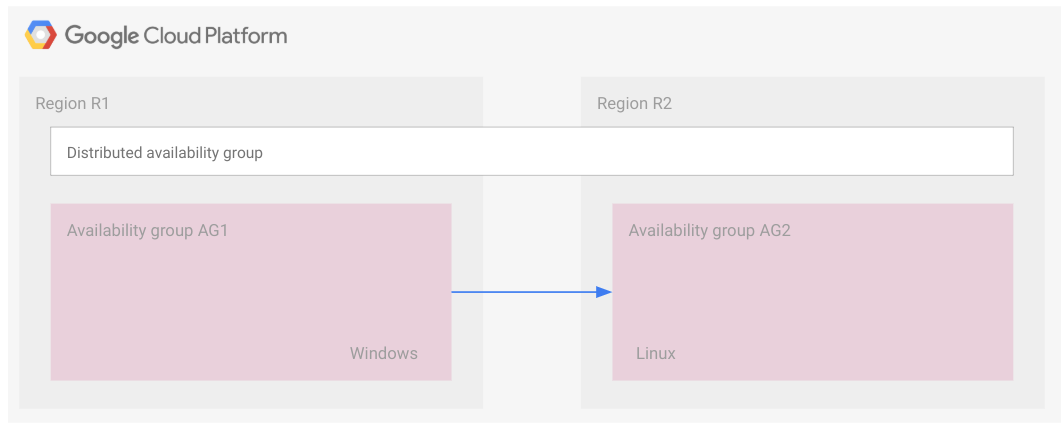
El grupo de disponibilidad 1 es el grupo de disponibilidad principal, y el grupo de disponibilidad 2 es el secundario.
Al igual que en el caso de las FCI, un grupo de disponibilidad distribuido se representa como un rectángulo. Este diagrama solo tiene fines ilustrativos, y en él se indica que todos los grupos de disponibilidad pertenecen al mismo grupo de disponibilidad distribuido. Un grupo de disponibilidad distribuido, como un grupo de disponibilidad, no es un recurso de la nube y, por lo tanto, no se implementa en un nodo ni en ningún otro tipo de recurso.
Para obtener más información, consulta Grupos de disponibilidad distribuidos.
Envío de registros
El envío de registros de transacciones es una función de disponibilidad de SQL Server disponible cuando el RTO y el RPO no son tan estrictos (RTO bajo o RPO reciente), porque la discrepancia entre el estado de una base de datos principal y el de su base de datos secundaria es mucho mayor. La discrepancia es mayor en términos de estado porque un archivo de registro de transacciones contiene muchos cambios de estado. La discrepancia también es mayor en términos de tiempo de retraso, ya que los archivos de registro de transacciones se transportan de forma asíncrona y deben aplicarse en su totalidad a una base de datos secundaria.
La base de datos principal crea los archivos de registro de transacciones, y se realiza una copia de seguridad de ellos, por ejemplo, en Cloud Storage. Todos los archivos de registro de transacciones se copian en cada base de datos secundaria, en donde se aplican. Debido a que la base de datos secundaria se retrasa con respecto a la base de datos principal, están en modo de espera semiactiva. Los objetos y cambios que los transacciones no capturan se deben aplicar de forma manual a las bases de datos secundarias para establecer una sincronización completa sin pérdidas.
El agente de SQL Server automatiza el proceso general de creación, copia y aplicación de registros de transacciones. El envío de registros debe configurarse para cada base de datos de forma individual. Si un grupo de disponibilidad administra más de una base de datos, se deben configurar tantos procesos de envío de registros como sean necesarios.
En caso de que se genere una falla, el proceso de recuperación ante desastres debe iniciarse de forma manual, ya que no hay asistencia automatizada. Además, un objeto de escucha no abstrae el acceso del cliente de las bases de datos principal y secundaria. En caso de que se lleve a cabo una conmutación por error, los clientes tienen que poder abordar por cuenta propia el cambio de función de una base de datos, de la función secundaria a la función principal nueva, de modo que se conecten a la nueva función principal después de una recuperación ante desastres. Es posible compilar abstracciones independientes de las instancias de SQL Server, por ejemplo, direcciones IP flotantes como se describe en Prácticas recomendadas para direcciones IP flotantes.
Debido a que el envío de registros es, en parte, un proceso manual, puedes retrasar la aplicación de los archivos de registro copiados en las bases de datos secundarias de forma intencional (a diferencia de lo que sucede en los grupos de disponibilidad distribuidos, en los que se aplican los cambios de inmediato). Un posible caso práctico consiste en impedir que los errores de modificación de datos en la base de datos principal se apliquen a las bases de datos secundarias hasta que se los solucione. En este caso, una base de datos secundaria que aún no tiene un error de modificación de datos puede convertirse en la base de datos principal hasta que se corrija dicho error. Luego, se puede reanudar el procesamiento normal.
Como sucede en el caso de los grupos de disponibilidad distribuidos, puedes usar el envío de registros para soluciones multiplataforma en las que, por ejemplo, la base de datos principal se ejecuta en Linux, mientras que las bases de datos secundarias están en Linux y Windows.
En el siguiente diagrama, se ilustra una implementación multiplataforma con envío de registros. Ten en cuenta que, en esta topología, no existe una configuración común entre regiones, como un grupo de disponibilidad distribuido.
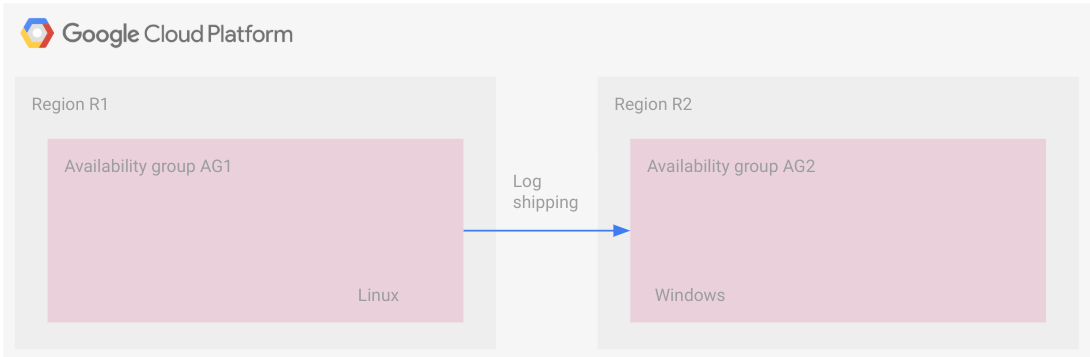
Los grupos de disponibilidad se encuentran en regiones diferentes: uno se ejecuta en Linux, y el otro, en Windows.
Para obtener más información sobre el envío de registros de SQL Server, consulta Acerca del envío de registros (SQL Server).
Combina funciones de disponibilidad de SQL Server
Puedes implementar funciones de disponibilidad de SQL Server en diferentes combinaciones. Por ejemplo, en el caso práctico anterior, el envío de registros se usó con diferentes grupos de disponibilidad instalados en diferentes sistemas operativos.
La siguiente es una lista de las formas en las que puedes combinar las funciones de disponibilidad de SQL Server:
- Usa el envío de registros entre los grupos de disponibilidad instalados en el mismo sistema operativo.
- Ten un grupo de disponibilidad principal mediante el uso de FCI con un grupo de disponibilidad secundario que use solo instancias independientes de SQL Server.
- Usa un grupo de disponibilidad distribuido entre regiones cercanas y el envío de registros entre regiones ubicadas en diferentes continentes.
Estas son solo algunas de las posibles combinaciones de funciones de disponibilidad de SQL Server.
La flexibilidad que ofrecen las funciones de disponibilidad de SQL Server permite ajustar una estrategia de recuperación ante desastres de acuerdo con los requisitos establecidos.
Replicación de SQL Server
Por lo general, la replicación de SQL Server no se considera una función de disponibilidad, pero en esta sección se describe de forma breve cómo se la puede usar en la recuperación ante desastres.
La función de replicación permite crear y mantener réplicas de bases de datos. Los diferentes tipos de agentes de SQL Server colaboran para capturar los cambios, transmitir esos cambios capturados y aplicarlos a las réplicas. Este proceso es asíncrono, y las réplicas suelen retrasarse en diferente medida con respecto a la base de datos que se replica.
Por ejemplo, es posible tener una réplica de una base de datos de producción. En términos de la recuperación ante desastres, la base de datos de producción es la base de datos principal, y la réplica es la base de datos secundaria. La función de replicación de SQL Server no está al tanto de que las bases de datos suponen diferentes funciones en el contexto de la recuperación ante desastres. Por lo tanto, la replicación no tiene operaciones que admitan el proceso de recuperación ante desastres, como cambios de función. El proceso de recuperación ante desastres debe implementarse por separado de las funciones de SQL Server, y la organización debe ejecutarlo porque no hay abstracciones de acceso de cliente.
Envío de archivos de copia de seguridad
El envío de archivos de copia de seguridad es otra estrategia de implementación de la recuperación ante desastres. Un enfoque estándar para configurar y actualizar de forma continua una base de datos secundaria consiste en realizar una copia de seguridad completa inicial de la base de datos principal y, luego, realizar copias de seguridad incrementales de ella. Todas las copias de seguridad incrementales se aplican a las bases de datos secundarias en el orden correcto. Existen muchas variaciones en este enfoque, según la frecuencia de las copias de seguridad incrementales y la ubicación de almacenamiento de los archivos de las copias de seguridad (ubicación global o copia entre ubicaciones).
Esta estrategia no implica ninguna función de disponibilidad de SQL Server cuando se replican cambios de estado de la base de datos principal en cualquier base de datos secundaria. No usa el agente de SQL Server que se usa en el caso del envío de registros.
Para obtener más información, consulta la sección Ejemplo: estrategia de DR de copia de seguridad y restablecimiento.
En comparación con el enfoque de la replicación que se analizó en la sección anterior, el envío de archivos de copia de seguridad y la replicación tienen en común que el proceso de recuperación ante desastres se implementa fuera del conjunto de atributos de SQL Server. Desde la perspectiva del envío de cambios capturados, la replicación de SQL Server es más conveniente, ya que implementa esta parte de forma automática mediante los agentes de SQL Server.
Nota sobre la interacción entre el ciclo de vida de la base de datos y el ciclo de vida de la aplicación
Una conmutación por error de una base de datos no es del todo independiente de las aplicaciones que acceden a la base de datos. En principio, hay dos situaciones de falla.
Primero, la aplicación permanece operativa mientras la base de datos está en el proceso de conmutación por error. Desde el momento en que la base de datos principal deja de estar disponible hasta que la nueva base de datos principal está en funcionamiento, las aplicaciones no pueden acceder a la base de datos. Las conexiones existentes fallan y no se establecen conexiones nuevas. Durante este tiempo, la aplicación no puede brindar prestaciones a sus clientes, al menos en los casos en los que las funciones requieren acceso a la base de datos. Las aplicaciones deben reconocer cuándo la nueva base de datos principal está disponible, de modo que puedan reanudar el procesamiento normal.
Es posible que las aplicaciones tengan un estado fuera de la base de datos, por ejemplo, en cachés de memoria principal. La aplicación se asegura de que la caché sea coherente (se sincronice) con la nueva base de datos principal. Si no hubo ninguna pérdida de transacciones durante la conmutación por error, es posible que la caché sea coherente sin que se necesite realizar mantenimiento adicional. Sin embargo, si se produjo una pérdida de transacción (datos) durante la conmutación por error, es posible que la caché no sea coherente en relación con la nueva base de datos principal. Un análisis equivalente se aplica al estado compartido cuando, por ejemplo, algunos de los datos de la base de datos también forman parte de los mensajes en las colas o de los archivos en el sistema de archivos. Este aspecto de la coherencia de los datos no se trata en este documento porque no está directamente relacionado con la recuperación ante desastres de base de datos.
En segundo lugar, es posible que una o más aplicaciones dejen de estar disponibles en el mismo momento en que la base de datos principal también deja de estarlo. Por ejemplo, si una región se desconecta, un sistema de aplicación que se ejecuta en esa región no estará disponible, al igual que la base de datos principal de esa región. En este caso, la aplicación también debe recuperarse, no solo el sistema de la base de datos principal. Junto con el proceso de recuperación ante desastres de la base de datos, debes iniciar un proceso de recuperación de la aplicación similar. La aplicación recuperada debe conectarse a la nueva base de datos principal y volver a configurarse (por ejemplo, con direcciones IP flotantes). La recuperación de aplicaciones no se trata en este documento.
Relación entre la copia de seguridad y el restablecimiento, y la recuperación ante desastres
Crear una copia de seguridad de una base de datos es independiente y ortogonal a la recuperación ante desastres de la base de datos. El propósito de la copia de seguridad de la base de datos es poder restablecer un estado coherente, por ejemplo, en caso de que una base de datos se pierda o se dañe, o si se debe recuperar un estado anterior debido a fallas o errores de la aplicación.
En la siguiente sección, se analiza cómo usar las copias de seguridad como un posible mecanismo para implementar la recuperación ante desastres de base de datos. En esta situación, debes copiar los archivos de copia de seguridad en la ubicación de la base de datos secundaria para que esta se pueda restablecer. Sin embargo, los archivos de copia de seguridad no son un requisito para la recuperación ante desastres. En el análisis anterior de las funciones de disponibilidad, se presentaron alternativas.
Alta disponibilidad y recuperación ante desastres
La alta disponibilidad y la recuperación ante desastres tienen en común que proporcionan soluciones para la falta de disponibilidad de una base de datos. Si una base de datos principal deja de estar disponible, una base de datos secundaria se convierte en la nueva base de datos principal con coherencia y disponibilidad.
La diferencia entre la alta disponibilidad y la recuperación ante desastres es el dominio de punto único de fallo. La alta disponibilidad aborda una interrupción dentro de una región, por ejemplo, cuando falla una sola zona o un nodo. Una solución de alta disponibilidad proporciona una nueva base de datos principal en otra zona de la misma región. Además, la alta disponibilidad aborda las fallas de nodos, no solo las fallas de una base de datos. Si un nodo que ejecuta una instancia de SQL Server falla, se habilita un nodo nuevo que ejecuta una nueva instancia de SQL Server (consulta este análisis en la sección Instancia de clústeres de conmutación por error siempre activa).
En la recuperación ante desastres, hay al menos dos regiones implicadas. En este proceso, se aborda el caso en el que una región completa no está disponible. La recuperación ante desastres puede proporcionar una nueva base de datos principal en una región diferente.
Las funciones de alta disponibilidad de SQL Server admiten soluciones de alta disponibilidad y recuperación ante desastres al mismo tiempo. Un solo grupo de disponibilidad puede abarcar las zonas dentro de una región y, también, las regiones. Un grupo de disponibilidad puede contener instancias de clústeres de conmutación por error para abordar la alta disponibilidad.
SQL Server puede establecer grupos de disponibilidad dentro de una región para la alta disponibilidad y las fallas de zonas, además de combinar esta acción con el envío de registros entre regiones a fin de abordar la recuperación ante desastres.
Alternativas de implementación de la DR
En las secciones siguientes, se muestran algunas topologías de recuperación ante desastres, además de las que se analizaron hasta ahora. Estas topologías satisfacen diferentes requisitos de RPO y RTO. Esta lista no es exhaustiva.
DR y alta disponibilidad intrarregionales
Esta implementación es una variación de un grupo de disponibilidad que contiene FCI dentro de una región que consta de tres zonas. En este caso, se considera que las zonas son el dominio del punto único de fallo.
En comparación con la implementación anterior, cada FCI consta de tres nodos, cada uno de los cuales se ejecuta en una zona diferente. El beneficio de esta configuración es que una o dos zonas pueden fallar sin que se requiera un proceso de recuperación ante desastres.
En el siguiente diagrama, se muestra esta configuración.
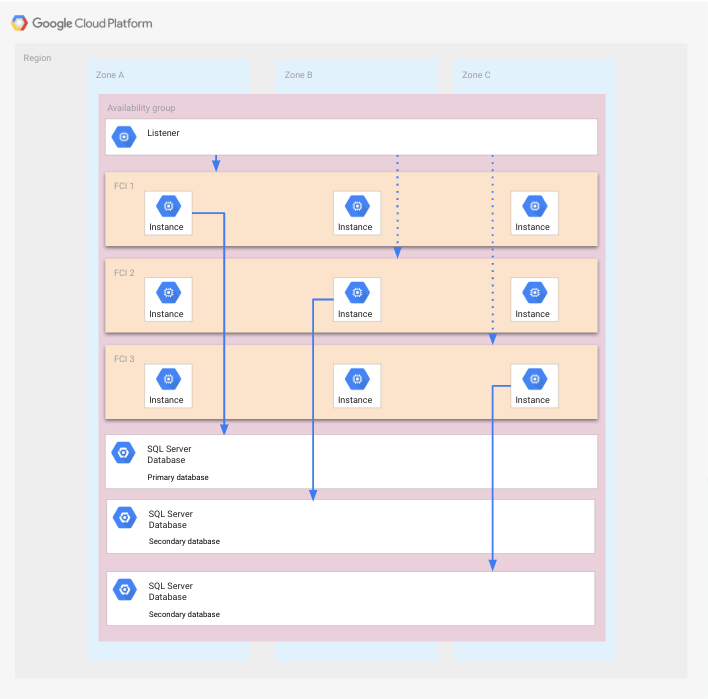
Las FCI abarcan todas las zonas, y cada FCI tiene una instancia de SQL Server en ejecución que accede a la base de datos correspondiente. Hay dos instancias más de SQL Server que no están en ejecución en cada FCI y que se pueden iniciar cuando falla una zona. Las bases de datos se muestran en todas las zonas, ya que cada base de datos usa los discos de todos los nodos que están en una FCI determinada. Una aplicación no se muestra por motivos de claridad.
DR interregional: grupo de disponibilidad que abarca regiones
En esta situación, un grupo de disponibilidad se ejecuta en un clúster de conmutación por error de Windows Server y abarca dos regiones. Las regiones se consideran un dominio de punto único de fallo.
En el siguiente diagrama, se ilustra esta configuración.

A fin de solucionar posibles problemas de latencia, puedes configurar las réplicas dentro de la región R1 para usar la propagación síncrona de transacciones, mientras que las réplicas en la región R2 están configuradas para usar una propagación asíncrona de transacciones.
DR interregional: transferencia de archivos de copia de seguridad
En esta situación, se usa la transferencia de archivos de copia de seguridad. Hay dos grupos de disponibilidad vinculados en dos regiones. Cada grupo de disponibilidad tiene sus réplicas que reciben las transacciones de forma síncrona; por lo que las réplicas secundarias de cada región tienen una configuración de espera activa.
En el siguiente diagrama, se ilustra esta configuración.
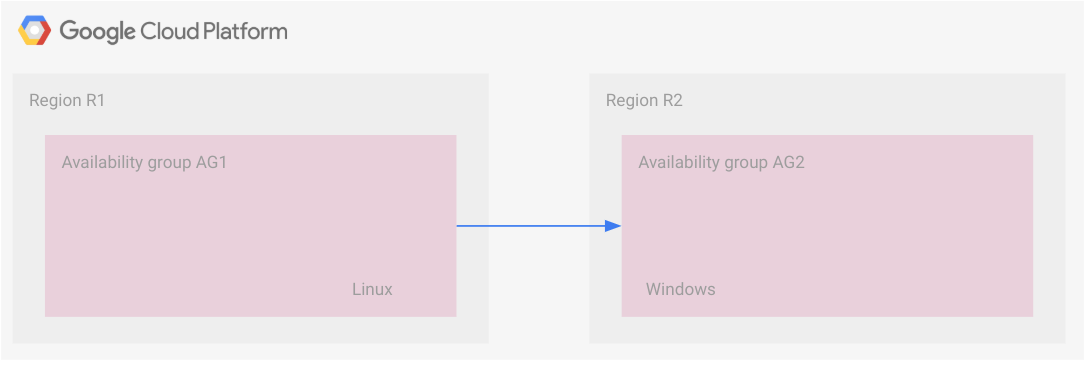
Sin embargo, los dos grupos de disponibilidad están conectados mediante la transferencia de archivos de copia de seguridad. El grupo de disponibilidad AG1 es el principal, y el grupo de disponibilidad AG2 es el secundario. A medida que los archivos de copia de seguridad están disponibles para el grupo de disponibilidad secundario, se aplican a él. Esta situación se analiza con más detalle en la siguiente sección, Ejemplo: estrategia de DR de copia de seguridad y restablecimiento.
Doble ubicación y topología de ubicación terciaria
Si solo hay dos bases de datos, una principal y una secundaria, cada una en una región diferente, existe un período sin protección después de una conmutación por error desde el momento en que la nueva base de datos principal comienza a funcionar y la nueva base de datos secundaria está lista. Si la nueva base de datos principal deja de estar disponible y la base de datos secundaria aún no se está ejecutando, se produce un tiempo de inactividad que solo se puede recuperar cuando se establece una nueva base de datos principal. Lo mismo se aplica a los grupos de disponibilidad.
Una tercera ubicación que ejecute otra base de datos secundaria o grupo de disponibilidad puede eliminar el período sin protección después de una conmutación por error. Esta configuración debe garantizar que una de las dos bases de datos secundarias siga siendo secundaria y se reasigne a una nueva base de datos principal para que no se pierdan datos. Como se indicó antes, se aplica lo mismo a los grupos de disponibilidad.
Ciclo de vida de la DR
Independientemente de la solución de recuperación ante desastres que elijas, hay pasos comunes del ciclo de vida que se aplican.
En una situación de recuperación ante desastres real, todas las partes interesadas (los propietarios de las aplicaciones, los grupos de operaciones y los administradores de las bases de datos) deben estar disponibles y participar de forma activa en la administración de la recuperación ante desastres. Las partes interesadas deben elegir la autoridad de decisión (a veces llamada instancia principal de la ceremonia) y los procesos de decisión que se deben seguir. Además, las partes interesadas deben acordar la terminología y los métodos de comunicación.
Decisión de iniciar un proceso de conmutación por error
A menos que la conmutación por error se inicie de forma automática, las partes interesadas deben tomar la decisión de iniciar una conmutación por error. Las distintas partes interesadas deben estar completamente de acuerdo con la decisión cuando optan por iniciar la conmutación por error.
Iniciar un proceso de conmutación por error depende de varios factores, sobre todo de que la base de datos principal deje de estar disponible.
Si el proceso de recuperación ante desastres lleva más tiempo del estimado en resolver la falta de disponibilidad de la base de datos principal, una conmutación por error sería perjudicial. Primero, debes evaluar si restablecer la base de datos principal es una opción factible.
Cuanto mejor se pruebe la estrategia de recuperación ante desastres, y cuanto más rápido se implemente, más fácil será iniciar el proceso de conmutación por error porque habrá menos incertidumbre a la hora de tomar la decisión.
Ejecución del proceso de conmutación por error
Lo ideal es que el proceso de conmutación por error se pruebe con regularidad y que, de este modo, las diversas partes interesadas lo conozcan bien.
La autoridad de decisión debe estar al tanto de todos los pasos que se realizan y de todos los problemas inesperados que surjan. La autoridad de decisión impulsa el proceso de conmutación por error y las partes interesadas son responsables de respaldar la autoridad de decisión.
Debes conservar las estadísticas para el análisis a posteriori y la mejora del proceso de conmutación por error; incluidas la duración de las actividades, los problemas que surgieron y cualquier confusión en los pasos del proceso de conmutación por error.
Falta de protección
Si solo tienes una base de datos secundaria, desde el momento en que la nueva base de datos principal está disponible y operativa hasta que se configura una nueva base de datos secundaria, no existe protección contra la DR. Una falta de disponibilidad durante este período puede causar un tiempo de inactividad severo, ya que no es posible realizar una conmutación por error a otra base de datos. Si surge esa situación, se debe configurar otra base de datos principal, y la RPA es el último aspecto que se puede reconstruir en función de las copias de seguridad disponibles.
A menos que la estrategia de recuperación ante desastres esté configurada de manera que haya protección en todo momento, cada parte interesada debe tener en cuenta este período de falta de protección para tomar precauciones adicionales durante los cambios de configuración o entorno.
Puedes evitar este período sin protección si el acceso de la aplicación a la nueva base de datos principal se retrasa hasta que la nueva base de datos secundaria esté en funcionamiento. En cuanto se apliquen los cambios de la base de datos principal, esta estará disponible para las aplicaciones. Si bien este enfoque evita que las aplicaciones no estén protegidas contra la DR, demora la finalización del proceso de recuperación ante desastres.
Evita las situaciones de cerebro dividido
Es importante que las aplicaciones no puedan acceder a una base de datos principal y a una secundaria al mismo tiempo de modo que se generen operaciones DML. En esta situación, ocurre una inconsistencia de datos que consiste en que los valores de datos de un mismo elemento de datos de la base de datos principal y la secundaria no coinciden (cerebro dividido). En particular, esta arquitectura es importante si la base de datos principal deja de estar disponible, pero se sigue ejecutando y puede recibir operaciones de escritura. Si la partición de red intermitente es la causa de la falta de disponibilidad, puede detenerse en cualquier momento, y una aplicación puede tener acceso de nuevo. Si se produce un proceso de conmutación por error en ese momento, es posible que se pierdan los cambios hechos en la base de datos principal anterior o que algunas aplicaciones comiencen a funcionar con la nueva base de datos principal mientras que otras siguen accediendo a la base de datos principal anterior.
El acceso de las aplicaciones a cualquier base de datos se desactiva por completo durante el proceso de conmutación por error para que no se produzcan cambios de estado en ninguna de las bases de datos. Después de la conmutación por error, solo hay una base de datos disponible para las operaciones de escritura: la nueva base de datos principal.
Declaración de finalización
Una vez que se completa el proceso de conmutación por error, la autoridad de decisión debe informar de forma explícita a todas las partes interesadas que se completó el proceso. Cualquier problema que aparezca después de la finalización debe tratarse como un incidente independiente que ya no forma parte del proceso de conmutación por error, sino que pertenece al procesamiento normal. El problema puede ser una consecuencia de un problema del proceso de conmutación por error o un problema independiente. Sin embargo, el método con el que se aborda el problema después de que se completó el proceso de conmutación por error puede ser diferente al que se usa para abordarlo durante la ejecución del proceso de conmutación por error.
Informe y análisis a posteriori
Para futuras consultas y a fin de mejorar el proceso de conmutación por error, organiza de inmediato un análisis a posteriori con el objetivo de tomar nota de aspectos, hallazgos y elementos de acción importantes.
Redacta un informe en el que se resuma el evento de recuperación ante desastres, las causas principales y todas las acciones realizadas. Este informe puede ser obligatorio si implementas requisitos normativos.
Prueba y verificación de la DR
Debido a que la recuperación ante desastres no forma parte de las operaciones diarias normales, la solución de DR debe someterse a pruebas periódicas para garantizar su correcto funcionamiento cuando se la necesite.
La frecuencia de las pruebas depende de los requisitos operativos y varía según la base de datos, la aplicación y la empresa. Además, los cambios en el entorno, como los cambios en la configuración de red y las actualizaciones de componentes de la infraestructura, deben activar una prueba de recuperación ante desastres si se realizan en los sistemas en los que se basa la solución de recuperación ante desastres que se eligió. Cualquier cambio puede hacer que la solución de recuperación ante desastres falle o que se requiera ajustar el proceso.
Puedes realizar la prueba de forma manual si inicias el proceso de conversión o de forma automática si sigues un enfoque de ingeniería de caos, como se describe en Chaos Engineering (Ingeniería del caos). Con las pruebas manuales, puedes minimizar el impacto comercial en caso de que se espere un tiempo de inactividad notable.
Un aspecto importante de las pruebas es recopilar estadísticas bien definidas. Estas son algunas estadísticas importantes que debes considerar:
- Tiempo de recuperación real: mide el tiempo de recuperación real y compáralo con el RTO.
- Punto de recuperación real: observa el punto de recuperación real y compáralo con el RPO.
- Tiempo hasta la detección de fallas: es el tiempo que tardaron los DBA o el equipo de operaciones en darse cuenta de la necesidad de realizar una conmutación por error.
- Tiempo de inicio de la recuperación: es el tiempo que llevó iniciar el proceso de conmutación por error después de que se detectó la falla.
- Confiabilidad: ¿qué tan detenidamente se siguió el proceso de conmutación por error o se requirieron desviaciones de él? ¿Surgieron problemas inesperados que deben investigarse, lo que puede generar posibilidades de un cambio en la estrategia de recuperación?
Según las estadísticas recopiladas, es posible que se deba ajustar o mejorar el proceso de conmutación por error para que se ajuste mejor con las expectativas de RPO y RTO.
Ejemplo: estrategia de DR con copia de seguridad y restablecimiento
En las siguientes secciones, se describe una estrategia de recuperación ante desastres con copia de seguridad y restablecimiento. En esta situación, se minimiza el uso de las funciones de disponibilidad de SQL Server a fin de demostrar el esfuerzo que se necesita para especificar una estrategia de copia de seguridad y restablecimiento de DR y debatir aspectos que son invisibles en los parámetros de configuración más automatizados.
Caso de uso
En la región R1, se encuentra un grupo de disponibilidad principal siempre activado. El grupo de disponibilidad secundario siempre activado se agrega a la región R2 para brindar protección interregional adicional y está disponible como objetivo de cambio o de conmutación.
Estrategia
La estrategia de recuperación ante desastres se basa en las copias de seguridad de la base de datos. Se realiza una copia de seguridad completa inicial seguida de copias de seguridad diferenciales posteriores. Las copias de seguridad se aplican al grupo de disponibilidad siempre activado secundario a medida que se realizan. Todas las copias de seguridad se almacenan en un bucket de Cloud Storage.
En este ejemplo, después de que se complete la conmutación por error es aceptable que el nuevo grupo de disponibilidad siempre activado principal en R2 esté activo y sin protección por un tiempo limitado hasta que el nuevo grupo de disponibilidad siempre activado secundario en R1 esté en funcionamiento.
No es necesario que haya una reversión, ya que el grupo de disponibilidad siempre activado en cada una de las regiones está calificado para funcionar como un grupo de disponibilidad siempre activado de producción.
RTO y RPO
En este ejemplo, el RPO se define como un máximo de 60 minutos, por lo que se realiza una copia de seguridad diferencial cada 60 minutos.
El RTO no se establece de forma explícita en un período, pero debe ser lo más breve posible; el mejor caso es el inmediato. El grupo de disponibilidad secundario debe configurarse en espera activa. En el caso de una espera activa, todas las copias de seguridad se aplican de inmediato para que la conmutación por error no se retrase con su aplicación.
Estrategia de DR de alto nivel
En las siguientes secciones, se describe la estrategia de DR. Se trata de una descripción breve a fin de poder centrarnos en los pasos esenciales.
Configuración inicial
- Crea un grupo de disponibilidad siempre activado secundario en la región R2.
- Evita que la aplicación acceda al grupo de disponibilidad secundario para que no se generen situaciones de cerebro dividido por accidente.
- Crea el bucket de archivos de copia de seguridad B1 en Cloud Storage para contener la copia de seguridad completa inicial del grupo de disponibilidad siempre activado en R1 y las copias de seguridad diferenciales posteriores del grupo de disponibilidad siempre activado en R1 que se realizan cada hora. Se debe establecer el orden correcto de las copias de seguridad diferenciales para que el proceso que aplica las copias de seguridad al grupo de disponibilidad secundario pueda inferir el orden correcto. Un enfoque que se puede adoptar es el de una convención de nombres que permita establecer el orden cronológico correcto en función de la fecha y la hora que forman parte de los nombres de los distintos archivos.
Estrategia de lanzamiento
- Aplica la copia de seguridad completa al grupo de disponibilidad siempre activado secundario en la región R2.
- A medida que las copias de seguridad diferenciales estén disponibles, aplícalas de inmediato al grupo de disponibilidad siempre activado secundario en R2. La aplicación inmediata es necesaria para abordar el RTO.
- Después de aplicar la copia de seguridad completa inicial y todas las copias de seguridad incrementales, el grupo de disponibilidad siempre activado secundario está listo.
- Para probar la estrategia de DR, realiza un cambio del grupo de disponibilidad principal al grupo de disponibilidad secundario. Al menos una copia de seguridad incremental debe estar disponible durante la prueba.
Caso de conmutación por error o cambio
En R2, los pasos esenciales son los siguientes:
- Asegúrate de que se haya aplicado la última copia de seguridad diferencial al grupo de disponibilidad siempre activado secundario en R2.
- Designa R2 como el nuevo grupo de disponibilidad siempre activado principal.
- Crea un bucket B2 nuevo, toma una copia de seguridad completa como modelo de referencia y abre el nuevo grupo de disponibilidad principal para que acceda la aplicación.
- Comienza a realizar copias de seguridad diferenciales.
En R1, los pasos esenciales son los siguientes:
- Quita el bucket B1, porque ya no lo necesitas.
- Cuando el grupo de disponibilidad siempre activado en R1 vuelva a estar disponible (como un nuevo grupo de disponibilidad siempre activado secundario), evita el acceso de la aplicación y quita todos los datos de la base de datos o restablece su estado inicial (vacío) (a menos que se la haya creado desde cero).
- Aplica la copia de seguridad completa del nuevo grupo de disponibilidad siempre activado principal en R2 y sigue aplicando copias de seguridad diferenciales de inmediato a medida que estén disponibles (almacenadas en el bucket B2).
Posibles mejoras
Una posible mejora de la estrategia de DR es evitar realizar una copia de seguridad completa después de una conmutación por error o un cambio, pero aun así poder configurar el nuevo grupo de disponibilidad secundario con rapidez. En lugar de una sola copia de seguridad completa y las copias de seguridad diferenciales posteriores, realiza una copia de seguridad completa todas las semanas y crea un bucket semanal que contenga la copia de seguridad completa de la semana, junto con todas sus copias de seguridad diferenciales posteriores. El nuevo grupo de disponibilidad principal debe crear copias de seguridad diferenciales solo después de la conmutación por error (no una copia de seguridad completa) y agregarlas al bucket. El nuevo grupo de disponibilidad secundario aplica todas las copias de seguridad en el bucket de la semana actual. Si se usa este método semanal, debes implementar una estrategia de limpieza o de borrado definitivo para quitar las copias de seguridad obsoletas.
Otra mejora se basa en el hecho de que el nuevo grupo de disponibilidad secundario solía ser el grupo de disponibilidad principal. Si la base de datos existe y está en funcionamiento una vez que vuelve a estar disponible, realizar una recuperación de un momento determinado hasta su última copia de seguridad diferencial evita tener que restablecer la base de datos por completo a partir de la última copia de seguridad completa, como se describe en el artículo Restore a SQL Server Database to a Point in Time (Restablecer una base de datos de SQL Server a un momento dado) [modelo de recuperación completa]. Esta situación reduce el esfuerzo y la cantidad de tiempo que el nuevo grupo de disponibilidad principal permanece sin protección.
Prácticas recomendadas de producción
En esta solución, no se especifica si las instancias de SQL Server en los grupos de disponibilidad siempre activados son instancias independientes o de FCI. El tipo de instancias que se usa debe decidirse antes de la implementación.
Hasta que un nuevo grupo de disponibilidad siempre activado secundario esté operativo después de una conmutación por error, hay un momento en el que la DR no está protegida. Debes configurar un tercer grupo de disponibilidad siempre activado en una tercera región.
Además, debes implementar la supervisión para garantizar que se detecte cualquier falla o error La supervisión no se trata en este documento, pero es esencial para una solución de recuperación ante desastres que funcione.
¿Qué sigue?
- Configura grupos de disponibilidad Always On de SQL Server.
- Implementa un grupo de disponibilidad Always On de SQL Server 2016 de varias subredes en Compute Engine.
- Configura instancias de clústeres de conmutación por error de SQL Server.
- Ejecuta los clústeres de conmutación por error de Windows Server.
- Cómo habilitar Cloud Logging, Cloud Monitoring y Error Reporting para aplicaciones .NET.
- Instala el agente de Cloud Monitoring.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.