Tutorial ini membahas cara menjalankan inferensi deep learning pada workload berskala besar menggunakan GPU NVIDIA TensorRT5 yang berjalan di Compute Engine.
Sebelum memulai, berikut beberapa hal penting:
- Inferensi deep learning adalah tahap dalam proses machine learning ketika model terlatih digunakan untuk mengenali, memproses, dan mengklasifikasikan hasil.
- NVIDIA TensorRT adalah platform yang dioptimalkan untuk menjalankan workload deep learning.
- GPU digunakan untuk mempercepat workflow yang intensif data seperti machine learning dan pemrosesan data. Berbagai GPU NVIDIA tersedia di Compute Engine. Tutorial ini menggunakan GPU T4, karena GPU T4 dirancang khusus untuk workflow inferensi deep learning.
Tujuan
Dalam tutorial ini, prosedur berikut dibahas:
- Menyiapkan model menggunakan grafik yang dilatih sebelumnya.
- Menguji kecepatan inferensi untuk model dengan mode pengoptimalan yang berbeda.
- Mengonversi model kustom menjadi TensorRT.
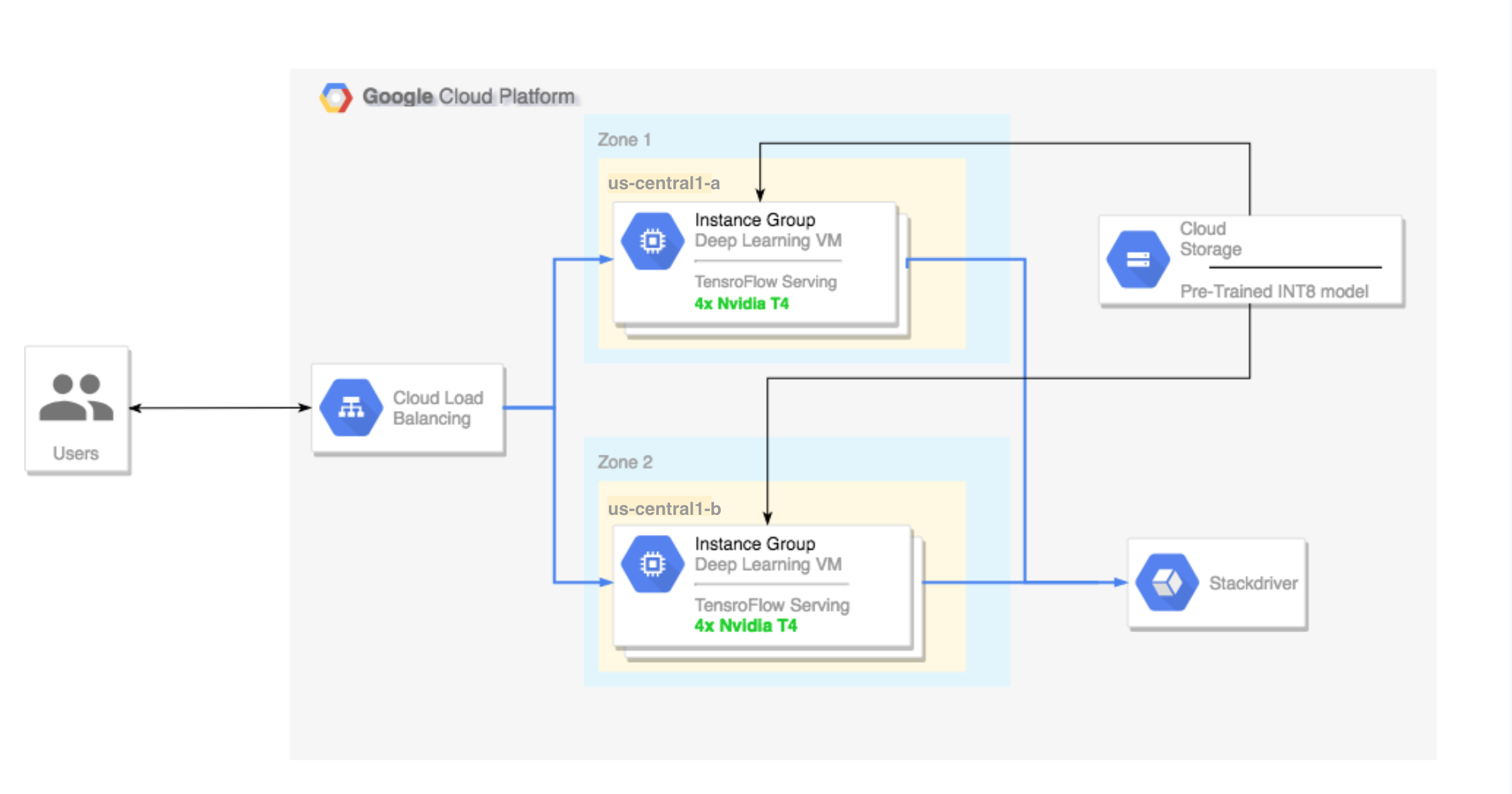
- Menyiapkan cluster multi-zona. Cluster multi-zona ini dikonfigurasi sebagai berikut:
- Dibangun berdasarkan Deep Learning VM Image. Image ini telah diinstal sebelumnya dengan TensorFlow, TensorFlow Serving, dan TensorRT5.
- Penskalaan otomatis diaktifkan. Penskalaan otomatis dalam tutorial ini didasarkan pada penggunaan GPU.
- Load balancing diaktifkan.
- Firewall diaktifkan.
- Menjalankan workflow inferensi di cluster multi-zona.
Prasyarat
Penyiapan project
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Compute Engine and Cloud Machine Learning APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Instal Google Cloud CLI atau update ke versi terbaru.
- Tetapkan region dan zona default (opsional).
Penyiapan alat
Untuk menggunakan Google Cloud CLI dalam tutorial ini:
Menyiapkan model
Bagian ini membahas pembuatan instance virtual machine (VM) yang digunakan untuk menjalankan model. Bagian ini juga membahas cara mendownload model dari katalog model resmi TensorFlow.
Buat instance VM. Tutorial ini dibuat menggunakan
tf-ent-2-10-cu113. Untuk versi image terbaru, lihat Memilih sistem operasi dalam dokumentasi Deep Learning VM Image.export IMAGE_FAMILY="tf-ent-2-10-cu113" export ZONE="us-central1-b" export INSTANCE_NAME="model-prep" gcloud compute instances create $INSTANCE_NAME \ --zone=$ZONE \ --image-family=$IMAGE_FAMILY \ --machine-type=n1-standard-8 \ --image-project=deeplearning-platform-release \ --maintenance-policy=TERMINATE \ --accelerator="type=nvidia-tesla-t4,count=1" \ --metadata="install-nvidia-driver=True"
Pilih sebuah model. Tutorial ini menggunakan model ResNet. Model ResNet ini dilatih menggunakan set data ImageNet yang berada di TensorFlow.
Untuk mendownload model ResNet ke instance VM Anda, jalankan perintah berikut:
wget -q http://download.tensorflow.org/models/official/resnetv2_imagenet_frozen_graph.pb
Simpan lokasi model ResNet Anda di variabel
$WORKDIR. GantiMODEL_LOCATIONdengan direktori kerja yang berisi model yang telah didownload.export WORKDIR=MODEL_LOCATION
Menjalankan uji kecepatan inferensi
Bagian ini membahas prosedur berikut:
- Menyiapkan model ResNet.
- Menjalankan pengujian inferensi pada berbagai mode pengoptimalan.
- Meninjau hasil pengujian inferensi.
Ringkasan proses pengujian
TensorRT dapat meningkatkan kecepatan performanya untuk workflow inferensi, tetapi peningkatan yang paling signifikan berasal dari proses kuantisasi.
Kuantisasi model adalah proses mengurangi presisi bobot untuk suatu model. Misalnya, jika bobot awal sebuah model adalah FP32, Anda dapat mengurangi presisinya ke FP16, INT8, atau bahkan INT4. Penting bagi Anda untuk memilih kompromi yang tepat antara kecepatan (presisi bobot) dan akurasi model. Untungnya, TensorFlow memiliki fungsionalitas untuk keperluan ini, yang mengukur akurasi versus kecepatan, atau metrik lainnya seperti throughput, latensi, rasio konversi node, dan total waktu pelatihan.
Prosedur
Siapkan model ResNet. Untuk menyiapkan model ini, jalankan perintah berikut:
git clone https://github.com/tensorflow/models.git cd models git checkout f0e10716160cd048618ccdd4b6e18336223a172f touch research/__init__.py touch research/tensorrt/__init__.py cp research/tensorrt/labellist.json . cp research/tensorrt/image.jpg ..
Jalankan pengujian. Penyelesaian perintah ini membutuhkan waktu beberapa lama.
python -m research.tensorrt.tensorrt \ --frozen_graph=$WORKDIR/resnetv2_imagenet_frozen_graph.pb \ --image_file=$WORKDIR/image.jpg \ --native --fp32 --fp16 --int8 \ --output_dir=$WORKDIR
Di mana:
$WORKDIRadalah direktori tempat Anda mendownload model ResNet.- Argumen
--nativeadalah mode kuantisasi berbeda yang akan diuji.
Tinjau hasilnya. Setelah pengujian selesai, Anda dapat membandingkan hasil inferensi untuk setiap mode pengoptimalan.
Predictions: Precision: native [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus'] Precision: FP32 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: FP16 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'lakeside, lakeshore', u'sandbar, sand bar'] Precision: INT8 [u'seashore, coast, seacoast, sea-coast', u'promontory, headland, head, foreland', u'breakwater, groin, groyne, mole, bulwark, seawall, jetty', u'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus', u'lakeside, lakeshore']
Untuk melihat hasil lengkapnya, jalankan perintah berikut:
cat $WORKDIR/log.txt
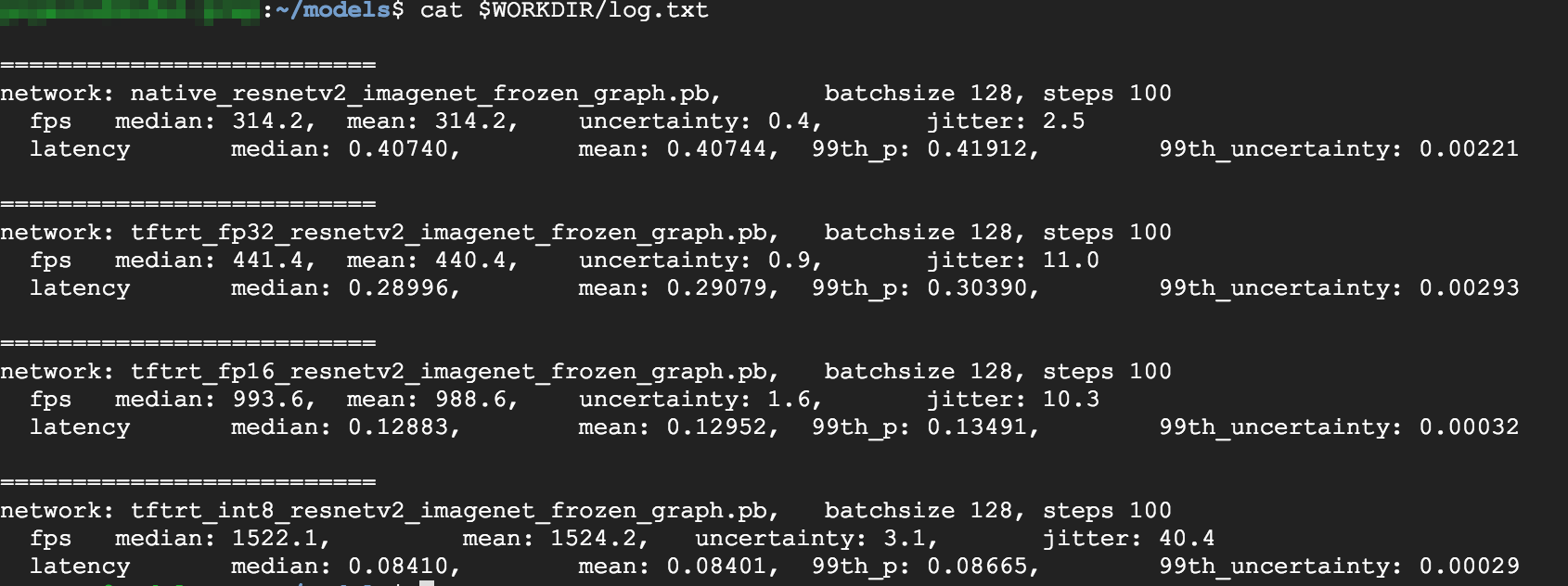
Dari hasil tersebut dapat dilihat bahwa FP32 dan FP16 identik. Artinya, jika Anda sudah nyaman menggunakan TensorRT, Anda pasti dapat langsung mulai menggunakan FP16. INT8, menunjukkan hasil yang sedikit lebih buruk.
Selain itu, Anda dapat melihat bahwa menjalankan model dengan TensorRT5 menunjukkan hasil berikut:
- Menggunakan pengoptimalan FP32, throughput meningkat 40% dari 314 fps menjadi 440 fps. Pada saat yang sama, latensi berkurang sekitar 30%, dari 0,40 md menjadi 0,28 md.
- Menggunakan pengoptimalan FP16, bukan grafik TensorFlow native, kecepatan meningkat 214% dari 314 menjadi 988 fps. Pada saat yang sama, latensi berkurang 0,12 md, turun hampir 3x lipat.
- Menggunakan INT8, Anda dapat melihat kecepatan meningkat 385% dari 314 fps menjadi 1.524 fps sementara latensi turun menjadi 0,08 md.
Mengonversi model kustom menjadi TensorRT
Untuk konversi ini, Anda dapat menggunakan model INT8.
Download modelnya. Untuk mengonversi model kustom menjadi grafik TensorRT, Anda memerlukan model tersimpan. Untuk mendapatkan model ResNet INT8 tersimpan, jalankan perintah berikut:
wget http://download.tensorflow.org/models/official/20181001_resnet/savedmodels/resnet_v2_fp32_savedmodel_NCHW.tar.gz tar -xzvf resnet_v2_fp32_savedmodel_NCHW.tar.gz
Konversi model menjadi grafik TensorRT menggunakan TFTools. Untuk mengonversi model menggunakan TFTools, jalankan perintah berikut:
git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/dlvm/tools python ./convert_to_rt.py \ --input_model_dir=$WORKDIR/resnet_v2_fp32_savedmodel_NCHW/1538687196 \ --output_model_dir=$WORKDIR/resnet_v2_int8_NCHW/00001 \ --batch_size=128 \ --precision_mode="INT8"
Sekarang Anda memiliki model INT8 di direktori
$WORKDIR/resnet_v2_int8_NCHW/00001.Untuk memastikan bahwa semuanya telah disiapkan dengan benar, coba jalankan pengujian inferensi.
tensorflow_model_server --model_base_path=$WORKDIR/resnet_v2_int8_NCHW/ --rest_api_port=8888
Upload model ke Cloud Storage. Langkah ini diperlukan agar model dapat digunakan dari cluster multi-zona yang disiapkan di bagian berikutnya. Untuk mengupload model, selesaikan langkah-langkah berikut:
Arsipkan model.
tar -zcvf model.tar.gz ./resnet_v2_int8_NCHW/
Upload arsip. Ganti
GCS_PATHdengan jalur ke bucket Cloud Storage Anda.export GCS_PATH=GCS_PATH gcloud storage cp model.tar.gz $GCS_PATH
Jika perlu, Anda bisa mendapatkan grafik frozen INT8 dari Cloud Storage di URL ini:
gs://cloud-samples-data/dlvm/t4/model.tar.gz
Menyiapkan cluster multi-zona
Bagian ini menjelaskan langkah-langkah yang harus Anda ikuti saat menyiapkan cluster multi-zona.
Membuat cluster
Setelah memiliki model di platform Cloud Storage, sekarang Anda dapat membuat cluster.
Buat template instance. Template instance merupakan resource berguna untuk membuat instance baru. Lihat Template Instance. Ganti
YOUR_PROJECT_NAMEdengan project ID Anda.export INSTANCE_TEMPLATE_NAME="tf-inference-template" export IMAGE_FAMILY="tf-ent-2-10-cu113" export PROJECT_NAME=YOUR_PROJECT_NAME gcloud beta compute --project=$PROJECT_NAME instance-templates create $INSTANCE_TEMPLATE_NAME \ --machine-type=n1-standard-16 \ --maintenance-policy=TERMINATE \ --accelerator=type=nvidia-tesla-t4,count=4 \ --min-cpu-platform=Intel\ Skylake \ --tags=http-server,https-server \ --image-family=$IMAGE_FAMILY \ --image-project=deeplearning-platform-release \ --boot-disk-size=100GB \ --boot-disk-type=pd-ssd \ --boot-disk-device-name=$INSTANCE_TEMPLATE_NAME \ --metadata startup-script-url=gs://cloud-samples-data/dlvm/t4/start_agent_and_inf_server_4.sh- Template instance ini mencakup skrip startup yang ditentukan oleh parameter metadata.
- Jalankan skrip startup ini selama pembuatan instance di setiap instance yang menggunakan template ini.
- Skrip startup ini melakukan langkah-langkah berikut:
- Menginstal agen pemantauan yang memantau penggunaan GPU di instance itu.
- Mendownload model.
- Memulai layanan inferensi.
- Dalam skrip startup,
tf_serve.pyberisi logika inferensi. Contoh ini mencakup file Python sangat kecil yang didasarkan pada paket TFServe. - Untuk melihat skrip startup, lihat startup_inf_script.sh.
- Template instance ini mencakup skrip startup yang ditentukan oleh parameter metadata.
Buat grup instance terkelola (MIG). Grup instance terkelola ini diperlukan untuk menyiapkan banyak instance yang berjalan di zona tertentu. Instance dibuat berdasarkan template instance yang dihasilkan pada langkah sebelumnya.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export INSTANCE_TEMPLATE_NAME="tf-inference-template" gcloud compute instance-groups managed create $INSTANCE_GROUP_NAME \ --template $INSTANCE_TEMPLATE_NAME \ --base-instance-name deeplearning-instances \ --size 2 \ --zones us-central1-a,us-central1-b
Anda dapat membuat instance ini di zona yang tersedia mana pun yang mendukung GPU T4. Pastikan kuota GPU tersedia di zona itu.
Pembuatan instance memerlukan waktu beberapa lama. Anda dapat melihat progresnya dengan menjalankan perintah berikut:
export INSTANCE_GROUP_NAME="deeplearning-instance-group"
gcloud compute instance-groups managed list-instances $INSTANCE_GROUP_NAME --region us-central1

Setelah grup instance terkelola dibuat, Anda akan melihat output yang mirip dengan berikut ini:

Pastikan metrik tersedia di Google Cloud halaman Cloud Monitoring.
Di konsol Google Cloud , buka halaman Monitoring.
Jika Metrics Explorer ditampilkan di panel navigasi, klik Metrics Explorer. Jika tidak, pilih Resources, lalu pilih Metrics Explorer.
Telusuri
gpu_utilization.
Saat data mulai masuk, Anda akan melihat sesuatu seperti ini:
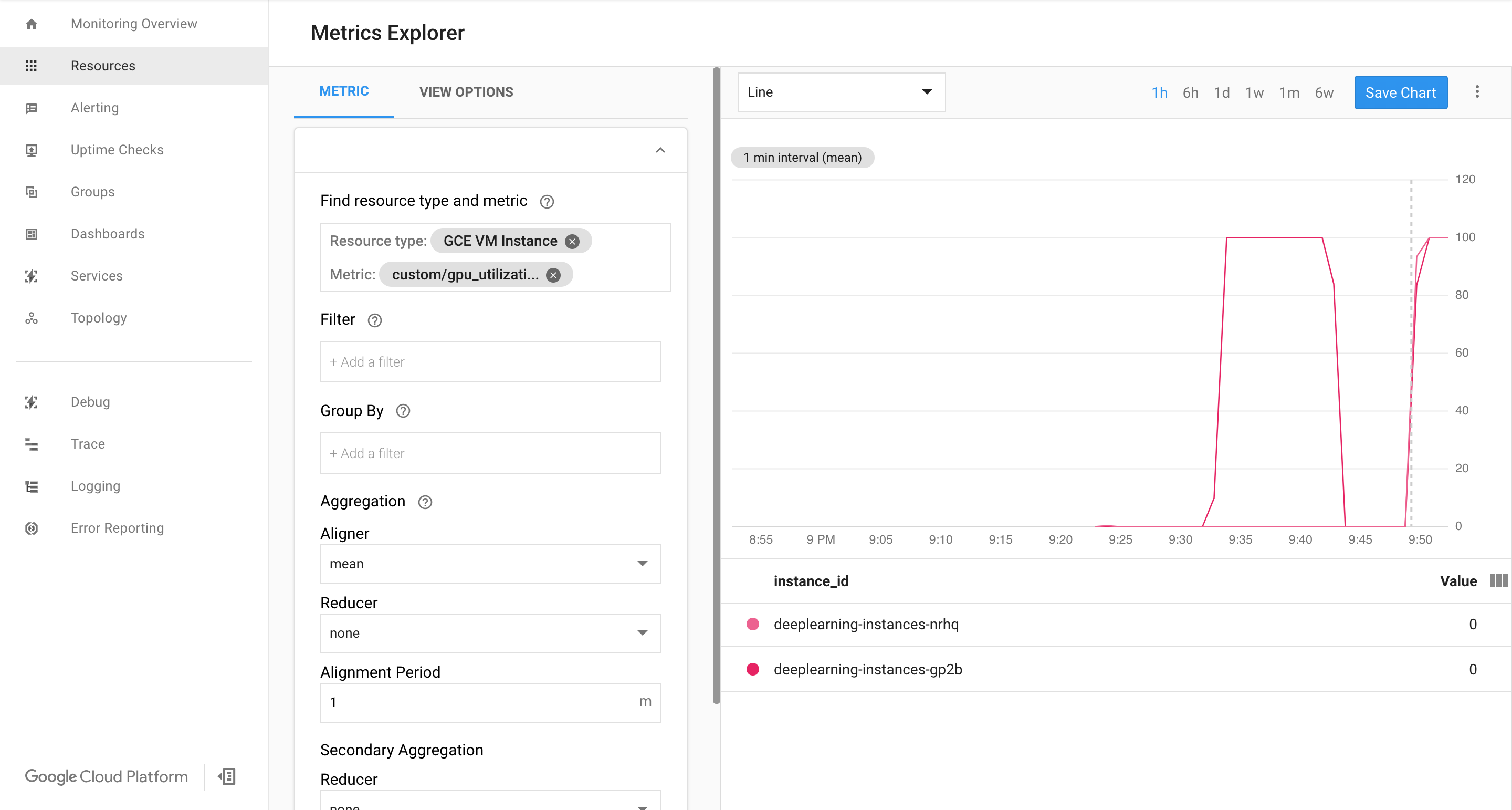
Mengaktifkan penskalaan otomatis
Aktifkan penskalaan otomatis untuk grup instance terkelola.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" gcloud compute instance-groups managed set-autoscaling $INSTANCE_GROUP_NAME \ --custom-metric-utilization metric=custom.googleapis.com/gpu_utilization,utilization-target-type=GAUGE,utilization-target=85 \ --max-num-replicas 4 \ --cool-down-period 360 \ --region us-central1
custom.googleapis.com/gpu_utilizationadalah jalur lengkap ke metrik kita. Contoh ini menetapkan level 85, yang berarti bahwa setiap kali penggunaan GPU mencapai 85, platform akan membuat instance baru di grup kita.Uji penskalaan otomatis. Untuk menguji penskalaan otomatis, Anda perlu menjalankan langkah berikut:
- SSH ke instance. Lihat bagian Terhubung ke Instance.
Gunakan alat
gpu-burnuntuk memuat GPU hingga pemakaian 100% selama 600 detik:git clone https://github.com/GoogleCloudPlatform/ml-on-gcp.git cd ml-on-gcp/third_party/gpu-burn git checkout c0b072aa09c360c17a065368294159a6cef59ddf make ./gpu_burn 600 > /dev/null &
Lihat halaman Cloud Monitoring. Amati penskalaan otomatis. Cluster akan meningkatkan skala dengan menambahkan satu instance lagi.
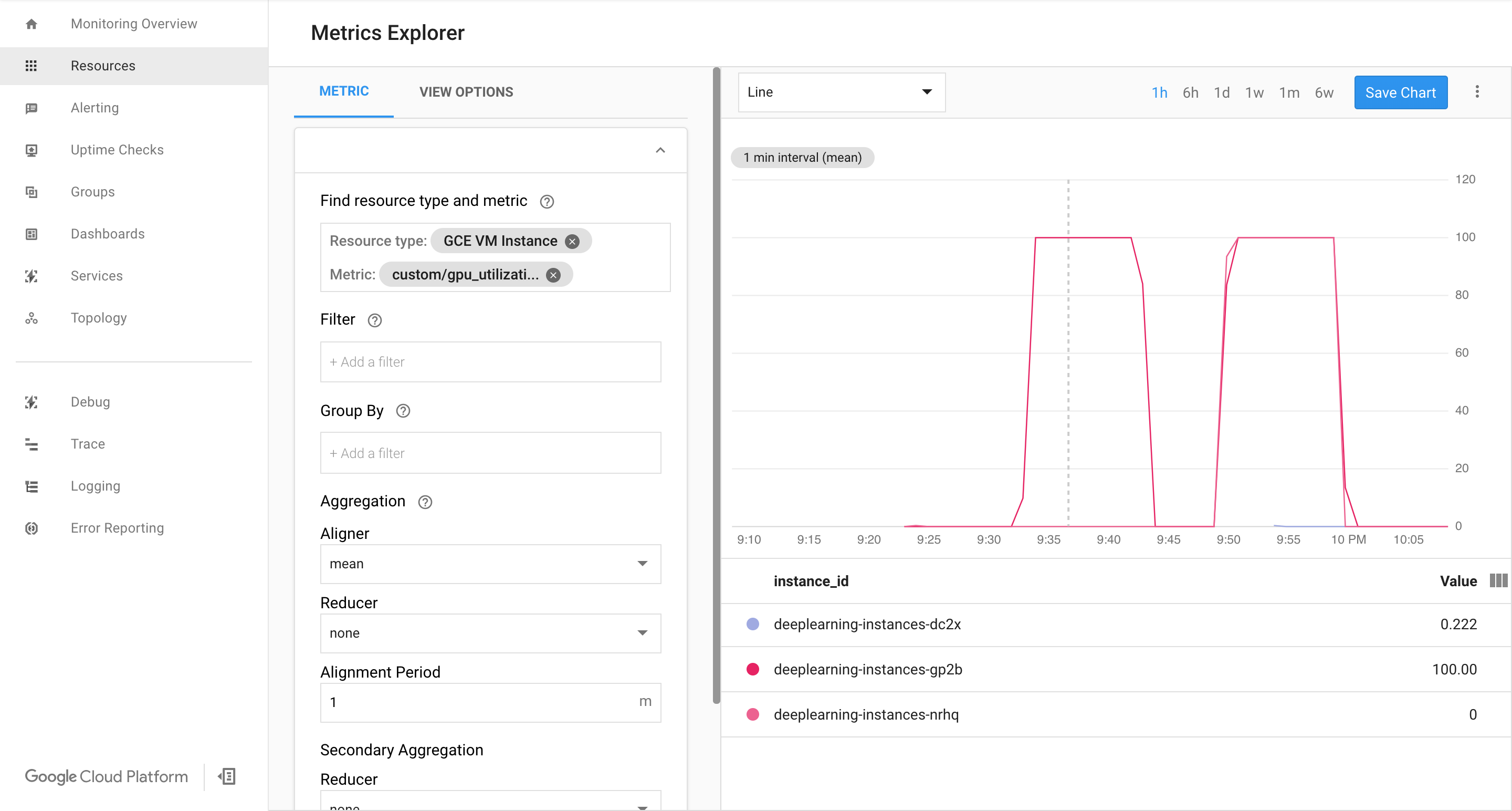
Di konsol Google Cloud , buka halaman Instance groups.
Klik grup instance terkelola
deeplearning-instance-group.Klik tab Monitoring.
Pada tahap ini, logika penskalaan otomatis Anda akan mencoba memutar sebanyak mungkin instance untuk mengurangi beban, tetapi tidak ada hasilnya:
Pada tahap ini, Anda dapat berhenti membakar instance, dan mengamati bagaimana sistem menurunkan skala.
Menyiapkan load balancer
Mari lihat kembali apa yang kita miliki sejauh ini:
- Model terlatih, yang dioptimalkan dengan TensorRT5 (INT8)
- Grup instance terkelola. Instance ini mengaktifkan penskalaan otomatis berdasarkan penggunaan GPU
Sekarang Anda dapat membuat load balancer di depan instance tersebut.
Buat health check. Health check digunakan untuk menentukan apakah host tertentu di backend kita dapat menyalurkan traffic atau tidak.
export HEALTH_CHECK_NAME="http-basic-check" gcloud compute health-checks create http $HEALTH_CHECK_NAME \ --request-path /v1/models/default \ --port 8888
Buat layanan backend yang mencakup grup instance dan health check.
Buat health check.
export HEALTH_CHECK_NAME="http-basic-check" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services create $WEB_BACKED_SERVICE_NAME \ --protocol HTTP \ --health-checks $HEALTH_CHECK_NAME \ --global
Tambahkan grup instance ke layanan backend baru.
export INSTANCE_GROUP_NAME="deeplearning-instance-group" export WEB_BACKED_SERVICE_NAME="tensorflow-backend" gcloud compute backend-services add-backend $WEB_BACKED_SERVICE_NAME \ --balancing-mode UTILIZATION \ --max-utilization 0.8 \ --capacity-scaler 1 \ --instance-group $INSTANCE_GROUP_NAME \ --instance-group-region us-central1 \ --global
Siapkan URL penerusan. Load balancer perlu mengetahui URL mana yang dapat diteruskan ke layanan backend.
export WEB_BACKED_SERVICE_NAME="tensorflow-backend" export WEB_MAP_NAME="map-all" gcloud compute url-maps create $WEB_MAP_NAME \ --default-service $WEB_BACKED_SERVICE_NAME
Buat load balancer.
export WEB_MAP_NAME="map-all" export LB_NAME="tf-lb" gcloud compute target-http-proxies create $LB_NAME \ --url-map $WEB_MAP_NAME
Tambahkan alamat IP eksternal ke load balancer.
export IP4_NAME="lb-ip4" gcloud compute addresses create $IP4_NAME \ --ip-version=IPV4 \ --network-tier=PREMIUM \ --global
Temukan alamat IP yang dialokasikan.
gcloud compute addresses list
Siapkan aturan penerusan yang memberi tahu Google Cloud untuk meneruskan semua permintaan dari alamat IP publik ke load balancer.
export IP=$(gcloud compute addresses list | grep ${IP4_NAME} | awk '{print $2}') export LB_NAME="tf-lb" export FORWARDING_RULE="lb-fwd-rule" gcloud compute forwarding-rules create $FORWARDING_RULE \ --address $IP \ --global \ --load-balancing-scheme=EXTERNAL \ --network-tier=PREMIUM \ --target-http-proxy $LB_NAME \ --ports 80Setelah membuat aturan penerusan global, mungkin perlu beberapa menit untuk menerapkan konfigurasi Anda.
Mengaktifkan firewall
Periksa apakah Anda memiliki aturan firewall yang mengizinkan koneksi dari sumber eksternal ke instance VM Anda.
gcloud compute firewall-rules list
Jika tidak memiliki aturan firewall untuk mengizinkan koneksi ini, Anda harus membuatnya. Untuk membuat aturan firewall, jalankan perintah berikut:
gcloud compute firewall-rules create www-firewall-80 \ --target-tags http-server --allow tcp:80 gcloud compute firewall-rules create www-firewall-8888 \ --target-tags http-server --allow tcp:8888
Menjalankan inferensi
Anda dapat menggunakan skrip Python berikut untuk mengonversi image ke dalam format yang dapat diupload ke server.
from PIL import Image import numpy as np import json import codecs
img = Image.open("image.jpg").resize((240, 240)) img_array=np.array(img) result = { "instances":[img_array.tolist()] } file_path="/tmp/out.json" print(json.dump(result, codecs.open(file_path, 'w', encoding='utf-8'), separators=(',', ':'), sort_keys=True, indent=4))Jalankan inferensi.
curl -X POST $IP/v1/models/default:predict -d @/tmp/out.json