본 대화형 튜토리얼에서는 자동 복구 기능을 사용하여 Compute Engine에서 가용성이 높은 앱을 빌드하는 방법을 보여줍니다.
가용성이 높은 앱은 지연 시간 및 다운타임이 최소화된 클라이언트를 제공하도록 설계됩니다. 앱이 다운되거나 중단되면 가용성이 저해됩니다. 이 경우 앱의 클라이언트는 높은 지연 시간 또는 다운타임을 경험할 수 있습니다.
자동 복구를 사용하면 장애가 발생한 앱을 자동으로 다시 시작할 수 있습니다. 이 기능은 장애가 발생한 가상 머신(VM) 인스턴스를 감지하고 이를 자동으로 다시 만들어서 클라이언트에 서비스를 계속 제공할 수 있습니다. 자동 복구 기능을 사용하면 더 이상 실패 후에 앱 서비스를 직접 복구할 필요가 없습니다.
앱 아키텍처
앱에는 다음과 같은 Compute Engine 구성요소가 포함됩니다.
- 상태 점검: 자동 복구 기능에서 실패한 VM을 감지하는 데 사용하는 HTTP 상태 점검 정책입니다.
- 방화벽 규칙:Google Cloud 방화벽 규칙을 사용하면 VM에 대한 트래픽을 허용하거나 거부할 수 있습니다.
- 관리형 인스턴스 그룹: 동일한 데모 웹 서비스를 실행하는 VM 그룹입니다.
- 인스턴스 템플릿: 인스턴스 그룹의 각 VM을 만들 때 사용하는 템플릿입니다.
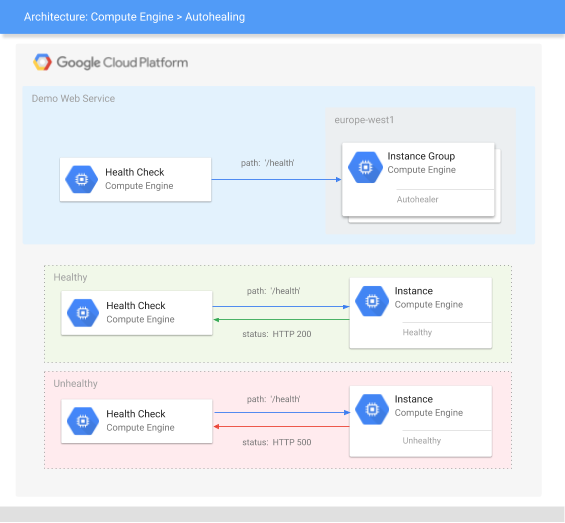
상태 점검이 데모 웹 서비스를 프로브하는 방법
상태 점검은 HTTP(S), SSL, TCP 같은 지정된 프로토콜을 사용하여 VM에 프로브 요청을 전송합니다. 자세한 내용은 상태 점검 작동 방식 및 상태 점검 카테고리, 프로토콜, 포트 문서를 참조하세요.
이 튜토리얼의 상태 점검은 포트 80에서 HTTP 경로 /health를 프로브하는 HTTP 상태 점검입니다. HTTP 상태 점검의 경우 경로가 HTTP 200 (OK) 응답을 반환하는 경우에만 프로브 요청이 전달됩니다. 이 튜토리얼에서는 정상일 때 /health 응답을 반환하고 비정상일 때 HTTP 200 (OK) 응답을 반환하기 위해 데모 웹 서버가 경로 HTTP 500 (Internal Server Error)를 정의합니다.
자세한 내용은 HTTP, HTTPS, HTTP/2의 성공 기준을 참조하세요.
상태 점검 만들기
자동 복구를 설정하려면 커스텀 상태 점검을 만들고 네트워크 방화벽을 구성하여 상태 점검 프로브를 허용합니다.
이 튜토리얼에서는 리전별 상태 점검을 만듭니다. 자동 복구의 경우 리전 또는 전역 상태 점검 중 하나를 사용할 수 있습니다. 리전별 상태 점검은 리전 간 종속 항목을 줄이고 데이터 상주를 달성하는 데 도움이 됩니다. 전역 상태 점검은 여러 리전의 MIG에 동일한 상태 점검을 사용하려는 경우에 편리합니다.
콘솔
상태 점검을 만듭니다.
Google Cloud 콘솔에서 상태 점검 만들기 페이지로 이동합니다.
이름 필드에
autohealer-check를 입력합니다.범위를
Regional로 설정합니다.리전 드롭다운에서
europe-west1을 선택합니다.프로토콜에서
HTTP를 선택합니다.요청 경로를
/health로 설정합니다. 이는 상태 점검이 사용하는 HTTP 경로를 나타냅니다. 이 튜토리얼에서는 정상일 때/health응답을 반환하고 비정상일 때HTTP 200 (OK)응답을 반환하기 위해 데모 웹 서버가 경로HTTP 500 (Internal Server Error)를 정의합니다.다음과 같이 상태 기준을 설정합니다.
- 확인 간격을
10으로 설정합니다. 이는 한 프로브의 시작부터 다른 프로브의 시작까지의 시간을 정의합니다. - 제한 시간을
5로 설정합니다. 이는Google Cloud 가 프로브에 대한 응답을 대기하는 시간을 정의합니다. 이 값은 확인 간격보다 작거나 같아야 합니다. - 정상 기준을
2로 설정합니다. 이는 VM이 정상으로 간주되도록 하기 위해 성공해야 하는 순차적 프로브의 수를 정의합니다. - 비정상 기준을
3로 설정합니다. 이는 VM이 비정상으로 간주되도록 하기 위해 실패해야 하는 순차적 프로브의 수를 정의합니다.
- 확인 간격을
다른 옵션은 기본값을 그대로 둡니다.
하단에서 만들기를 클릭합니다.
방화벽 규칙을 만들어 상태 점검 프로브가 HTTP 요청을 수행하도록 허용합니다.
Google Cloud 콘솔에서 방화벽 규칙 만들기 페이지로 이동합니다.
이름에
default-allow-http-health-check를 입력합니다.네트워크에서
default를 선택합니다.타겟에서
All instances in the network를 선택합니다.소스 필터에서
IPv4 ranges를 선택합니다.소스 IPv4 범위에
130.211.0.0/22, 35.191.0.0/16을 입력합니다.프로토콜 및 포트에서 TCP를 선택하고
80을 입력합니다.다른 옵션은 기본값을 그대로 둡니다.
만들기를 클릭합니다.
gcloud
health-checks create http명령어를 사용하여 상태 점검을 만듭니다.gcloud compute health-checks create http autohealer-check \ --region europe-west1 \ --check-interval 10 \ --timeout 5 \ --healthy-threshold 2 \ --unhealthy-threshold 3 \ --request-path "/health"check-interval은 한 프로브의 시작에서 다음 프로브의 시작까지의 시간을 정의합니다.timeout은 Google Cloud가 프로브에 대한 응답을 대기하는 시간을 정의합니다. 이 값은 확인 간격보다 작거나 같아야 합니다.healthy-threshold는 VM이 정상으로 간주되도록 하기 위해 성공해야 하는 순차적 프로브의 수를 정의합니다.unhealthy-threshold는 VM이 비정상으로 간주되도록 하기 위해 실패해야 하는 순차적 프로브의 수를 정의합니다.request-path는 상태 점검이 사용하는 HTTP 경로를 나타냅니다. 이 튜토리얼에서는 정상일 때HTTP 200 (OK)응답을 반환하고 비정상일 때HTTP 500 (Internal Server Error)응답을 반환하기 위해 데모 웹 서버가 경로/health를 정의합니다.
방화벽 규칙을 만들어 상태 점검 프로브가 HTTP 요청을 수행하도록 허용합니다.
gcloud compute firewall-rules create default-allow-http-health-check \ --network default \ --allow tcp:80 \ --source-ranges 130.211.0.0/22,35.191.0.0/16
유용한 자동 복구 상태 점검의 핵심 기능
자동 복구에 사용되는 상태 점검은 인스턴스를 사전에 삭제하고 다시 만들지 않도록 보수적이어야 합니다. 자동 복구 상태 점검이 지나치게 공격적인 경우 자동 복구 기능은 사용량이 많은 인스턴스를 실패한 인스턴스로 오인하고 불필요하게 다시 시작하여 가용성을 저하시킬 수 있습니다.
unhealthy-threshold:1보다 커야 합니다. 이 값을3이상으로 설정하는 것이 좋습니다. 이렇게 하면 네트워크 패킷 손실과 같이 드물게 발생하는 실패로부터 보호됩니다.healthy-threshold: 대부분의 앱에서 값이2면 충분합니다.timeout: 이 시간 값은 넉넉하게 설정합니다(예상되는 응답 시간의 5배 이상). 이렇게 하면 사용량이 많은 인스턴스 또는 느린 네트워크 연결과 같은 예상치 못한 지연으로부터 보호됩니다.check-interval: 이 값은 1초와 제한 시간 두 배 사이여야 합니다(너무 길지도, 너무 짧지도 않은 시간). 값이 너무 길면 실패한 인스턴스가 신속하게 포착되지 않습니다. 값이 너무 짧으면 매 초 전송되는 많은 수의 상태 점검 프로브로 인해 인스턴스와 네트워크의 사용량이 과도하게 많은 것으로 측정될 수 있습니다.
웹 서비스 설정
이 튜토리얼에서는 GitHub에 저장된 웹 앱을 사용합니다. 앱이 구현된 방법을 자세히 알아보려면 GoogleCloudPlatform/python-docs-samples GitHub 저장소를 참조하세요.
데모 웹 서비스를 설정하려면 시작 시 데모 웹 서버를 실행하는 인스턴스 템플릿을 만듭니다. 그런 다음 이 인스턴스 템플릿을 사용하여 관리형 인스턴스 그룹을 배포하고 자동 복구 기능을 사용 설정합니다.
콘솔
인스턴스 템플릿을 만듭니다. 데모 웹 서버를 시작하는 시작 스크립트를 추가합니다.
Google Cloud 콘솔에서 인스턴스 템플릿 만들기 페이지로 이동합니다.
이름을
webserver-template으로 설정합니다.위치 섹션의 리전 드롭다운에서 europe-west1을 선택합니다.
머신 구성 섹션의 머신 유형 드롭다운에서 e2-medium을 선택합니다.
방화벽 섹션에서 HTTP 트래픽 허용 체크박스를 선택합니다.
고급 옵션 섹션을 펼쳐 고급 설정을 표시합니다. 여러 하위 섹션이 표시됩니다.
관리 섹션에서 자동화를 찾고 다음 시작 스크립트를 입력합니다.
apt-get update apt-get -y install git python3-pip python3-venv git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git python3 -m venv venv ./venv/bin/pip3 install -Ur ./python-docs-samples/compute/managed-instances/demo/requirements.txt ./venv/bin/pip3 install gunicorn ./venv/bin/gunicorn --bind 0.0.0.0:80 app:app --daemon --chdir ./python-docs-samples/compute/managed-instances/demo
다른 옵션은 기본값을 그대로 둡니다.
만들기를 클릭합니다.
웹 서버를 관리형 인스턴스 그룹으로 배포합니다.
Google Cloud 콘솔에서 인스턴스 그룹 만들기 페이지로 이동합니다.
이름을
webserver-group으로 설정합니다.인스턴스 템플릿에서
webserver-template을 선택합니다.리전에서
europe-west1을 선택합니다.영역에서
europe-west1-b를 선택합니다.자동 확장 섹션의 자동 확장 모드에서 사용 안함: 자동 확장 안함을 선택합니다.
인스턴스 수 필드로 다시 스크롤하고
3으로 설정합니다.자동 복구 섹션에서 다음을 수행합니다.
- 상태 점검 드롭다운에서
autohealer-check를 선택합니다. 초기 지연을
300으로 설정합니다.
- 상태 점검 드롭다운에서
다른 옵션은 기본값을 그대로 둡니다.
만들기를 클릭합니다.
웹 서버에 대한 HTTP 요청을 허용하는 방화벽 규칙을 만듭니다.
Google Cloud 콘솔에서 방화벽 규칙 만들기 페이지로 이동합니다.
이름에
default-allow-http를 입력합니다.네트워크에서
default를 선택합니다.타겟에서
Specified target tags를 선택합니다.타겟 태그 에
http-server를 입력합니다.소스 필터에서
IPv4 ranges를 선택합니다.소스 IPv4 범위에
0.0.0.0/0을 입력하여 모든 IP 주소에 대한 액세스를 허용합니다.프로토콜 및 포트에서 TCP를 선택하고
80을 입력합니다.다른 옵션은 기본값을 그대로 둡니다.
만들기를 클릭합니다.
gcloud
인스턴스 템플릿을 만듭니다. 데모 웹 서버를 시작하는 시작 스크립트를 추가합니다.
gcloud compute instance-templates create webserver-template \ --instance-template-region europe-west1 \ --machine-type e2-medium \ --tags http-server \ --metadata startup-script=' apt-get update apt-get -y install git python3-pip python3-venv git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git python3 -m venv venv ./venv/bin/pip3 install -Ur ./python-docs-samples/compute/managed-instances/demo/requirements.txt ./venv/bin/pip3 install gunicorn ./venv/bin/gunicorn --bind 0.0.0.0:80 app:app --daemon --chdir ./python-docs-samples/compute/managed-instances/demo'관리형 인스턴스 그룹을 만듭니다.
gcloud compute instance-groups managed create webserver-group \ --zone europe-west1-b \ --template projects/PROJECT_ID/regions/europe-west1/instanceTemplates/webserver-template \ --size 3 \ --health-check projects/PROJECT_ID/regions/europe-west1/healthChecks/autohealer-check \ --initial-delay 300웹 서버에 대한 HTTP 요청을 허용하는 방화벽 규칙을 만듭니다.
gcloud compute firewall-rules create default-allow-http \ --network default \ --allow tcp:80 \ --target-tags http-server
관리형 인스턴스 그룹이 VM을 만들고 확인할 때까지 몇 분 정도 기다립니다.
상태 점검 실패 시뮬레이션
상태 점검 실패를 시뮬레이션하기 위해 데모 웹 서버는 강제로 상태 점검 실패를 만드는 방법을 제공합니다.
콘솔
웹 서버 VM으로 이동합니다.
Google Cloud 콘솔에서 VM 인스턴스 페이지로 이동합니다.
webserver-groupVM의 외부 IP 열에서 IP 주소를 클릭합니다. 웹 브라우저에 새 탭이 열립니다. 요청이 타임아웃되거나 웹 페이지를 사용할 수 없는 경우 서버가 설정을 완료할 때까지 1분 동안 기다렸다가 다시 시도하세요.
데모 웹 서버는 다음과 유사한 페이지를 표시합니다.
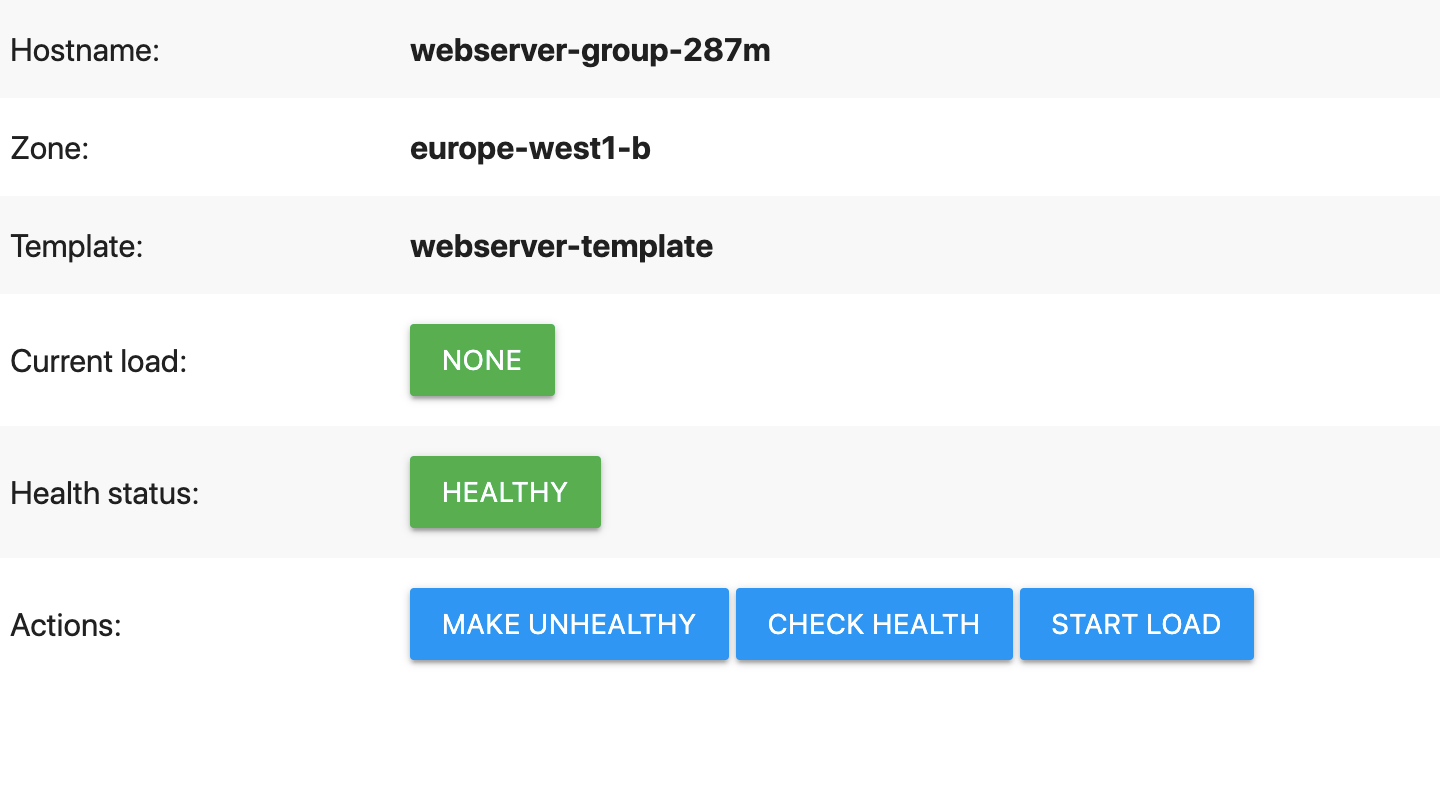
데모 웹페이지에서 비정상으로 설정을 클릭합니다.
이렇게 하면 웹 서버가 상태 점검에 실패합니다. 즉, 웹 서버는
/health경로가HTTP 500 (Internal Server Error)을 반환하도록 합니다. 상태 점검 버튼을 빠르게 클릭하여 직접 확인할 수 있습니다(자동 복구 기능이 VM 재부팅을 시작하면 작동이 중지됨).자동 복구 기능이 작동할 때까지 기다립니다.
Google Cloud 콘솔에서 VM 인스턴스 페이지로 이동합니다.
웹 서버 VM의 상태가 변경될 때까지 기다립니다. VM 이름 옆의 녹색 체크표시가 회색 사각형으로 변경됩니다. 이는 자동 복구 기능이 비정상 VM의 재부팅을 시작했음을 나타냅니다.
페이지 상단의 새로고침을 주기적으로 클릭하여 최신 상태를 가져옵니다.
회색 사각형이 VM이 정상 상태임을 나타내는 녹색 체크마크로 다시 변경되면 자동 복구 프로세스가 완료된 것입니다.
gcloud
관리형 인스턴스 그룹의 상태를 모니터링합니다. (모니터링을 마치면
Ctrl+C를 눌러 중지합니다.)while : ; do gcloud compute instance-groups managed list-instances webserver-group \ --zone europe-west1-b sleep 5 # Wait for 5 seconds done
NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: NAME: webserver-group-4qbx ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: NAME: webserver-group-m5v5 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR:
그룹의 모든 VM에
STATUS: RUNNING및ACTION: NONE이 표시되어야 합니다. 그렇지 않으면 VM 설정이 완료될 때까지 몇 분 정도 기다렸다가 다시 시도하세요.설치된 Google Cloud CLI를 사용해서 새 Cloud Shell 세션을 엽니다.
웹 서버 VM의 주소를 가져옵니다.
gcloud compute instances list --filter webserver-group
EXTERNAL_IP열에서 웹 서버 VM의 IP 주소를 복사하여 로컬 bash 변수로 저장합니다.export IP_ADDRESS=EXTERNAL_IP_ADDRESS
웹 서버가 설정을 완료했는지 확인합니다. 서버가
HTTP 200 OK응답을 합니다.curl --head $IP_ADDRESS/health
HTTP/1.1 200 OK Server: gunicorn ...
Connection refused오류가 발생하면 서버가 설정을 완료할 때까지 1분 동안 기다렸다가 다시 시도하세요.웹 서버를 비정상 상태로 설정합니다.
curl $IP_ADDRESS/makeUnhealthy > /dev/null
이렇게 하면 웹 서버가 상태 점검에 실패합니다. 즉, 웹 서버는
/health경로가HTTP 500 INTERNAL SERVER ERROR을 반환하도록 합니다./health을 빠르게 요청하여 직접 확인할 수 있습니다(자동 복구 기능이 VM 재부팅을 시작하면 작동이 중지됨).curl --head $IP_ADDRESS/health
HTTP/1.1 500 INTERNAL SERVER ERROR Server: gunicorn ...
첫 번째 셸 세션으로 돌아가서 관리형 인스턴스 그룹을 모니터링하고 자동 복구 기능이 작동할 때까지 기다립니다.
자동 복구 프로세스가 시작되면
STATUS열과ACTION열이 업데이트되어 자동 복구 기능이 비정상 VM의 재부팅을 시작했음을 나타냅니다.NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: STOPPING HEALTH_STATE: UNHEALTHY ACTION: RECREATING INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: ...
VM이
STATUS는RUNNING을,ACTION은NONE을 보고하여 VM이 성공적으로 다시 시작되었음을 나타내면 자동 복구 프로세스가 완료된 것입니다.NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: ...
관리형 인스턴스 그룹 모니터링을 마치면
Ctrl+C를 눌러 중지합니다.
이 연습을 얼마든지 반복해도 됩니다. 다음 팁을 참조하세요.
모든 VM을 한 번에 비정상으로 설정하는 경우 어떻게 될까요? 동시 실패 중의 자동 복구 동작에 대한 자세한 내용은 자동 복구 동작을 참조하세요.
VM을 최대한 빠르게 복구하기 위해 상태 점검 구성을 업데이트할 수 있나요? (실제로는 이 튜토리얼에서 설명한 대로 보수적인 값을 사용하도록 상태 점검 매개변수를 설정해야 합니다. 그렇지 않으면 실제 문제가 없는 경우에도 VM이 잘못 삭제되고 다시 시작될 위험이 있습니다.)
관리형 인스턴스 그룹에
initial delay구성 설정이 있습니다. 이 데모 웹 서버에 필요한 최소 지연 시간을 확인할 수 있나요? (실제로는 VM이 부팅되고 앱 요청을 처리하기 시작하는 데 걸리는 시간보다 지연 시간을 약간 더 길게(10~20%) 설정해야 합니다. 그렇지 않으면 VM이 자동 복구 부팅 루프에서 멈출 위험이 있습니다.)
자동 복구 기록 보기(선택사항)
자동 복구 작업의 기록을 보려면 다음 gcloud 명령어를 사용하세요.
gcloud compute operations list --filter='operationType~compute.instances.repair.*'
자세한 내용은 이전 자동 복구 작업 보기를 참조하세요.