Neste documento, descrevemos nós de locatário individual. Para informações sobre como provisionar VMs em nós de locatário individual, consulte este documento.
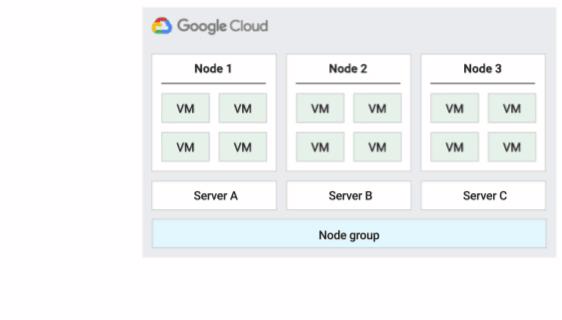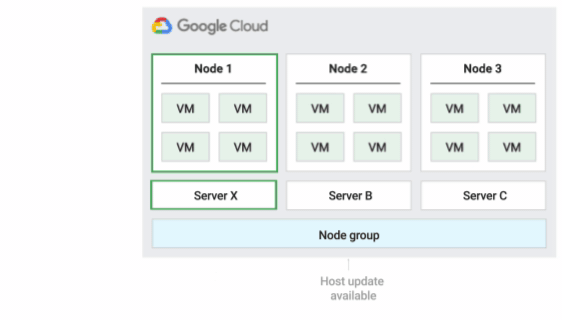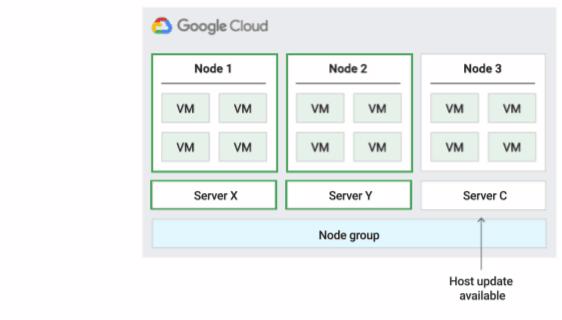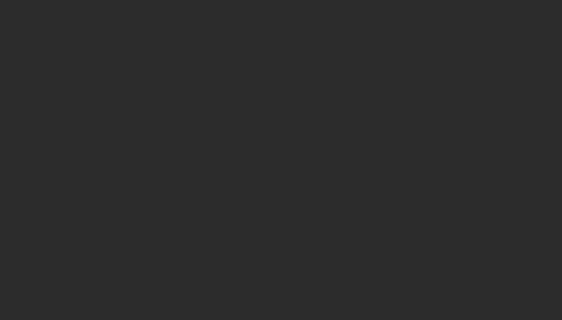
O locatário individual permite que você tenha acesso exclusivo a um nó de locatário individual, que é um servidor físico do Compute Engine dedicado a hospedar apenas as VMs do projeto. Use nós de locatário individual para manter suas VMs fisicamente separadas das VMs de outros projetos ou para agrupá-las no mesmo hardware host, conforme mostrado no diagrama a seguir. Também é possível criar um grupo de nós de locatário individual e especificar se você quer compartilhá-lo com outros projetos ou com toda a organização.

As VMs executadas em nós de locatário individual podem usar os mesmos recursos do Compute Engine que outras VMs, incluindo programação transparente e armazenamento em blocos, mas com uma camada extra de isolamento de hardware. Para que você tenha controle total sobre as VMs no servidor físico, cada nó de locatário individual tem um mapeamento de um para um em relação ao servidor físico que está fazendo backup do nó.
Em um nó de locatário individual, é possível provisionar várias VMs em tipos de máquina de vários tamanhos, o que permite usar os recursos do hardware de base do host dedicado. Além disso, se você optar por não compartilhar o hardware de host com outros projetos, será possível atender aos requisitos de segurança ou conformidade com cargas de trabalho que exijam isolamento físico de outras cargas de trabalho ou VMs. Caso a carga de trabalho exija uma locação única apenas temporariamente, modifique a locação de VM conforme necessário.
Os nós de locatário individual podem ajudar você a atender aos requisitos de hardware dedicados para cenários de licenças adquiridas pelo usuário (BYOL) que exigem licenças por núcleo ou por processador. Ao usar nós de locatário individual, você tem certa visibilidade sobre o hardware de base, o que permite monitorar o uso do núcleo e do processador. Para acompanhar esse uso, o Compute Engine informa o ID do servidor físico em que uma VM está programada. Em seguida, é possível usar o Cloud Logging para ver o histórico de uso do servidor de uma VM.
Para otimizar o uso do hardware do host, faça o seguinte:
Com uma política de manutenção configurável do host, é possível controlar o comportamento de VMs de locatário individual enquanto o host está em manutenção. Você pode especificar quando a manutenção ocorre e se as VMs mantêm a afinidade com um servidor físico específico ou se são movidas para outros nós de locatário individual em um grupo de nós.
Considerações sobre carga de trabalho
Os tipos de cargas de trabalho a seguir podem se beneficiar com o uso de nós de locatário individual:
Cargas de trabalho de jogos com requisitos de desempenho
Cargas de trabalho financeiras ou de saúde com requisitos de segurança e conformidade
Cargas de trabalho do Windows com requisitos de licenciamento
Cargas de trabalho de machine learning, processamento de dados ou renderização de imagens. Para essas cargas de trabalho, considere reservar GPUs.
Cargas de trabalho que exigem aumento de operações de entrada/saída por segundo (IOPS, na sigla em inglês) e redução de latência, ou cargas de trabalho que usam armazenamento temporário na forma de caches, espaço de processamento ou dados de baixo valor. Para essas cargas de trabalho, considere reservar discos SSD locais.
Modelos de nó
Um modelo de nó é um recurso regional que define as propriedades de cada nó em um grupo de nós. Ao criar um grupo de nós a partir de um modelo, as propriedades desse modelo serão copiadas sem alterações para cada nó do grupo.
Ao criar um modelo de nó, é necessário especificar um tipo de nó. Se preferir, especifique rótulos de afinidade de nó ao criar um modelo de nó. Só é possível especificar rótulos de afinidade de nó em um modelo de nó. Não é possível especificar rótulos de afinidade de nó em um grupo de nós.
Tipos de nós
Ao configurar um modelo de nó, especifique um tipo de nó para aplicar a todos os nós
presentes em um grupo criado com base nesse modelo. O tipo de nó de locatário individual,
referenciado pelo modelo de nó, especifica a quantidade total de núcleos de vCPU
e memória para nós criados em grupos de nós que usam esse modelo. Por exemplo,
o tipo de nó n2-node-80-640 tem 80 vCPUs e 640 GB de memória.
As VMs que você adicionar a um nó de locatário individual precisarão ter o mesmo tipo de máquina que
você especificar no modelo de nó. Por exemplo, os tipos de nó de locatário individual n2
são compatíveis somente com VMs criadas com o tipo de
máquina n2. É possível adicionar VMs a um nó de locatário individual até que a quantidade total de vCPUs ou
de memória exceda a capacidade do nó.
Ao criar um grupo de nós usando um modelo, cada nó do grupo
herda as especificações de tipo de nó desse modelo. Um tipo de nó se aplica a
cada nó individual em um grupo de nós, não a todos os nós do grupo
de maneira uniforme. Portanto, se você criar um grupo de nós com dois nós do tipo n2-node-80-640,
cada um deles receberá 80 vCPUs e 640 GB
de memória.
Dependendo dos requisitos de carga de trabalho, é possível preencher o nó com várias VMs menores executadas em tipos de máquina de vários tamanhos, incluindo tipos de máquina predefinidos, tipos de máquina personalizados e tipos de máquina com memória estendida. Quando um nó está cheio, não é possível programar mais VMs nele.
A tabela a seguir mostra os tipos de nó disponíveis. Para ver uma lista dos
tipos de nó disponíveis no projeto, execute o
comando
gcloud compute sole-tenancy node-types list
ou crie uma
solicitação REST nodeTypes.list.
| Tipo de nó | Processador | vCPU | GB | vCPU:GB | Soquetes | Núcleos:soquete | Total de núcleos | Número máximo de VMs permitidas |
|---|---|---|---|---|---|---|---|---|
c2-node-60-240 |
Cascade Lake | 60 | 240 | 1:4 | 2 | 18 | 36 | 15 |
c3-node-176-352 |
Sapphire Rapids | 176 | 352 | 1:2 | 2 | 48 | 96 | 44 |
c3-node-176-704 |
Sapphire Rapids | 176 | 704 | 1:4 | 2 | 48 | 96 | 44 |
c3-node-176-1408 |
Sapphire Rapids | 176 | 1408 | 1:8 | 2 | 48 | 96 | 44 |
c3d-node-360-708 |
AMD EPYC Genoa | 360 | 708 | 1:2 | 2 | 96 | 192 | 34 |
c3d-node-360-1440 |
AMD EPYC Genoa | 360 | 1440 | 1:4 | 2 | 96 | 192 | 40 |
c3d-node-360-2880 |
AMD EPYC Genoa | 360 | 2880 | 1:8 | 2 | 96 | 192 | 40 |
c4-node-192-384 |
Cordas de esmeralda | 192 | 384 | 1:2 | 2 | 60 | 120 | 40 |
c4-node-192-720 |
Cordas de esmeralda | 192 | 720 | 1:3.75 | 2 | 60 | 120 | 30 |
c4-node-192-1488 |
Cordas de esmeralda | 192 | 1.488 | 1:7.75 | 2 | 60 | 120 | 30 |
c4a-node-72-144 |
Google Axion | 72 | 144 | 1:2 | 1 | 80 | 80 | 22 |
c4a-node-72-288 |
Google Axion | 72 | 288 | 1:4 | 1 | 80 | 80 | 22 |
c4a-node-72-576 |
Google Axion | 72 | 576 | 1:8 | 1 | 80 | 80 | 36 |
c4d-node-384-720 |
AMD EPYC Turin | 384 | 744 | 1:2 | 2 | 96 | 192 | 24 |
c4d-node-384-1488 |
AMD EPYC Turin | 384 | 1488 | 1:4 | 2 | 96 | 192 | 25 |
c4d-node-384-3024 |
AMD EPYC Turin | 384 | 3024 | 1:8 | 2 | 96 | 192 | 25 |
g2-node-96-384 |
Cascade Lake | 96 | 384 | 1:4 | 2 | 28 | 56 | 8 |
g2-node-96-432 |
Cascade Lake | 96 | 432 | 1:4.5 | 2 | 28 | 56 | 8 |
h3-node-88-352 |
Sapphire Rapids | 88 | 352 | 1:4 | 2 | 48 | 96 | 1 |
m1-node-96-1433 |
Skylake | 96 | 1433 | 1:14.93 | 2 | 28 | 56 | 1 |
m1-node-160-3844 |
Broadwell E7 | 160 | 3.844 | 1:24 | 4 | 22 | 88 | 4 |
m2-node-416-8832 |
Cascade Lake | 416 | 8832 | 1:21.23 | 8 | 28 | 224 | 1 |
m2-node-416-11776 |
Cascade Lake | 416 | 11.776 | 1:28.31 | 8 | 28 | 224 | 2 |
m3-node-128-1952 |
Ice Lake | 128 | 1952 | 1:15.25 | 2 | 36 | 72 | 2 |
m3-node-128-3904 |
Ice Lake | 128 | 3904 | 1:30.5 | 2 | 36 | 72 | 2 |
m4-node-224-2976 |
Cordas de esmeralda | 224 | 2976 | 1:13.3 | 2 | 112 | 224 | 1 |
m4-node-224-5952 |
Cordas de esmeralda | 224 | 5952 | 1:26.7 | 2 | 112 | 224 | 1 |
n1-node-96-624 |
Skylake | 96 | 624 | 1:6.5 | 2 | 28 | 56 | 96 |
n2-node-80-640 |
Cascade Lake | 80 | 640 | 1:8 | 2 | 24 | 48 | 80 |
n2-node-128-864 |
Ice Lake | 128 | 864 | 1:6.75 | 2 | 36 | 72 | 128 |
n2d-node-224-896 |
AMD EPYC Rome | 224 | 896 | 1:4 | 2 | 64 | 128 | 112 |
n2d-node-224-1792 |
AMD EPYC Milan | 224 | 1792 | 1:8 | 2 | 64 | 128 | 112 |
n4-node-224-1372 |
Cordas de esmeralda | 224 | 1372 | 1:6 | 2 | 60 | 120 | 90 |
Para informações sobre os preços desses tipos de nó, consulte preços de nó de locatário individual.
Todos os nós permitem programar VMs de diferentes formas. O tipo n de nó são
nós de uso geral, em que é possível programar
instâncias de tipo de máquina personalizado. Para recomendações sobre qual tipo de nó escolher, consulte
Recomendações para tipos de máquina.
Para informações sobre desempenho, consulte
Plataformas de CPU.
Grupos de nós e provisionamento de VM
Os modelos de nó de locatário individual definem as propriedades de um grupo de nós, então é necessário criar um modelo de nó antes de criar um grupo em uma zona do Google Cloud. Ao criar um grupo, especifique a política de manutenção do host para VMs no grupo de nós, o número de nós do grupo de nós e se você quer compartilhá-lo com outros projetos ou com toda a organização.
Um grupo pode ter zero ou mais nós. Por exemplo, o número de nós em um grupo poderá ser reduzido para zero quando não for necessário executar nenhuma VM nos nós do grupo. Além disso, o escalonador automático do grupo de nós pode ser ativado para gerenciar o tamanho do grupo de nós automaticamente.
Antes de provisionar VMs em nós de locatário individual, crie um grupo desse tipo. Um grupo de nós é um conjunto homogêneo de nós de locatário individual em uma zona específica. Grupos de nós podem conter várias VMs da mesma série de máquinas em execução em tipos de máquina de vários tamanhos, contanto que o tipo de máquina tenha duas ou mais vCPUs.
Ao criar um grupo de nós, ative o escalonamento automático para que o tamanho do grupo seja ajustado automaticamente e atenda aos requisitos da carga de trabalho. Se os requisitos de carga de trabalho forem estáticos, especifique o tamanho do grupo de nós manualmente.
Depois de criar um grupo de nós, é possível provisionar VMs no grupo ou em um nó específico dentro do grupo. Para ter mais controle, use rótulos de afinidade de nó para programar VMs em qualquer nó com rótulos de afinidade correspondentes.
Depois de provisionar VMs em grupos de nós e, como opção, atribuir rótulos de afinidade para provisionar VMs em grupos ou nós específicos, considere rotular recursos para ajudar a gerenciar as VMs. Os rótulos são pares de chave-valor que podem ajudar a categorizar VMs. Assim, você consegue visualizá-las de forma agregada para fins de faturamento, por exemplo. Os rótulos podem ser usados para marcar o papel de uma VM, o locatário, o tipo de licença ou o local.
Política de manutenção do host
Dependendo dos cenários de licenciamento e das cargas de trabalho, convém limitar o número de núcleos físicos usados pelas VMs. A política de manutenção do host escolhida pode depender, por exemplo, dos requisitos de licenciamento ou conformidade. Ou talvez você prefira uma política que permita limitar o uso de servidores físicos. Com todas essas políticas, as VMs permanecem em hardware dedicado.
Ao programar VMs em nós de locatário individual, é possível escolher uma das três políticas de manutenção do host a seguir. Elas permitem determinar como e se o Compute Engine migra em tempo real as VMs durante os eventos do host, que ocorrem aproximadamente a cada quatro a seis semanas. Durante a manutenção, o Compute Engine migra em tempo real, como um grupo, todas as VMs no host para um nó de locatário individual diferente. Em alguns casos, porém, o Compute Engine pode dividir as VMs em grupos menores e migrar em tempo real cada um deles para separar nós de locatário individual.
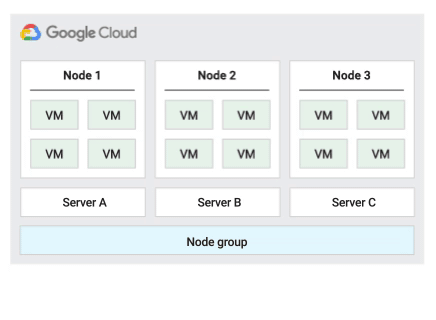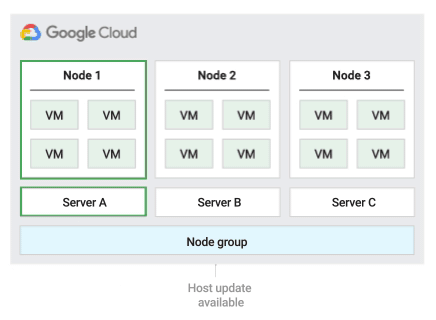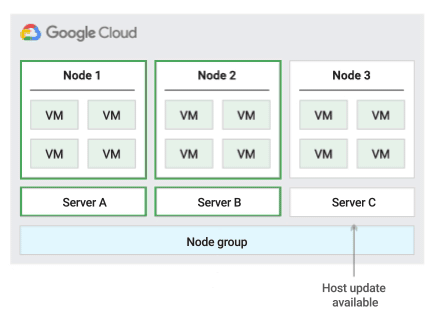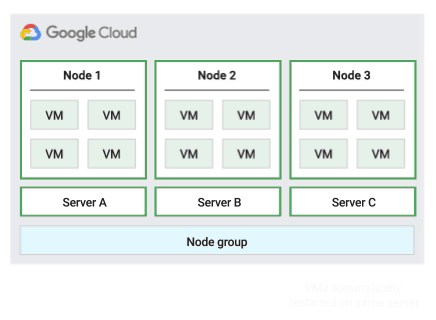
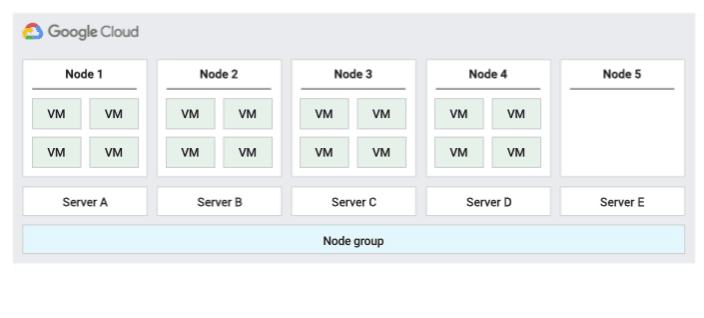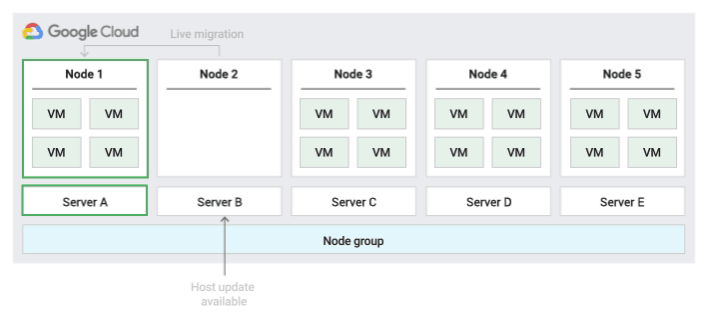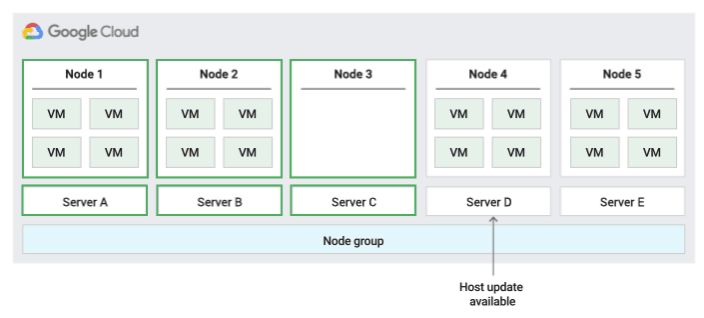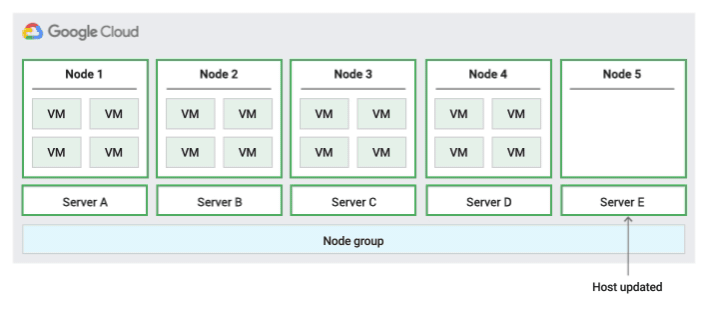
Política padrão de manutenção do host
Essa é a política de manutenção padrão, e as VMs em grupos de nós configurados com essa política seguem o comportamento de manutenção tradicional das VMs que não são de locatário individual. Isso significa que, dependendo da configuração de manutenção do host da VM, as VMs migram em tempo real para um novo nó de locatário individual no grupo de nós antes de um evento de manutenção do host. Esse novo nó de locatário individual executa apenas as VMs do cliente.
Essa política é mais adequada para licenças por usuário ou por dispositivo que exigem migração em tempo real durante eventos do host. Essa configuração não restringe a migração de VMs para um pool fixo de servidores físicos e é recomendada para cargas de trabalho gerais que não exigem servidores físicos e licenças atuais.
Como as VMs migram em tempo real para qualquer servidor sem considerar a afinidade do servidor atual com essa política, ela não é adequada para cenários que exigem minimização do uso de núcleos físicos durante eventos do host.
A figura a seguir mostra uma animação da política de manutenção do host padrão.
Reiniciar a política de manutenção do host no local
Ao usar essa política de manutenção do host, o Compute Engine interrompe as VMs
durante os eventos do host e, em seguida, reinicia as VMs no mesmo servidor físico após
o evento do host. Com esta política, você precisa definir as configurações de manutenção do
host da VM para serem TERMINATE.
Essa política é mais adequada para cargas de trabalho tolerantes a falhas e que podem apresentar aproximadamente uma hora de inatividade durante eventos do host, cargas de trabalho que precisam permanecer no mesmo servidor físico e cargas de trabalho que não exigem migração em tempo real. Ela também é adequada para quem tem licenças com base no número de núcleos físicos ou processadores.
Com essa política, a instância pode ser atribuída ao grupo de nós usando
node-name, node-group-name ou um rótulo de afinidade de nó.
A figura a seguir mostra uma animação da política de manutenção Reinicialização no local.
Migrar na política de manutenção do host do grupo de nós
Ao usar essa política de manutenção do host, o Compute Engine migra em tempo real as VMs em um grupo de servidores físicos de tamanho fixo durante os eventos do host, o que ajuda a limitar o número de servidores físicos exclusivos usados pela VM.
Essa política é mais adequada para cargas de trabalho de alta disponibilidade com licenças baseadas no número de núcleos ou processadores físicos, já que com essa política de manutenção do host cada nó de locatário individual no grupo é fixado em um conjunto fixo de servidores físicos. Isso é diferente da política padrão, que permite às VMs migrarem para qualquer servidor.
Para confirmar a capacidade de migração em tempo real, o Compute Engine reserva um nó de restrição para cada 20 nós reservados. A figura a seguir mostra uma animação da política de manutenção do host Migração dentro do grupo de nós.
A tabela a seguir mostra quantos nós de restrição são reservados pelo Compute Engine, dependendo de quantos nós você reserva para o grupo de nós.
| Total de nós no grupo | Nós de restrição reservados para migração em tempo real |
|---|---|
| 1 | Não relevante. É necessário reservar pelo menos dois nós. |
| 2 a 20 | 1 |
| 21 a 40 | 2 |
| 41 a 60 | 3 |
| 61 a 80 | 4 |
| 81 a 100 | 5 |
Fixar uma instância em vários grupos de nós
É possível fixar uma instância em vários grupos de nós usando o node-group-name
rótulo de afinidade
nas seguintes condições:
- A instância que você quer fixar está usando uma política de manutenção do host padrão (Migrar instância da VM).
- A política de manutenção do host de todos os grupos de nós em que você quer fixar a instância é migrar dentro do grupo de nós. Se você tentar fixar uma instância em grupos de nós com políticas de manutenção de host diferentes, a operação vai falhar com um erro.
Por exemplo, se você quiser fixar uma instância test-node em dois grupos de nós node-group1 e node-group2, verifique o seguinte:
- A política de manutenção de host de
test-nodeé Migrar instância de VM. - A política de manutenção do host de
node-group1enode-group2é migrar no grupo de nós.
Não é possível atribuir uma instância a um nó específico com o rótulo de afinidade
node-name. Você pode usar qualquer rótulo de afinidade de nó personalizado para suas instâncias, desde que recebam node-group-name e não node-name.
Janelas de manutenção
Se você estiver gerenciando cargas de trabalho, por exemplo, bancos de dados ajustados, que podem ser sensíveis ao impacto no desempenho da migração em tempo real, é possível determinar quando a manutenção começa em um grupo nó de locatário individual especificando uma janela de manutenção ao criar o grupo. Não é possível modificar a janela de manutenção depois de criar o grupo de nós.
As janelas de manutenção são blocos de quatro horas que podem ser usados para especificar quando o Google realiza manutenção nas VMs de locatário individual. Os eventos de manutenção ocorrem aproximadamente uma vez a cada quatro a seis semanas.
Essa janela de manutenção se aplica a todas as VMs no grupo de nós de locatário individual e só especifica quando a manutenção é iniciada. Não há garantia de que ela será concluída durante a janela de manutenção. Também não há garantias sobre a frequência de manutenção. As janelas de manutenção não são compatíveis em grupos de nós com a política de manutenção do host migrar dentro do grupo de nós.
Simular um evento de manutenção de host
É possível simular um evento de manutenção de host para testar como as cargas de trabalho em execução nos nós de locatário individual se comportam durante um evento de manutenção de host. Isso permite que você confira os efeitos da política de manutenção de host da VM de locatário individual nos aplicativos em execução nas VMs.
Erros de host
Quando há uma falha crítica de hardware grave no host, locatário individual ou multilocatário, o Compute Engine faz o seguinte:
desativa o servidor físico e seu identificador exclusivo;
revoga o acesso do projeto ao servidor físico;
substitui o hardware com falha por um novo servidor físico que tem um novo identificador exclusivo;
migra as VMs do hardware com falha para o nó substituto;
reinicia as VMs afetadas se você as configurou para reiniciar automaticamente.
Afinidade e antiafinidade de nós
Os nós de locatário individual garantem que suas VMs não compartilhem um host com VMs de outros projetos, a menos que você use grupos de nó de locatário individual compartilhados. Com os grupos de nós de locatário individual compartilhados, outros projetos dentro da organização podem provisionar VMs no mesmo host. No entanto, é possível agrupar várias cargas de trabalho no mesmo nó de locatário individual ou isolar cargas de trabalho em nós diferentes. Por exemplo, para ajudar a cumprir alguns requisitos de conformidade, talvez seja necessário usar rótulos de afinidade para separar cargas de trabalho confidenciais de cargas de trabalho não confidenciais.
Ao criar uma VM, você solicita o locatário individual especificando a afinidade ou antiafinidade do nó, referenciando um ou mais rótulos de afinidade de nó. Ao criar um modelo de nó, você especifica rótulos de afinidade personalizados. O Compute Engine inclui automaticamente alguns rótulos de afinidade padrão em cada nó. Ao especificar a afinidade durante a criação de uma VM, é possível programar VMs em um nó específico ou em um grupo de nós. Ao especificar a antiafinidade no momento de criação de uma VM, você garante que determinadas VMs não sejam programadas juntas no mesmo nó ou em um grupo de nós.
Os rótulos de afinidade de nó são pares de chave-valor atribuídos a nós e são herdados de um modelo de nó. Os rótulos de afinidade permitem:
- controlar como as instâncias de VM individuais são atribuídas aos nós;
- controlar como são atribuídas a nós as instâncias de VM criadas com base em um modelo, como as criadas por um grupo de instâncias gerenciadas;
- agrupar instâncias de VM confidenciais em nós ou grupos de nós específicos, separadas de outras VMs.
Rótulos de afinidade padrão
O Compute Engine atribui os seguintes identificadores de afinidade padrão a cada nó:
- Um rótulo para o nome do grupo de nós:
- Chave:
compute.googleapis.com/node-group-name - Valor: nome do grupo de nós
- Chave:
- Um rótulo para o nome do nó:
- Chave:
compute.googleapis.com/node-name - Valor: nome do nó individual
- Chave:
- Um rótulo para os projetos com que o grupo de nós é compartilhado:
- Chave:
compute.googleapis.com/projects - Valor: ID do projeto que contém o grupo de nós.
- Chave:
Rótulos de afinidade personalizados
É possível criar rótulos de afinidade de nó personalizados ao criar um modelo de nó. Esses rótulos de afinidade são atribuídos a todos os nós dos grupos criados com base nesse modelo. Não é possível adicionar mais rótulos de afinidade personalizados a nós em um grupo após ele ser criado.
Para informações sobre como usar rótulos de afinidade, consulte Como configurar a afinidade de nó.
Preços
Para ajudar a minimizar o custo dos nós de locatário individual, o Compute Engine oferece descontos por uso contínuo (CUDs) e descontos por uso prolongado (SUDs). Para cobranças premium de locatário individual, você só pode receber CUDs e SUDs flexíveis, não CUDs baseados em recursos.
Como a vCPU e a memória dos nós de locatário individual já são cobradas, você não paga mais pelas VMs criadas nesses nós.
Se você provisionar nós de locatário individual com GPUs ou discos SSD locais, será cobrado por todas as GPUs ou discos SSD locais em cada nó provisionado. O acréscimo de locatário individual é baseado apenas nas vCPUs e na memória usadas para o nó de locatário individual e não inclui GPUs ou discos SSD locais.
Disponibilidade
Os nós de locatário individual estão disponíveis em zonas selecionadas. Para verificar a alta disponibilidade, programe VMs em nós de locatário individual em diferentes zonas.
Antes de usar GPUs ou discos SSD locais em nós de locatário individual, verifique se você tem cota de GPU ou SSD local suficiente na zona em que está reservando o recurso.
O Compute Engine é compatível com GPUs em tipos de nós de locatário individual do
n1oug2que estejam em zonas compatíveis com GPU. A tabela a seguir mostra os tipos de GPUs que podem ser anexadas a nósn1eg2e quantas GPUs você precisa anexar ao criar o modelo de nó.Tipo de GPU Quantidade da GPU Tipo de nó de locatário individual NVIDIA L4 8 g2NVIDIA P100 4 n1NVIDIA P4 4 n1NVIDIA T4 4 n1NVIDIA V100 8 n1O Compute Engine é compatível com discos SSD locais nos tipos de nós de locatário individual
n1,n2,n2deg2usados em zonas que oferecem suporte a essas séries de máquinas.
Restrições
Não é possível usar VMs de locatário individual com as seguintes séries e tipos de máquinas: T2D, T2A, E2, C2D, A2, A3, A4, A4X, G4 ou instâncias de hardware bare metal.
VMs de locatário individual não podem especificar uma plataforma mínima de CPU.
Não é possível migrar uma VM para um nó de locatário individual se essa VM especificar uma plataforma mínima de CPU. Para migrar uma VM para um nó de locatário individual, remova a especificação mínima da plataforma de CPU definindo-a como automática antes de atualizar os rótulos de afinidade de nó da VM.
Os nós de locatário individual não são compatíveis com instâncias de VM preemptivas.
Para informações sobre as limitações do uso de discos SSD locais em nós de locatário individual, consulte Permanência de dados do SSD local.
Para informações sobre como o uso de GPUs afeta a migração em tempo real, consulte as limitações da migração em tempo real.
Os nós de locatário individual com GPUs não oferecem suporte a VMs sem GPUs.
Somente os nós de locatário individual N1, N2, N2D e N4 são compatíveis com a alocação excessiva de CPUs.
As VMs C3, C3D, C4, C4A, C4D e N4 são programadas com alinhamento à arquitetura NUMA do nó de locatário individual. O agendamento de formatos de VM NUMA e sub-NUMA completos no mesmo nó pode levar à fragmentação, em que um formato maior não pode ser executado enquanto vários formatos menores que totalizam os mesmos requisitos de recursos podem.
Os nós de locatário individual C3 e C4 exigem que as VMs tenham a mesma proporção de vCPU para memória que o tipo de nó. Por exemplo, não é possível colocar uma VM
c3-standardem um tipo de nó-highmem.Não é possível atualizar a política de manutenção em um grupo de nós ativo.
A seguir
Saiba como criar, configurar e consumir nós de locatário individual.
Saiba como sobrecarregar CPUs em VMs de locatário individual.
Saiba mais sobre o modelo de licenças adquiridas pelo usuário (BYOL).
Consulte nossas práticas recomendadas para o uso de nós de locatário individual para executar cargas de trabalho de VM.