Die in diesem Dokument vorgestellten Strategien zur Notfallwiederherstellung (Disaster Recovery, DR) für Microsoft SQL Server richten sich an Architekten und Technikexperten, die für Design und Implementierung der Notfallwiederherstellung in Google Cloudverantwortlich sind.
Datenbanken können aus verschiedenen Gründen nicht mehr verfügbar sein, beispielsweise aufgrund von Hardware- oder Netzwerkfehlern. Damit auch bei Fehlerzuständen ein kontinuierlicher Datenbankzugriff möglich ist, gibt es eine sekundäre Datenbank, die ein Replikat einer primären Datenbank ist. Wenn sich die sekundäre Datenbank an einem anderen Standort als die primäre befindet, steigt die Wahrscheinlichkeit, dass sie bei einem Ausfall der primären Datenbank verfügbar ist.
Falls die primäre Datenbank nicht mehr verfügbar ist, stellt Ihre geschäftskritische Anwendung eine Verbindung zu einer sekundären Datenbank mit dem zuletzt bekannten konsistenten Datenzustand her. So können Dienste mit minimaler oder gar keiner Ausfallzeit weiterhin für Ihre Nutzer bereitgestellt werden.
Das Verfügbarmachen einer sekundären Datenbank bei einem Fehler in der primären Datenbank wird als Datenbank-Notfallwiederherstellung bezeichnet. Die sekundäre Datenbank übernimmt die Wiederherstellung, wenn die primäre Datenbank nicht mehr verfügbar ist. Idealerweise sollte die sekundäre Datenbank im exakt gleichen konsistenten Zustand sein wie die primäre Datenbank zum Zeitpunkt ihres Ausfalls oder nur ein minimaler Satz an zuletzt erfolgten Transaktionen gegenüber der primären Datenbank fehlen.
Datenbank-DR ist ein unverzichtbares Feature für Unternehmenskunden. Dabei spielt die Geschäftskontinuität für geschäftskritische Anwendungen die entscheidende Rolle. Eine geschäftskritische Anwendung generiert beispielsweise Einnahmen (E-Commerce), bietet kontinuierlich zuverlässige Dienste (Verwaltung von Flügen und Kraftwerken) oder unterstützt lebenserhaltende Funktionen (Patientenmonitoring). Bei all diesen Beispielen ist es von größter Wichtigkeit, dass eine als geschäftskritisch eingestufte Anwendung kontinuierlich verfügbar ist.
Die meisten Systeme zur Datenbankverwaltung bieten Funktionen zur Notfallwiederherstellung, darunter auch Microsoft SQL Server. In diesem Architekturdokument erfahren Sie, wie Sie die von SQL Server bereitgestellten Features zur Notfallwiederherstellung im Kontext von Google Cloudimplementieren.
Terminologie
In den folgenden Abschnitten werden die in diesem Dokument verwendeten Begriffe erklärt.
Allgemeine Architektur zur Datenwiederherstellung
Das folgende Diagramm veranschaulicht die Topologie der allgemeinen Architektur zur Datenwiederherstellung.
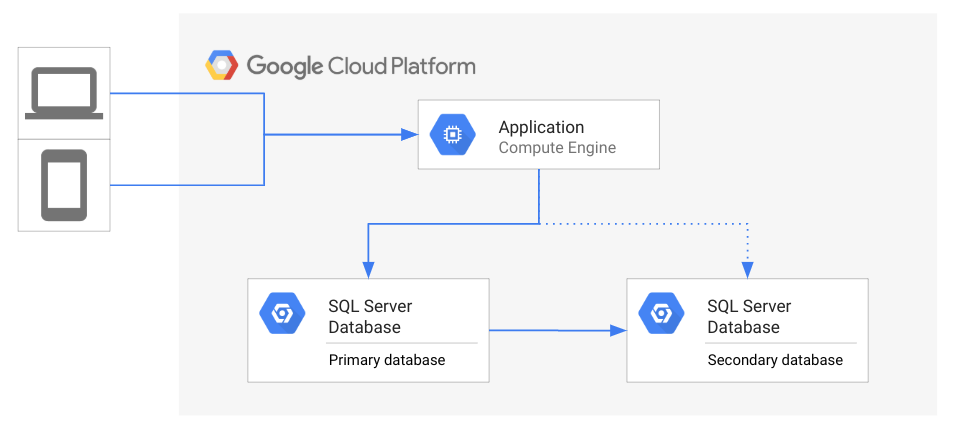
Im obigen Diagramm greift eine Anwendung auf eine primäre Datenbank zu, während eine sekundäre Datenbank bereitsteht und den Zustand der primären Datenbank spiegelt. Clients greifen auf die Anwendung zu, die auf Google Cloudausgeführt wird.
Wenn die primäre Datenbank nicht mehr verfügbar ist, müssen Datenbankadministratoren oder das operative Team gegebenenfalls den Prozess der Notfallwiederherstellung in Gang setzen. Ist die Notfallwiederherstellung für die Datenbank einmal eingeleitet, wird die Anwendung mit der sekundären Datenbank neu verbunden. Nachdem die Verbindung hergestellt wurde, kann die Anwendung ihre Clients wieder bedienen. Im Idealfall steht die Anwendung so schnell wie möglich mit der sekundären Datenbank zur Verfügung, sodass Clients erst gar keinen Ausfall wahrnehmen. Statt eine Notfallwiederherstellung auszulösen, könnte auch gewartet werden, bis der Zugriff auf die primäre Datenbank wieder möglich ist. Beispielsweise geht es bei einem kurzzeitigen Problem unter Umständen schneller, dieses zu lösen, anstatt ein Failover durchzuführen.
Primäre und sekundäre Datenbanken
Eine primäre Datenbank bietet Persistenzdienste für die Zustandsverwaltung von Anwendungen und wird zu diesem Zweck von einer oder mehreren Anwendungen aufgerufen. Eine sekundäre Datenbank ist mit einer primären Datenbank verknüpft und enthält ein Replikat der primären Datenbank. Idealerweise stimmt der Inhalt der sekundären Datenbank zu jedem Zeitpunkt genau mit dem Inhalt der primären Datenbank überein. In vielen Fällen ist die sekundäre Datenbank nicht ganz auf dem Stand der primären Datenbank, weil beim Anwenden von Transaktionsänderungen aus der primären Datenbank Verzögerungen entstehen. In Abhängigkeit von der Datenbanktechnologie können mehrere sekundäre Datenbanken mit einer primären Datenbank verknüpft werden. Die Verknüpfung mehrerer sekundärer Datenbanken mit einer primären Datenbank wird von SQL Server unterstützt.
Notfallwiederherstellung
Wenn eine primäre Datenbank nicht mehr verfügbar ist, wird die Rolle der sekundären Datenbank während der Notfallwiederherstellung geändert, sodass sie zur primären Datenbank wird. Sind mehrere sekundäre Datenbanken vorhanden, wird eine dieser Datenbanken manuell oder auf Basis einer Liste mit bevorzugten Failover-Kandidaten ausgewählt. Anwendungen müssen wieder eine Verbindung zur neuen primären Datenbank herstellen, um weiterhin auf ihren eigenen Zustand zugreifen zu können. Wenn die neue primäre Datenbank nicht dem letzten bekannten Zustand der früheren primären Datenbank entspricht, startet die Anwendung von einem früheren Zustand (auch als Flashback bezeichnet).
Es ist wichtig, dass für jede primäre Datenbank immer mindestens eine sekundäre Datenbank vorhanden ist. Sorgen Sie daher nach einer Notfallwiederherstellung dafür, dass eine neue sekundäre Datenbank für zukünftige Notfallwiederherstellungsszenarien eingerichtet wird.
Failover, Switchover und Fallback
Der Rollenwechsel zwischen primären und sekundären Datenbanken kann auf verschiedene Arten erfolgen:
- Failover: Der Vorgang, bei dem eine sekundäre Datenbank die Rolle der neuen primären Datenbank übernimmt und alle Anwendungen mit ihr verbunden werden. Zu einem Failover kommt es wegen der Nichtverfügbarkeit einer primären Datenbank. Je nach Konfiguration kann das Failover automatisch oder manuell ausgelöst werden.
- Switchover: Im Gegensatz zum Failover wird ein Switchover von einer primären Datenbank auf eine sekundäre Datenbank (neue primäre Datenbank) absichtlich ausgelöst, etwa für erste Tests oder geplante Wartungsarbeiten. Testen Sie Ihr System zur Notfallwiederherstellung mit einem regelmäßigen Switchover, um die Zuverlässigkeit dauerhaft zu sicherzustellen.
- Fallback: Ein Fallback kehrt den Vorgang um, sodass die neue primäre Datenbank nach der Reparatur der alten primären Datenbank wieder zur sekundären Datenbank wird. Ein Fallback wird absichtlich ausgelöst, um den Zustand wiederherzustellen, der vor dem Einleiten des Failovers oder Switchovers gegeben war. Dies ist nicht unbedingt erforderlich, kann jedoch aufgrund von Notfallwiederherstellungsanforderungen wie dem Standort oder den verfügbaren Ressourcen erfolgen.
Google Cloud Zonen und Regionen
Ressourcen wie Datenbanken befinden sich in Google Cloud Zonen und Regionen, wobei jede Zone zu einer Region gehört. Eine Zone ist eine Single-Point-of-Failure-Domain. Es empfiehlt sich, eine hochverfügbare und fehlertolerante Ressource in mehreren Zonen innerhalb einer Region bereitzustellen.
Damit Sie vor dem Ausfall einer ganzen Region geschützt sind, sollten Sie multiregionale Strategien zur Notfallwiederherstellung entwickeln. So könnte sich beispielsweise die primäre Datenbank in einer anderen Region als die zugehörige sekundäre Datenbank befinden.
Aktiv/Passiv- und Aktiv/Aktiv-Modi
Eine primäre Datenbank ist eine Datenbank, die für Lese- und Schreibvorgänge (DML-Vorgänge) geöffnet ist, sodass die auf die Datenbank zugreifenden Anwendungen ihren eigenen Zustand verwalten können. Die primäre Datenbank wird als aktive Datenbank bezeichnet. Die zugehörige sekundäre Datenbank ist passiv, da sie die primäre Datenbank repliziert, den Anwendungen jedoch für Zustandsänderungsvorgänge nicht zur Verfügung steht. Nach einem Failover oder Switchover wird die sekundäre Datenbank zur neuen primären Datenbank und damit zur aktiven Datenbank.
Sowohl die primäre als auch die sekundäre Datenbank können aktive Datenbanken sein, wenn die Datenbanktechnologie dieses Feature, den sogenannten Aktiv/Aktiv-Modus, unterstützt. In diesem Szenario können Anwendungen auf die eine oder die andere Datenbank zugreifen, da beide Datenbanken für die Zustandsverwaltung verfügbar sind. Falls nur eine der aktiven Datenbanken ausfällt, ist für die Notfallwiederherstellung im Aktiv-Aktiv-Modus kein Failover erforderlich. Wenn eine aktive Datenbank nicht verfügbar ist, bleibt die andere aktive Datenbank weiterhin verfügbar. Der Aktiv/Aktiv-Modus wird in diesem Artikel nicht behandelt, da SQL Server diesen Modus nicht unterstützt.
Hot-, Warm- und Cold-Standby-Modus sowie kein Standby
Damit die primäre Datenbank die aktive Datenbank ist, muss sie in Betrieb sein und DML-Anweisungen ausführen können. Die sekundäre Datenbank muss nicht ausgeführt werden und kann heruntergefahren sein. Wenn sie nicht ausgeführt wird, nimmt die Wiederherstellung nach einem Notfall mehr Zeit in Anspruch, da die neue primäre Datenbank zuerst in einen aktiven Zustand versetzt werden muss, bevor sie die Rolle der neuen primären Datenbank annehmen kann.
Die sekundäre Datenbank kann auf verschiedene Arten eingerichtet werden:
- Hot-Standby: Die sekundäre Datenbank ist einsatzbereit und Clients können eine Verbindung zu ihr herstellen. Die letzte verfügbare Änderung aus der primären Datenbank wird immer angewendet, sobald sie verfügbar ist.
- Warm-Standby: Eine sekundäre Datenbank ist einsatzbereit, es wurden jedoch unter Umständen noch nicht alle Änderungen aus der primären Datenbank angewendet.
- Cold-Standby: Eine sekundäre Datenbank wird nicht ausgeführt. Diese muss zuerst gestartet und dann mit dem letzten verfügbaren Zustand synchronisiert werden.
- Kein Standby: Die Datenbanksoftware muss zuerst installiert und anschließend gestartet werden, bevor alle Änderungen aus der primären Datenbank angewendet werden. Dieser Modus ist der kostengünstigste, da er keine Ressourcen verbraucht, wenn sie nicht benötigt werden. Im Vergleich zu den anderen Modi dauert es jedoch am längsten, bis eine neue primäre Datenbank verfügbar ist.
Strategien zur Notfallwiederherstellung
Die folgenden Abschnitte gehen auf Strategien zur Notfallwiederherstellung ein, die von Microsoft SQL Server unterstützt werden.
Dimensionen der Wiederherstellungsstrategie
Bei der Wahl oder Implementierung einer Strategie zur Notfallwiederherstellung für Datenbanken sind mehrere Schlüsseldimensionen zu berücksichtigen. Jede Dimension hat ein Spektrum und das Verhalten und die Erwartungen der Notfallwiederherstellungsstrategie hängen von der Auswahl der Punkte im Spektrum ab. Diese Schlüsseldimensionen sind:
- Recovery Point Objective (RPO): Die maximal zulässige Dauer, während der Daten aufgrund eines größeren Zwischenfalls bei der Anwendung verloren gehen können. Diese Dimension variiert je nach Verwendungszweck der Daten. Der RPO-Wert kann als Dauer in Sekunden, Minuten oder Stunden ab dem Zeitpunkt der Nichtverfügbarkeit der primären Datenbank oder als identifizierbarer Verarbeitungszustand (letzte vollständige Sicherung oder letzte inkrementelle Sicherung) ausgedrückt werden. Unabhängig davon, wie der RPO-Wert angegeben wird, muss die Notfallwiederherstellungsstrategie den jeweiligen Messwert umsetzen, damit die RPO-Anforderung erfüllt werden kann. Im anspruchsvollsten Fall muss die letzte festgeschriebene Transaktion verfügbar sein. Es darf also kein Verlust beim Umschalten von der primären Datenbank auf die sekundäre auftreten.
- Recovery Time Objective (RTO): Die maximal zulässige Zeitspanne, in der Ihre Anwendung offline sein kann. Dieser Wert wird normalerweise im Rahmen eines größeren Service Level Agreements festgelegt. Der RTO-Wert wird in der Regel als Dauer ab dem Zeitpunkt der Nichtverfügbarkeit der primären Datenbank ausgedrückt. So könnte beispielsweise festgelegt sein, dass die Anwendung innerhalb von fünf Minuten voll funktionsfähig sein muss. Im anspruchsvollsten Fall muss die Verfügbarkeit sofort gegeben sein, sodass Nutzer der Anwendung nicht bemerken, dass eine Notfallwiederherstellung stattgefunden hat.
- Single-Point-of-Failure-Domain: Sie entscheiden selbst, ob eine Region für Ihre Notfallwiederherstellungsanforderungen als Single-Point-of-Failure-Domain gilt. Ist eine Region für Sie eine Single-Point-of-Failure-Domain, muss die Notfallwiederherstellung so eingerichtet werden, dass zwei oder mehr Regionen daran beteiligt sind. Fällt die Region mit der primären Datenbank aus, übernimmt die sekundäre Datenbank in einer anderen Region die Rolle der neuen primären Datenbank. Wird bei der Single-Point-of-Failure-Domain von einer Zone ausgegangen, kann die Notfallwiederherstellung zonenübergreifend in einer einzelnen Region eingerichtet werden. Bei einem Zonenausfall greift die Notfallwiederherstellung auf eine zweite Zone zurück und stellt die neue primäre Datenbank darin zur Verfügung.
Bei der Entscheidung über diese Schlüsseldimensionen entscheiden Sie zwischen Kosten und Qualität. Je niedriger die RTO- und RPO-Werte sind, desto teurer kann die Notfallwiederherstellungslösung werden, da mehr aktive Ressourcen im Einsatz sind. In den folgenden Abschnitten werden verschiedene alternative Strategien zur Notfallwiederherstellung erläutert, die Punkte in den Dimensionen im Kontext der Microsoft SQL Server-Datenbank darstellen.
Strategien zur Notfallwiederherstellung für SQL Server
Unter Geschäftskontinuität und Datenbankwiederherstellung – SQL Server werden Verfügbarkeitsfeatures beschrieben, mit denen Sie Notfallwiederherstellungsstrategien implementieren können.
Grundlegendes
SQL Server kann sowohl unter Windows als auch unter Linux ausgeführt werden. Unter Linux werden jedoch nicht alle Verfügbarkeitsfeatures angeboten. SQL Server gibt es in mehreren Editionen, allerdings sind nicht alle Verfügbarkeitsfeatures in jeder Edition verfügbar.
Bei SQL Server wird zwischen Instanzen und Datenbanken unterschieden. Eine Instanz ist die ausführende SQL Server-Software, während eine Datenbank die Datenmenge ist, die von einer SQL Server-Instanz verwaltet wird.
Always On-Verfügbarkeitsgruppen
Always On-Verfügbarkeitsgruppen bieten Schutz auf Datenbankebene. Eine Verfügbarkeitsgruppe umfasst zwei oder mehr Replikate. Eines der Replikate ist das primäre Replikat mit Lese- und Schreibzugriff und die restlichen Replikate sind sekundäre Replikate, die Lesezugriff bereitstellen können. Jedes Datenbankreplikat wird von einer eigenständigen SQL Server-Instanz verwaltet. Eine Verfügbarkeitsgruppe kann eine oder mehrere Datenbanken umfassen. Wie viele Datenbanken in einer Verfügbarkeitsgruppe enthalten sein können und wie viele sekundäre Replikate unterstützt werden, hängt von der SQL Server-Edition ab. Auf alle Datenbanken in einer Verfügbarkeitsgruppe werden gleichzeitig dieselben Lebenszyklusänderungen angewendet. Verfügbarkeitsgruppen implementieren den Aktiv/Passiv-Modus, da nur die primäre Datenbank Schreibzugriff unterstützt.
Bei einem Failover wird ein sekundäres Replikat zum neuen primären Replikat. Da eine Verfügbarkeitsgruppe eigenständige SQL Server-Instanzen umfasst, sind alle in Transaktionslogs erfassten Vorgänge in den Replikaten verfügbar. Alle Änderungen, die nicht in einem Transaktionslog erfasst wurden, müssen manuell synchronisiert werden, beispielsweise SQL Server-Anmeldungen auf Instanzebene oder SQL Server-Agent-Jobs. Damit Schutz auf Datenbankebene und für SQL Server-Instanzen sichergestellt ist, müssen Sie Failover-Clusterinstanzen (FCI) einrichten. Diese Bereitstellungsarchitektur wird später im Abschnitt "Always On-Failover-Clusterinstanz" erläutert.
Mithilfe eines Listeners können Sie Anwendungen vor Rollenwechseln abschirmen. Ein Listener unterstützt Anwendungen, die eine Verbindung zur Verfügbarkeitsgruppe herstellen. Anwendungen wissen zu keinem Zeitpunkt, welche SQL Server-Instanzen die primäre Datenbank oder die sekundären Replikate verwalten. Listener setzen voraus, dass Clients mindestens die .NET-Version 3.5 mit einem Update oder Version 4.0 oder höher verwenden (siehe Geschäftskontinuität und Datenbankwiederherstellung – SQL Server).
Damit Verfügbarkeitsgruppen ihre Funktionalität bereitstellen können, müssen sie auf zugrunde liegende Abstraktionsebenen zurückgreifen. Verfügbarkeitsgruppen werden in einem Windows Server-Failover-Cluster (WSFC) ausgeführt, wie unter Windows Server Failover Clustering mit SQL Server beschrieben. Alle Knoten, auf denen SQL Server-Instanzen ausgeführt werden, müssen zum selben WSFC gehören.
Transaktionen werden von der primären Datenbank an alle sekundären Replikate gesendet. Zum Senden von Transaktionen gibt es zwei Modi: synchron und asynchron. Sie können jedes Replikat unabhängig für die Verwendung des einen oder anderen Modus konfigurieren. Im synchronen Sendemodus ist die Transaktion in der primären Datenbank nur dann erfolgreich, wenn sie auch in allen synchron verknüpften sekundären Replikaten erfolgreich ist. Im asynchronen Modus kann die Transaktion in der primären Datenbank erfolgreich sein, auch wenn sie nicht auf alle sekundären Replikate angewendet wurde.
Die Wahl des Sendemodus beeinflusst die möglichen RTO- und RPO-Werte sowie den Standby-Modus. Wenn beispielsweise Transaktionen im synchronen Modus an alle Replikate gesendet werden, befinden sich alle Replikate im exakt gleichen Zustand. Der anspruchsvollste RPO-Wert (zuletzt erfolgte Transaktion) wird erreicht, da alle Replikate vollständig synchronisiert sind. Die sekundären Replikate sind Hot-Standbys, sodass jedes dieser Replikate sofort als primäre Datenbank verwendet werden kann.
Das Failover kann automatisch oder manuell erfolgen. Ein automatisches Failover ist möglich, wenn alle Replikate vollständig synchronisiert sind. Im obigen Beispiel ist dies möglich, da alle Replikate immer vollständig synchronisiert sind.
Die folgende Abbildung zeigt eine Always On-Verfügbarkeitsgruppe in einer einzelnen Region.
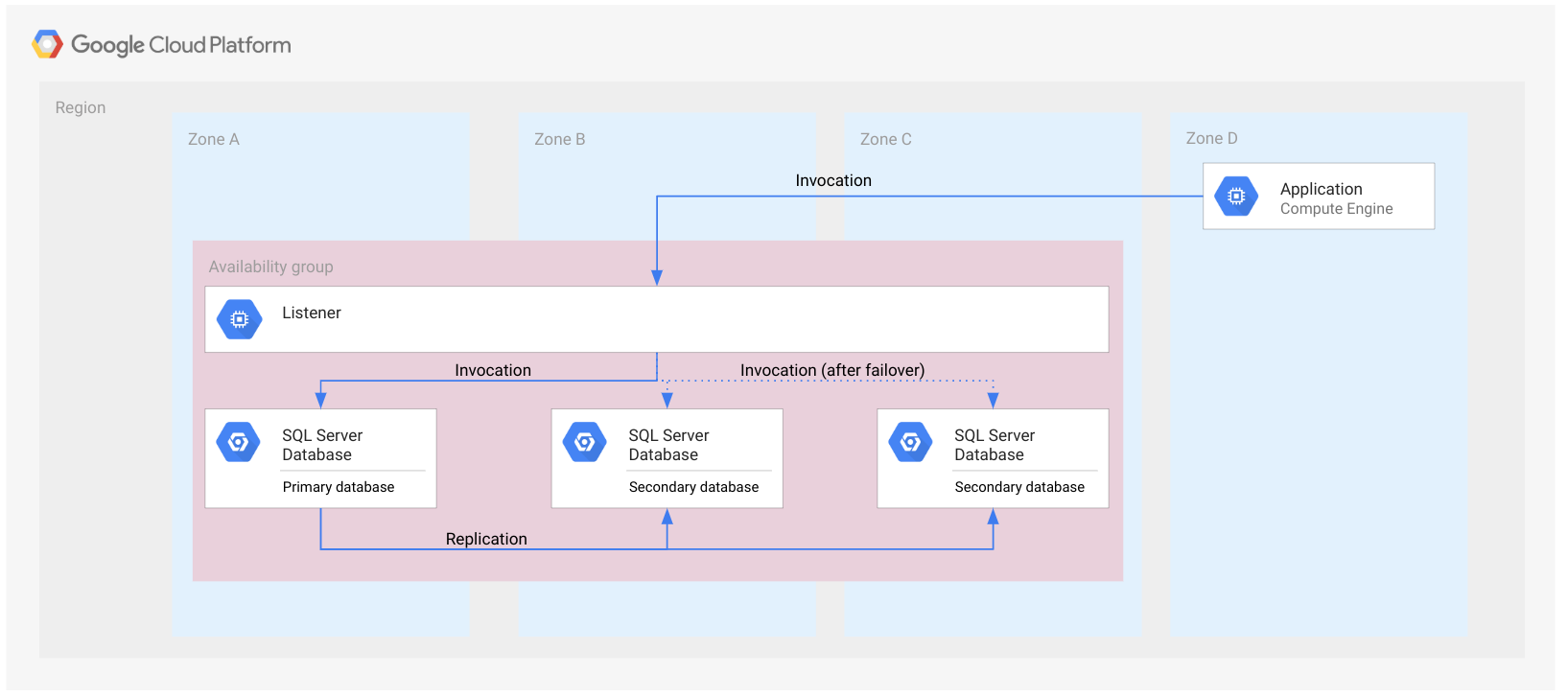
Die Verfügbarkeitsgruppe wird als Rechteck dargestellt, das sich über Zonen erstreckt. Damit soll nur veranschaulicht werden, dass alle Datenbanken derselben Verfügbarkeitsgruppe angehören. Die Verfügbarkeitsgruppe ist keine Cloudressource und daher nicht in einem Knoten oder einem anderen Ressourcentyp implementiert.
Always On-Failover-Clusterinstanz
Zum Schutz vor Knotenausfällen können Sie Failover-Clusterinstanzen (FCI) anstelle von eigenständigen SQL Server-Instanzen verwenden. In diesem Szenario gibt es zwei oder mehr Knoten, auf denen SQL Server-Instanzen zum Verwalten einer Datenbank (primär oder sekundär) ausgeführt werden. Die Knoten, die eine Datenbank verwalten, bilden einen Failover-Cluster. Auf einem der Clusterknoten wird aktiv eine SQL Server-Instanz ausgeführt, auf den anderen Knoten dagegen nicht. Wenn der Knoten mit der SQL Server-Instanz ausfällt, startet ein anderer Knoten im Cluster eine SQL Server-Instanz und übernimmt die Verwaltung der Datenbank (Knoten-Failover). Durch dieses automatische Starten einer SQL Server-Instanz wird Hochverfügbarkeit bereitgestellt.
Der FCI-Cluster erscheint wie eine Einheit und Clients, die auf den Cluster zugreifen, nehmen das Failover zwischen Knoten gar nicht oder allenfalls als eine kurze Phase der Nichtverfügbarkeit wahr. Bei einem Knoten-Failover tritt kein Datenverlust auf. Alle in der fehlgeschlagenen SQL Server-Instanz ausgeführten Vorgänge werden in eine andere SQL Server-Instanz im selben Cluster verschoben. Beispielsweise werden SQL Server-Agent-Jobs oder verknüpfte Server in eine andere Instanz verschoben.
FCI-Clusterknoten können in verschiedenen Google Cloud Zonen eingerichtet werden. Diese Architektur bietet nicht nur bei Knotenausfällen, sondern auch bei Zonenausfällen Hochverfügbarkeit. Eine exemplarische Bereitstellung dieser Strategie wird im Abschnitt „Bereitstellungsalternativen für Notfallwiederherstellung“ erläutert.
Obwohl verschiedene Knoten dieselbe Datenbank verwalten und gemeinsam nutzen, ist für die Knoten eines FCI-Clusters kein gemeinsamer Speicher erforderlich. SQL Server verwendet die Funktion "Direkte Speicherplätze" (Storage Spaces Direct, S2D), um Datenbanken auf dedizierten Knotenlaufwerken zu verwalten. Weitere Informationen finden Sie unter SQL Server-Failover-Clusterinstanzen konfigurieren.
Das Beispiel aus dem vorherigen Abschnitt Always On-Verfügbarkeitsgruppen mit Failover-Clusterinstanzen anstelle von eigenständigen SQL Server-Instanzen wird in der folgenden Abbildung dargestellt. Jede FCI enthält genau eine aktive SQL Server-Instanz, die die Datenbank verwaltet.
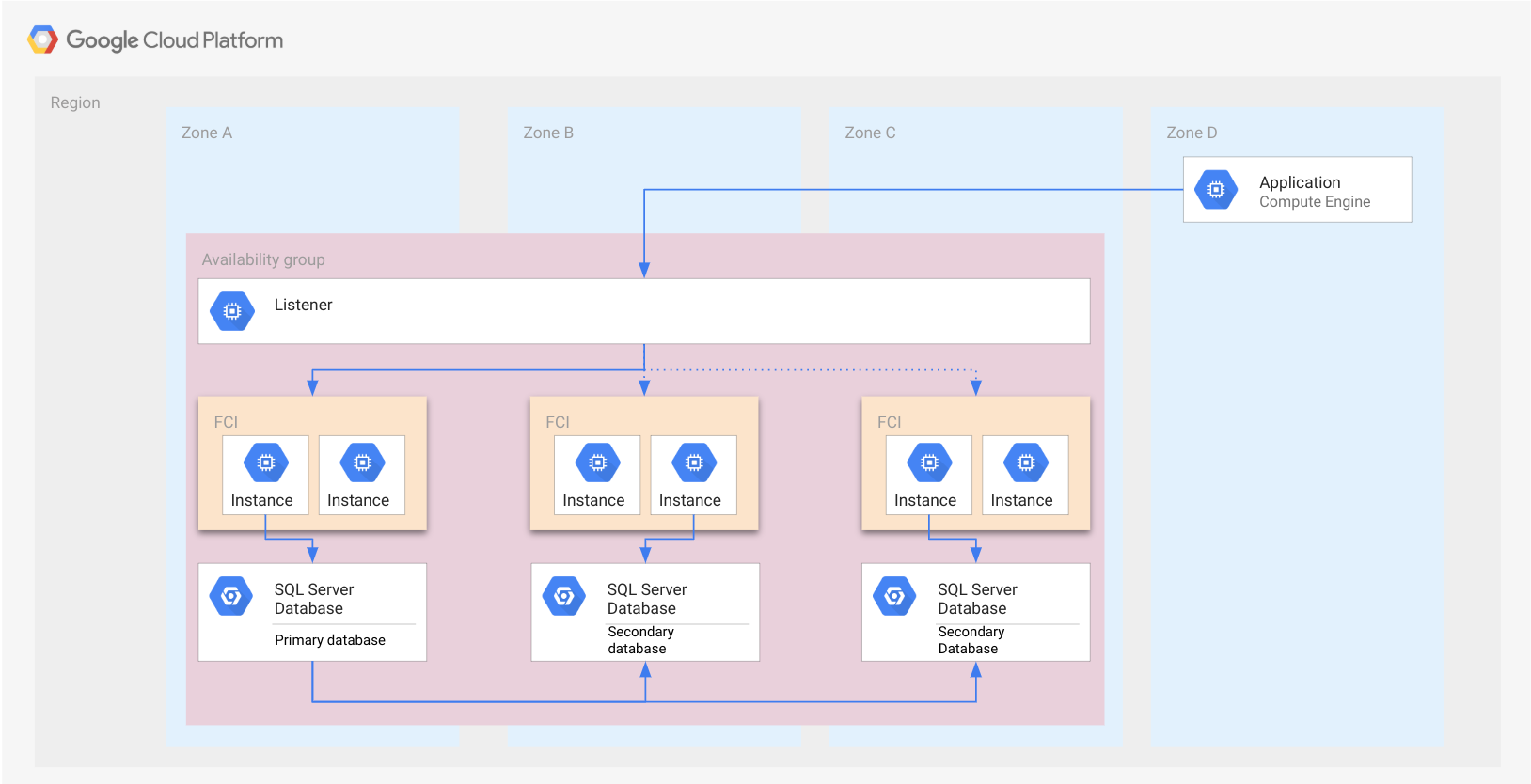
Wie die Verfügbarkeitsgruppe wird auch die FCI als Rechteck dargestellt. Damit soll lediglich veranschaulicht werden, dass die Knoten alle derselben FCI angehören. Eine FCI ist keine Cloud-Ressource und daher nicht in einem Knoten oder einem anderen Ressourcentyp implementiert.
Ausführlichere Informationen finden Sie unter Always On-Failover-Clusterinstanzen (SQL Server).
Verteilte Verfügbarkeitsgruppen
Verteilte Verfügbarkeitsgruppen sind ein besonderer Typ von Verfügbarkeitsgruppe. Eine verteilte Verfügbarkeitsgruppe umfasst zwei Verfügbarkeitsgruppen, von denen eine als primäre Verfügbarkeitsgruppe und die andere als sekundäre Verfügbarkeitsgruppe dient. Verteilte Verfügbarkeitsgruppen können Transaktionen sowohl im synchronen als auch asynchronen Modus von der primären Verfügbarkeitsgruppe an die sekundäre Verfügbarkeitsgruppe weiterleiten.
Obwohl jede der Verfügbarkeitsgruppen eine eigene primäre Datenbank hat, handelt es sich hierbei nicht um eine Aktiv/Aktiv-Bereitstellung. Nur die primäre Datenbank der primären Verfügbarkeitsgruppe kann Schreibvorgänge empfangen. Die primäre Datenbank der sekundären Verfügbarkeitsgruppe wird als Forwarder bezeichnet. Der Forwarder empfängt die Transaktionen von der primären Verfügbarkeitsgruppe und leitet sie an die sekundären Datenbanken der sekundären Verfügbarkeitsgruppe weiter. Ein Failover von der primären Verfügbarkeitsgruppe auf die sekundäre Verfügbarkeitsgruppe würde die primäre Datenbank der neuen primären Verfügbarkeitsgruppe für Schreibvorgänge zugänglich machen.
Die primären und sekundären Verfügbarkeitsgruppen müssen sich weder am selben Standort noch auf demselben Betriebssystem befinden. Allerdings muss für jede Verfügbarkeitsgruppe ein Listener installiert sein. Die verteilte Verfügbarkeitsgruppe selbst hat keinen Listener. Verteilte Verfügbarkeitsgruppen setzen nicht voraus, dass sich die zwei Verfügbarkeitsgruppen im selben WSFC befinden. Die gesamte Funktionalität, die zum Ausführen verteilter Verfügbarkeitsgruppen erforderlich ist, wird von der SQL Server-Funktionalität abgedeckt und erfordert keine zusätzliche Installation von zugrunde liegenden Komponenten.
Eine verteilte Verfügbarkeitsgruppe umfasst genau zwei Verfügbarkeitsgruppen. Eine Verfügbarkeitsgruppe kann Teil von zwei verteilten Verfügbarkeitsgruppen sein. Dies ermöglicht zwei unterschiedliche Topologien: eine Verkettungstopologie, die von Verfügbarkeitsgruppe zu Verfügbarkeitsgruppe über mehrere Standorte hinweg verläuft, und eine baumartige Topologie, bei der die primäre Verfügbarkeitsgruppe Teil von zwei verschiedenen und getrennten verteilten Verfügbarkeitsgruppen ist.
Verteilte Verfügbarkeitsgruppen sind das wichtigste Mittel zur Implementierung der Notfallwiederherstellung auf verschiedenen Betriebssystemen. Beispielsweise kann die primäre Verfügbarkeitsgruppe unter Windows und eine entsprechende zweite Verfügbarkeitsgruppe unter Linux eingerichtet werden, wobei beide Verfügbarkeitsgruppen eine verteilte Verfügbarkeitsgruppe bilden.
Das folgende Diagramm zeigt zwei Verfügbarkeitsgruppen, die Teil einer verteilten Verfügbarkeitsgruppe sind.
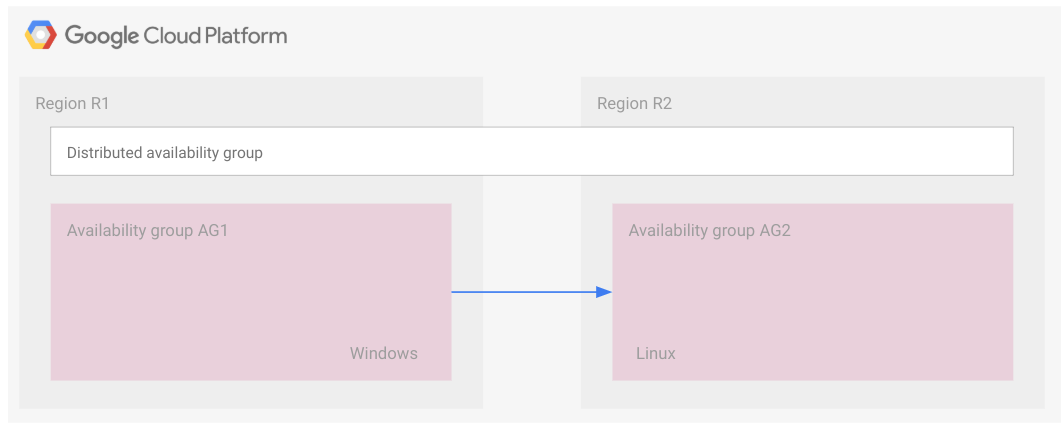
Verfügbarkeitsgruppe 1 ist die primäre Verfügbarkeitsgruppe und Verfügbarkeitsgruppe 2 die sekundäre.
Wie die FCI wird auch die verteilte Verfügbarkeitsgruppe als Rechteck dargestellt. Damit soll lediglich veranschaulicht werden, dass die Verfügbarkeitsgruppen alle derselben verteilten Verfügbarkeitsgruppe angehören. Eine verteilte Verfügbarkeitsgruppe ist wie eine reguläre Verfügbarkeitsgruppe keine Cloudressource und daher nicht in einem Knoten oder einem anderen Ressourcentyp implementiert.
Weitere Informationen finden Sie unter Verteilte Verfügbarkeitsgruppen.
Logversand
Der Transaktionslogversand ist ein SQL Server-Verfügbarkeitsfeature (dort "Protokollversand" genannt), wenn die RTO- und RPO-Werte nicht zu strikt sind (also kein niedriger RTO-Wert und/oder RPO der zuletzt erfolgten Transaktion), da die Zustandsabweichung zwischen einer primären Datenbank und ihrer sekundären Datenbank sonst erheblich größer ist. Die Abweichung ist in Bezug auf den Zustand größer, da eine Transaktionslogdatei viele Zustandsänderungen enthält. Die Abweichung ist auch in Bezug auf die Verzögerungszeit größer, da Transaktionslogdateien asynchron versendet werden und in ihrer Gesamtheit auf eine sekundäre Datenbank angewendet werden müssen.
Transaktionslogdateien werden von der primären Datenbank erstellt und beispielsweise in Cloud Storage gesichert. Jede Transaktionslogdatei wird in jede sekundäre Datenbank kopiert und auf diese angewendet. Da die sekundäre Datenbank nicht ganz auf dem Stand der primären Datenbank ist, sind die Datenbanken im Warm-Standby-Modus. Objekte und Änderungen, die nicht in Transaktionslogs erfasst werden, müssen manuell auf die sekundären Datenbanken angewendet werden, um eine vollständige Synchronisierung ohne Verlust sicherzustellen.
Der SQL Server-Agent automatisiert den gesamten Erstell-, Kopier- und Anwendungsprozess von Transaktionslogs. Der Logversand muss für jede Datenbank einzeln eingerichtet werden. Wenn eine Verfügbarkeitsgruppe mehr als eine Datenbank verwaltet, sind entsprechend viele Logversandprozesse einzurichten.
Im Falle eines Fehlers muss der Notfallwiederherstellungsprozess manuell eingeleitet werden, da eine Automatisierung nicht unterstützt wird. Darüber hinaus wird der Clientzugriff nicht durch einen Listener von der primären Datenbank und den sekundären Datenbanken abstrahiert. Bei einem Failover müssen Clients den Rollenwechsel einer Datenbank von der sekundären Rolle zur neuen primären Rolle selbst handhaben können und nach der Notfallwiederherstellung eine Verbindung zur neuen primären Rolle herstellen. Es besteht jedoch die Möglichkeit, separate Abstraktionen unabhängig von SQL Server-Instanzen zu erstellen, beispielsweise Floating-IP-Adressen (siehe Best Practices für Floating-IP-Adressen).
Da der Logversand zum Teil ein manueller Prozess ist, lässt sich das Anwenden kopierter Logdateien auf die sekundären Datenbanken bewusst verzögern (im Gegensatz zu Verfügbarkeitsgruppen und verteilten Verfügbarkeitsgruppen, bei denen Änderungen sofort angewendet werden). Sie könnten dies beispielsweise tun, um das Anwenden von Datenänderungsfehlern aus der primären Datenbank auf die sekundäre Datenbank zu verhindern, bis die Datenänderungsfehler behoben sind. In diesem Fall kann eine sekundäre Datenbank, auf die noch kein Datenänderungsfehler angewendet wurde, zur primären Datenbank werden, bis der Datenänderungsfehler behoben ist. Danach kann die normale Verarbeitung fortgesetzt werden.
Wie bei verteilten Verfügbarkeitsgruppen können Sie den Logversand für plattformübergreifende Lösungen verwenden, bei denen beispielsweise die primäre Datenbank unter Linux und die sekundären Datenbanken unter Linux und Windows ausgeführt werden.
Das folgende Diagramm veranschaulicht eine plattformübergreifende Bereitstellung mit Logversand. In dieser Topologie gibt es keine regionsübergreifende gemeinsame Konfiguration wie beispielsweise eine verteilte Verfügbarkeitsgruppe.
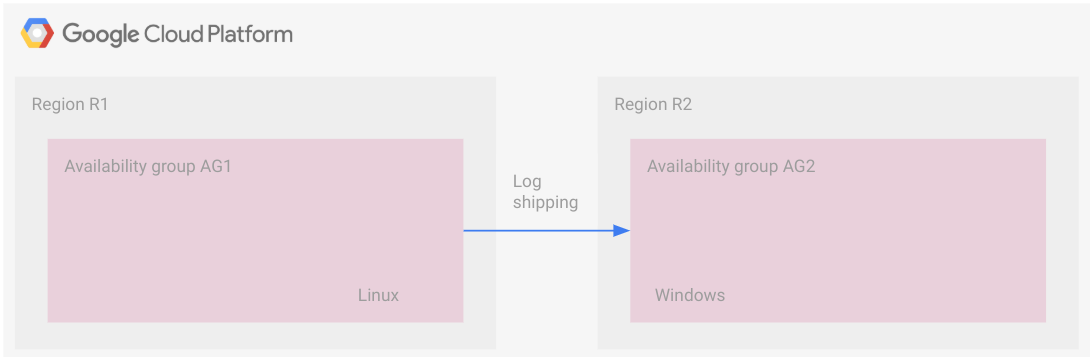
Die Verfügbarkeitsgruppen befinden sich in separaten Regionen, wobei eine unter Linux und die andere unter Windows ausgeführt wird.
Näheres zum Logversand in SQL Server finden Sie unter Informationen zum Protokollversand (SQL Server).
SQL Server-Verfügbarkeitsfeatures kombinieren
Sie können SQL Server-Verfügbarkeitsfeatures in verschiedenen Kombinationen bereitstellen. Im vorherigen Anwendungsfall wurde beispielsweise der Logversand mit verschiedenen Verfügbarkeitsgruppen verwendet, die auf verschiedenen Betriebssystemen installiert waren.
Im Folgenden sind die möglichen Kombinationen von SQL Server-Verfügbarkeitsfeatures aufgeführt:
- Verwenden Sie den Logversand zwischen Verfügbarkeitsgruppen, die auf demselben Betriebssystem installiert sind.
- Kombinieren Sie eine primäre Verfügbarkeitsgruppe, die Failover-Clusterinstanzen verwendet, mit einer sekundären Verfügbarkeitsgruppe, die nur eigenständige SQL Server-Instanzen verwendet.
- Verwenden Sie eine verteilte Verfügbarkeitsgruppe für Regionen, die eng beieinanderliegen, und den Logversand für Regionen, die sich auf verschiedenen Kontinenten befinden.
Dies sind nur einige der möglichen Kombinationen von SQL Server-Verfügbarkeitsfeatures.
Dank der Flexibilität, die SQL Server-Verfügbarkeitsfeatures bieten, kann eine Strategie zur Notfallwiederherstellung genau auf die jeweiligen Anforderungen zugeschnitten werden.
SQL Server-Replikation
Die SQL Server-Replikation wird im Allgemeinen nicht als Verfügbarkeitsfeature angesehen. Dennoch soll in diesem Abschnitt kurz erläutert werden, wie sich dieses Feature für die Notfallwiederherstellung einsetzen lässt.
Mithilfe des Replikationsfeatures können Sie Replikate von Datenbanken erstellen und verwalten. Verschiedene Arten von SQL Server-Agents arbeiten zusammen, um Änderungen zu erfassen, zu übertragen und auf die Replikate anzuwenden. Dieser Prozess ist asynchron und Replikate sind üblicherweise in unterschiedlichem Umfang nicht auf dem Stand der replizierten Datenbank.
Nehmen Sie als Beispiel ein Replikat einer Produktionsdatenbank. In Bezug auf die Notfallwiederherstellung ist die Produktionsdatenbank die primäre Datenbank und das Replikat die sekundäre. Das SQL Server-Replikationsfeature weiß nicht, dass die Datenbanken im Zuge der Notfallwiederherstellung unterschiedliche Rollen annehmen. Daher bietet die Replikation keine Vorgänge zur Unterstützung des Notfallwiederherstellungsprozesses wie etwa Rollenwechsel. Der Notfallwiederherstellungsprozess muss getrennt von der SQL Server-Funktionalität implementiert und von der implementierenden Organisation ausgeführt werden, da es keine Abstraktionen für den Clientzugriff gibt.
Versand von Sicherungsdateien
Der Versand von Sicherungsdateien ist eine weitere Strategie zur Implementierung der Notfallwiederherstellung. Ein Standardansatz zum Einrichten und kontinuierlichen Aktualisieren einer sekundären Datenbank besteht darin, eine erste vollständige Sicherung der primären Datenbank und anschließend inkrementelle Sicherungen dieser Datenbank zu erstellen. Alle inkrementellen Sicherungen werden in der richtigen Reihenfolge auf sekundäre Datenbanken angewendet. In Abhängigkeit von der Häufigkeit der inkrementellen Sicherungen und dem Speicherort der Sicherungsdateien (globaler Speicherort oder zwischen Speicherorten kopiert) gibt es viele Variationen dieses Ansatzes.
Bei dieser Strategie ist kein SQL Server-Verfügbarkeitsfeature an der Replikation von Zustandsänderungen aus der primären Datenbank in eine sekundäre beteiligt. Der SQL Server-Agent, der beim Logversand verwendet wird, kommt nicht zum Einsatz.
Weitere Informationen finden Sie im Abschnitt Beispiel: Sicherungs- und Wiederherstellungsstrategie zur Notfallwiederherstellung.
Verglichen mit dem Replikationsansatz, der im vorherigen Abschnitt erläutert wurde, wird der Notfallwiederherstellungsprozess sowohl bei der Replikation als auch beim Versand von Sicherungsdateien außerhalb des SQL Server-Featuresets und getrennt von diesem implementiert. Aus der Sicht des Versands erfasster Änderungen ist die SQL Server-Replikation praktischer, da dieser Teil automatisch über SQL Server-Agents implementiert wird.
Hinweis zur Interaktion zwischen Datenbank- und Anwendungslebenszyklen
Ein Datenbank-Failover ist von den Anwendungen, die auf die Datenbank zugreifen, nicht völlig getrennt und unabhängig. Grundsätzlich gibt es zwei Fehlerszenarien.
Beim ersten Szenario bleibt die Anwendung betriebsbereit, während für die Datenbank ein Failover durchgeführt wird. Ab der Nichtverfügbarkeit der primären Datenbank bis zur Inbetriebnahme der neuen primären Datenbank können die Anwendungen überhaupt nicht auf die Datenbank zugreifen. Vorhandene Verbindungen brechen ab und es werden keine neuen Verbindungen hergestellt. Während dieser Zeit kann die Anwendung ihre Clients nicht bedienen, zumindest nicht dann, wenn dafür ein Datenbankzugriff erforderlich ist. Die Anwendungen müssen erkennen, wann die neue primäre Datenbank verfügbar ist, damit sie die normale Verarbeitung wieder aufnehmen können.
Anwendungen können einen Zustand außerhalb der Datenbank haben, beispielsweise in Caches des Hauptarbeitsspeichers. Die Anwendung stellt dann sicher, dass der Cache mit der neuen primären Datenbank konsistent (synchronisiert) ist. Wenn beim Failover keinerlei Transaktionen verloren gingen, ist der Cache möglicherweise ohne weiteres Zutun konsistent. Sind jedoch Transaktionen (Daten) beim Failover verloren gegangen, ist der Cache im Vergleich zur neuen primären Datenbank unter Umständen nicht konsistent. Ähnliches gilt für gemeinsame Zustände, wenn beispielsweise einige Daten in der Datenbank auch Teil von Nachrichten in Warteschlangen oder von Dateien im Dateisystem sind. Dieser Aspekt der Datenkonsistenz wird im vorliegenden Dokument nicht behandelt, da er nicht unmittelbar mit der Notfallwiederherstellung für Datenbanken zusammenhängt.
Im zweiten Szenario könnten eine oder mehrere Anwendungen gleichzeitig mit der primären Datenbank ausfallen. Wenn beispielsweise eine Region offline geht, ist ein Anwendungssystem, das in dieser Region ausgeführt wird, genauso wenig verfügbar wie die primäre Datenbank in derselben Region. In diesem Fall muss auch die Anwendung wiederhergestellt werden, nicht nur das primäre Datenbanksystem. Neben dem Notfallwiederherstellungsprozess für die Datenbank müssen Sie einen ähnlichen Wiederherstellungsprozess für die Anwendung einleiten. Die wiederhergestellte Anwendung muss eine Verbindung zur neuen primären Datenbank herstellen und neu konfiguriert werden (z. B. Floating-IP-Adressen). Eine Erläuterung der Anwendungswiederherstellung würde allerdings den Rahmen dieses Dokuments sprengen.
Beziehung zwischen Sicherungs- und Wiederherstellungsvorgängen und der Notfallwiederherstellung
Das Sichern einer Datenbank und die Notfallwiederherstellung für Datenbanken sind unabhängige und orthogonale Vorgänge. Der Zweck der Datenbanksicherung besteht darin, einen konsistenten Zustand wiederherstellen zu können, beispielsweise wenn eine Datenbank verloren geht bzw. beschädigt wird oder ein vorheriger Zustand aufgrund von Anwendungs- oder Programmfehlern wiederhergestellt werden muss.
Im folgenden Abschnitt wird erläutert, wie Sie Sicherungen als einen möglichen Mechanismus zum Implementieren der Notfallwiederherstellung für Datenbanken einsetzen können. In diesem Szenario kopieren Sie Sicherungsdateien an den Speicherort der sekundären Datenbank, damit die sekundäre Datenbank wiederhergestellt werden kann. Sicherungsdateien sind jedoch keine Voraussetzung für die Notfallwiederherstellung. In der obigen Erörterung der Verfügbarkeitsfeatures wurden Alternativen vorgestellt.
Hochverfügbarkeit und Notfallwiederherstellung
Hochverfügbarkeit und Notfallwiederherstellung haben eines gemeinsam: Sie stellen beide Lösungen für Datenbanken bereit, die nicht mehr verfügbar sind. Wenn eine primäre Datenbank ausfällt, wird eine sekundäre Datenbank zur neuen primären Datenbank, die konsistent und verfügbar ist.
Der Unterschied zwischen Hochverfügbarkeit und Notfallwiederherstellung besteht in der Single-Point-of-Failure-Domain. Hochverfügbarkeit schafft bei einem Ausfall innerhalb einer Region Abhilfe, beispielsweise wenn eine einzelne Zone oder ein Knoten fehlschlägt. Eine Hochverfügbarkeitslösung stellt eine neue primäre Datenbank in einer anderen Zone innerhalb derselben Region bereit. Darüber hinaus behebt eine Hochverfügbarkeitslösung auch Knotenfehler, nicht nur Datenbankfehler. Wenn ein Knoten fehlschlägt, auf dem eine SQL Server-Instanz ausgeführt wird, wird ein neuer Knoten bereitgestellt, auf dem eine neue SQL Server-Instanz ausgeführt wird (siehe Erläuterung im Abschnitt Always On-Failover-Clusterinstanz).
Die Notfallwiederherstellung umfasst mindestens zwei Regionen. Sie greift in dem Fall, dass eine ganze Region nicht mehr verfügbar ist. Durch die Notfallwiederherstellung kann eine neue primäre Datenbank in einer anderen Region bereitstellt werden.
Die Hochverfügbarkeitsfeatures von SQL Server unterstützen sowohl Hochverfügbarkeits- als auch Notfallwiederherstellungslösungen. Eine einzelne Verfügbarkeitsgruppe kann sich sowohl über die Zonen innerhalb einer Region als auch Regionen selbst erstrecken. Zum Implementieren von Hochverfügbarkeit kann eine Verfügbarkeitsgruppe Failover-Clusterinstanzen umfassen.
SQL Server kann Verfügbarkeitsgruppen innerhalb einer einzelnen Region für Hochverfügbarkeit und Zonenausfälle einrichten und mit regionenübergreifendem Logversand kombinieren, um eine Notfallwiederherstellung zu ermöglichen.
Bereitstellungsalternativen für Notfallwiederherstellung
In den folgenden Abschnitten werden einige Topologien zur Notfallwiederherstellung aufgezeigt, die neben den bisher erläuterten möglich sind. Diese Topologien erfüllen unterschiedliche RPO- und RTO-Anforderungen. Die Liste erhebt keinen Anspruch auf Vollständigkeit.
Intraregionale Notfallwiederherstellung und Hochverfügbarkeit
Diese Bereitstellung ist eine Variante einer Verfügbarkeitsgruppe mit Failover-Clusterinstanzen innerhalb einer Region, die aus drei Zonen besteht. In diesem Szenario dienen Zonen als Single-Point-of-Failure-Domain.
Im Vergleich zur oben gezeigten Bereitstellung besteht jede FCI aus drei Knoten, wobei jeder Knoten in einer anderen Zone ausgeführt wird. Der Vorteil dieser Konfiguration besteht darin, dass eine oder zwei beliebige Zonen ausfallen können, ohne dass ein Notfallwiederherstellungsprozess erforderlich ist.
Das folgende Diagramm veranschaulicht die Konfiguration.

Jede FCI erstreckt sich über alle Zonen und enthält eine ausgeführte SQL Server-Instanz, die auf die entsprechende Datenbank zugreift. Jede FCI enthält zwei weitere SQL Server-Instanzen, die nicht ausgeführt werden und gestartet werden können, wenn eine Zone fehlschlägt. Die Datenbanken werden zonenübergreifend dargestellt, da jede Datenbank die Laufwerke aller Knoten in einer bestimmten FCI verwendet. Eine Anwendung wird aus Gründen der Übersichtlichkeit nicht gezeigt.
Interregionale Notfallwiederherstellung: Regionenübergreifende Verfügbarkeitsgruppe
In diesem Szenario wird eine Verfügbarkeitsgruppe in einem Windows Server-Failover-Cluster und über zwei Regionen hinweg ausgeführt. Hier dienen Regionen als Single-Point-of-Failure-Domain.
Das folgende Diagramm veranschaulicht diese Konfiguration.

Zur Vermeidung potenzieller Latenzprobleme können Sie die Replikate in den Regionen R1 und R2 so konfigurieren, dass die R1-Replikate die synchrone Transaktionsweitergabe und die R2-Replikate die asynchrone Transaktionsweitergabe verwenden.
Interregionale Notfallwiederherstellung: Sicherungsdateiübertragung
In diesem Szenario kommt die Sicherungsdateiübertragung zum Einsatz. Zwei Verfügbarkeitsgruppen in zwei Regionen sind verknüpft. Da die Replikate jeder Verfügbarkeitsgruppe die Transaktionen synchron empfangen, befinden sich die sekundären Replikate jeder Region in einer Hot-Standby-Konfiguration.
Das folgende Diagramm veranschaulicht diese Konfiguration.
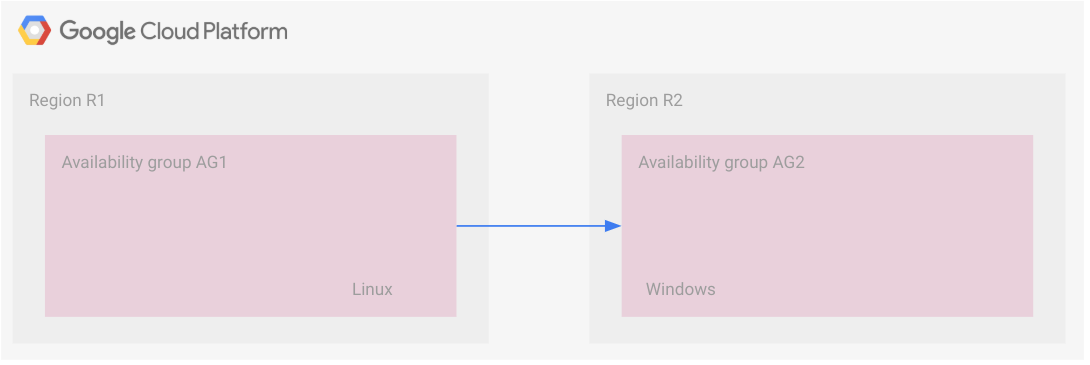
Die beiden Verfügbarkeitsgruppen sind jedoch durch die Sicherungsdateiübertragung verbunden. Die Verfügbarkeitsgruppe AG1 ist die primäre Verfügbarkeitsgruppe und die Verfügbarkeitsgruppe AG2 die sekundäre. Sobald die Sicherungsdateien der sekundären Verfügbarkeitsgruppe zur Verfügung stehen, werden sie dort angewendet. Dieses Szenario wird weiter unten im Abschnitt Beispiel: Sicherungs- und Wiederherstellungsstrategie zur Notfallwiederherstellung ausführlicher erläutert.
Topologie mit Zweit- und Drittstandort
Wenn nur zwei Datenbanken vorhanden sind – eine primäre und eine sekundäre, jeweils in eigenen Regionen – ergibt sich nach einem Failover ein ungeschützter Zeitraum ab dem Zeitpunkt, an dem die neue primäre Datenbank ausgeführt wird, bis zu dem Zeitpunkt, an dem die neue sekundäre Datenbank einsatzbereit ist. Wenn die neue primäre Datenbank ausfällt und die sekundäre Datenbank noch nicht ausgeführt wird, kommt es zu einer totalen Ausfallzeit, die nur durch Einrichtung einer neuen primären Datenbank behoben werden kann. Gleiches gilt für Verfügbarkeitsgruppen.
Ein dritter Standort, an dem eine andere sekundäre Datenbank oder Verfügbarkeitsgruppe ausgeführt wird, kann dafür sorgen, dass es keinen solchen ungeschützten Zeitraum nach einem Failover gibt. In dieser Konfiguration muss sichergestellt werden, dass eine der beiden sekundären Datenbanken eine sekundäre Datenbank bleibt und einer neuen primären Datenbank zugewiesen wird, damit kein Datenverlust auftritt. Wie oben gilt dies auch für Verfügbarkeitsgruppen.
Lebenszyklus der Notfallwiederherstellung
Unabhängig von der gewählten Notfallwiederherstellungslösung gibt es Schritte im zugehörigen Lebenszyklus, die allgemeinen gültig sind.
Im Falle einer tatsächlichen Notfallwiederherstellung müssen alle Beteiligten (Anwendungseigentümer, operative Teams und Datenbankadministratoren) verfügbar sein und aktiv an der Verwaltung der Notfallwiederherstellung mitarbeiten. Die Beteiligten müssen sich auf einen Entscheider einigen (manchmal als Master of Ceremony bezeichnet) und die zu befolgenden Entscheidungsprozesse festlegen. Darüber hinaus müssen sie sich auf ihre Terminologie und Kommunikationsmethoden verständigen.
Entscheidung über den Start eines Failover-Prozesses fällen
Sofern das Failover nicht automatisch eingeleitet wird, müssen die verschiedenen Beteiligten über die Einleitung eines Failovers entscheiden und sich dabei eng abstimmen.
Das Starten eines Failover-Prozesses hängt von mehreren Faktoren ab, in erster Linie vom Grund für die Nichtverfügbarkeit der primären Datenbank.
Wenn der Notfallwiederherstellungsprozess voraussichtlich länger dauert als die Instandsetzung der primären Datenbank, wäre ein Failover nachteilig. Sie müssen also zuerst prüfen, ob die Wiederherstellung der primären Datenbank eine praktikable Option ist.
Je besser die Notfallwiederherstellungsstrategie getestet und je schneller sie implementiert wird, desto einfacher ist es, den Failover-Prozess einzuleiten, da weniger Unsicherheitsfaktoren bei der Entscheidung zu berücksichtigen sind.
Failover-Prozess ausführen
Der Failover-Prozess wird idealerweise regelmäßig getestet und ist daher den verschiedenen Beteiligten bestens bekannt.
Der Entscheider muss sich über alle Schritte, die ausgeführt werden, und alle unerwarteten Probleme, die auftreten können, bewusst sein. Er steuert den Failover-Prozess und die Beteiligten müssen ihn dabei unterstützten.
Zur Störungsanalyse und Verbesserung des Failover-Prozesses sollten Sie Statistiken führen, unter anderem über die Dauer der Aktivitäten, die aufgetretenen Probleme und etwaige Unklarheiten bei den Schritten des Failover-Prozesses.
Fehlender Schutz
Wenn Sie nur eine einzige sekundäre Datenbank haben, ist ab dem Zeitpunkt, an dem die neue primäre Datenbank verfügbar und betriebsbereit ist, bis zu dem Zeitpunkt, an dem eine neue sekundäre Datenbank eingerichtet ist, kein Notfallwiederherstellungsschutz vorhanden. Eine Nichtverfügbarkeit während dieses Zeitraums kann zu einer Totalausfallzeit führen, da kein Failover auf eine andere Datenbank möglich ist. In diesem Fall muss eine andere primäre Datenbank eingerichtet werden und der RPA (Recovery Point Actual, Ist-Wiederherstellungszeitpunkt) ist der letzte Punkt, der anhand der verfügbaren Sicherungen rekonstruiert werden kann.
Sofern die Notfallwiederherstellungsstrategie nicht so eingerichtet ist, dass jederzeit Schutz gewährleistet ist, muss jeder Beteiligte diesen Zeitraum des fehlenden Schutzes berücksichtigen und zusätzliche Vorsichtsmaßnahmen während der Einrichtung und Änderung der Umgebungskonfiguration ergreifen.
Sie können diesen ungeschützten Zeitraum vermeiden, wenn Sie den Anwendungszugriff auf die neue primäre Datenbank verzögern, bis die neue sekundäre Datenbank einsatzbereit ist. Sobald Änderungen aus der primären Datenbank angewendet wurden, steht die primäre Datenbank Anwendungen zur Verfügung. Dieser Ansatz verhindert zwar, dass Anwendungen während der Notfallwiederherstellung zu irgendeinem Zeitpunkt ungeschützt sind, verzögert aber auch den Prozess der Notfallwiederherstellung.
Split-Brain-Situationen vermeiden
Es ist wichtig, dass Anwendungen nicht gleichzeitig auf eine primäre und eine sekundäre Datenbank zugreifen können, um DML-Vorgänge auszuführen. Es kommt sonst zu einer Dateninkonsistenz, bei der sich die primäre und sekundäre Datenbank über Datenwerte desselben Datenelements uneinig sind (Split-Brain). Diese Architektur ist besonders wichtig, falls die primäre Datenbank zwar nicht mehr verfügbar ist, aber noch ausgeführt wird und Schreibvorgänge empfangen kann. Wenn die Nichtverfügbarkeit durch periodische Netzwerkpartitionierung verursacht wird, kann die Partitionierung jederzeit enden und eine Anwendung dann wieder Zugriff haben. Erfolgt zu diesem Zeitpunkt ein Failover, können Änderungen an der alten primären Datenbank verloren gehen oder manche Anwendungen bereits mit der neuen primären Datenbank arbeiten, während andere noch auf die alte primäre Datenbank zugreifen.
Der gesamte Anwendungszugriff auf alle Datenbanken wird während des Failover-Prozesses deaktiviert, sodass in keiner der Datenbanken eine Zustandsänderung auftreten kann. Nach dem Failover ist nur eine einzige Datenbank für Schreibvorgänge verfügbar: die neue primäre Datenbank.
Abschluss bekanntgeben
Wenn der Failover-Prozess abgeschlossen ist, muss der Entscheider alle Beteiligten explizit davon in Kenntnis setzen. Jedes Problem, das nach dem Abschluss auftritt, muss als separater Zwischenfall behandelt werden, der nicht mehr Teil des Failover-Prozesses ist, sondern zur regulären Verarbeitung gehört. Das Problem kann die Folge eines Problems mit dem Failover-Prozess oder ein völlig eigenständiges Problem sein. Allerdings kann sich die Vorgehensweise zur Behebung des Problems nach Abschluss des Failover-Prozesses von der Vorgehensweise während der Ausführung des Failover-Prozesses unterscheiden.
Störungsanalyse und Bericht
Ordnen Sie zur zukünftigen Referenz und zur Verbesserung Ihres Failover-Prozesses sofort eine Störungsanalyse an, um wichtige Aspekte, Ergebnisse und Maßnahmen festzuhalten.
Schreiben Sie einen Bericht, in dem das Notfallwiederherstellungsereignis, die Ursachen und alle ergriffenen Maßnahmen zusammengefasst sind. Dieser Bericht kann obligatorisch sein, wenn Sie rechtliche Bestimmungen umsetzen.
Test und Verifizierung der Notfallwiederherstellung
Da die Notfallwiederherstellung nicht zum normalen Tagesgeschäft gehört, muss Ihre entsprechende Lösung regelmäßig getestet werden. Damit stellen Sie sicher, dass sie bei Bedarf ordnungsgemäß funktioniert.
Die Häufigkeit der Tests hängt von den betrieblichen Anforderungen ab und variiert je nach Datenbank, Anwendung und Unternehmen. Darüber hinaus sollten Änderungen an der Umgebung, z. B. Änderungen an der Netzwerkkonfiguration und Updates von Infrastrukturkomponenten, einen Notfallwiederherstellungstest auslösen, wenn die Änderungen an den Systemen vorgenommen werden, auf denen sich die gewählte Notfallwiederherstellungslösung stützt. Jede Änderung kann dazu führen, dass die Notfallwiederherstellungslösung fehlschlägt oder der Notfallwiederherstellungsprozess angepasst werden muss.
Sie können Tests manuell veranlassen, indem Sie den Switchover-Prozess starten, oder automatisch, indem Sie einem Chaos-Engineering-Ansatz folgen, wie unter Chaos Engineering beschrieben. Mit manuellen Tests können Sie die Auswirkungen auf Ihre Geschäftstätigkeit minimieren, falls wahrnehmbare Ausfallzeiten zu erwarten sind.
Ein wichtiger Aspekt beim Testen ist das Erfassen klar definierter Statistiken. Einige wichtige zu berücksichtigende Statistiken sind:
- Ist-Wiederherstellungsdauer (Recovery Time Actual, RTA): Messen Sie die tatsächliche Wiederherstellungsdauer und vergleichen Sie sie mit dem RTO-Wert.
- Ist-Wiederherstellungszeitpunkt (Recovery Point Actual, RPA): Beobachten Sie den tatsächlichen Wiederherstellungszeitpunkt und vergleichen Sie ihn mit dem RPO-Wert.
- Zeit bis zur Fehlererkennung: Die Zeit, die Datenbankadministratoren oder das operative Team benötigt haben, um die Notwendigkeit eines Failovers zu erkennen.
- Zeit bis zur Einleitung der Wiederherstellung: Die Zeit, die benötigt wurde, um den Failover-Prozess zu starten, nachdem der Fehler erkannt wurde.
- Zuverlässigkeit: Wurde der Failover-Prozess genau befolgt oder musste davon abgewichen werden? Sind unerwartete Probleme aufgetreten, die untersucht werden müssen und möglicherweise zu einer Änderung der Wiederherstellungsstrategie führen?
Ausgehend von den erfassten Statistiken muss der Failover-Prozess möglicherweise angepasst oder verbessert werden, um die RPO- und RTO-Erwartungen besser zu erfüllen.
Beispiel: Sicherungs- und Wiederherstellungsstrategie zur Notfallwiederherstellung
In den folgenden Abschnitten wird eine exemplarische Notfallwiederherstellungsstrategie beschrieben, die sich aus Sicherungs- und Wiederherstellungsvorgängen zusammensetzt. In diesem Szenario wird die Verwendung von SQL Server-Verfügbarkeitsfeatures minimiert, um den Aufwand für das Festlegen einer solchen Strategie zur Notfallwiederherstellung zu demonstrieren und Aspekte zu beleuchten, die in stärker automatisierten Konfigurationen unsichtbar sind.
Anwendungsfall
Eine primäre Always On-Verfügbarkeitsgruppe befindet sich in Region R1 und ist in Betrieb. Die sekundäre Always On-Verfügbarkeitsgruppe wird in Region R2 für zusätzlichen überregionalen Schutz hinzugefügt und ist als Failover- oder Switchover-Ziel verfügbar.
Strategie
Die Notfallwiederherstellungsstrategie basiert auf Datenbanksicherungen. Eine erste vollständige Sicherung wird erstellt, auf die differenzielle Sicherungen folgen. Sobald die Sicherungen erstellt wurden, erfolgt deren Anwendung auf die sekundäre Always On-Verfügbarkeitsgruppe. Alle Sicherungen werden in einem Cloud Storage-Bucket gespeichert.
In diesem Beispiel ist es nach Abschluss des Failovers akzeptabel, dass die neue primäre Always On-Verfügbarkeitsgruppe in R2 für eine begrenzte Zeit aktiv und ungeschützt ist, bis die neue sekundäre Always On-Verfügbarkeitsgruppe in R1 betriebsbereit ist.
Es muss kein Fallback stattfinden, da die Always On-Verfügbarkeitsgruppen in den einzelnen Regionen gleichermaßen als Always On-Verfügbarkeitsgruppe für die Produktion dienen können.
RTO und RPO
Der RPO-Wert wird in diesem Beispiel auf maximal 60 Minuten festgelegt, sodass alle 60 Minuten eine differenzielle Sicherung erfolgt.
Der RTO-Wert wird nicht explizit auf eine bestimmte Dauer festgelegt, sondern soll so gering wie möglich sein – sofort ist der Idealfall. Die sekundäre Verfügbarkeitsgruppe muss als Hot-Standby eingerichtet werden. Bei einem Hot-Standby werden alle Sicherungen sofort angewendet, damit sich das Failover nicht durch die Anwendung von Sicherungen verzögert.
Allgemeine Strategie zur Notfallwiederherstellung
In den folgenden Abschnitten wird die Strategie zur Notfallwiederherstellung zusammengefasst. Die Zusammenfassung ist kurz gehalten, um die wesentlichen Schritte zu beleuchten.
Ersteinrichtung
- Erstellen Sie eine sekundäre Always On-Verfügbarkeitsgruppe in Region R2.
- Verhindern Sie den Anwendungszugriff auf die sekundäre Verfügbarkeitsgruppe, damit nicht versehentlich eine Split-Brain-Situation auftritt.
- Erstellen Sie den Sicherungsdatei-Bucket B1 in Cloud Storage, um die erste vollständige Sicherung der Always On-Verfügbarkeitsgruppe in R1 und die nachfolgenden stündlichen differenziellen Sicherungen der Always On-Verfügbarkeitsgruppe in R1 aufzunehmen. Die richtige Reihenfolge der differenziellen Sicherungen muss festgelegt werden, damit der Prozess, der die Sicherungen auf die sekundäre Verfügbarkeitsgruppe anwendet, die richtige Reihenfolge ableiten kann. Ein Ansatz könnte eine Namenskonvention sein, an der sich die richtige chronologische Reihenfolge anhand von Datum und Uhrzeit ablesen lässt, die in den verschiedenen Dateinamen enthalten sind.
Strategie starten
- Wenden Sie die vollständige Sicherung auf die sekundäre Always On-Verfügbarkeitsgruppe in Region R2 an.
- Wenn differenzielle Sicherungen zur Verfügung stehen, wenden Sie diese sofort auf die sekundäre Always On-Verfügbarkeitsgruppe in R2 an. Die sofortige Anwendung ist notwendig, um den RTO-Wert zu erreichen.
- Nachdem die erste vollständige Sicherung und alle inkrementellen Sicherungen angewendet wurden, ist die sekundäre Always On-Verfügbarkeitsgruppe einsatzbereit.
- Testen Sie die Strategie, indem Sie ein Switchover von der primären Verfügbarkeitsgruppe auf die sekundäre Verfügbarkeitsgruppe durchführen. Während des Tests sollte mindestens eine inkrementelle Sicherung verfügbar sein.
Failover- oder Switchover-Fall
In R2 sehen die wesentlichen Schritte so aus:
- Sorgen Sie dafür, dass die letzte differenzielle Sicherung auf die sekundäre Always On-Verfügbarkeitsgruppe in R2 angewendet wurde.
- Legen Sie R2 als neue primäre Always On-Verfügbarkeitsgruppe fest.
- Erstellen Sie einen neuen Bucket B2, führen Sie eine vollständige Sicherung als Basis durch und öffnen Sie die neue primäre Verfügbarkeitsgruppe für den Anwendungszugriff.
- Beginnen Sie mit dem Erstellen differenzieller Sicherungen.
In R1 sehen die wesentlichen Schritte so aus:
- Entfernen Sie Bucket B1, da er nicht mehr benötigt wird.
- Wenn die Always On-Verfügbarkeitsgruppe in R1 wieder verfügbar ist (als neue sekundäre Always On-Verfügbarkeitsgruppe), verhindern Sie den Anwendungszugriff und entfernen alle Daten aus der Datenbank oder setzen diese in ihren ursprünglichen (leeren) Zustand zurück (sofern sie nicht neu erstellt werden musste).
- Wenden Sie die vollständige Sicherung aus der neuen primären Always On-Verfügbarkeitsgruppe in R2 an. Wenden Sie nachfolgend differenzielle Sicherungen sofort an, sobald sie verfügbar sind (gespeichert in Bucket B2).
Mögliche Verbesserungen
Eine mögliche Verbesserung der Strategie besteht darin, eine vollständige Sicherung nach einem Failover oder Switchover zu vermeiden und trotzdem in der Lage zu sein, die neue sekundäre Verfügbarkeitsgruppe schnell einzurichten. Erstellen Sie dazu anstelle einer einzelnen vollständigen Sicherung und nachfolgender differenzieller Sicherungen jede Woche eine vollständige Sicherung und einen wöchentlichen Bucket, der die vollständige Sicherung der Woche und alle nachfolgenden differenziellen Sicherungen für diese Woche enthält. Die neue primäre Verfügbarkeitsgruppe muss nur nach dem Failover differenzielle Sicherungen (und keine vollständige Sicherung) erstellen und diese dem Bucket hinzufügen. Die neue sekundäre Verfügbarkeitsgruppe wendet einfach alle Sicherungen im Bucket der aktuellen Wochen an. Wenn dieser wöchentliche Ansatz verwendet wird, müssen Sie eine Bereinigungs- oder Löschstrategie implementieren, um veraltete Sicherungen zu entfernen.
Eine weitere Verbesserung beruht auf der Tatsache, dass die neue sekundäre Verfügbarkeitsgruppe die frühere primäre Verfügbarkeitsgruppe war. Wenn die Datenbank existiert und nach erneuter Verfügbarkeit betriebsbereit ist, kann durch eine Wiederherstellung zum Zeitpunkt ihrer letzten differenziellen Sicherung verhindert werden, dass sie aus der letzten vollständigen Sicherung vollständig wiederhergestellt werden muss, wie unter Wiederherstellen einer SQL Server-Datenbank zu einem Zeitpunkt (vollständiges Wiederherstellungsmodell) beschrieben. Dieses Szenario reduziert den Aufwand und den Zeitraum, in dem die neue primäre Verfügbarkeitsgruppe ungeschützt ist.
Best Practices für die Produktion
In dieser Lösung ist nicht festgelegt, ob die SQL Server-Instanzen in den Always On-Verfügbarkeitsgruppen eigenständige Instanzen oder Failover-Clusterinstanzen sind. Über die Art der verwendeten Instanzen muss vor der Implementierung entschieden werden.
Bis eine neue sekundäre Always On-Verfügbarkeitsgruppe nach einem Failover betriebsbereit ist, ergibt sich während der Notfallwiederherstellung ein Zeitraum, in dem kein Schutz besteht. Sie sollten daher eine dritte Always On-Verfügbarkeitsgruppe in einer dritten Region einrichten.
Darüber hinaus sollten Sie Monitoring implementieren und so sicherstellen, dass jeder Ausfall oder Fehler erkannt wird. Monitoring wird in diesem Dokument zwar nicht behandelt, ist aber für eine funktionierende Notfallwiederherstellungslösung unerlässlich.
Weitere Informationen
- Always On-Verfügbarkeitsgruppen von SQL Server konfigurieren
- Always On-Verfügbarkeitsgruppe von SQL Server 2016 mit mehreren Subnetzen in Compute Engine bereitstellen
- Failover-Clusterinstanzen von SQL Server konfigurieren
- Windows Server-Failover-Clustering ausführen
- Cloud Logging, Cloud Monitoring und Error Reporting für .NET-Anwendungen aktivieren
- Cloud Monitoring-Agent installieren
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center