Dokumen ini menjelaskan cara mengakses dan melihat metrik virtual machine (VM). Dokumen ini juga menjelaskan cara meninjau metrik VM untuk mempelajari lebih lanjut VM Anda atau memecahkan masalah tertentu pada VM.
Memantau instance virtual machine (VM) sangat penting untuk mempertahankan resource VM Anda. Compute Engine menawarkan tampilan tingkat tinggi metrik VM Anda menggunakan tab Observability di konsol Google Cloud . Tab ini menyediakan dasbor bawaan menggunakan data telemetri sehingga Anda dapat memantau VM dan membuat keputusan yang tepat terkait resource Compute Engine Anda. Anda juga dapat menyesuaikan dasbor standar untuk melihat hanya metrik tertentu yang Anda inginkan.
Semua VM memiliki data pemanfaatan proses dasar yang tersedia saat dibuat. Namun, menginstal Agen Operasional memberikan insight yang lebih mendalam tentang perilaku VM.
Untuk mengetahui informasi selengkapnya tentang cara membuat kebijakan pemberitahuan pemantauan, menggunakan Metrics Explorer, atau informasi umum tentang cara kerja pemantauan dan metrik di Google Cloud, lihat dokumen Cloud Monitoring.
Sebelum memulai
Opsional: Instal Agen Operasional untuk mengumpulkan data yang lebih mendetail dari instance Compute Engine Anda.
Untuk memeriksa instance VM mana yang telah menginstal Agen Operasional, lakukan hal berikut:
Di konsol Google Cloud , buka Dasbor Monitoring
Pilih VM instances dari daftar dasbor.
Klik Daftar untuk melihat VM sebagai daftar.
Semua VM di project Anda akan ditampilkan. Kolom Agen menampilkan status penginstalan Agen Operasional. Anda dapat menginstal atau mengupdate agen dari halaman ini.
Opsional: Untuk memperbarui dasbor Predefined agar menampilkan peristiwa, seperti peristiwa yang menunjukkan pembaruan pada grup instance terkelola, klik Pilih Peristiwa, lalu selesaikan dialog.event_available
Untuk mengetahui informasi selengkapnya tentang peristiwa, lihat Jenis peristiwa.
Mengakses metrik kemampuan observasi VM
Akses informasi untuk satu atau beberapa VM menggunakan tab Kemampuan observasi di konsol Google Cloud . Secara default, dasbor standar menampilkan metrik VM. Jika hanya ingin melihat metrik tertentu yang Anda inginkan, Anda dapat membuat dasbor yang disesuaikan.
Melihat metrik kemampuan observasi untuk satu VM
Metrik VM dasar seperti pemanfaatan CPU dan traffic jaringan tersedia untuk Anda saat Anda membuat VM. Metrik untuk penggunaan memori dan proses hanya tersedia dengan penginstalan Agen Operasional, yang merupakan agen utama untuk mengumpulkan telemetri dari instance Compute Engine Anda.
Untuk melihat metrik satu VM, lakukan hal berikut:
Di konsol Google Cloud , buka halaman VM instances.
Pilih VM untuk membuka halaman Detail.
Klik tab Observability untuk menampilkan informasi tentang VM.
Opsional: Reset jangka waktu default satu jam ke jangka waktu yang ingin Anda pantau.
Opsional: Untuk memperbarui dasbor Predefined agar menampilkan peristiwa, seperti peristiwa yang menunjukkan pembaruan pada grup instance terkelola, klik Pilih Peristiwa, lalu selesaikan dialog.event_available
Untuk mengetahui informasi selengkapnya tentang peristiwa, lihat Jenis peristiwa.
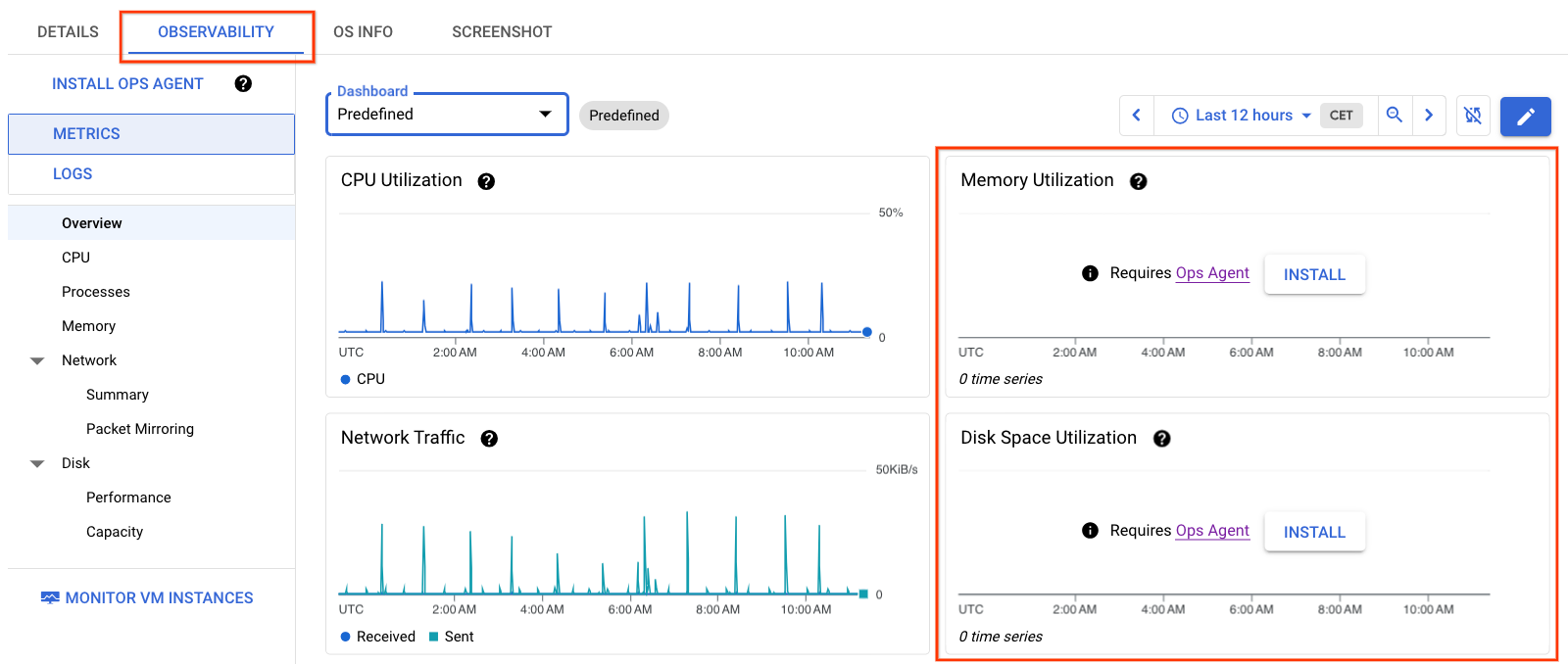
Informasi pada Gambar 1 menampilkan detail VM tanpa Agen Operasional diinstal di VM. Perhatikan bahwa grafik Memory Utilization dan Disk Space Utilization tidak memiliki data.
Melihat metrik kemampuan observasi untuk beberapa VM
Kemampuan observasi di tingkat armada menampilkan metrik untuk lima VM teratas dengan pemanfaatan proses tertinggi. Lima VM teratas yang tercantum bervariasi menurut metrik. Anda mungkin tidak melihat lima VM yang sama untuk setiap proses. Meskipun ada lebih banyak data yang tersedia di tingkat armada tanpa menginstal Agen Operasi dibandingkan dengan jumlah data yang tersedia untuk satu VM, menginstal agen memberikan lebih banyak data untuk tujuan pemecahan masalah di masa mendatang.
Untuk melihat metrik beberapa VM, lakukan hal berikut:
Di konsol Google Cloud , buka halaman VM instances.
Klik tab Observability.
Opsional: Reset jangka waktu default satu jam ke jangka waktu yang ingin Anda pantau.
Filter hasil menurut satu atau beberapa opsi berikut:
- ID
- Nama
- Machine type
- Zone
- Region
- Instance group
- Label
- Negara Bagian
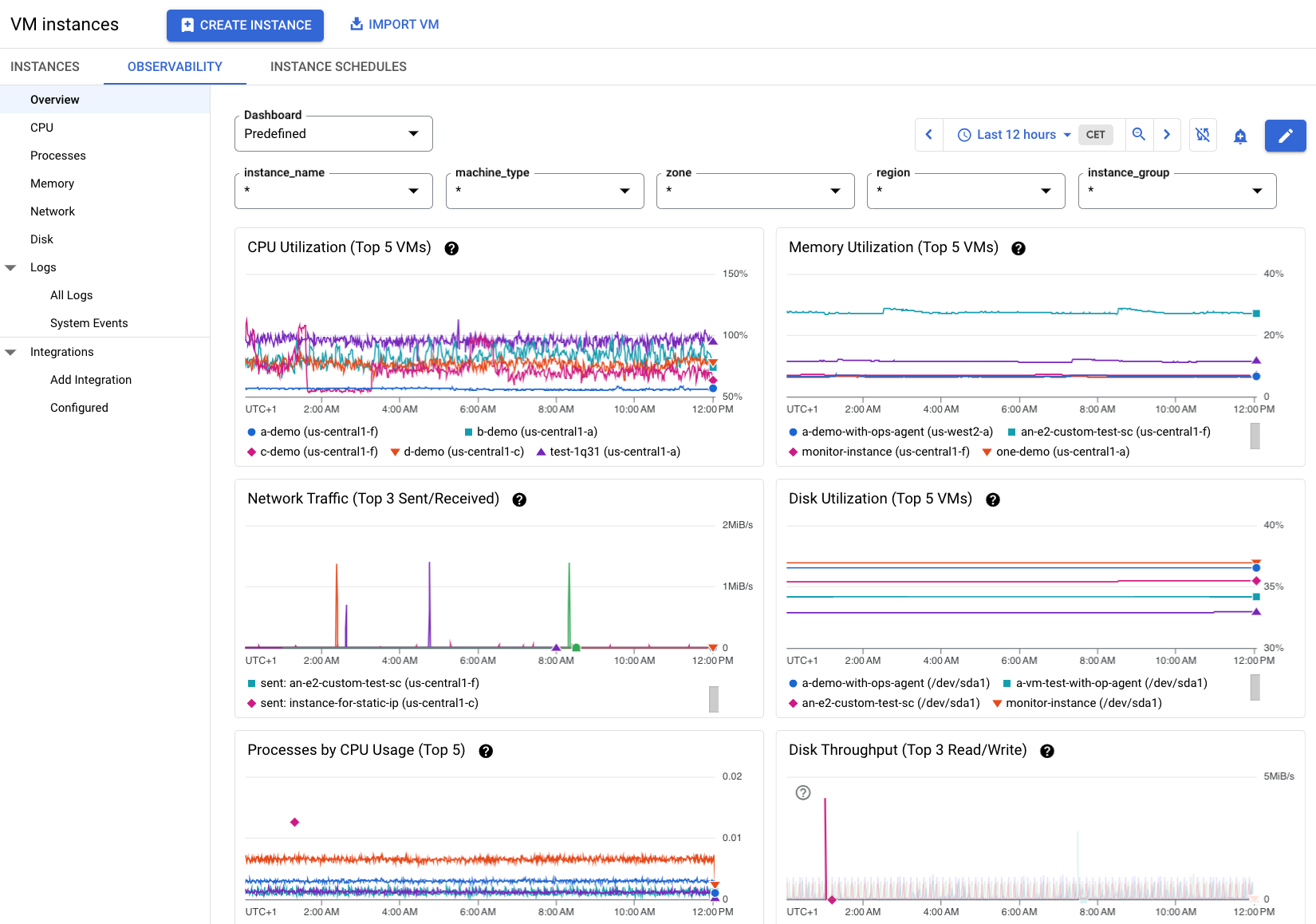
Informasi pada Gambar 2 menampilkan contoh tab Kemampuan observasi saat beberapa VM dalam suatu project telah menginstal Agen Operasional. Perhatikan bahwa ada lebih banyak metrik yang tersedia tentang VM ini.
Melihat metrik mendetail untuk VM
Setiap metrik proses VM diwakili oleh garis grafik pada diagram. Dalam contoh berikut, VM uptime-demo telah menginstal Agen Operasional. Data penggunaan memori tersedia untuk tujuan pemecahan masalah. Jika VM tidak tercantum di kartu, filter menurut nama VM untuk menemukan VM tertentu.
Untuk mengambil informasi tentang VM ini atau VM lainnya dari lima VM teratas dari tab Kemampuan observasi, lakukan langkah berikut:
- Tahan kursor di garis grafik VM mana pun. Kartu akan muncul dengan daftar lima VM teratas yang menggunakan proses ini, masing-masing menampilkan metrik.
- Untuk mempelajari lebih lanjut perilaku VM, klik garis grafik VM atau nama VM tertentu dalam daftar.
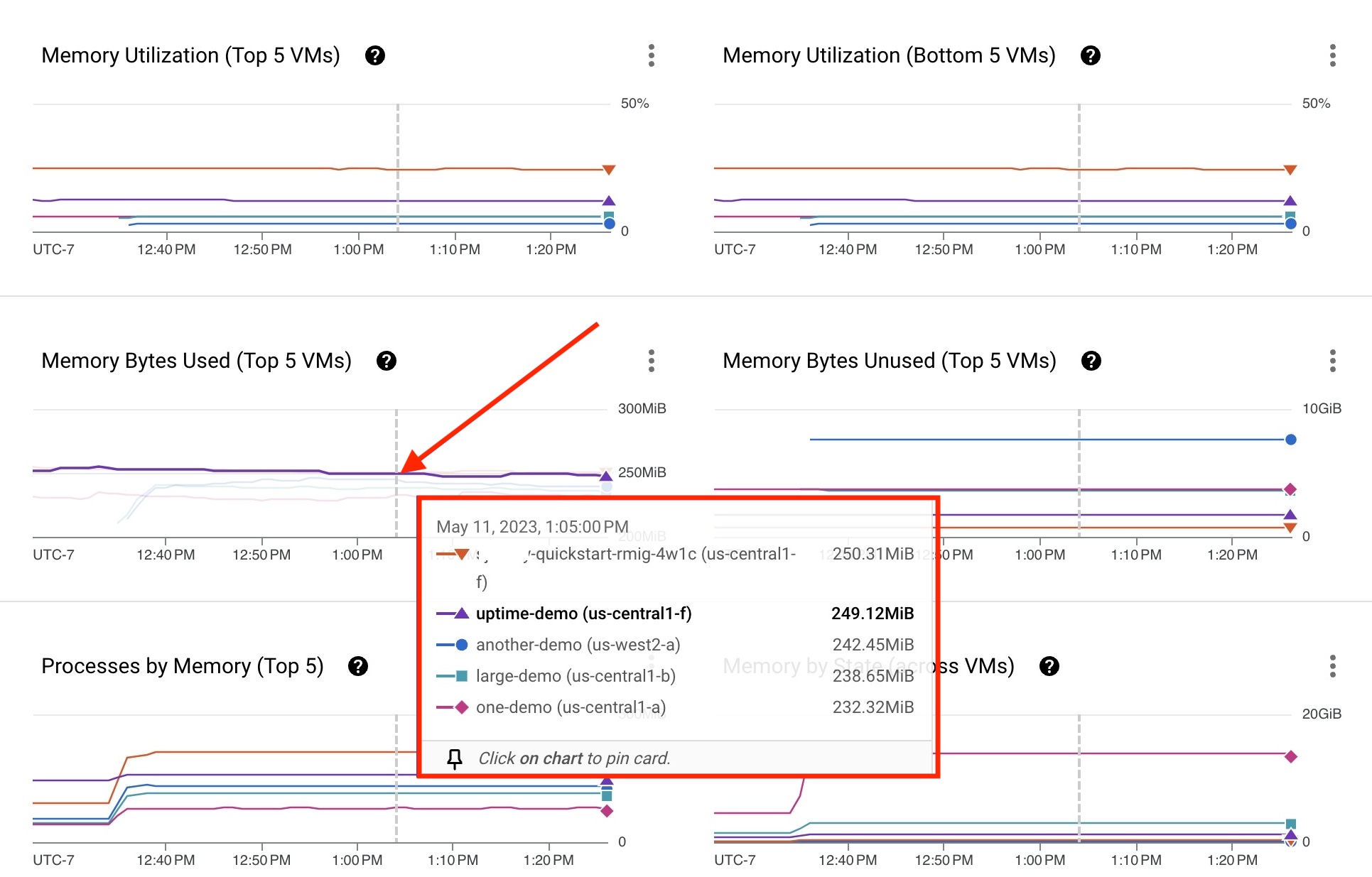
VM uptime-demo yang ditampilkan di kartu pada Gambar 3 mengungkapkan beberapa metrik yang mungkin memerlukan peninjauan.
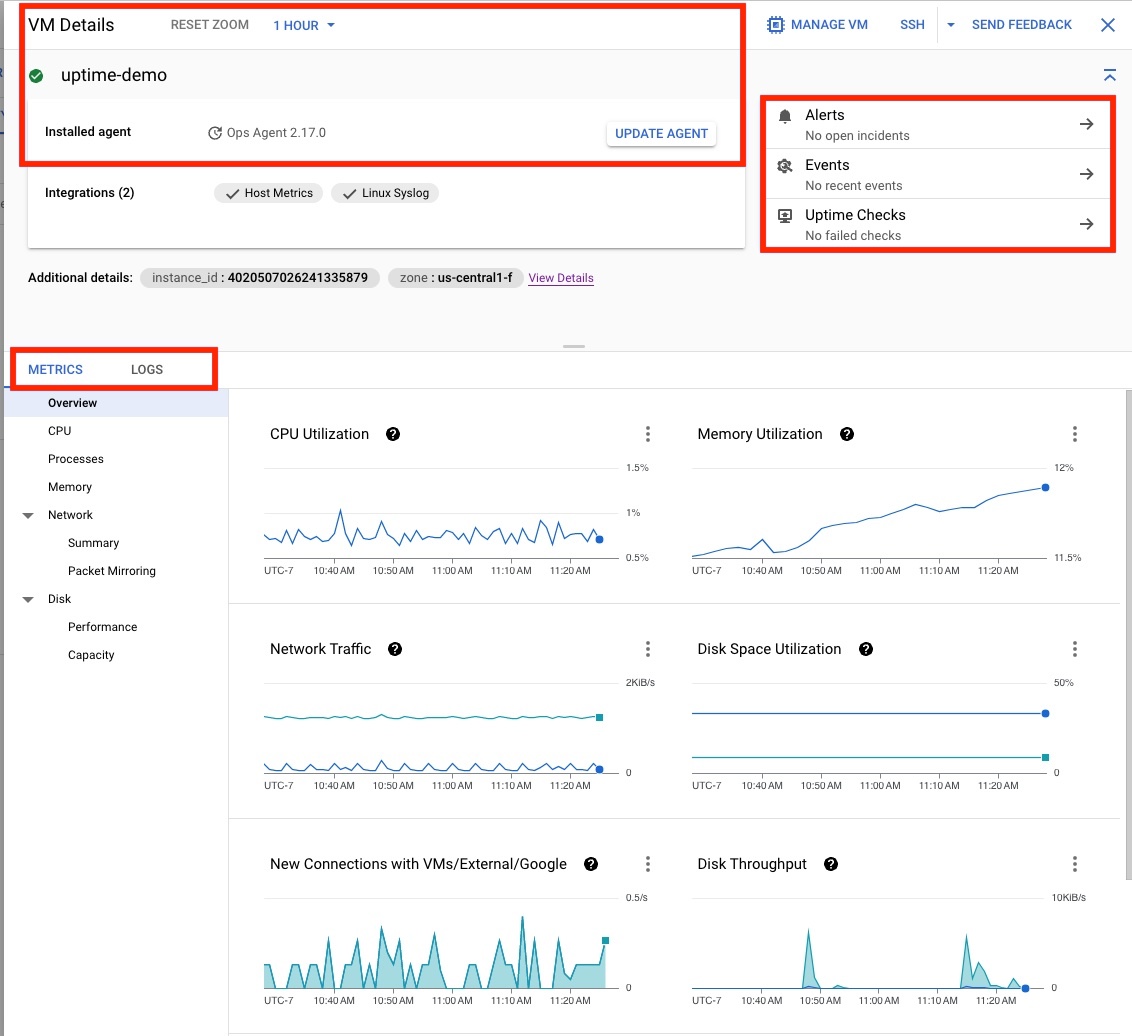
Klik VM uptime-demo untuk membuka halaman VM Details yang ditampilkan di Gambar 4, yang memberikan informasi berikut:
- Status Agen Operasional.
- Opsi dalam konteks untuk membuat Pemberitahuan, memeriksa Peristiwa, atau membuat Cek Uptime.
- Opsi untuk melihat detail konfigurasi, metrik, dan log VM.
Membuat dasbor yang disesuaikan untuk melihat metrik tertentu
Secara default, tab Observability di Compute Engine menyediakan dasbor yang telah ditentukan dan menampilkan metrik VM dasar. Untuk melihat hanya metrik tertentu yang ingin Anda lihat, Anda dapat mengubah dasbor bawaan dan menyimpannya sebagai dasbor yang disesuaikan. Anda dapat menyesuaikan dasbor lebih lanjut sesuai keinginan.
Untuk membuat dasbor yang disesuaikan, lakukan hal berikut:
Di konsol Google Cloud , buka halaman VM instances.
Buka tab Observability sebagai berikut:
- Untuk VM tunggal: Di halaman VM instances, klik nama VM untuk membuka halaman Details, lalu klik tab Observability untuk VM tersebut.
- Untuk beberapa VM: Di halaman VM instances, klik tab Observability.
Jika drop-down Dasbor diaktifkan, dasbor yang disesuaikan akan tersedia. Untuk mengubah tampilan kustom, pilih tampilan kustom dari drop-down, lalu, di toolbar dasbor, klik .
Jika tidak, untuk menyesuaikan dasbor bawaan, di toolbar dasbor, klik .
Compute Engine membuat salinan dasbor standar, lalu membuka salinan dalam mode edit.
Di editor, Anda dapat menambahkan, mengubah, menghapus, memosisikan ulang, atau mengubah ukuran visualisasi di dasbor. Visualisasi ini secara kolektif disebut widget. Untuk mengetahui informasi selengkapnya tentang berbagai jenis widget, lihat Ringkasan dasbor.
Untuk menambahkan widget, di toolbar dasbor, klik Tambahkan widget dan selesaikan konfigurasi.
Misalnya, untuk melihat log dengan data metrik Anda, klik Tambahkan widget, pilih Log, lalu klik Terapkan.
Untuk mengubah widget, arahkan kursor ke widget untuk mengaktifkan toolbar, klik Edit widget, lalu gunakan dialog Konfigurasi widget. Untuk menerapkan perubahan pada dasbor, klik Terapkan di toolbar. Untuk menghapus perubahan, klik Batal.
Untuk menghapus widget, letakkan kursor pada widget untuk mengaktifkan toolbar, klik Opsi diagram lainnya, lalu pilih Hapus.
Untuk mengubah posisi widget, gunakan pointer Anda untuk menarik widget berdasarkan headernya ke lokasi baru.
Untuk mengubah ukuran widget, gunakan pointer Anda untuk memosisikan ulang sudut kanan widget.
Setelah selesai mengubah dasbor, klik Simpan.
Pada dialog yang mengonfirmasi perubahan, klik Lihat dasbor yang disesuaikan untuk membuka tampilan yang disesuaikan.
Anda dapat beralih kembali ke tampilan standar dengan memilih Standar dari drop-down Dasbor.
Meninjau metrik resource
Untuk mempelajari lebih lanjut setiap metrik resource, klik setiap proses dalam menu tab Observasi:
- Pelajari CPU, Proses, penggunaan Memori, traffic Jaringan, dan Disk.
- Lihat data log dengan menelusuri Log untuk mengidentifikasi dan melihat Peristiwa Sistem.
- Tambahkan Integrasi pihak ketiga dan periksa integrasi yang sudah Dikonfigurasi.
Bagian selanjutnya dari artikel ini menjelaskan contoh bagaimana beberapa proses dapat memengaruhi workload Anda. Informasi ini mengasumsikan bahwa Agen Operasional telah diinstal di VM Anda.
Pemakaian CPU
Contoh penggunaan CPU ekstrem mungkin terjadi saat server mengalami beban berat yang tidak terduga, seperti saat situs mengalami lonjakan traffic yang tiba-tiba atau saat tugas pemrosesan data berskala besar sedang berlangsung. Dalam situasi seperti itu, CPU mungkin berjalan dengan kapasitas 100% selama jangka waktu yang lama, yang dapat menyebabkan server melambat atau menjadi tidak responsif.
Dalam contoh ini, saturasi adalah masalahnya. Jika pemakaian CPU Anda mencapai 100%, mungkin hal tersebut tidak masalah untuk workload Anda. Namun, sebaiknya periksa metrik lain untuk mengetahui apakah hal ini memerlukan intervensi atau tidak. Dalam hal ini, sebaiknya Anda membuat kebijakan pemberitahuan agar Anda diberi tahu saat pemanfaatan CPU VM meningkat.
Dengan izin yang tepat, Anda dapat terhubung menggunakan SSH ke VM untuk menyelidiki masalah. Namun, jika Ops Agent diinstal, Anda dapat melihat data historis lainnya untuk membantu memecahkan masalah.
Penggunaan proses
Contoh perilaku proses ekstrem mungkin terjadi saat suatu proses menggunakan resource dalam jumlah berlebihan seperti CPU, memori, atau I/O disk, hingga menyebabkan penurunan performa atau bahkan membuat VM mengalami error.
Misalnya, jika proses yang berjalan di VM mengalami kebocoran memori, proses tersebut dapat mulai menggunakan jumlah memori yang semakin besar seiring waktu, hingga akhirnya menyebabkan VM kehabisan memori dan error. Demikian pula, jika suatu proses menggunakan disk secara berlebihan, hal ini dapat menyebabkan I/O disk VM menjadi jenuh, sehingga menyebabkan waktu respons yang lambat untuk proses lainnya.
Pemakaian memori
Database memerlukan memori dalam jumlah besar untuk melakukan operasi seperti pengindeksan, pengurutan, dan penggabungan tabel.
Contoh penggunaan memori yang tinggi di VM adalah saat Anda menjalankan server database, seperti Cloud SQL untuk MySQL atau Cloud SQL untuk PostgreSQL, dengan set data yang besar. Jika memori yang tersedia di VM Anda terlalu kecil, memuat ulang set data ke dalam memori dapat menyebabkan database berjalan lambat atau error.
Performa jaringan
Masalah performa jaringan disebabkan oleh berbagai faktor: kemacetan, batasan bandwidth, masalah hardware atau software, dan latensi. Untuk mendiagnosis masalah, pantau metrik performa jaringan Anda, pecahkan masalah hardware dan software, serta analisis pola traffic jaringan untuk mengidentifikasi dan menyelesaikan penyebab utama masalah.
Pemanfaatan disk
Penggunaan disk yang tinggi pada VM terjadi saat ada banyak data yang dibaca ke atau ditulis dari disk virtual yang mengakibatkan penundaan akses disk dan kemungkinan berdampak pada performa VM.
Memantau metrik pemanfaatan disk seperti operasi I/O disk per detik (IOPS), panjang antrean disk, dan waktu respons disk rata-rata dapat membantu mengidentifikasi dan mendiagnosis masalah pemanfaatan disk yang tinggi pada VM.
Memeriksa log dan peristiwa sistem
Halaman Semua Log menyediakan data log tentang resource Anda. Urutkan berdasarkan keparahan untuk mengidentifikasi masalah dan memeriksa payload.
Log audit mencatat peristiwa administratif yang terjadi di resource Anda. Log dapat memberi tahu Anda apa yang terjadi untuk memicu peristiwa. Beberapa log dicatat dan disimpan dalam baris yang sama, jadi misalnya, jika Anda memiliki 20 log yang identik, informasi tersebut disimpan dalam satu baris, bukan 20 baris terpisah.
Anda dapat menganggap Peristiwa Sistem sebagai istilah umum untuk peristiwa yang terjadi di tingkat yang lebih tinggi, tetapi dapat memengaruhi resource Compute Engine Anda. Peristiwa sistem terjadi saat error yang tidak terkait dengan peristiwa yang direncanakan dipicu. Peristiwa sistem dicatat di tingkat armada.
Menggunakan integrasi pihak ketiga
Monitoring menyediakan integrasi dengan aplikasi pihak ketiga. Integrasi ini memungkinkan Anda mengumpulkan telemetri dari aplikasi seperti Apache Web Server, Cloud SQL untuk MySQL, Memorystore untuk Redis, dan lainnya untuk deployment yang berjalan di Compute Engine dan GKE. Saat Anda menggunakan Compute Engine, telemetri pihak ketiga dikumpulkan oleh Agen Operasional.