Ce document décrit comment accéder aux métriques des machines virtuelles (VM) et les afficher. Il décrit également comment examiner les métriques des VM pour en apprendre davantage sur vos VM ou pour résoudre des problèmes spécifiques à une VM.
La surveillance des instances de machine virtuelle (VM) est essentielle à la maintenance de vos ressources de VM. Compute Engine offre une vue d'ensemble de vos métriques de VM à l'aide de l'onglet Observabilité de la console Google Cloud . Cet onglet fournit un tableau de bord prédéfini à l'aide de données de télémétrie afin que vous puissiez surveiller vos VM et prendre des décisions avisées sur vos ressources Compute Engine. Vous pouvez également personnaliser le tableau de bord prédéfini pour n'afficher que les métriques spécifiques que vous souhaitez.
Toutes les VM disposent des données de base d'utilisation des processus lors de leur création. Toutefois, l'installation de l'agent Ops fournit des informations plus détaillées sur le comportement des VM.
Pour en savoir plus sur la création d'une règle d'alerte de surveillance, l'utilisation de l'explorateur de métriques, ou pour obtenir des informations générales sur le fonctionnement de la surveillance et des métriques dans Google Cloud, consultez la documentation de Cloud Monitoring.
Avant de commencer
Facultatif : installez l'agent Ops pour collecter des données plus détaillées à partir de vos instances Compute Engine.
Pour vérifier quelles instances de VM ont l'agent Ops installé, procédez comme suit :
Dans la console Google Cloud , accédez à Tableaux de bord Monitoring.
Sélectionnez Instances de VM dans la liste du tableau de bord.
Cliquez sur Liste pour afficher les VM sous forme de liste.
Toutes les VM de votre projet s'affichent. La colonne Agent affiche l'état de l'installation de l'agent Ops. Vous pouvez installer ou mettre à jour l'agent à partir de cette page.
Facultatif : Pour mettre à jour le tableau de bord prédéfini pour afficher des événements tels que ceux qui indiquent une mise à jour d'un groupe d'instances géré, cliquez sur event_available Sélectionner des événements, puis remplissez les champs de la boîte de dialogue.
Pour en savoir plus sur les événements, consultez la section Types d'événements.
Accéder aux métriques d'observabilité des VM
Accédez aux informations sur une ou plusieurs VM en utilisant l'onglet Observabilité de la console Google Cloud . Par défaut, un tableau de bord prédéfini affiche les métriques des VM. Si vous souhaitez sélectionner et afficher uniquement des métriques spécifiques, vous pouvez créer un tableau de bord personnalisé.
Afficher les métriques d'observabilité pour une seule VM
Les métriques de base des VM telles que l'utilisation du processeur et le trafic réseau sont disponibles lorsque vous créez votre VM. Les métriques d'utilisation de la mémoire et des processus ne sont disponibles qu'avec l'installation de l'agent Ops, qui est l'agent principal de collecte de la télémétrie à partir de vos instances Compute Engine.
Pour afficher les métriques pour une seule VM, procédez comme suit :
Dans la console Google Cloud , accédez à la page Instances de VM.
Sélectionnez une VM pour ouvrir la page Détails.
Cliquez sur l'onglet Observability (Observabilité) pour afficher des informations sur la VM.
Facultatif : Réinitialisez la période par défaut d'une heure sur la période que vous souhaitez surveiller.
Facultatif : Pour mettre à jour le tableau de bord prédéfini pour afficher des événements tels que ceux qui indiquent une mise à jour d'un groupe d'instances géré, cliquez sur event_available Sélectionner des événements, puis remplissez les champs de la boîte de dialogue.
Pour en savoir plus sur les événements, consultez la section Types d'événements.
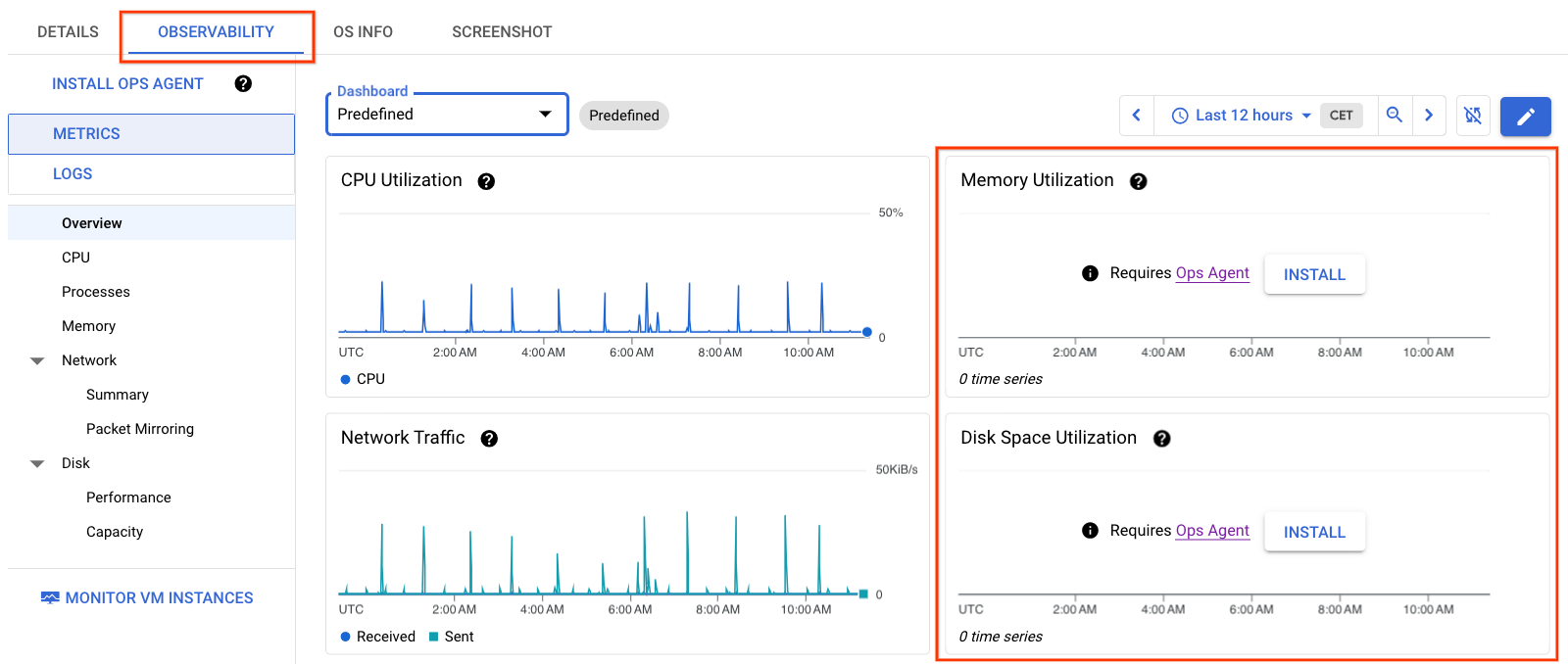
Les informations de la Figure 1 affichent les détails de la VM sans que l'agent Ops soit installé sur la VM. Notez que les graphiques Memory Utilization (Utilisation de la mémoire) et Disk Space Utilization (Utilisation de l'espace disque) ne contiennent aucune donnée.
Afficher les métriques d'observabilité pour plusieurs VM
L'observabilité au niveau du parc affiche les métriques des cinq premières VM dont la valeur d'utilisation des processus est la plus élevée. Les cinq premières VM répertoriées varient en fonction de la métrique. Il est possible que vous ne voyiez pas les mêmes cinq VM pour chaque processus. Bien que la quantité de données disponibles au niveau du parc sans installer l'agent Ops est supérieure à celle disponible pour une seule VM, l'installation de l'agent fournit davantage de données à des fins de dépannage futures.
Pour afficher les métriques pour plusieurs VM, procédez comme suit :
Dans la console Google Cloud , accédez à la page Instances de VM.
Cliquez sur l'onglet Observabilité.
Facultatif : Réinitialisez la période par défaut d'une heure sur la période que vous souhaitez surveiller.
Filtrez les résultats en fonction d'une ou de plusieurs des options suivantes :
- ID
- Nom
- Type de machine
- Zone
- Région
- Groupe d'instances
- Étiquettes
- État
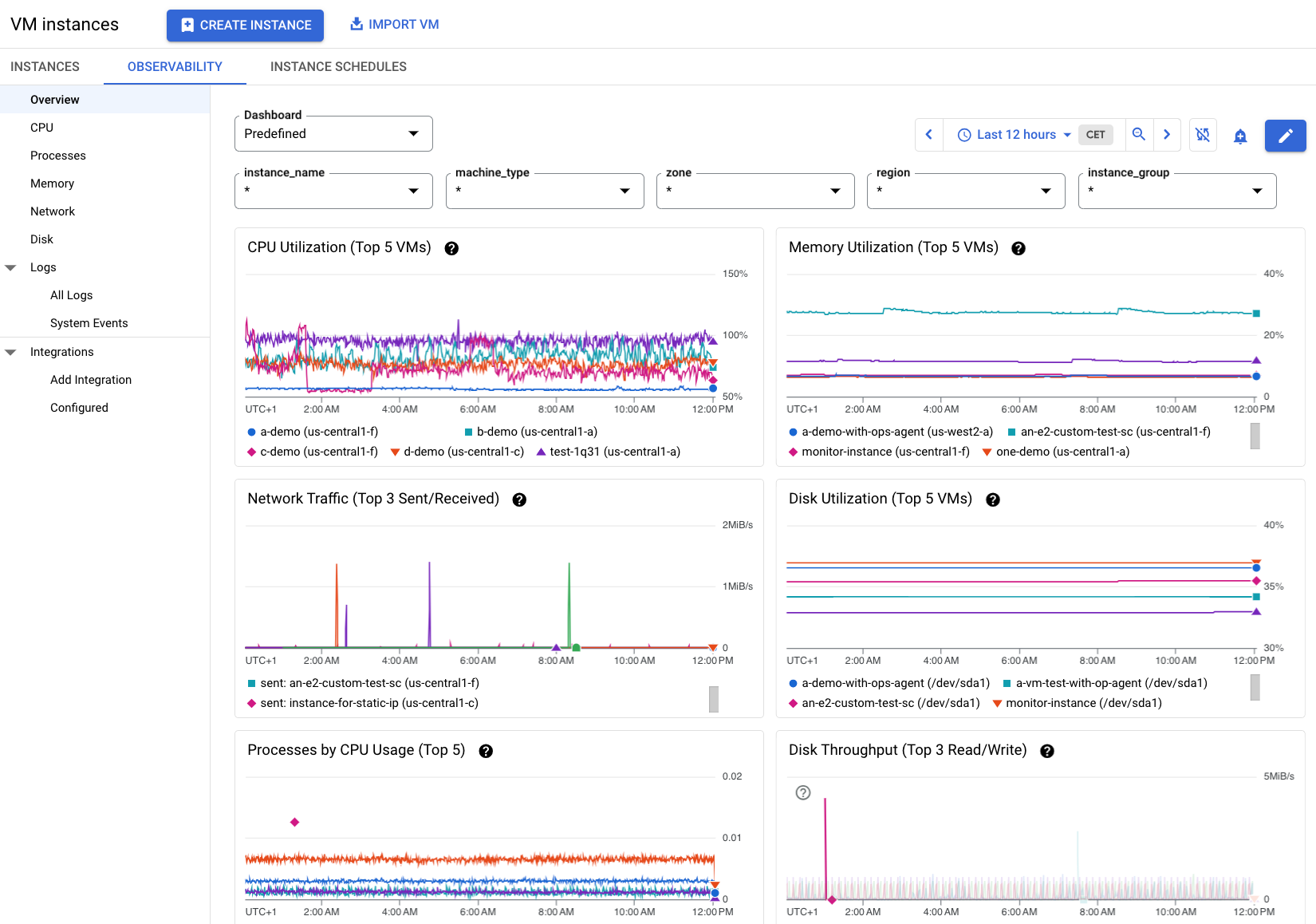
Les informations de la Figure 2 affichent un exemple d'onglet "Observability" (Observabilité) lorsque plusieurs VM d'un projet ont l'agent Ops installé. Notez que d'autres métriques sont disponibles pour ces VM.
Afficher les métriques détaillées pour une VM
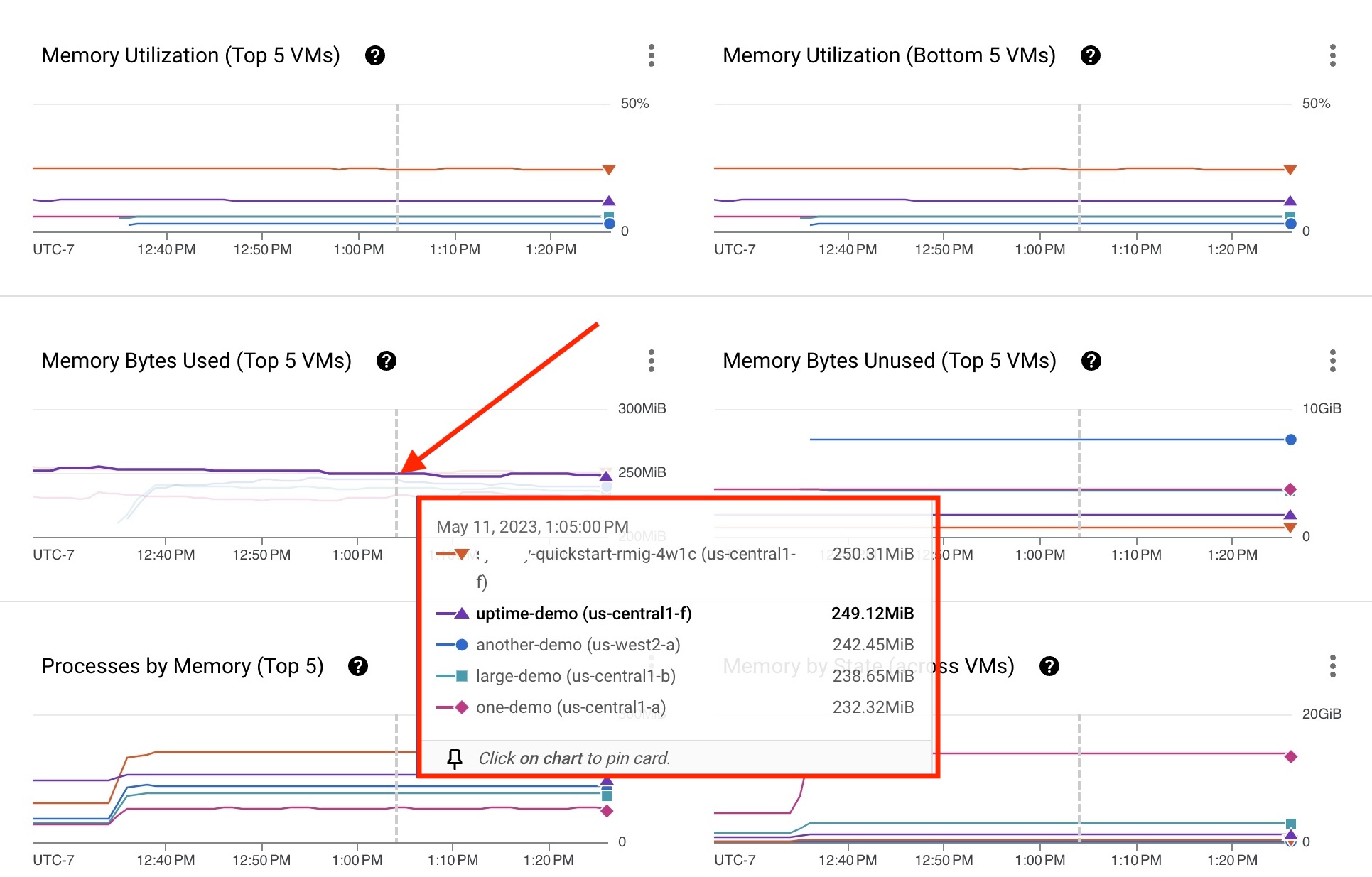
Chaque métrique de processus de VM est représentée par une ligne sur un graphique. Dans l'exemple suivant, l'agent Ops est installé sur la VM uptime-demo. Les données d'utilisation de la mémoire sont disponibles à des fins de dépannage. Si une VM n'est pas répertoriée sur la fiche, filtrez par nom de VM pour rechercher une VM spécifique.
Pour récupérer des informations sur cette VM ou sur l'une des cinq premières VM de l'onglet "Observabilité", procédez comme suit :
- Pointez sur la ligne de graphique de n'importe quelle VM. Une fiche apparaît avec la liste des cinq premières VM utilisant le processus, chacune affichant une métrique.
- Pour en savoir plus sur le comportement de la VM, cliquez sur la ligne du graphique de la VM ou sur le nom spécifique de la VM sur la liste.
La VM uptime-demo affichée sur la fiche de la Figure 3 présente certaines métriques pouvant nécessiter un examen.
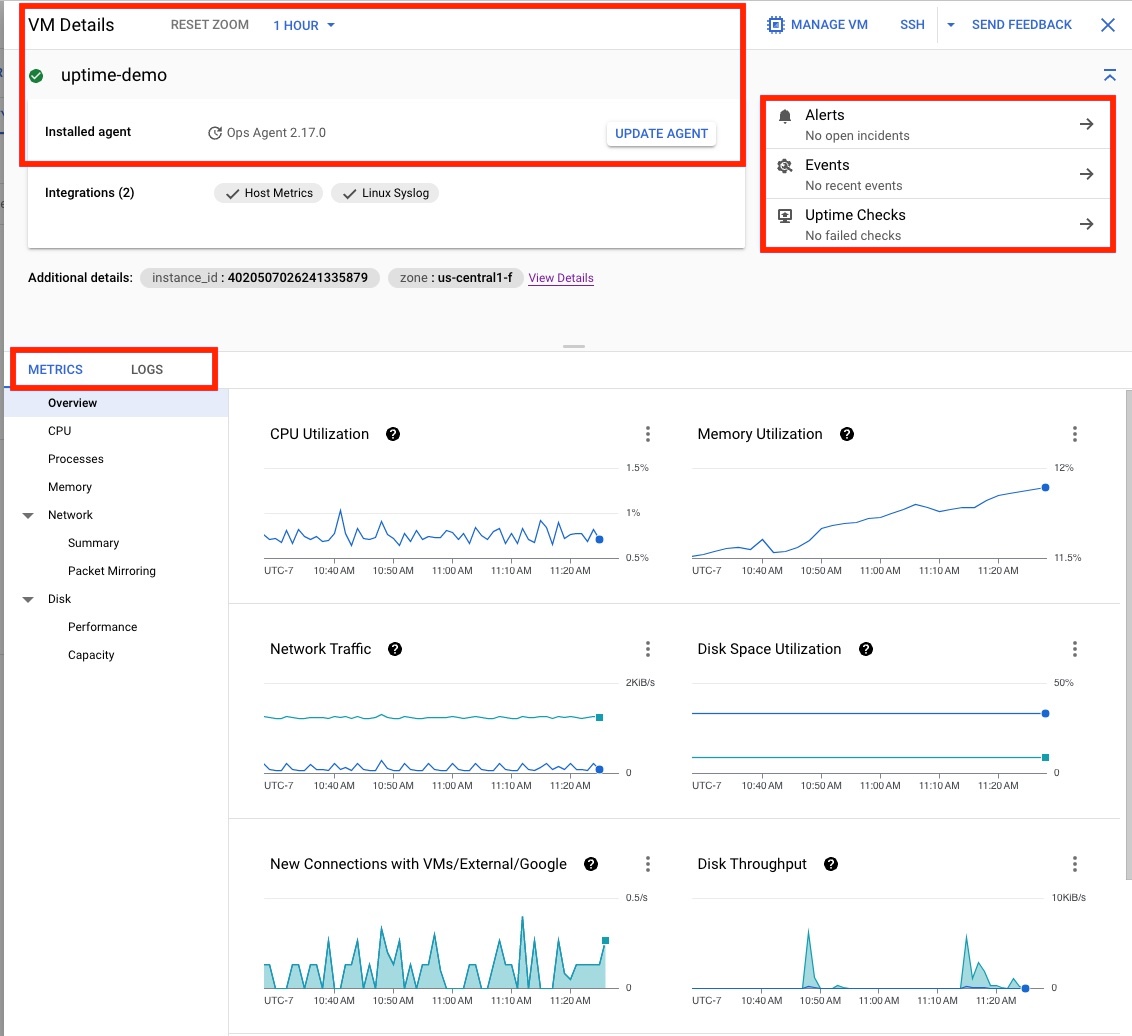
Cliquez sur la VM uptime-demo pour ouvrir la page des Détails de la VM affichée dans la Figure 4, qui fournit les informations suivantes :
- L'État de l'agent Ops.
- Les options de contexte permettant de créer des alertes, rechercher des événements ou créer des tests de disponibilité.
- L'option permettant d'afficher les détails des configurations, des métriques et des journaux de la VM.
Créer un tableau de bord personnalisé pour afficher des métriques spécifiques
Par défaut, l'onglet Observabilité dans Compute Engine fournit un tableau de bord prédéfini qui affiche les métriques de base de la VM. Pour afficher uniquement les métriques spécifiques qui vous intéressent, vous pouvez modifier le tableau de bord prédéfini et l'enregistrer en tant que tableau de bord personnalisé. Vous pouvez également personnaliser le tableau de bord comme vous le souhaitez.
Pour créer un tableau de bord personnalisé, procédez comme suit :
Dans la console Google Cloud , accédez à la page Instances de VM.
Accédez à l'onglet Observabilité comme suit :
- Pour une seule VM : sur la page Instances de VM, cliquez sur le nom de la VM pour ouvrir la page des Détails de la VM, puis cliquez sur l'onglet Observabilité pour cette VM.
- Pour plusieurs VM : sur la page Instances de VM, cliquez sur l'onglet Observabilité.
Si le menu déroulant Tableau de bord est activé, des tableaux de bord personnalisés sont disponibles. Pour modifier une vue personnalisée, sélectionnez-en une dans le menu déroulant, puis cliquez sur dans la barre d'outils du tableau de bord.
Sinon, pour personnaliser le tableau de bord prédéfini, cliquez sur dans la barre d'outils du tableau de bord.
Compute Engine crée une copie du tableau de bord prédéfini, puis ouvre ensuite cette copie en mode Édition.
Dans l'éditeur, vous pouvez ajouter, modifier, supprimer, repositionner ou redimensionner les visualisations du tableau de bord. Les visualisations sont collectivement appelées widgets. Pour en savoir plus sur les différents types de widgets, consultez la page Présentation des tableaux de bord.
Pour ajouter un widget, cliquez sur Ajouter un widget dans la barre d'outils du tableau de bord, puis terminez la configuration.
Par exemple, pour afficher les journaux contenant vos données de métriques, cliquez sur Ajouter un widget, sélectionnez Journaux, puis cliquez sur Appliquer.
Pour modifier un widget, placez votre pointeur sur le widget afin d'activer la barre d'outils, cliquez sur Modifier le widget, et utilisez ensuite la boîte de dialogue Configurer le widget. Pour appliquer vos modifications au tableau de bord, cliquez sur Appliquer dans la barre d'outils. Pour supprimer vos modifications, cliquez sur Annuler.
Pour supprimer un widget, placez votre pointeur sur le widget afin d'activer la barre d'outils, cliquez sur Plus d'options pour le graphique, puis sélectionnez Supprimer.
Pour repositionner un widget, utilisez votre pointeur au niveau son en-tête pour le faire glisser vers un nouvel emplacement.
Pour redimensionner un widget, utilisez votre pointeur sur le coin droit du widget pour le repositionner.
Une fois que vous avez terminé de modifier le tableau de bord, cliquez sur Enregistrer.
Dans la boîte de dialogue de confirmation des modifications, cliquez sur Afficher le tableau de bord personnalisé pour accéder à la vue personnalisée.
Vous pouvez revenir à la vue prédéfinie en sélectionnant Prédéfini dans le menu déroulant Tableau de bord.
Examiner les métriques de ressources
Pour en savoir plus sur chaque métrique de ressources, cliquez sur chaque processus dans le menu de l'onglet Observabilité :
- Découvrez l'utilisation du processeur, des processus et de la mémoire, le trafic réseau et l'utilisation du disque.
- Affichez les données de journal en recherchant des journaux pour identifier et afficher les événements système.
- Ajoutez des intégrations tierces et recherchez les intégrations configurées existantes.
Le reste de cette section décrit des exemples d'impact de certains processus sur vos charges de travail. Ces informations supposent que l'agent Ops est installé sur vos VM.
Utilisation du processeur
Un exemple d'utilisation extrême du processeur peut se produire lorsqu'un serveur est soumis à une charge inattendue et élevée, par exemple lorsqu'un site Web subit une augmentation soudaine du trafic, ou lorsqu'une tâche de traitement des données à grande échelle est en cours d'exécution. Dans de telles situations, le processeur peut fonctionner à 100 % de sa capacité pendant une période prolongée, ce qui peut conduire le serveur à ralentir ou à ne plus répondre.
Dans cet exemple, le problème est la saturation. Si votre utilisation du processeur est de 100 %, ce n'est pas forcément un problème pour vos charges de travail, mais il vaudrait sûrement mieux examiner d'autres métriques pour savoir si une intervention est nécessaire. Dans ce cas, vous pouvez créer une règle d'alerte afin d'être averti lorsque l'utilisation du processeur par une VM augmente.
Avec les autorisations appropriées, vous pouvez vous connecter en SSH à vos VM pour examiner le problème. Toutefois, si l'agent Ops est installé, vous pouvez afficher plus de données de l'historique pour vous aider à résoudre les problèmes.
Utilisation des processus
Un exemple de comportement de processus extrême peut être lorsqu'un processus utilise une quantité excessive de ressources telles que le processeur, la mémoire ou les E/S du disque, au point de provoquer une dégradation des performances ou même un plantage de la VM.
Par exemple, si un processus exécuté sur une VM subit une fuite de mémoire, il peut commencer à consommer de plus en plus de mémoire au fil du temps, ce qui finit par entraîner un manque de mémoire et un plantage de la VM. De même, si un processus utilise beaucoup le disque, les E/S du disque de la VM peuvent être saturées, ce qui entraîne des temps de réponse lents pour d'autres processus.
Utilisation de la mémoire
Les bases de données nécessitent beaucoup de mémoire pour effectuer des opérations telles que l'indexation, le tri et la jointure de tables.
Un exemple d'utilisation élevée de mémoire sur une VM peut être lorsque vous exécutez un serveur de base de données, tel que Cloud SQL pour MySQL et Cloud SQL pour PostgreSQL, avec un ensemble de données volumineux. Si la mémoire disponible de votre VM est trop petite, le rechargement en mémoire d'un ensemble de données peut ralentir la base de données ou la faire planter.
Performances du réseau
Les problèmes de performances de la mise en réseau résultent de différents facteurs : congestion, limites de bande passante, problèmes matériels ou logiciels, et latence. Pour diagnostiquer le problème, surveillez les métriques de performances du réseau, résolvez les problèmes matériels et logiciels et analysez les données du trafic réseau pour identifier et résoudre la cause première du problème.
Utilisation du disque
L'utilisation élevée du disque sur une VM se produit lorsqu'une grande quantité de données sont lues ou écrites sur le disque virtuel, ce qui entraîne un retard dans l'accès au disque et peut avoir un impact sur les performances de la VM.
La surveillance des métriques d'utilisation du disque, telles que les opérations d'E/S par seconde (IOPS, I/O operations per second), la longueur de la file d'attente et le temps de réponse moyen du disque, peuvent vous aider à identifier et à diagnostiquer les problèmes d'utilisation élevée du disque sur une VM.
Vérifier les journaux et les événements système
La page Tous les journaux fournit les données des journaux sur vos ressources. Triez-les par gravité pour identifier les problèmes et inspecter la charge utile.
Les journaux d'audit enregistrent les événements d'administration qui se produisent dans vos ressources. Les journaux peuvent vous indiquer ce qui s'est passé pour déclencher l'événement. Plusieurs journaux sont enregistrés et conservés sur la même ligne. Par exemple, si vous disposez de 20 journaux identiques, les informations sont stockées sur une seule ligne, plutôt que sur 20 lignes distinctes.
Vous pouvez considérer les événements système comme un terme générique pour les événements qui se produisent à un niveau supérieur, mais qui peuvent avoir un impact sur vos ressources Compute Engine. Un événement système se produit lorsqu'une erreur sans rapport avec un événement planifié se déclenche. Les événements système sont consignés au niveau du parc.
Utiliser des intégrations tierces
Monitoring fournit des intégrations à des applications tierces. Ces intégrations vous permettent de collecter des données de télémétrie à partir d'applications telles qu'Apache Web Server, Cloud SQL pour MySQL, Memorystore pour Redis et d'autres pour les déploiements exécutés sur Compute Engine et GKE. Lorsque vous utilisez Compute Engine, la télémétrie tierce est collectée par l'agent Ops.