本文档介绍如何访问和查看虚拟机 (VM) 指标。本文档还介绍了如何查看虚拟机指标以详细了解虚拟机或排查虚拟机的特定问题。
监控虚拟机 (VM) 实例对于维护虚拟机资源至关重要。Compute Engine 使用 Google Cloud 控制台中的可观测性标签页简要介绍了虚拟机指标。此标签页提供使用遥测数据的预定义信息中心,因此您可以监控虚拟机并就 Compute Engine 资源做出明智的决策。您还可以自定义预定义的信息中心,以便仅查看所需的特定指标。
所有虚拟机在创建时都有基本的进程利用率数据。 但是,安装 Ops Agent 可让您更深入地了解虚拟机行为。
如需详细了解如何使用 Metrics Explorer 创建监控提醒政策,或者如需大概了解 Google Cloud上监控和指标的工作原理,请参阅 Cloud Monitoring 文档。
准备工作
可选:安装 Ops Agent,以便从 Compute Engine 实例收集更详细的数据。
如需检查哪些虚拟机实例安装了 Ops Agent,请执行以下操作:
在 Google Cloud 控制台中,前往 Monitoring 信息中心
从信息中心列表中选择虚拟机实例。
点击列表,以列表形式查看虚拟机。
此时系统会显示项目中的所有虚拟机。代理列显示 Ops Agent 安装的状态。您可以通过此页面安装或更新代理。
可选:如需更新预定义信息中心以显示事件(例如指示更新了托管式实例组的事件),请点击 event_available 选择事件,然后完成对话框。
如需详细了解事件,请参阅事件类型。
访问虚拟机可观测性指标
使用 Google Cloud 控制台中的可观测性标签页访问单个或多个虚拟机的信息。默认情况下,预定义的信息中心会显示虚拟机指标。如果您只想查看所需的特定指标,可以创建自定义信息中心。
查看单个虚拟机的可观测性指标
创建虚拟机时,您可以使用基本虚拟机指标,例如 CPU 利用率和网络流量。内存和进程利用率指标仅在安装 Ops Agent 时可用,Ops Agent 是用于从 Compute Engine 实例收集遥测数据的主要代理。
如需查看单个虚拟机的指标,请执行以下操作:
在 Google Cloud 控制台中,前往虚拟机实例页面。
选择虚拟机以打开详细信息页面。
点击可观测性标签页以显示有关虚拟机的信息。
可选:将一小时默认时间范围重置为您要监控的时间范围。
可选:如需更新预定义信息中心以显示事件(例如指示更新了托管式实例组的事件),请点击 event_available 选择事件,然后完成对话框。
如需详细了解事件,请参阅事件类型。
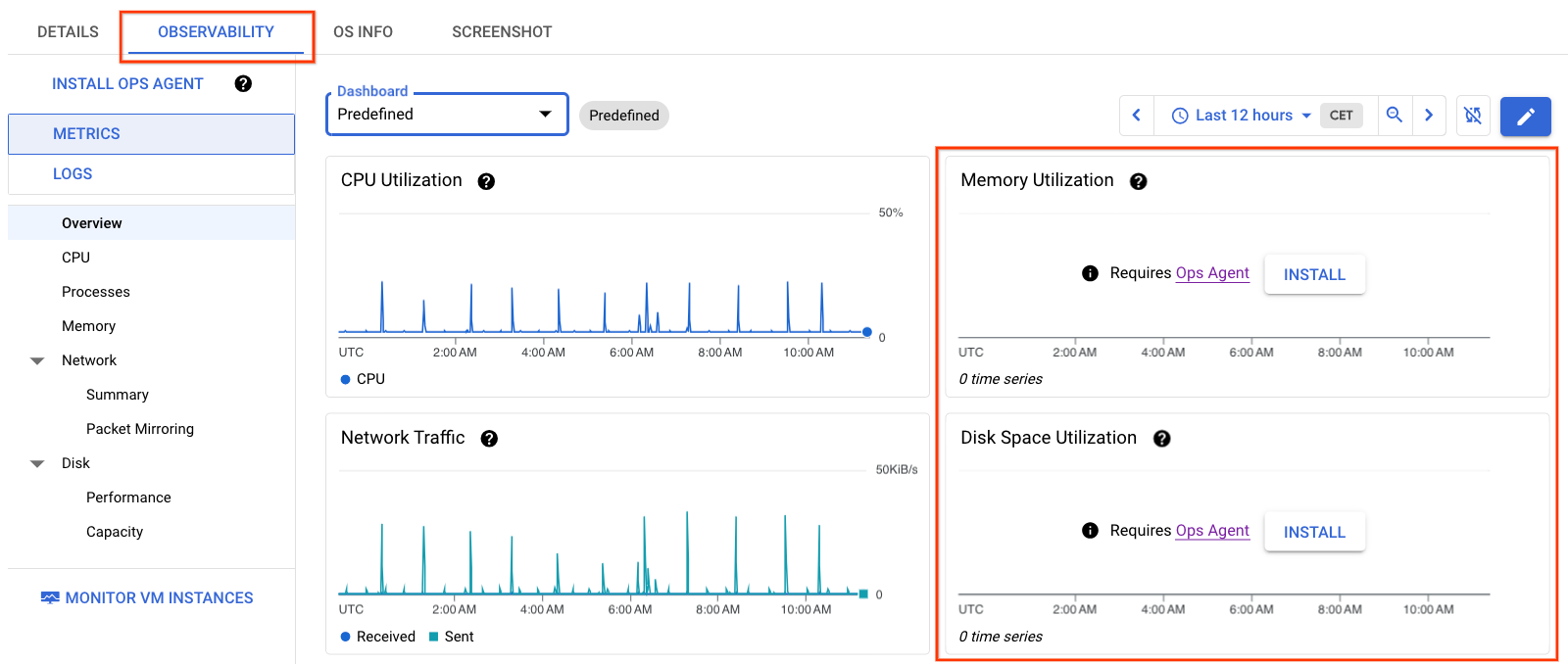
图 1 中的信息显示了虚拟机上未安装 Ops Agent 的虚拟机详情。请注意,内存和磁盘空间利用率图表没有数据。
查看多个虚拟机的可观测性指标
舰队级的可观测性显示进程利用率最高的前五个虚拟机的指标。列出的前五个虚拟机因指标而异。对于每个进程,您可能不会看到相同的五个虚拟机。虽然与安装单个虚拟机可用的数据相比,不安装 Ops Agent 的舰队级层提供了更多数据,但安装该代理可提供更多数据,以供将来的问题排查使用。
如需查看多个虚拟机的指标,请执行以下操作:
在 Google Cloud 控制台中,前往虚拟机实例页面。
点击可观测性标签页。
可选:将一小时默认时间范围重置为您要监控的时间范围。
按以下一个或多个选项过滤结果:
- ID
- 名称
- 机器类型
- 可用区
- 区域
- 实例组
- 标签
- 状态
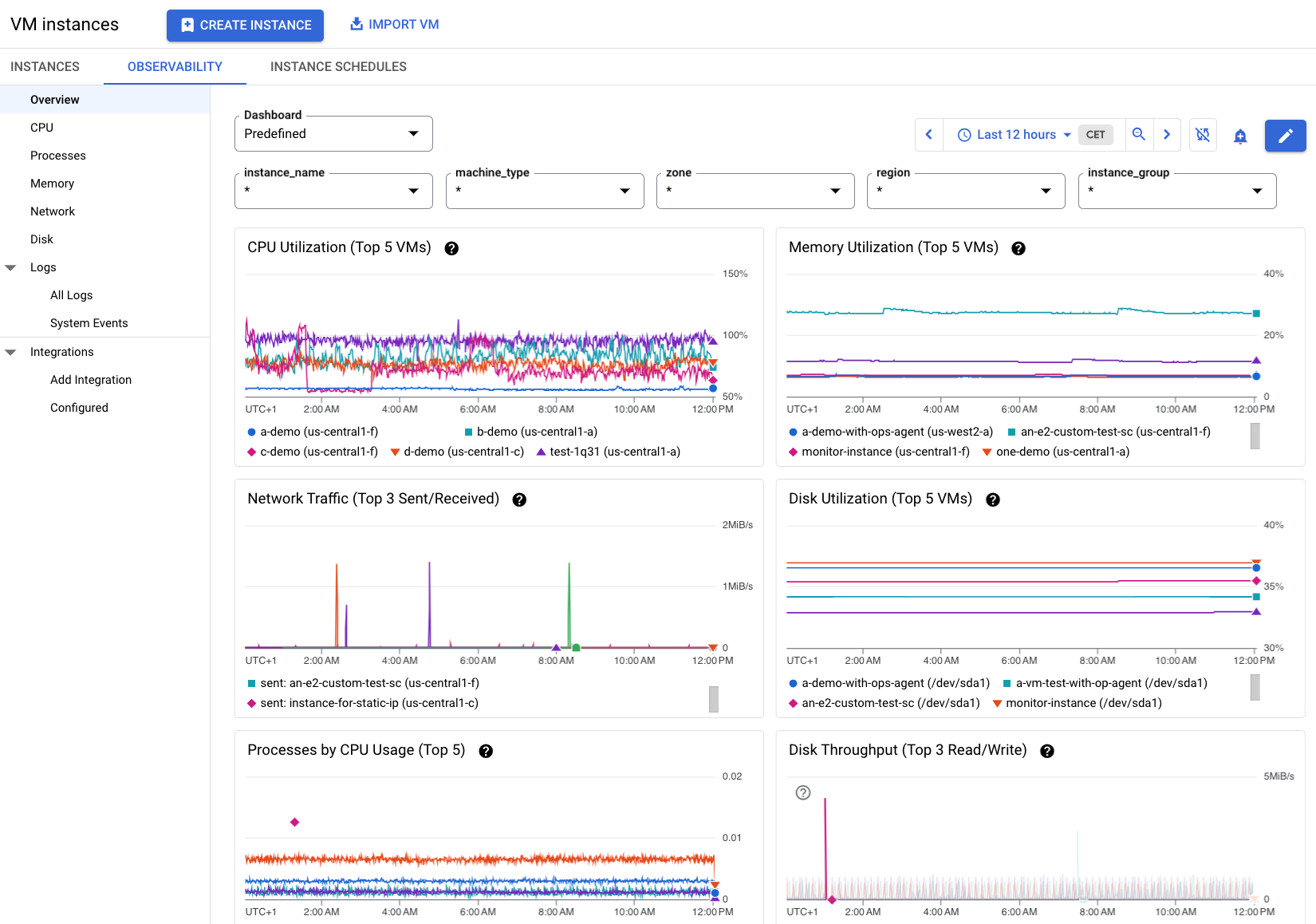
图 2 中的信息展示了当项目中的多个虚拟机安装了 Ops Agent 时,“可观测性”标签页的示例。请注意,这些虚拟机还有更多可用指标。
查看虚拟机的详细指标
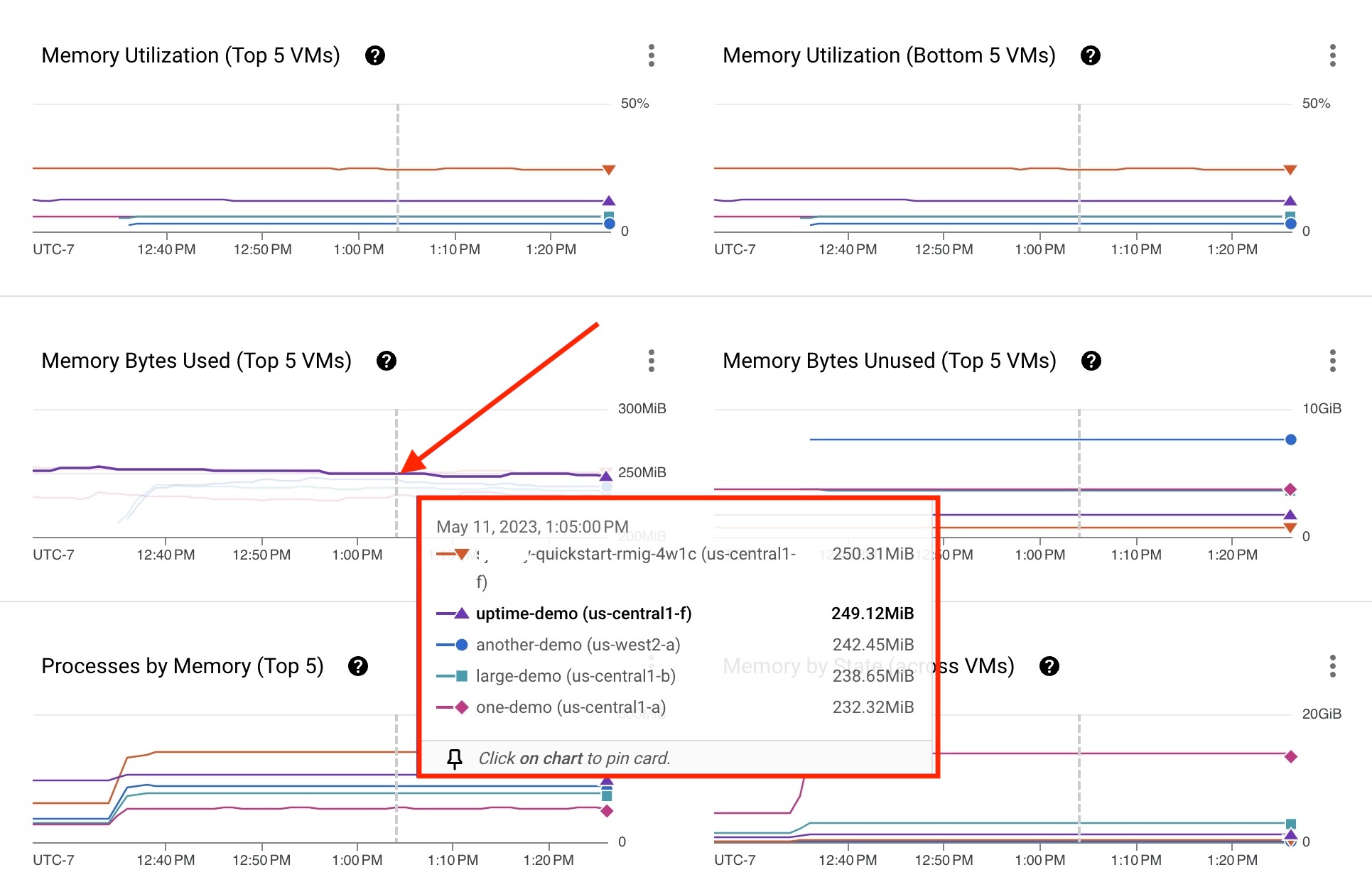
每个虚拟机进程指标都由图表上的一条折线表示。在以下示例中,uptime-demo 虚拟机已安装 Ops Agent。内存利用率数据可用于问题排查。如果卡片上未列出某个虚拟机,请按虚拟机名称进行过滤以查找特定的虚拟机。
如需从“可观测性”标签页中检索此虚拟机或前五个虚拟机中的其他虚拟机的相关信息,请执行以下操作:
- 将指针悬停在任意虚拟机的图表线条上。系统会显示一个卡片,其中包含使用该进程的前 5 个虚拟机的列表,每个虚拟机都会显示一个指标。
- 如需详细了解虚拟机的行为,请点击虚拟机图行或列表中的特定虚拟机名称。
图 3 中的卡片上显示的 uptime-demo 虚拟机显示了一些可能需要审核的指标。
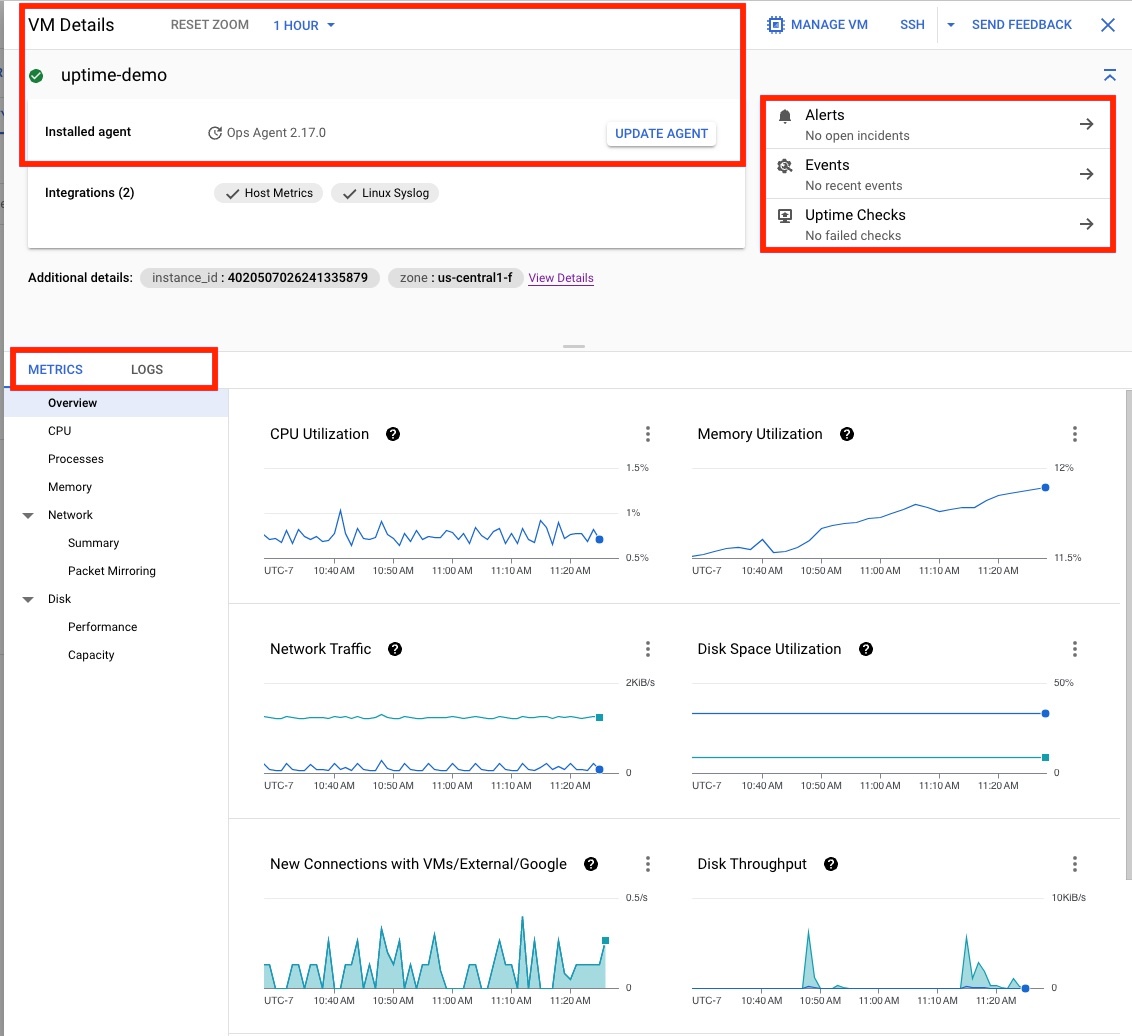
点击 uptime-demo 虚拟机以打开图 4 中显示的虚拟机详情页面,该页面提供以下信息:
- Ops Agent 状态。
- 创建提醒、检查事件或创建拨测的上下文选项。
- 用于查看有关虚拟机配置、指标和日志的详细信息的选项。
创建自定义信息中心以查看特定指标
默认情况下,Compute Engine 中的可观测性标签页提供了一个预定义的信息中心,用于显示基本虚拟机指标。如需仅查看要查看的特定指标,您可以修改预定义的信息中心并将其另存为自定义信息中心。您可以根据需要进一步自定义信息中心。
如需创建自定义信息中心,请执行以下操作:
在 Google Cloud 控制台中,前往虚拟机实例页面。
转到可观测性标签页,如下所示:
- 对于单个虚拟机:在虚拟机实例页面中,点击虚拟机名称以打开其详细信息页面,然后点击该虚拟机的可观测性标签页。
- 对于多个虚拟机:在虚拟机实例页面中,点击可观测性标签页。
如果启用了信息中心下拉列表,则可以使用自定义信息中心。如需修改自定义视图,请从下拉列表中选择自定义视图,然后在信息中心工具栏中点击 。
否则,如需自定义预定义的信息中心,请在信息中心工具栏中点击 。
Compute Engine 会创建预定义信息中心的副本,然后在修改模式下打开该副本。
在编辑器中,您可以在信息中心内添加、修改、删除可视化,调整其位置或大小。这些可视化统称为微件。如需详细了解不同的微件类型,请参阅信息中心概览。
如需添加微件,请在信息中心工具栏中点击添加微件并完成配置。
例如,如需查看包含指标数据的日志,请点击添加微件,选择日志,然后点击应用。
如需修改微件,请将指针放在微件上以激活工具栏,点击修改微件,然后使用配置微件对话框。如需将更改应用于信息中心,请在工具栏中点击应用。若要舍弃更改,请点击取消。
如需删除微件,请将指针放在微件上以激活工具栏,点击 更多图表选项,然后选择删除。
如需调整微件的位置,请使用指针拖动微件标题,将其拖动到新位置。
要调整微件的大小,请使用指针调整微件右上角。
修改完信息中心后,点击保存。
在确认更改的对话框中,点击查看自定义信息中心以转到自定义视图。
您可以通过从信息中心下拉列表中选择预定义来切换回预定义视图。
查看资源指标
如需详细了解每个资源指标,请点击可观测性标签页菜单中的每个进程:
- 探索 CPU、进程、内存利用率、网络流量和磁盘利用率。
- 通过搜索日志来识别和查看系统事件来查看日志数据。
- 添加第三方集成,并检查已配置的现有集成。
本部分的其余部分介绍某些流程如何影响您的工作负载。此信息假设虚拟机上安装了 Ops Agent。
CPU 利用率
极端 CPU 利用率的示例包括:服务器承受意外高负载,例如网站遇到流量突然激增,或大规模数据处理任务的情况。在这种情况下,CPU 可能会长时间运行 100% 容量,这可能会导致服务器变慢或无响应。
在此示例中,饱和度是问题。如果您的 CPU 利用率为 100%,这可能适合您的工作负载,但您可能需要检查其他指标以了解是否需要干预。在这种情况下,您可能需要创建提醒政策,以便在虚拟机的 CPU 利用率激增时收到通知。
凭借适当的权限,您就可以使用 SSH 连接到您的虚拟机来调查此问题。但是,如果安装了 Ops Agent,您可以查看更多历史数据来帮助您排查问题。
进程利用率
极端进程行为的一个示例是,进程占用了过多的资源(例如 CPU、内存或磁盘 I/O),以致造成性能下降甚至崩溃虚拟机。
例如,如果在某个虚拟机上运行的进程遇到内存泄露,可能会随着时间的推移开始消耗大量内存,最终导致虚拟机耗尽内存并崩溃。同样,如果进程大量使用磁盘,可能会导致虚拟机的磁盘 I/O 饱和,从而导致其他进程的响应时间较长。
内存利用率
数据库需要大量内存来执行索引、排序和联接表等操作。
举例来说,当您使用大型数据集运行数据库服务器(例如 Cloud SQL for MySQL 或 Cloud SQL for PostgreSQL)时,虚拟机上的高内存使用量。如果虚拟机的可用内存太小,将数据集重新加载到内存中可能会导致数据库运行缓慢或崩溃。
网络性能
网络性能问题是由不同因素造成的:拥塞、带宽限制、硬件或软件问题以及延迟时间。如需诊断问题,请监控网络性能指标,排查硬件和软件问题,并分析网络流量模式以确定并解决问题的根本原因。
磁盘利用率
从虚拟磁盘读取或写入大量数据时,虚拟机上的磁盘利用率较高,从而导致磁盘访问延迟且可能对虚拟机性能产生影响。
监控磁盘利用率指标(如磁盘每秒 I/O 操作次数 (IOPS)、磁盘队列长度和平均磁盘响应时间)有助于识别和诊断虚拟机上的高磁盘利用率问题。
检查日志和系统事件
所有日志页面提供有关资源的日志数据。按严重级别进行排序以找出问题并检查载荷。
审核日志会记录资源中发生的管理事件。日志可以告诉您触发事件的原因。系统会在同一行中记录和维护多个日志,因此,如果您有 20 个相同的日志,则信息将存储在一行中,而不是 20 个单独的行。
您可以将系统事件视为在较高级别发生,但可能会影响 Compute Engine 资源的事件的综合术语。当与计划事件无关的错误触发时,会发生系统事件。系统事件会在舰队级层记录。
使用第三方集成
Monitoring 可与第三方应用集成。这些集成可让您从 Apache Web Server、Cloud SQL for MySQL、Memorystore for Redis 等应用收集遥测数据,以便在 Compute Engine 和 GKE 上运行。使用 Compute Engine 时,Ops Agent 会收集第三方遥测数据。