Questo documento spiega il ciclo di vita di un'istanza Compute Engine, illustrando i vari stati che può attraversare dalla creazione all'eliminazione. Per scoprire come controllare lo stato di una o più istanze, consulta quanto segue:
Comprendendo il ciclo di vita di un'istanza, puoi eseguire più efficacemente le seguenti operazioni:
Risolvere i problemi relativi alle istanze.
Gestire le risorse delle istanze.
Pianificare le migrazioni delle istanze.
Stati delle istanze
Un'istanza di computing può passare da uno stato all'altro nel corso del suo ciclo di vita. Quando crei un'istanza, Compute Engine esegue il provisioning delle risorse per avviarla, dopodiché l'istanza passa alla gestione temporanea e si prepara al primo avvio. Una volta avviata, l'istanza è considerata in esecuzione. Un'istanza in esecuzione può essere interrotta e riavviata ripetutamente o sospesa e ripresa fino alla sua eliminazione.
Il seguente diagramma mostra i diversi stati in cui Compute Engine può impostare un'istanza:
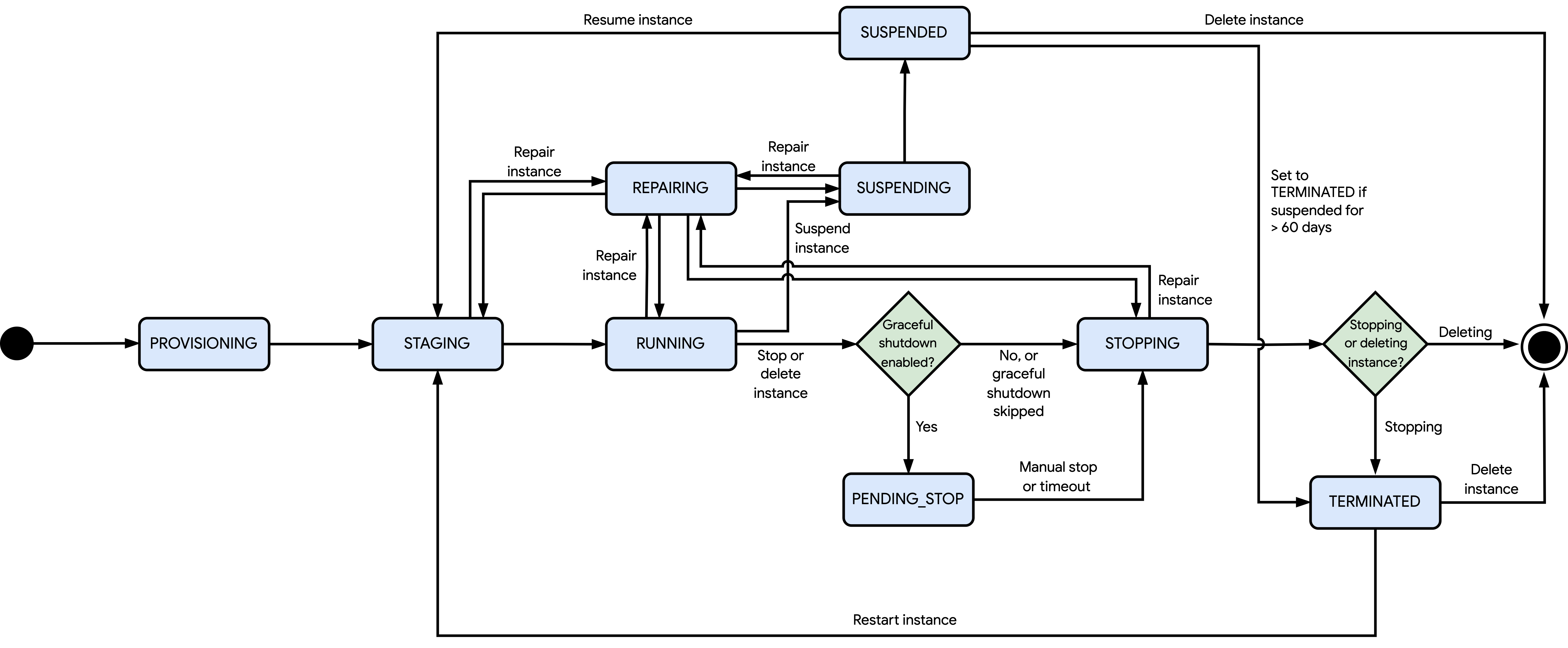
Gli stati mostrati nel diagramma precedente sono i seguenti:
PENDING: dopo aver creato una VM Flex-start autonoma con un tempo di attesa (requestValidForDuration) di almeno 90 secondi, lo stato della VM cambia inPENDING. In questo stato, Compute Engine tenta di acquisire le risorse necessarie per avviare la VM fino al termine del tempo di attesa. Se Compute Engine acquisisce le risorse entro questo periodo e disponi di una quota sufficiente per queste risorse, lo stato della VM cambia inPROVISIONING. In caso contrario, si verifica un errore e Compute Engine elimina la VM con avvio flessibile. Se non hai più bisogno della VM, puoi eliminarla facoltativamente prima del termine del tempo di attesa.PROVISIONING: dopo aver creato, riavviato o ripristinato un'istanza, Compute Engine alloca le risorse per l'istanza.STAGING: Compute Engine sta preparando l'istanza per il primo avvio per uno dei seguenti motivi:Compute Engine sta ancora creando e configurando l'istanza.
Tu o un'operazione pianificata avete richiesto di riavviare o riprendere l'istanza.
In questo stato, l'istanza non è ancora in esecuzione.
RUNNING: Compute Engine sta avviando l'istanza o l'istanza è in esecuzione. In questo stato, puoi arrestare, sospendere o eliminare l'istanza. Inoltre, Compute Engine può arrestare o eliminare l'istanza per le operazioni pianificate oppure ripararla se si verifica un errore hardware e l'istanza fa parte di un gruppo di istanze gestite (MIG).PENDING_STOP: l'istanza è in fase di arresto normale. Questo processo avviene solo se hai attivato l'arresto normale e hai richiesto di arrestare o eliminare l'istanza, oppure se Compute Engine lo fa automaticamente per un arresto o un'eliminazione pianificati. Lo stato dell'istanza diventaSTOPPINGquando si verifica una delle seguenti condizioni:Interrompi manualmente l'arresto normale.
Il periodo di arresto normale raggiunge il timeout. Se ci sono ancora attività in esecuzione, Compute Engine ne forza l'interruzione.
STOPPING: l'istanza sta arrestando il sistema operativo guest, il che si verifica nei seguenti scenari:Tu o un'operazione pianificata avete richiesto di arrestare o eliminare l'istanza.
Si è verificato un errore hardware.
A meno che tu non configuri l'istanza in modo da saltare l'arresto del sistema operativo guest, il tempo di arresto dipende dal tipo di istanza. Tuttavia, se l'istanza si arresta a causa di un errore hardware, il tempo di arresto potrebbe differire dalla durata prevista. Dopo l'arresto del sistema operativo guest e in base all'operazione in esecuzione, Compute Engine esegue una delle seguenti operazioni:
Compute Engine completa l'operazione di arresto e modifica lo stato dell'istanza in
TERMINATED.Compute Engine elimina l'istanza e tutte le risorse collegate.
TERMINATED: Compute Engine ha completato l'operazione di arresto. Le risorse collegate rimangono collegate, a meno che tu non le scolleghi. In questo stato, l'istanza rimane in stato di arresto finché non la riavvii o la elimini. Se richiedi di riavviare l'istanza, ma Compute Engine non riesce ad allocare le risorse richieste, la richiesta di riavvio non va a buon fine e l'istanza rimane nello statoTERMINATED. In caso contrario, la richiesta di riavvio va a buon fine e lo stato dell'istanza viene modificato inPROVISIONING.REPAIRING: Compute Engine sta riparando l'istanza. Compute Engine ripara un'istanza se rileva un errore interno o se il server host dell'istanza non è disponibile a causa di operazioni di manutenzione. Mentre viene riparata un'istanza, si verifica quanto segue:Non puoi utilizzare l'istanza.
L'accordo sul livello del servizio (SLA) non copre l'istanza.
Se Compute Engine ripara l'istanza, la riporta allo stato che aveva prima dell'inizio dell'operazione di riparazione. Questo stato può essere
STAGING,RUNNING,SUSPENDINGoSTOPPING. Se la tua istanza è configurata per il riavvio automatico (automaticRestart) al termine dell'operazione di riparazione, puoi facoltativamente arrestare l'istanza durante la procedura di riparazione. Questa azione impedisce il riavvio automatico dell'istanza al termine della riparazione, lasciandola nello statoTERMINATED.SUSPENDING: Compute Engine ha avviato l'operazione di sospensione dell'istanza dopo che hai richiesto di sospenderla. In questo stato, puoi solo attendere il completamento dell'operazione di sospensione.SUSPENDED: Compute Engine ha completato l'operazione di sospensione. In questo stato, puoi ripristinare o eliminare l'istanza. Se richiedi di riattivare l'istanza, ma Compute Engine non riesce ad allocare le risorse richieste, la richiesta di riattivazione non va a buon fine e l'istanza rimane nello statoSUSPENDED. In caso contrario, la richiesta di ripristino va a buon fine e lo stato dell'istanza viene modificato inPROVISIONING. L'istanza può rimanere nello statoSUSPENDEDper un massimo di 60 giorni. Trascorso questo periodo di tempo, Compute Engine modifica lo stato dell'istanza inTERMINATED.
Guasto hardware
In rari casi, un'istanza di computing potrebbe non riuscire a causa di un'interruzione imprevista, di un errore hardware o di un altro problema di sistema. Google consiglia di ridurre al minimo i guasti hardware utilizzando volumi di archiviazione permanente, eseguendo regolarmente il backup dei dati e progettando il sistema in modo che un singolo guasto dell'istanza non sia catastrofico. Per saperne di più, scopri come progettare sistemi solidi.
Se un'istanza non riesce, Compute Engine la riavvia automaticamente utilizzando gli stessi metadati, le stesse impostazioni dell'istanza e lo stesso disco di avvio. Per modificare il comportamento di riavvio automatico di un'istanza, consulta Imposta la policy di manutenzione dell'host per un'istanza di computing.
Prezzi
Le istanze di computing ti vengono addebitate nel modo seguente:
L'utilizzo della CPU ti viene addebitato quando l'istanza è nei seguenti stati:
RUNNINGPENDING_STOP
La memoria utilizzata ti viene addebitata quando l'istanza è nei seguenti stati:
RUNNINGPENDING_STOPSUSPENDINGSUSPENDED
Per le risorse collegate, come i dischi o gli indirizzi IP esterni, ti vengono addebitati costi fino a quando le risorse esistono, indipendentemente dallo stato dell'istanza.
Per saperne di più, consulta Prezzi delle istanze VM.
Passaggi successivi
Visualizza lo stato di una o più istanze di computing procedendo nel seguente modo: