This document explains the lifecycle of a Compute Engine instance, covering the various states it can go through from creation to deletion. To learn how to check the state of one or more instances, see the following:
By understanding the lifecycle of an instance, you can do the following more effectively:
Troubleshoot instance issues.
Manage instance resources.
Plan instance migrations.
Instance states
A compute instance can transition through different states as part of its lifecycle. When creating an instance, Compute Engine provisions resources to start it, after which the instance moves into staging and prepares for first boot. After the instance starts, it's considered running. A running instance can be repeatedly stopped and restarted, or suspended and resumed, until its deletion.
The following diagram shows the different states that Compute Engine can set an instance to:
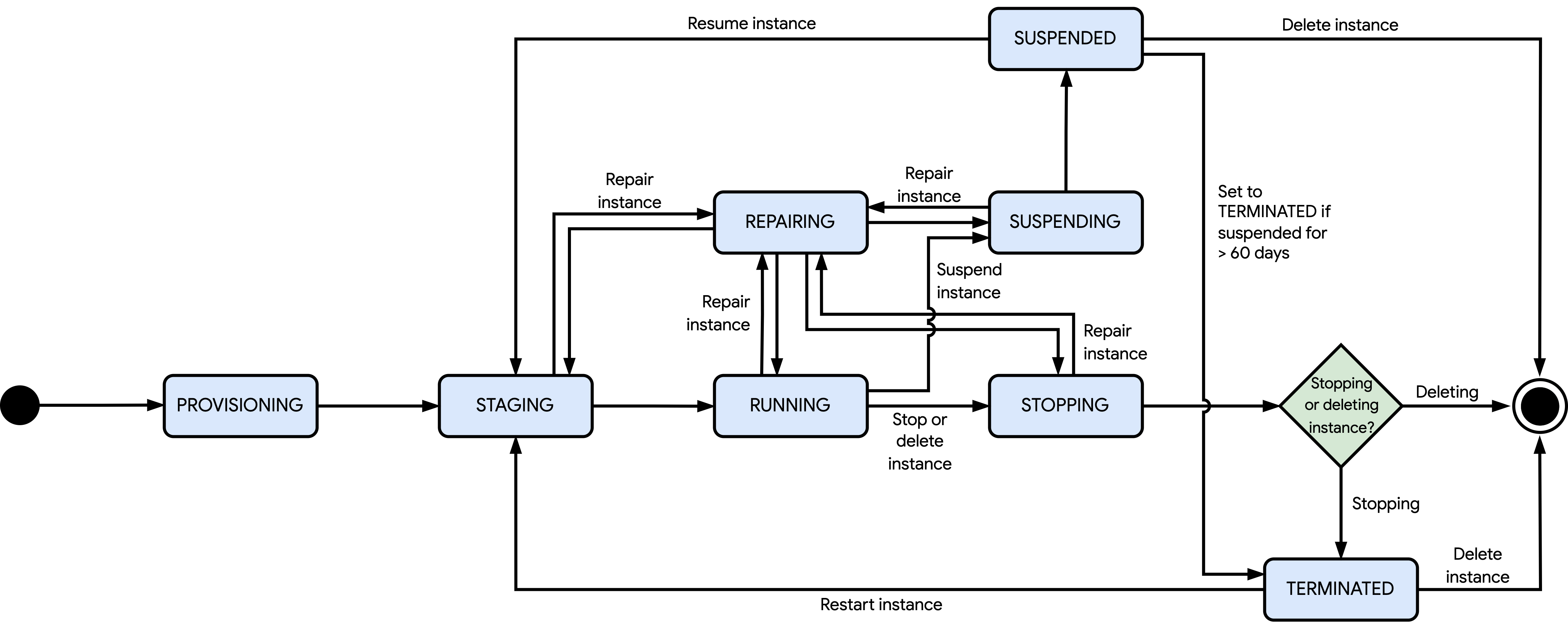
The states shown in the preceding diagram are as follows:
PENDING: after you create a standalone Flex-start VM with a wait time (requestValidForDuration) that is 90 seconds or longer, the VM state changes toPENDING. In this state, Compute Engine attempts to acquire the necessary resources to start your VM until its wait time ends. If Compute Engine acquires the resources within this time and you have sufficient quota for those resources, then the VM state changes toPROVISIONING. Otherwise, you encounter an error and Compute Engine deletes the Flex-start VM. You can optionally delete the Flex-start VM before the wait time ends if you no longer need the VM.PROVISIONING: after you create, restart, or resume an instance, Compute Engine allocates resources for the instance.STAGING: Compute Engine is preparing the instance for first boot due to one of the following reasons:Compute Engine is still creating and configuring the instance.
You, or a scheduled operation, have requested to restart or resume the instance.
In this state, the instance isn't running yet.
RUNNING: Compute Engine is booting up the instance, or the instance is running. In this state, you can stop, suspend, or delete the instance. Additionally, Compute Engine can stop or delete the instance for scheduled operations, or repair the instance if a hardware error occurs and the instance is part of a managed instance group (MIG).PENDING_STOP: the instance is gracefully shutting down. This shutdown process happens only if you've enabled graceful shutdown and you've requested to stop or delete the instance, or Compute Engine is doing so automatically for a scheduled stop or deletion. The instance state changes toSTOPPINGwhen one of the following happens:You manually end the graceful shutdown.
The graceful shutdown period times out. If any tasks are still running, then Compute Engine forcefully stops them.
STOPPING: the instance is shutting down its guest OS, which happens in the following scenarios:You, or a scheduled operation, have requested to stop or delete the instance.
A hardware error occurred.
Unless you configure the instance to skip the guest OS shutdown, the shutdown time depends on the instance type. However, if the instance stops due to a hardware error, the shutdown time might differ from the expected length. After the guest OS shuts down and based on the operation that is running, Compute Engine does one of the following:
Compute Engine completes the stops operation and changes the instance state to
TERMINATED.Compute Engine deletes the instance and all attached resources.
TERMINATED: Compute Engine has completed the stop operation. The attached resources remain attached unless you detach them. In this state, the instance remains stopped until you restart or delete it. If you request to restart the instance, but Compute Engine can't allocate your requested resources, then the restart request fails and the instance remains in theTERMINATEDstate. Otherwise, the restart request succeeds and the instance state changes toPROVISIONING.REPAIRING: Compute Engine is repairing the instance. Compute Engine repairs an instance if it encounters an internal error or the instance's host server is unavailable due to maintenance. While an instance is in repair, the following happens:You can't use the instance.
The service level agreement (SLA) doesn't cover the instance.
If Compute Engine successfully repairs the instance, then it returns the instance state to its original state before the repair operation began. This state can be
STAGING,RUNNING,SUSPENDING, orSTOPPING. If your instance is configured to automatically restart (automaticRestart) after the repair operation completes, then you can optionally stop the instance during the repair process. This action prevents the instance from automatically restarting after the repair completes, leaving the instance in theTERMINATEDstate.SUSPENDING: Compute Engine has started the suspend operation of the instance after you've requested to suspend it. In this state, you can only wait for the suspend operation to complete.SUSPENDED: Compute Engine has completed the suspend operation. In this state, you can resume or delete the instance. If you request to resume the instance, but Compute Engine can't allocate your requested resources, then the resume request fails and the instance remains in theSUSPENDEDstate. Otherwise, the resume request succeeds and the instance state changes toPROVISIONING. The instance can remain in theSUSPENDEDstate for up to 60 days. After that time, Compute Engine changes the instance state toTERMINATED.
Hardware failure
Rarely, a compute instance might fail due to an unexpected outage, hardware error, or another system issue. Google recommends mitigating hardware failures by using persistent storage volumes, routinely backing up your data, and designing your system so that a single instance failure isn't catastrophic. For more information, see how to design robust systems.
If an instance fails, then Compute Engine automatically restarts the instance using the same boot disk, metadata, and instance settings. To modify the automatic restart behavior of an instance, see Set the host maintenance policy for a compute instance.
Pricing
You're charged for a compute instance as follows:
For CPU usage, you're charged when the instance is in the following states:
RUNNINGPENDING_STOP
For memory usage, you're charged when the instance is in the following states:
RUNNINGPENDING_STOPSUSPENDINGSUSPENDED
For attached resources like disks or external IP addresses, you're charged until the resources exist, regardless of the instance state.
For more information, see VM instance pricing.
What's next
View the state of one or more compute instances by doing the following: