You can track metrics such as GPU utilization and GPU memory from your virtual machine (VM) instances by using the Ops Agent, which is Google's recommended telemetry collection solution for Compute Engine. By using the Ops Agent, you can manage your GPU VMs as follows:
- Visualize the health of your NVIDIA GPU fleet with our pre-configured dashboards.
- Optimize costs by identifying underutilized GPUs and consolidating workloads.
- Plan scaling by looking at trends to decide when to expand GPU capacity or upgrade existing GPUs.
- Use NVIDIA Data Center GPU Manager (DCGM) profiling metrics to identify bottlenecks and performance issues within your GPUs.
- Set up managed instance groups (MIGs) to autoscale resources.
- Get alerts on metrics from your NVIDIA GPUs.
This document covers the procedures for monitoring GPUs on Linux VMs by using
the Ops Agent. Alternatively, a reporting script is available on GitHub that can
also be setup for monitoring GPU usage on Linux VMs, see
compute-gpu-monitoring monitoring script.
This script is not actively maintained.
For monitoring GPUs on Windows VMs, see Monitoring GPU performance (Windows).
Overview
The Ops Agent, version 2.38.0 or later, can automatically track GPU utilization and GPU memory usage rates on your Linux VMs that have the agent installed. These metrics, obtained from the NVIDIA Management Library (NVML), are tracked per GPU and per process for any process that uses GPUs. To view the metrics that are monitored by the Ops Agent, see Agent metrics: gpu.
You can also set up the NVIDIA Data Center GPU Manager (DCGM) integration with the Ops Agent. This integration allows the Ops Agent to track metrics using the hardware counters on the GPU. DCGM provides access to the GPU device-level metrics. These include Streaming Multiprocessor (SM) block utilization, SM occupancy, SM pipe utilization, PCIe traffic rate, and NVLink traffic rate. To view the metrics monitored by the Ops Agent, see Third-party application metrics: NVIDIA Data Center GPU Manager (DCGM).
To review GPU metrics by using the Ops Agent, complete the following steps:
- On each VM, check that you have met the requirements.
- On each VM, install the Ops Agent.
- Optional: On each VM, set up the NVIDIA Data Center GPU Manager (DCGM) integration.
- Review metrics in Cloud Monitoring.
Limitations
- The Ops Agent doesn't track GPU utilization on VMs that use Container-Optimized OS.
Requirements
On each of your VMs, check that you meet the following requirements:
- Each VM must have GPUs attached.
- Each VM must have a GPU driver installed.
- The Linux operating system and version for each of your VM must support the Ops Agent. See the list of Linux operating systems that support the Ops Agent.
- Ensure you have
sudoaccess to each VM.
Install the Ops Agent
To install the Ops Agent, complete the following steps:
If you were previously using the
compute-gpu-monitoringmonitoring script to track GPU utilization, disable the service before installing the Ops Agent. To disable the monitoring script, run the following command:sudo systemctl --no-reload --now disable google_gpu_monitoring_agent
Install the latest version of the Ops Agent. For detailed instructions, see Installing the Ops Agent.
After you have installed the Ops agent, if you need to install or upgrade your GPU drivers by using the installation scripts provided by Compute Engine, review the limitations section.
Review NVML metrics in Compute Engine
You can review the NVML metrics that the Ops Agent collects from the Observability tabs for Compute Engine Linux VM instances.
To view the metrics for a single VM do the following:
In the Google Cloud console, go to the VM instances page.
Select a VM to open the Details page.
Click the Observability tab to display information about the VM.
Select the GPU quick filter.
To view the metrics for multiple VMs, do the following:
In the Google Cloud console, go to the VM instances page.
Click the Observability tab.
Select the GPU quick filter.
Optional: Set up NVIDIA Data Center GPU Manager (DCGM) integration
The Ops Agent also provides integration for NVIDIA Data Center GPU Manager (DCGM) to collect key advanced GPU metrics such as Streaming Multiprocessor (SM) block utilization, SM occupancy, SM pipe utilization, PCIe traffic rate, and NVLink traffic rate.
These advanced GPU metrics are not collected from NVIDIA P100 and P4 models.
For detailed instructions on how to setup and use this integration on each VM, see NVIDIA Data Center GPU Manager (DCGM).
Review DCGM metrics in Cloud Monitoring
In the Google Cloud console, go to the Monitoring > Dashboards page.
Select the Sample Library tab.
In the Filter field, type NVIDIA. The NVIDIA GPU Monitoring Overview (GCE and GKE) dashboard displays.
If you have set up the NVIDIA Data Center GPU Manager (DCGM) integration, the NVIDIA GPU Monitoring Advanced DCGM Metrics (GCE Only) dashboard also displays.
For the required dashboard, click Preview. The Sample dashboard preview page displays.
From the Sample dashboard preview page, click Import sample dashboard.
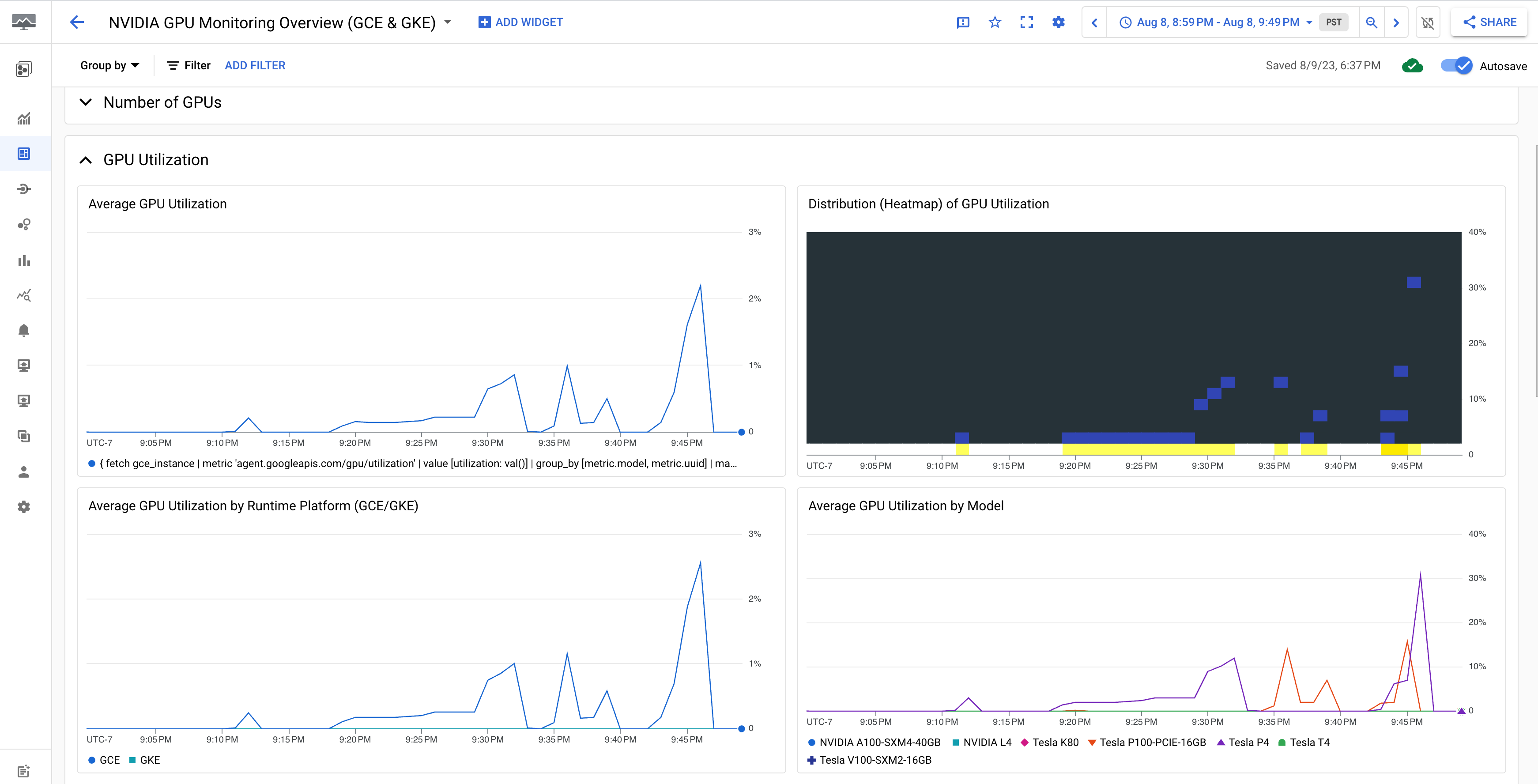
The NVIDIA GPU Monitoring Overview (GCE and GKE) dashboard displays the GPU metrics such as GPU utilization, NIC traffic rate, and GPU memory usage.
Your GPU utilization display is similar to the following output:
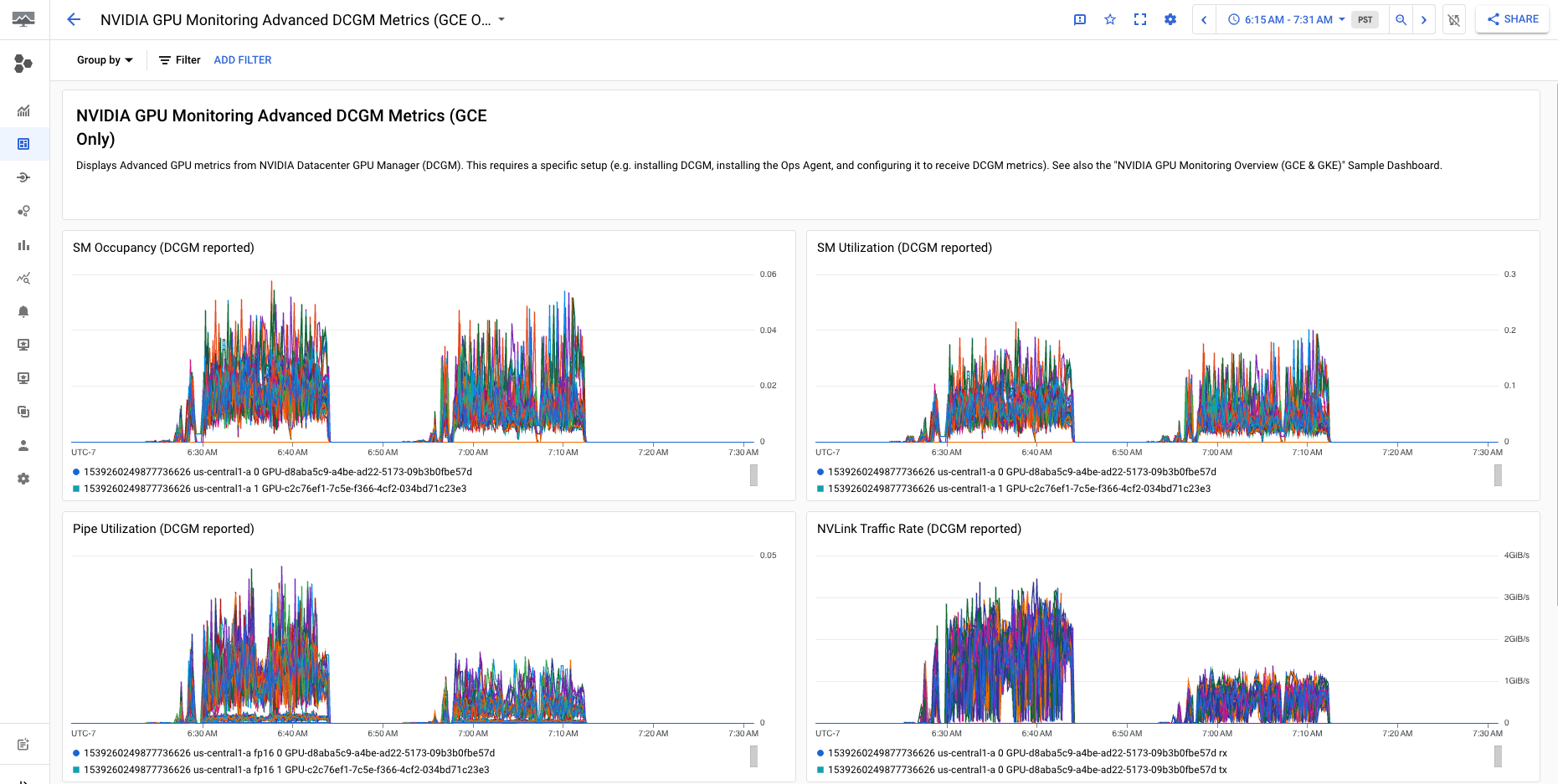
The NVIDIA GPU Monitoring Advanced DCGM Metrics (GCE Only) dashboard displays key advanced metrics such as SM utilization, SM occupancy, SM pipe utilization, PCIe traffic rate, and NVLink traffic rate.
Your Advanced DCGM Metric display is similar to the following output:
What's next?
- To handle GPU host maintenance, see Handling GPU host maintenance events.
- To improve network performance, see Use higher network bandwidth.