Rastreie métricas como utilização de GPU e memória da GPU de suas instâncias de máquina virtual (VM) usando o Agente de operações, que é a solução de coleta de telemetria recomendada pelo Google para o Compute Engine. Ao usar o Agente de operações, é possível gerenciar as VMs da GPU da seguinte maneira:
- Visualize a integridade da sua frota de GPUs NVIDIA com nossos painéis pré-configurados.
- Otimize os custos identificando GPUs subutilizadas e consolidando cargas de trabalho.
- Planeje o escalonamento analisando as tendências para decidir quando expandir a capacidade da GPU ou fazer upgrade das GPUs atuais.
- Use as métricas de criação de perfil do NVIDIA Data Center GPU Manager (DCGM) para identificar gargalos e problemas de desempenho nas GPUs.
- Configure grupos gerenciados de instâncias (MIGs) para escalonar recursos automaticamente.
- Receba alertas sobre métricas das suas GPUs NVIDIA.
Neste documento, abordamos os procedimentos para monitorar GPUs em VMs do Linux usando
o Agente de operações. Como alternativa, há um script de relatório disponível no GitHub que também pode
ser configurado para monitorar o uso da GPU em VMs do Linux. Consulte
Script de monitoramento compute-gpu-monitoring.
Este script não é mantido ativamente.
Para monitorar GPUs em VMs do Windows, consulte Como monitorar o desempenho da GPU (Windows).
Visão geral
O Agente de operações, versão 2.38.0 ou posterior, pode rastrear automaticamente a utilização da GPU e as taxas de uso da memória GPU nas VMs do Linux que têm o agente instalado. Essas métricas, coletadas na Biblioteca de Gerenciamento NVIDIA (NVML), são rastreadas por GPU e por processo para qualquer processo que use GPUs. Para conferir as métricas monitoradas pelo agente de operações, consulte Métricas do agente: gpu.
Também é possível configurar a integração do NVIDIA Data Center GPU Manager (DCGM) com o Agente de operações. Essa integração permite que o agente de operações rastreie métricas usando os contadores de hardware na GPU. O DCGM fornece acesso às métricas no nível do dispositivo da GPU. Isso inclui a utilização de blocos de Multiprocessador de streaming (SM), a ocupação do SM, a utilização do pipeline do SM, a taxa de tráfego PCIe e a taxa de tráfego do NVLink. Para conferir as métricas monitoradas pelo agente de operações, consulte Métricas de aplicativos de terceiros: gerenciador de GPU do NVIDIA Data Center (DCGM).
Para analisar as métricas da GPU usando o agente de operações, siga estas etapas:
- Em cada VM, verifique se você atendeu aos requisitos.
- Em cada VM, instale o Agente de operações.
- Opcional: configure para cada VM a integração do Gerenciador de GPUs do data center (DCGM) da NVIDIA.
- Analisar métricas no Cloud Monitoring.
Limitações
- O Agente de operações não rastreia a utilização da GPU em VMs que usam o Container-Optimized OS.
Requisitos
Em cada uma das VMs, verifique se você atende aos requisitos a seguir:
- Cada VM precisa ter GPUs conectadas.
- Cada VM precisa ter um driver de GPU instalado.
- O sistema operacional e a versão do Linux para cada uma das VMs precisam ser compatíveis com o agente de operações. Confira a lista de sistemas operacionais Linux compatíveis com o agente de operações.
- Verifique se você tem acesso a
sudopara cada VM.
Instalar o Agente de operações
Para instalar o agente, siga estes passos:
Se você estava usando o script de monitoramento
compute-gpu-monitoringpara monitorar a utilização da GPU, desative o serviço antes de instalar o agente de operações. Para desativar o script de monitoramento, execute o seguinte comando:sudo systemctl --no-reload --now disable google_gpu_monitoring_agent
Como instalar a versão mais recente do agente de operações Para instruções detalhadas, consulte Como instalar o Agente de operações.
Depois de instalar o agente de operações, se você precisar instalar ou fazer upgrade dos drivers de GPU usando os scripts de instalação fornecidos pelo Compute Engine, confira as limitações..
Analisar as métricas de NVML no Compute Engine
É possível analisar as métricas de NVML coletadas pelo agente de operações para as instâncias de VM Linux do Compute Engine nas guias Observabilidade.
Para visualizar as métricas de uma única VM, faça o seguinte:
No console do Google Cloud , acesse a página Instâncias de VM.
Selecione uma VM para abrir a página Detalhes.
Clique na guia Observabilidade para exibir informações sobre a VM.
Selecione o filtro rápido GPU.
Para visualizar as métricas de várias VMs, faça o seguinte:
No console do Google Cloud , acesse a página Instâncias de VM.
Clique na guia Observabilidade.
Selecione o filtro rápido GPU.
Opcional: configurar a integração do NVIDIA Data Center GPU Manager (DCGM)
O Agente de operações também oferece integração com o NVIDIA Data Center GPU Manager (DCGM) para coletar métricas de GPU avançadas importantes, como utilização de blocos de Multiprocessador de Streaming (SM), ocupação de SM, utilização de pipeline SM, taxa de tráfego PCIe e taxa de tráfego de NVLink.
Essas métricas avançadas de GPU não são coletadas para os modelos NVIDIA P100 e P4.
Para instruções detalhadas sobre como configurar e usar essa integração em cada VM, consulte NVIDIA Data Center GPU Manager (DCGM).
Analisar as métricas de DCGM no Cloud Monitoring
No console Google Cloud , acesse a página Monitoring > Painéis.
Selecione a guia Biblioteca de amostra.
No campo Filtro , digite NVIDIA. O painel Visão geral do monitoramento de GPU NVIDIA (GCE e GKE) é exibido.
Se você configurou a integração do NVIDIA Data Center GPU Manager (DCGM), o painel Métricas avançadas de DCGM do monitoramento de GPU NVIDIA (somente GCE) também será exibido.
No painel necessário, clique em Visualizar. A página Visualização do painel de amostra é exibida.
Na página Visualização do painel de amostra, clique em Importar painel de amostra.
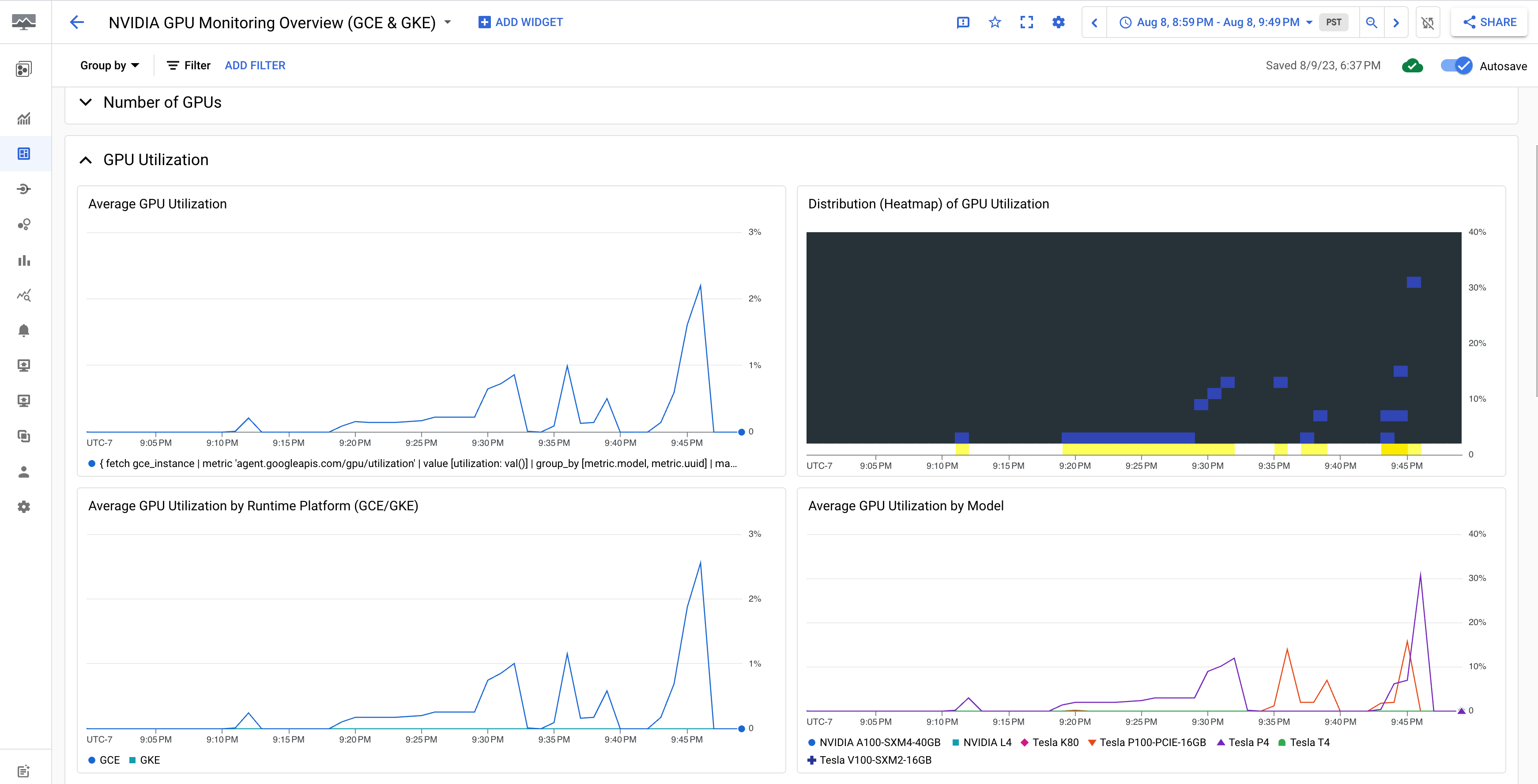
O painel Visão geral do monitoramento de GPU NVIDIA (GCE e GKE) exibe as métricas da GPU, como o uso da GPU, a taxa de tráfego da NIC e o uso da memória da GPU.
A exibição de utilização da GPU é semelhante a esta:
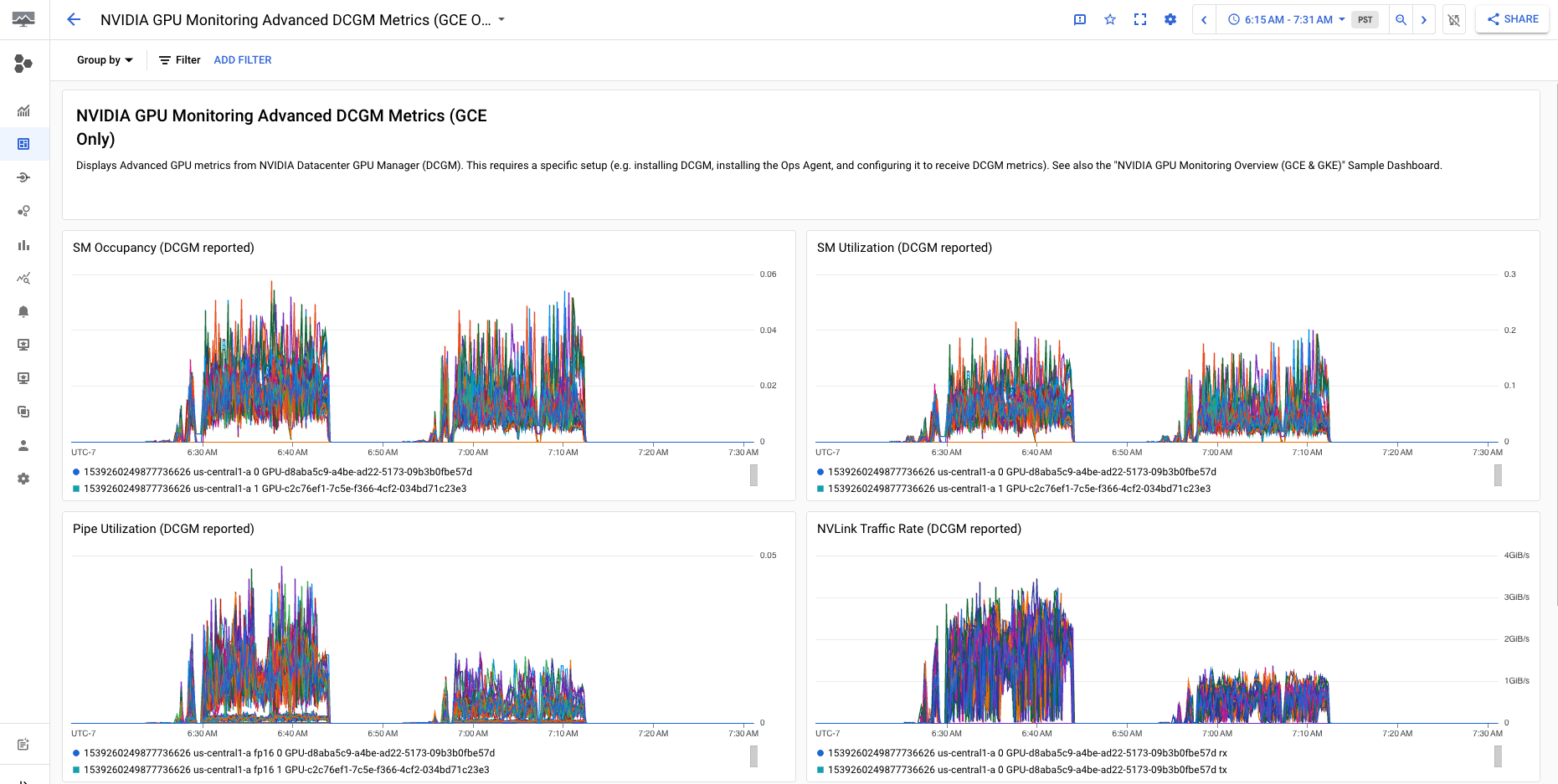
O Métricas avançadas de DCGM do monitoramento de GPU NVIDIA (somente GCE) O painel exibe as principais métricas avançadas, como a utilização de SM, a ocupação de SM, a utilização do pipeline do SM, a taxa de tráfego do PCIe e a taxa de tráfego do NVLink.
A exibição da métrica avançada do DCGM é semelhante à seguinte saída:
A seguir
- Para lidar com a manutenção do host da GPU, consulte "Como manipular eventos de manutenção do host da GPU".
- Para melhorar o desempenho da rede, consulte Usar uma largura de banda de rede maior.