Vous pouvez suivre des métriques telles que l'utilisation du GPU et la mémoire du GPU sur vos instances de machine virtuelle (VM) à l'aide de l'agent Ops, la solution de collecte de télémétrie recommandée par Google pour Compute Engine. En utilisant l'agent Ops, vous pouvez gérer vos VM avec GPU comme suit :
- Visualisez l'état de votre parc de GPU NVIDIA à l'aide de nos tableaux de bord préconfigurés.
- Optimisez les coûts en identifiant les GPU sous-utilisés et en consolidant les charges de travail.
- Planifiez le scaling en examinant les tendances pour décider quand augmenter la capacité des GPU ou mettre à niveau les GPU existants.
- Utilisez les métriques de profilage GPU (DCGM) de NVIDIA pour identifier les goulots d'étranglement et les problèmes de performances dans vos GPU.
- Configurer des groupes d'instances gérés (MIG) pour effectuer l'autoscaling des ressources.
- Recevez des alertes sur les métriques de vos GPU NVIDIA.
Ce document décrit les procédures de surveillance des GPU sur les VM Linux à l'aide de l'agent Ops. Un script de création de rapports est également disponible sur GitHub. Vous pouvez également le configurer pour surveiller l'utilisation des GPU sur les VM Linux. Pour plus d'informations, consultez la page Script de surveillance compute-gpu-monitoring.
Ce script n'est pas activement géré.
Pour surveiller les GPU sur les VM Windows, consultez la page Surveiller les performances des GPU (Windows).
Présentation
L'agent Ops, version 2.38.0 ou ultérieure, peut suivre automatiquement l'utilisation du GPU et les taux d'utilisation de la mémoire GPU sur les VM Linux sur lesquelles l'agent est installé. Ces métriques, obtenues à partir de la bibliothèque de gestion NVIDIA (NVML), sont suivies par GPU et par processus, pour chaque processus utilisant des GPU. Pour afficher les métriques surveillées par l'agent Ops, consultez Métriques d'agent : GPU.
Vous pouvez également configurer l'intégration du gestionnaire de GPU NVIDIA Data Center (DCGM) avec l'agent Ops. Cette intégration permet à l'agent Ops de suivre les métriques en utilisant les compteurs matériels sur le GPU. La DCGM permet d'accéder aux métriques au niveau du GPU. Celles-ci incluent l'utilisation des blocs de multiprocesseurs de flux (SM, Streaming Multiprocessor), l'occupation associée aux SM, l'utilisation du pipeline SM, le taux de trafic PCIe et le taux de trafic NVLink. Pour afficher les métriques surveillées par l'agent Ops, consultez la page Métriques des applications tierces : gestionnaire GPU de centre de données (DCGM) NVIDIA.
Pour examiner les métriques GPU à l'aide de l'agent Ops, procédez comme suit :
- Sur chaque VM, vérifiez que vous remplissez les conditions requises.
- Sur chaque VM, installez l'agent Ops.
- Facultatif : sur chaque VM, configurez l'intégration du gestionnaire GPU de centre de données (DCGM) NVIDIA.
- Examinez les métriques dans Cloud Monitoring.
Limites
- L'agent Ops ne suit pas l'utilisation du GPU sur les VM qui utilisent Container-Optimized OS.
Conditions requises
Sur chacune de vos VM, vérifiez que vous remplissez les conditions suivantes :
- Chaque VM doit avoir des GPU connectés.
- Chaque VM doit disposer d'un pilote GPU installé.
- Le système d'exploitation Linux et la version de chacune de vos VM doivent être compatibles avec l'agent Ops. Consultez la liste des systèmes d'exploitation Linux compatibles avec l'agent Ops.
- Assurez-vous de disposer d'un accès
sudoà chaque VM.
Installer l'agent Ops
Pour installer l'agent Ops, procédez comme suit :
Si vous utilisiez le script de surveillance
compute-gpu-monitoringpour suivre l'utilisation des GPU, désactivez le service avant d'installer l'agent Ops. Pour désactiver le script de surveillance, exécutez la commande suivante :sudo systemctl --no-reload --now disable google_gpu_monitoring_agent
Installez la dernière version de l'agent Ops. Pour obtenir des instructions détaillées, consultez la page Installer l'agent Ops.
Après avoir installé l'agent Ops, si vous devez installer ou mettre à niveau vos pilotes de GPU à l'aide des scripts d'installation fournis par Compute Engine, consultez la section limitations.
Consulter les métriques NVML dans Compute Engine
Vous pouvez consulter les métriques NVML collectées par l'agent Ops dans les onglets Observabilité, pour les instances de VM Linux Compute Engine.
Pour afficher les métriques pour une seule VM, procédez comme suit :
Dans la console Google Cloud , accédez à la page Instances de VM.
Sélectionnez une VM pour ouvrir la page Détails.
Cliquez sur l'onglet Observability (Observabilité) pour afficher des informations sur la VM.
Sélectionnez le filtre rapide GPU.
Pour afficher les métriques pour plusieurs VM, procédez comme suit :
Dans la console Google Cloud , accédez à la page Instances de VM.
Cliquez sur l'onglet Observabilité.
Sélectionnez le filtre rapide GPU.
Facultatif : configurer l'intégration du gestionnaire de GPU NVIDIA Data Center
L'agent Ops fournit également une intégration pour le gestionnaire GPU de centre de données (DCGM) NVIDIA, afin de collecter des métriques de GPU avancées clés, telles que l'utilisation de blocs de multiprocesseurs de flux (SM), l'occupation associée aux SM, l'utilisation du pipeline SM, le taux de trafic PCIe et le taux de trafic NVLink.
Ces métriques GPU avancées ne sont pas collectées à partir des modèles NVIDIA P100 et P4.
Pour obtenir des instructions détaillées sur la configuration et l'utilisation de cette intégration sur chaque VM, consultez la page Gestionnaire GPU de centre de données (DCGM) NVIDIA.
Examiner les métriques DCGM dans Cloud Monitoring
Dans la console Google Cloud , accédez à la page Surveillance > Tableaux de bord.
Sélectionnez l'onglet Bibliothèque d'exemples.
Dans le champ Filtre , saisissez NVIDIA. Le tableau de bord Présentation de la surveillance des GPU NVIDIA (GCE et GKE) s'affiche.
Si vous avez configuré l'intégration du gestionnaire de GPU NVIDIA Data Center (DCGM), le tableau de bord Métriques DCGM avancées de surveillance des GPU NVIDIA s'affiche également.
Pour obtenir le tableau de bord requis, cliquez sur Aperçu. La page Exemple d'aperçu de tableau de bord s'affiche.
Sur la page Exemple d'aperçu de tableau de bord, cliquez sur Importer un exemple de tableau de bord.
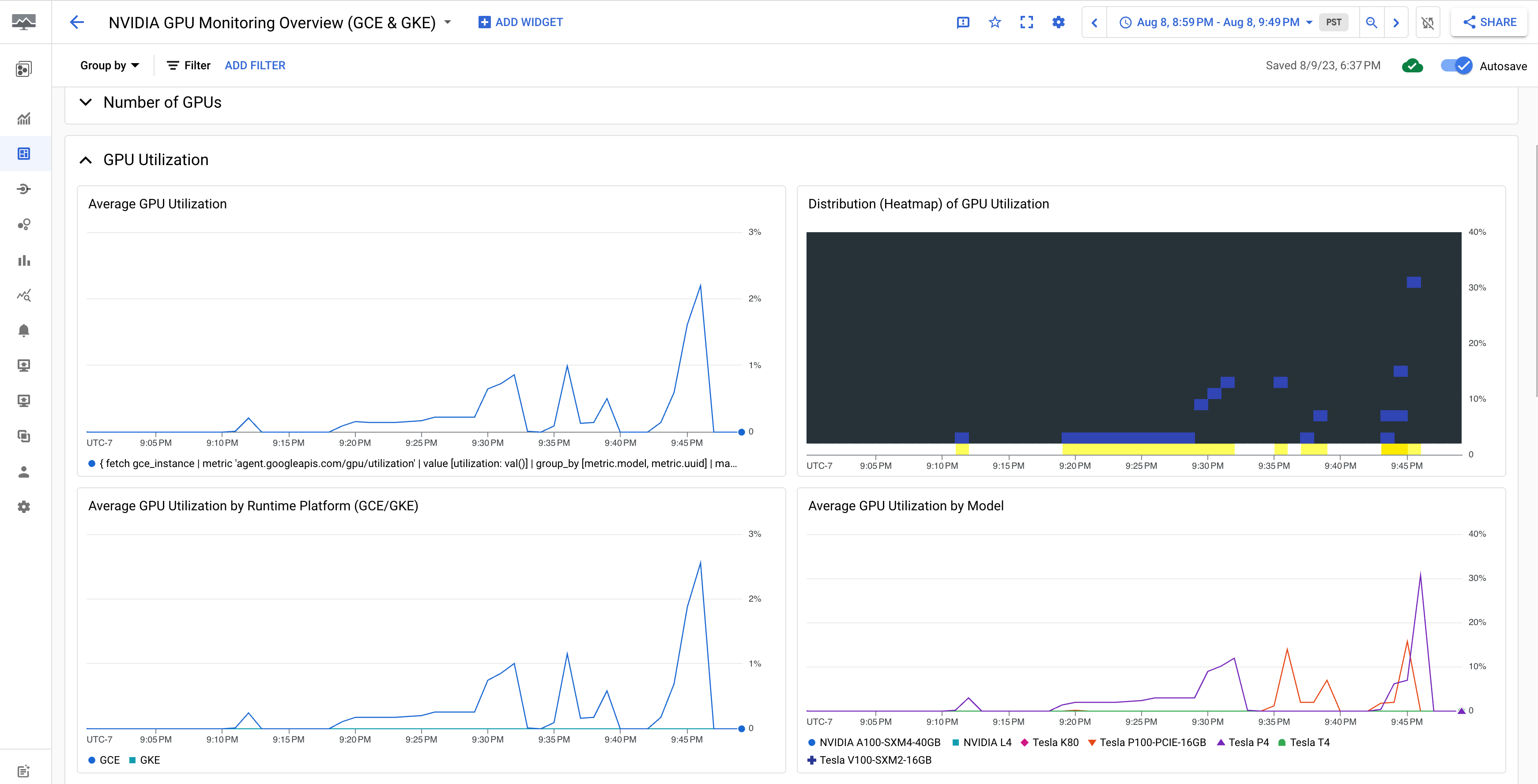
Le tableau de bord Présentation de la surveillance des GPU NVIDIA (GCE et GKE) affiche les métriques de GPU, telles que l'utilisation du GPU, le taux de trafic de la carte d'interface réseau et l'utilisation de la mémoire du GPU.
L'affichage de votre utilisation du GPU est semblable au résultat suivant :
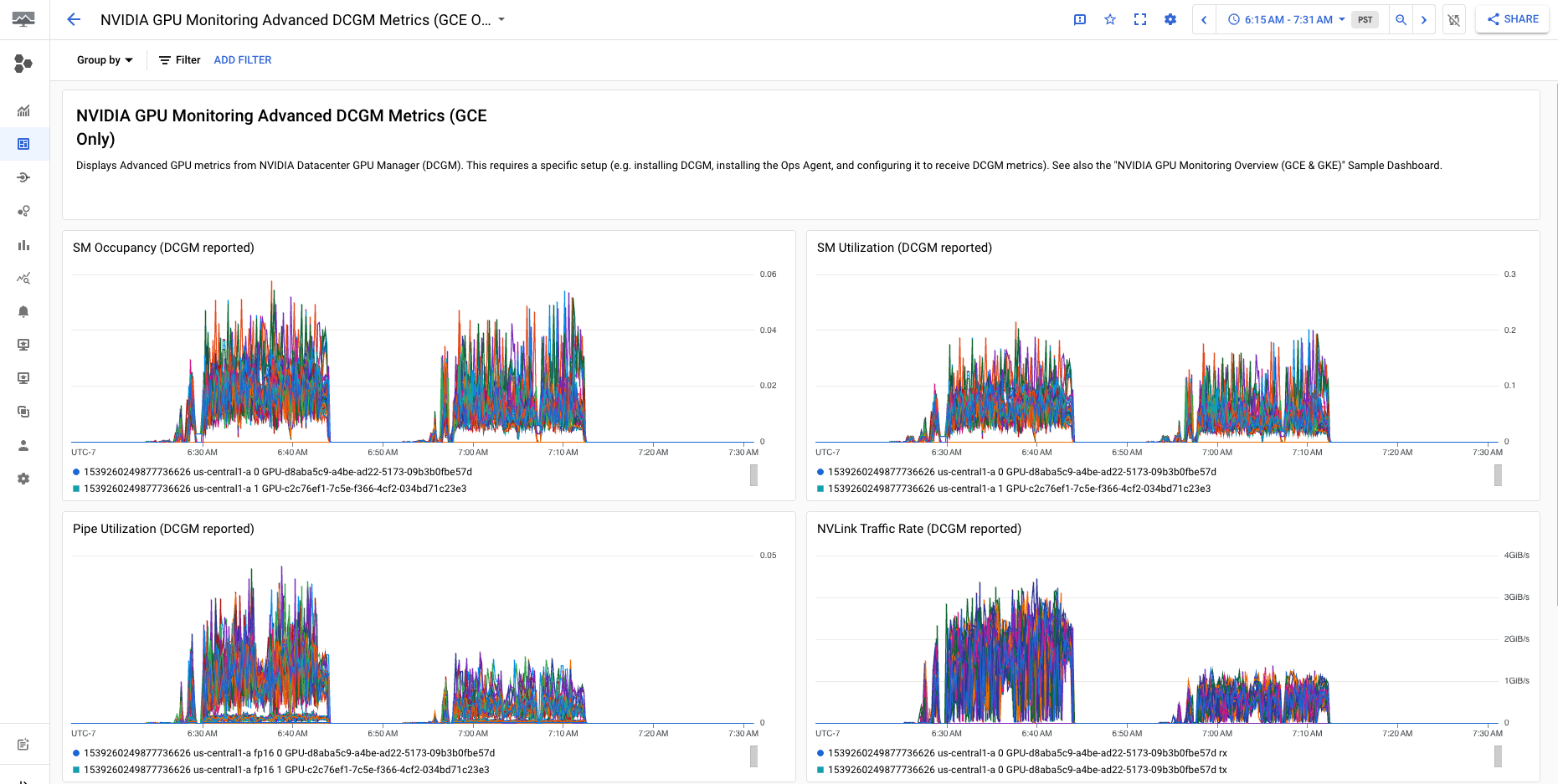
Le tableau de bord Métriques DCGM avancées de surveillance des GPU NVIDIA (GCE uniquement) affiche des métriques avancées telles que l'utilisation SM, l'occupation SM, l'utilisation de pipelines SM, le taux de trafic PCIe et taux de trafic NVLink.
Votre affichage de métrique DCGM avancée est similaire à ce qui suit :
Étape suivante
- Pour gérer la maintenance de l'hôte GPU, consultez la section Gérer les événements de maintenance de l'hôte GPU.
- Pour améliorer les performances du réseau, consultez la section Utiliser une bande passante réseau plus élevée.