Pour optimiser l'utilisation des ressources, vous pouvez suivre les taux d'utilisation des GPU de vos instances de machines virtuelles.
Lorsque vous connaissez les taux d'utilisation des GPU, vous pouvez effectuer des tâches telles que la configuration de groupes d'instances gérés pouvant être utilisés pour procéder à un autoscaling des ressources.
Pour examiner les métriques GPU à l'aide de Cloud Monitoring, procédez comme suit :
- Sur chaque instance de VM, configurez le script de génération de rapport de métriques GPU. Ce script installe l'agent de génération de rapports de métriques GPU. Cet agent s'exécute à intervalles réguliers sur l'instance pour collecter des données GPU et envoie ces données à Cloud Monitoring.
- Sur chaque VM, exécutez le script.
- Sur chaque VM, définissez l'agent de génération de rapports de métriques GPU sur le démarrage automatique au démarrage.
- Affichez les journaux dans Google Cloud Cloud Monitoring.
Rôles requis
Pour surveiller les performances des GPU sur les VM Windows, vous devez attribuer les rôles IAM (Identity and Access Management) requis aux comptes principaux suivants :
- Le compte de service utilisé par l'instance de VM
- Votre compte utilisateur
Pour vous assurer que vous et le compte de service de la VM disposez des autorisations nécessaires pour surveiller les performances du GPU sur les VM Windows, demandez à votre administrateur de vous accorder, à vous et au compte de service de la VM, les rôles IAM suivants sur le projet :
-
Administrateur d'instances Compute (v1) (
roles/compute.instanceAdmin.v1) -
Rédacteur de métriques Monitoring (
roles/monitoring.metricWriter)
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Votre administrateur peut également vous accorder, à vous et au compte de service de la VM, les autorisations requises à l'aide de rôles personnalisés ou d'autres rôles prédéfinis.
Configurer le script de génération de rapport de métriques GPU
Exigences
Sur chacune de vos VM, vérifiez que vous remplissez les conditions suivantes :
- Chaque VM doit avoir des GPU connectés.
- Chaque VM doit disposer d'un pilote GPU installé.
Télécharger le script
Ouvrez un terminal PowerShell en tant qu'administrateur, puis utilisez la commande Invoke-WebRequest pour télécharger le script.
Invoke-WebRequest est disponible sur PowerShell 3.0 ou version ultérieure.
Google Cloud recommande d'utiliser ctrl+v pour coller les blocs de code copiés.
mkdir c:\google-scripts cd c:\google-scripts Invoke-Webrequest -uri https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-monitoring/main/windows/gce-gpu-monitoring-cuda.ps1 -outfile gce-gpu-monitoring-cuda.ps1
Exécuter le script
cd c:\google-scripts .\gce-gpu-monitoring-cuda.ps1
Configurer l'agent pour qu'il démarre automatiquement au démarrage
Pour vous assurer que l'agent de génération de rapport de métriques GPU est configuré pour s'exécuter au démarrage du système, utilisez la commande suivante pour ajouter l'agent au planificateur de tâches Windows.
$Trigger= New-ScheduledTaskTrigger -AtStartup $Trigger.ExecutionTimeLimit = "PT0S" $User= "NT AUTHORITY\SYSTEM" $Action= New-ScheduledTaskAction -Execute "PowerShell.exe" -Argument "C:\google-scripts\gce-gpu-monitoring-cuda.ps1" $settingsSet = New-ScheduledTaskSettingsSet # Set the Execution Time Limit to unlimited on all versions of Windows Server $settingsSet.ExecutionTimeLimit = 'PT0S' Register-ScheduledTask -TaskName "MonitoringGPUs" -Trigger $Trigger -User $User -Action $Action -Force -Settings $settingsSet
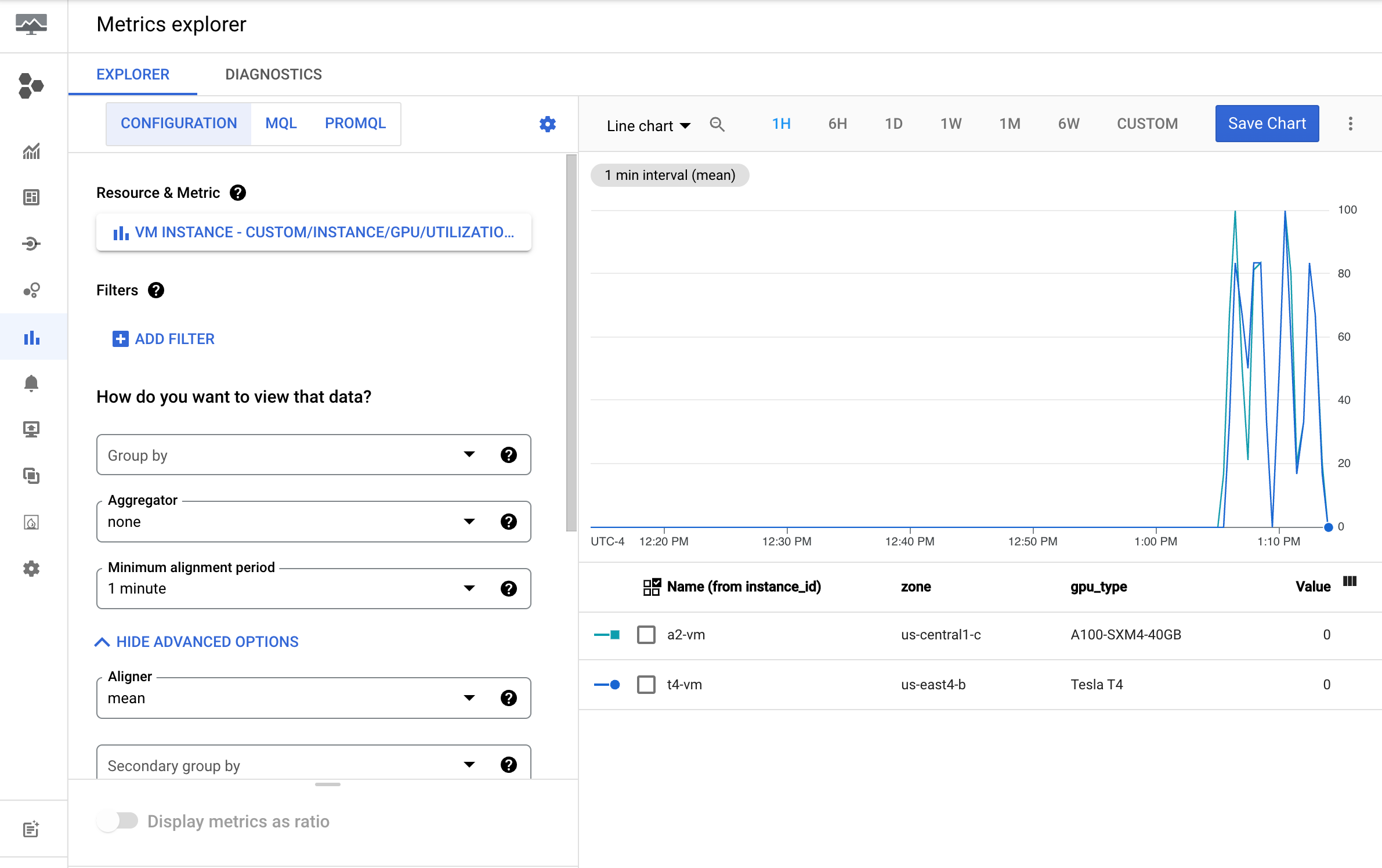
Examiner les métriques dans Cloud Monitoring
Dans la console Google Cloud , accédez à la page Explorateur de métriques.
Développez le menu Sélectionner une métrique.
Dans le menu Ressource, sélectionnez Instance de VM.
Dans le menu Catégorie de métrique, sélectionnez Personnaliser.
Dans le menu Métrique, sélectionnez la métrique à représenter graphiquement. Par exemple,
custom/instance/gpu/utilization.Cliquez sur Appliquer.
Votre utilisation GPU doit se présenter comme suit :
Métriques disponibles
| Nom de la métrique | Description |
|---|---|
instance/gpu/utilization |
Durée moyenne de la dernière période d'échantillonnage pendant laquelle un ou plusieurs noyaux se sont exécutés sur le GPU. |
instance/gpu/memory_utilization |
Durée moyenne de la dernière période d'échantillonnage pendant laquelle des données ont été lues ou écrites dans la mémoire globale (appareil). |
instance/gpu/memory_total |
Mémoire de GPU totale installée. |
instance/gpu/memory_used |
Mémoire totale allouée par les contextes actifs. |
instance/gpu/memory_used_percent |
Pourcentage de la mémoire totale allouée par les contextes actifs. Les valeurs vont de 0 à 100. |
instance/gpu/memory_free |
Mémoire totale disponible. |
instance/gpu/temperature |
Température du GPU principale en degrés Celsius. |
Étape suivante
- Pour gérer la maintenance de l'hôte GPU, consultez la section Gérer les événements de maintenance de l'hôte GPU.
- Pour améliorer les performances du réseau, consultez la section Utiliser une bande passante réseau plus élevée.