为了帮助提高资源利用率,您可以跟踪虚拟机 (VM) 实例的 GPU 利用率。
在了解 GPU 利用率之后,您可以执行多项任务,如设置可用于自动扩缩资源的代管式实例组。
如需使用 Cloud Monitoring 查看 GPU 指标,请完成以下步骤:
- 在每个虚拟机上,设置 GPU 指标报告脚本。此脚本会安装 GPU 指标报告代理。此代理会在虚拟机上定期运行来收集 GPU 数据,并将这些数据发送到 Cloud Monitoring。
- 在每个虚拟机上,运行脚本。
- 在每个虚拟机上,将 GPU 指标报告代理设置为在引导时自动启动。
- 在 Google Cloud Cloud Monitoring 中查看日志。
所需的角色
如需监控 Windows 虚拟机上的 GPU 性能,您需要向以下主账号授予所需的 Identity and Access Management (IAM) 角色:
- 虚拟机实例所使用的服务账号
- 您的用户账号
如需确保您和虚拟机的服务账号具有在 Windows 虚拟机上监控 GPU 性能所需的权限,请让您的管理员为您和虚拟机的服务账号授予项目的以下 IAM 角色:
-
Compute Instance Admin (v1) (
roles/compute.instanceAdmin.v1) -
Monitoring Metric Writer (
roles/monitoring.metricWriter)
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
您的管理员也可以通过自定义角色或其他预定义角色向您和虚拟机的服务账号授予所需的权限。
设置 GPU 指标报告脚本
要求
检查每个虚拟机都满足以下要求:
- 每个虚拟机必须已挂接 GPU。
- 每个虚拟机必须已安装 GPU 驱动程序。
下载脚本:
以管理员身份打开 PowerShell 终端,并使用 Invoke-WebRequest 命令下载脚本。
Invoke-WebRequest 适用于 PowerShell 3.0 或更高版本。Google Cloud 建议您使用 ctrl+v 粘贴复制的代码块。
mkdir c:\google-scripts cd c:\google-scripts Invoke-Webrequest -uri https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-monitoring/main/windows/gce-gpu-monitoring-cuda.ps1 -outfile gce-gpu-monitoring-cuda.ps1
运行脚本
cd c:\google-scripts .\gce-gpu-monitoring-cuda.ps1
将代理配置为在引导时自动启动
如需确保将 GPU 指标报告代理设置为在系统启动时运行,请使用以下命令将该代理添加到 Windows 任务计划程序。
$Trigger= New-ScheduledTaskTrigger -AtStartup $Trigger.ExecutionTimeLimit = "PT0S" $User= "NT AUTHORITY\SYSTEM" $Action= New-ScheduledTaskAction -Execute "PowerShell.exe" -Argument "C:\google-scripts\gce-gpu-monitoring-cuda.ps1" $settingsSet = New-ScheduledTaskSettingsSet # Set the Execution Time Limit to unlimited on all versions of Windows Server $settingsSet.ExecutionTimeLimit = 'PT0S' Register-ScheduledTask -TaskName "MonitoringGPUs" -Trigger $Trigger -User $User -Action $Action -Force -Settings $settingsSet
在 Cloud Monitoring 中查看指标
在 Google Cloud 控制台中,前往 Metrics Explorer 页面。
展开选择指标菜单。
在资源菜单中,选择虚拟机实例。
在 Metric category(指标类别)菜单中,选择自定义。
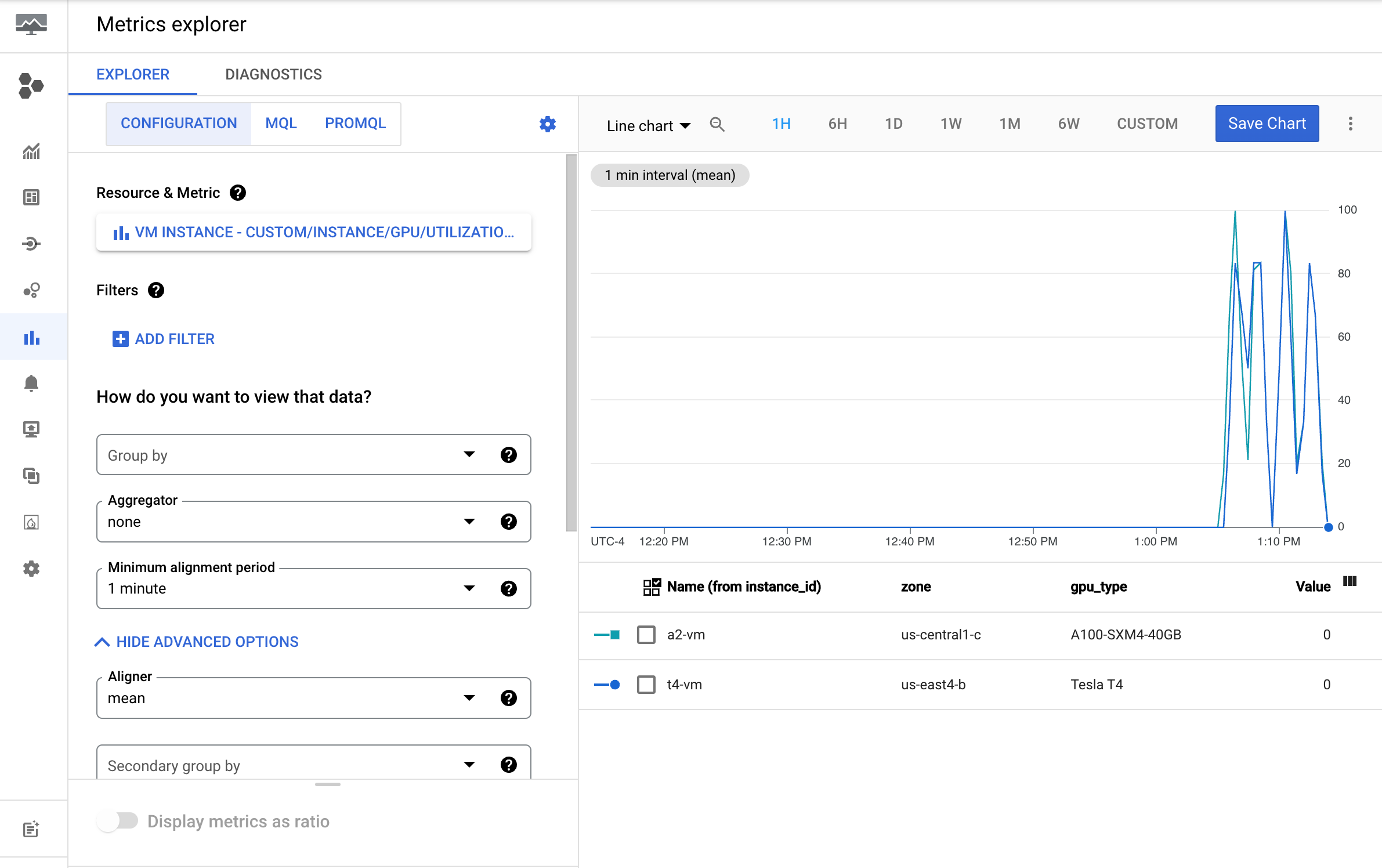
在指标菜单中,选择要用于绘制图表的指标。例如
custom/instance/gpu/utilization。点击应用。
您的 GPU 利用率应与以下输出内容类似:
可用指标
| 指标名称 | 说明 |
|---|---|
instance/gpu/utilization |
在上一个采样周期内,一个或多个内核在 GPU 上执行的时间所占的百分比。 |
instance/gpu/memory_utilization |
在上一个采样周期内,读取或写入全局(设备)内存的时间所占的百分比。 |
instance/gpu/memory_total |
已安装 GPU 总内存。 |
instance/gpu/memory_used |
活跃上下文分配的总内存。 |
instance/gpu/memory_used_percent |
活跃上下文分配的总内存百分比。范围是 0 - 100。 |
instance/gpu/memory_free |
可用总内存。 |
instance/gpu/temperature |
核心 GPU 温度(以摄氏度 (°C) 为单位)。 |
后续步骤
- 如需处理 GPU 主机维护,请参阅处理 GPU 主机维护事件。
- 如需提升网络性能,请参阅使用更高的网络带宽。