標準快照會以增量方式備份磁碟上的資料。建立快照後,您可以使用快照建立包含擷取資料的新磁碟。標準快照可為單一磁碟提供異地備援備份。快照會擷取磁碟內容,無論磁碟是否已附加至正在執行的虛擬機器 (VM) 執行個體。如要備份整個 VM 或多個磁碟,請建立機器映像檔。如需其他情境,請參閱資料備份選項說明圖表。
從附加至執行中 VM 執行個體的磁碟建立的快照,其生命週期與 VM 執行個體的生命週期無關。
快照類型
您可以透過快照備份磁碟。標準、即時和封存這 3 種快照都會擷取磁碟在特定時間點的內容。
以下是快照類型的主要差異:
- 刪除來源磁碟後保留
- 資料復原時間 (RTO)
- 儲存空間位置
刪除來源磁碟後保留
磁碟的即時快照只會在來源磁碟刪除前存在。標準快照和封存快照不會隨著來源磁碟一併刪除。因此,如要在刪除磁碟後保留磁碟備份,請使用封存或標準快照。
資料救援時間
資料復原時間是指從快照建立新磁碟所需的時間長度,且會因快照類型而異。
- 即時快照的復原時間最短,效果也最好。
- 標準快照的資料復原時間比封存快照短。
- 封存快照的資料復原時間最長,但儲存空間的成本效益最高。
依快照類型劃分的儲存位置
儲存位置是 Compute Engine 儲存快照的區域或地區。
- 即時快照是本機磁碟備份,儲存在與來源磁碟相同的可用區或區域。
- 封存快照和標準快照是磁碟資料的遠端備份,儲存位置與來源磁碟不同。
Compute Engine 儲存封存和標準快照的方式相同。系統會將封存和標準快照的副本儲存在不同位置,同時也會自動使用檢查碼機制確保資料完整性。
除非另有說明,否則標準快照的參照也包括封存快照。
本文中的資訊適用於封存和標準快照。 進一步瞭解即時快照。
快照類型比較
下表比較了不同類型的快照:
| 快照類型 | 適用情境 | 儲存空間備援 | 支援 Hyperdisk | 可透過快照排程建立 | 來源磁碟刪除時一併刪除 |
|---|---|---|---|---|---|
| 標準快照 | 以異地備援的方式提供資料備份,以防本機、可用區和區域性服務中斷。 | 重複。儲存在一或多個區域。不限於與來源磁碟相同的可用區或區域。 | 是 | 是 | 否 |
| 封存快照 | 與標準快照相同,不過適用於極少存取且須保留數個月或數年的資料。成本較低的異地備援儲存空間,更適合用於與法規遵循、稽核和冷儲存相關的資料。 | 重複。儲存在一或多個區域。不限於與來源磁碟相同的可用區或區域。 | 是 | 否 | 否 |
| 即時快照 | 就地備份資料,如果發生使用者錯誤或應用程式損毀,就能迅速還原至新的磁碟。 | 不會重複。只能儲存在與來源磁碟相同的可用區或區域。 | 是,適用於特定 Hyperdisk 類型* |
否 | 是 |
*您無法建立 Hyperdisk ML 或 Hyperdisk Throughput 磁碟區的即時快照。
除了快照,Compute Engine 也提供其他資料備份選項。查看說明資料備份選項的圖表。
封存快照
標準快照和封存快照的主要差異在於儲存位置和費用。
封存快照與標準快照享有相同優點,包括增量鏈結、壓縮和加密。
不過,封存快照的費用較低,更適合用於法規遵循、稽核和長期冷儲存等用途。如果您需要保留快照數月或數年,但很少需要存取快照,建議使用封存快照,而非標準快照。每種快照類型會儲存在不同的增量快照鏈中,封存快照則會分別列在Google Cloud 控制台中。
快照範圍
建立快照時,您可以建立全球範圍的快照 (預設) 或地區範圍的快照。如要設定地區範圍,請完成建立地區範圍快照的步驟。
設定區域範圍可確保所有快照資料和使用快照所需的中繼資料,都位於範圍內的區域。區域範圍快照支援額外的位置控制項,可限制允許建立和還原快照的位置。 相較之下,全域範圍的快照可在任何區域建立及還原,不受限制。這有助於控管快照網路費用、提升全球服務中斷的復原能力,並為快照資料提供額外保護。
如要決定區域範圍或全域範圍快照是否最適合您的專案,請參閱下表:
| 區域範圍快照 | 全域範圍快照 (預設) |
|---|---|
| 限制允許建立及還原快照的位置。 | 對快照建立和還原位置的控制權有限。 |
| 所有快照中繼資料和資料都位於相同範圍的區域。 | 快照中繼資料和資料不一定會儲存在相同區域。 |
| 限制潛在攻擊者建立及還原快照資料的位置,提升資料安全性。 | 具備必要 IAM 權限的使用者可以在任何區域建立及還原資料。 |
使用標準快照
如要瞭解如何使用快照備份磁碟,請參閱「建立快照」。您可以在嘗試可能危險的作業前建立磁碟快照,這樣一來,如果結果不如預期,就能還原變更。
如要瞭解如何將快照內容還原至新磁碟,請參閱「還原快照」。
如果您不再需要特定快照,可以刪除快照以降低儲存空間成本。
如要降低意外遺失資料的風險,最佳做法是設定快照排程,確保系統會定期備份資料。
存取標準快照
根據預設,快照是全域資源。也就是說,使用快照建立新磁碟時,新磁碟可以位於任何地區,無論來源快照儲存在何處。如要限制存取位置,請設定可建立及還原快照的區域。
還原快照時,系統會從快照建立新磁碟。還原快照不會覆寫來源磁碟。
您也可以跨專案共用快照。
限制
您無法變更現有標準快照的儲存位置。請參閱「選取快照的儲存位置」一節。
每 60 分鐘最多可為特定磁碟建立 6 次快照。詳情請參閱「快照頻率限制」。
您無法編輯快照中儲存的資料。
刪除的快照無法復原。
您可以為特定磁碟建立數量不限的標準快照。
(預先發布版) 您只能將區域範圍快照儲存在 Cloud Storage 地區位置,例如
asia-south1或us-central1。您無法將區域範圍快照儲存在多地區位置,例如asia。您無法將全域範圍的快照轉換為區域範圍的快照。 您必須建立範圍適當的新快照。
您無法使用受客戶提供的加密金鑰 (CSEK) 保護的來源磁碟,建立區域範圍快照。
區域範圍的快照名稱僅在區域內不得重複。您可以在不同區域中,擁有相同名稱的區域範圍快照。
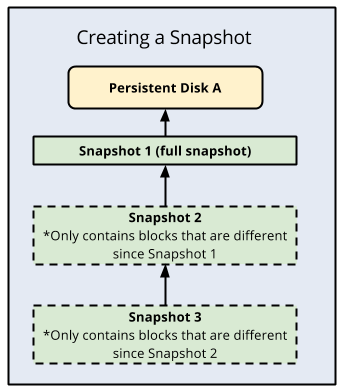
增量標準快照的運作方式
快照中的資料會逐漸增加,因此相較於定期建立完整的磁碟映像檔,定期建立永久磁碟或 Hyperdisk 快照不僅速度更快,成本也能大幅降低。
增量快照的運作方式如下:
- 第一個成功建立的磁碟快照是完整快照,其中包含磁碟上的所有資料。
- 第二個快照僅包含第一個快照建立後新增或修改過的資料。在第一個快照建立後未曾更動的資料不會包含在第二個快照中, 而第二個快照會包含第一個快照中所有未更動資料的參照。
- 第三個快照包含第二個快照建立後新增或變更過的資料,但不會加入第一個快照或第二個快照中任何未經修改的資料。第三個快照會包含第一個快照與第二個快照中所有未更動資料區塊的參照。
後續所有的磁碟快照皆會重複採用相同模式,以上一次成功建立的快照為基礎來進行備份。
刪除快照
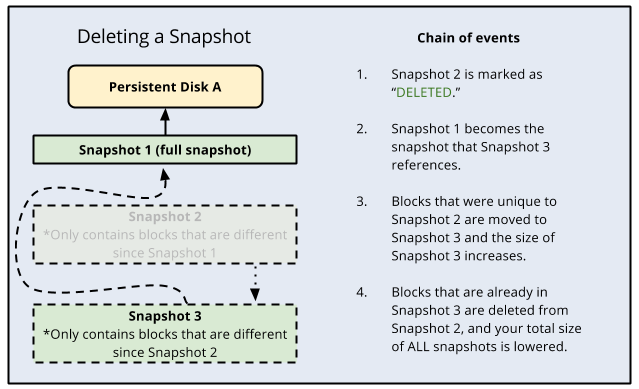
Compute Engine 使用增量快照,讓每個快照只包含前一個快照後變更的資料。針對未變更的資料,快照會參照前一個快照的資料。Persistent Disk 和 Hyperdisk 快照的儲存空間成本只會根據快照總大小來計費。
刪除標準快照時,如果該快照沒有其他相依的快照,則會遭到完全刪除。
不過,如果刪除有相依快照的快照,會發生下列情況:
- 還原其他快照所需的所有資料都會移到下一個快照中,從而增加其大小。
- 還原其他快照所需的所有資料都會遭到刪除。這會減少所有快照的總大小。
- 下一個快照不會再參照標示為待刪除的快照,而是會參照前一個快照。
由於後續快照可能需要存放在先前快照上的資訊,因此請注意,刪除快照不一定會刪除快照上的所有資料。如要確認刪除快照中的資料,建議您刪除所有快照。
如果您的磁碟有快照排程,則必須先將快照排程從磁碟卸離,才能刪除該排程。從磁碟中移除快照排程可避免發生進一步的快照活動。您無法刪除已附加至磁碟的排程。您隨時可以手動刪除快照。
下圖呈現此程序:
快照大小和已刪除的區塊
快照會擷取寫入磁碟且未捨棄的部分。
視磁碟檔案系統設定而定,有時刪除的檔案不會遭到捨棄。如果發生這種情況,您可能會發現快照大小大於檔案系統回報的磁碟使用空間。為避免這種情況,最佳做法是啟用 discard 選項或在磁碟上執行 fstrim。
快照鏈結
您可以在建立快照時指定快照鏈結名稱,在不同的快照鏈結中建立標準快照。使用鏈結名稱為永久磁碟建立多個標準快照時,每個新快照都會以使用該鏈結名稱建立的最後一個成功快照為基礎,以遞增方式建立。只有進階服務擁有者需要建立個別快照鏈 (例如用於退款追蹤),才應使用快照鏈。
使用 gcloud CLI、REST 或 Terraform 建立標準快照時,可以指定快照鏈結名稱。
建立快照時,您可以選擇建立標準快照或封存快照。封存快照與標準快照的優點相同,包括增量鏈結、壓縮和加密。不過,封存快照的費用較低,更適合用於法規遵循、稽核和長期冷儲存等用途。如果您需要保留快照數月或數年,但很少需要存取快照,建議使用封存快照,而非標準快照。每種快照類型會儲存在不同的增量快照鏈中,封存快照則會分別列在Google Cloud 控制台中。
快照儲存和存取位置
建立磁碟快照時, Google Cloud 會將快照儲存在特定儲存位置。如果是全域範圍的快照,無論快照的儲存位置為何,您都可以使用快照在任何區域和可用區中建立新磁碟。不過,快照的位置會影響其可用性,而且在建立快照或將快照還原至新磁碟時,可能會產生網路費用。如果是區域範圍的快照,您可以設定允許的位置,控管可還原快照的區域。
儲存空間位置類型
您可以將全域範圍的快照儲存在下列任一位置類型:
- Cloud Storage 多地區位置,例如
asia或us。 - Cloud Storage 地區位置,例如
asia-south1或us-central1。
(預先發布版) 您可以將區域範圍的快照儲存在 Cloud Storage 地區位置,例如 asia-south1 或 us-central1。
多地區儲存空間位置提供最高的可用性和復原能力。單一地區儲存位置可讓您更有效地控制資料的實際位置,因為您指定了單一地區。
如果您需要遵循企業或政府的資料放置政策,請將快照儲存在符合這些政策的最近單一地區位置。
如果您的應用程式未部署在屬於多地區的位置中,且與高快照可用性相比,您更在乎降低網路費用,那麼請將快照儲存在來源磁碟所在地區。只要將快照儲存在來源磁碟的所在地區,就能將從該來源磁碟還原與建立快照的網路費用降到最低。
不過,與多地區儲存位置不同的是,單一地區儲存位置會在單一地區的多個可用區儲存資料,因此如果發生區域中斷情形,可能無法存取資料。為了確保資料的可用性,您可能也想將備援快照儲存在第二個位置。
如果您有包含資源位置限制的組織政策,您指定的任何快照儲存位置都必須位於限制所定義的該組位置中。詳情請參閱 Compute Engine 資源位置。
設定儲存位置
根據您要建立全域或區域快照,設定儲存位置。
全域範圍快照
使用快照設定中指定的預先定義或自訂預設儲存位置。快照設定的儲存位置政策會定義預設位置, Google Cloud 用於儲存專案的所有快照。雖然 Google Cloud 會維持預先定義的預設儲存位置政策,但您可以在快照設定中自訂這項政策,並設定自己的預設儲存位置:
- 使用 Google Cloud 預先定義的預設位置。 首次更新快照設定前, Google Cloud會維持儲存空間位置政策的預先定義值。這個預先定義的預設位置是離來源磁碟最近的多區域。詳情請參閱Google Cloud 預先定義的儲存位置政策。
- 設定自訂預設位置。 如要為專案快照自訂預設儲存位置,請更新快照設定的儲存位置政策。更新快照設定並設定預設值後,Google Cloud 就會開始使用這個新設定的位置儲存日後的所有快照。詳情請參閱「更新專案的快照設定」。
覆寫快照設定,並在建立快照時手動指定位置。 或者,您也可以覆寫快照設定,並在建立快照時手動指定所需位置。您可以運用這個選項,為特定快照選擇其他位置,但只能在作業基礎上進行。如要瞭解如何在建立快照時指定位置,請參閱「建立永久磁碟磁碟區的快照」。
選擇 Google Cloud 預先定義的預設位置的時機
以下為使用快照設定中預先定義的多區域做為儲存位置的使用範例:
- 預設多地區位置符合企業或政府的資料放置政策。
- 您的磁碟儲存在屬於多地區位置 (
us) 的單一地區位置 (例如us-central1),且您偏好較高的快照可用性,但可能導致快照還原效能較慢。 - 您不想讓快照頻繁還原至預設快照儲存位置外部的磁碟。
選擇自行指定儲存空間位置的時機
以下為使用自訂儲存位置的範例,您可以更新或覆寫快照設定:
- 自訂多地區位置符合企業或政府的資料放置政策。
- 您的應用程式部署在未列入任何 Cloud Storage 多地區位置的地區中,且與快照可用性相比,您更在乎快照還原效能。
- 您從預設快照儲存位置外部的磁碟多次還原快照。
您無法修改現有快照的儲存位置。如要在新位置儲存磁碟快照,請在所選位置建立新快照,然後刪除舊位置的快照。如要將快照儲存在多個位置,則必須在每個位置建立快照。在新的位置建立新快照時,系統會建立包含磁碟上所有資料的完整快照。
區域範圍快照
如要選擇區域範圍快照的儲存位置,您必須在建立快照時手動指定區域。設定區域範圍時,系統會覆寫您設定的所有預設儲存位置。如果您未設定區域範圍,系統會將快照建立為全域範圍快照。如要瞭解如何在建立快照時指定區域,請參閱為區域範圍快照設定快照建立和還原位置。
網路費用
如果是全域範圍的快照,當磁碟位於多區域的成員區域時,建立或還原所有多區域標準快照都會產生網路費用。如果您無須用到多區域快照的額外複製和應變功能,建議您在快照建立時指定區域位置,以便使用區域快照。
如果您要盡量降低網路費用,選取快照的儲存位置是非常重要的。只要您把快照儲存在來源磁碟的所在地區,當您從相同的地區存取該快照時,就不會產生網路費用。但如果您從另一個地區存取該快照,就會產生網路費用。如果快照的建立地區與來源磁碟不同,或是快照的還原地區與快照不同,就會產生網路費用。
跨地區的存取作業會產生網路費用。舉例來說,如果您的來源磁碟位於 asia-east1,而您將快照儲存在 asia-east2,當您跨這兩個地區來存取快照時,就會產生網路費用。
australia-southeast1 和 southamerica-east1 這兩個地區都有預設的多地區快照儲存位置,因此您必須變更儲存位置,否則就會產生網路費用。您可以透過快照設定修改儲存位置,或在建立快照時手動覆寫預設位置:
- 如果來源磁碟位於
australia-southeast1,預設的快照儲存位置就是在asia多地區。如要降低費用,請改為將快照儲存在australia-southeast1地區。 - 如果來源磁碟位於
southamerica-east1,預設的快照儲存位置就是在us多地區。如要降低費用,請改為將快照儲存在southamerica-east1地區。
如果您將快照還原到某個磁碟,而該磁碟的所在地區並不在該快照的儲存位置中,就會產生網路費用。舉例來說,如果您利用儲存在多地區位置 asia 的快照,在 australia-southeast1 中建立新的地區永久磁碟,就會產生網路費用。